💡 동시성
동시성(Concurrency)
동시성은 프로세스 관점에서 각 작업을 스레드를 통해 빠르게 전환하며 동시에 실행되는 것처럼 보이는 방식이다. 이때, 여러 스레드가 공유 자원에 접근하려 할 때 문제가 발생할 수 있다.
병렬성(Parallelism)
병렬성은 멀티 스레드와 멀티 프로세서를 이용해 여러 작업을 실제로 동시에 수행하는 것이다.
- 동기는 "같은 시간에 실행될 수 있는 작업을 나누는 것"이며,
- 병렬성은 "여러 작업이 실제로 동시에 실행되는 것"이다.
💡 동시성 문제
동시성 문제는 여러 스레드가 동일한 자원에 동시에 접근할 때 발생한다. 멀티스레딩 환경에서 여러 스레드가 동시에 실행되므로, 동일 자원에 대한 경합(Race Condition), 교착 상태(Deadlock), 기아 상태(Starvation) 등의 문제가 발생할 수 있다.
주요 문제
- 경쟁 상태(Race Condition): 여러 스레드가 동시에 같은 자원에 접근하여 그 값을 변경할 때 발생하는 문제이다.
- 교착 상태(Deadlock): 두 개 이상의 스레드가 서로 자원을 기다리며 무한 대기 상태에 빠지는 것이다.
- 기아 상태(Starvation): 일부 스레드가 자원을 계속 기다리다가 실행되지 못하는 상태이다.
💡 동시성 문제 해결 방법
1. 애플리케이션 레벨에서 해결
- Synchronized와 @Transactional
- ReentrantLock과 ConcurrentHashMap
애플리케이션 레벨 동시성 제어를 사용하는 경우
- 단일 JVM 내에서만 동시성을 제어하면 되는 경우
- 간단한 동시성 제어가 필요한 경우
- 성능이 중요하고 DB 부하를 최소화해야 하는 경우
- ex) 캐시나 메모리 내 카운터 등을 다룰 때
- 여러 서버(분산 환경)에서는 동작하지 않음
2. 데이터베이스에서 해결
- 낙관적 락(Optimistic Locking): 락을 사용하지 않고 버전 컬럼을 추가해 데이터의 정합성을 맞춘다. 동시성 이슈가 발생하지 않을 것으로 예상하고 모든 요청을 락 없이 처리하며, 문제가 발생하면 롤백한다.
- 비관적 락(Pessimistic Locking): 동시성 이슈가 자주 발생할 것이라 예상하여 락을 사용한다. 한 트랜잭션이 데이터에 접근하면 다른 트랜잭션은 해당 데이터를 읽거나 쓸 수 없다.
SELECT ~ FOR UPDATESQL문을 사용해 구현한다.
DB 레벨 동시성 제어를 사용하는 경우
- 여러 서버에서 같은 데이터에 접근하는 경우
- 데이터 정합성이 매우 중요한 경우
- 트랜잭션 ACID 속성이 필요한 경우
- ex) 재고 관리, 예약 시스템, 결제 처리
- 데드락 가능성이 있음
- 짧은 시간의 락에는 오버헤드가 큼
낙관적 락 사용
- 충돌이 적을 것으로 예상될 때
- 읽기가 쓰기보다 많은 경우
- 응답 시간이 중요한 경우
비관적 락 사용
- 충돌이 자주 발생할 것으로 예상될 때
- 데이터 정합성이 매우 중요한 경우
- 동시 수정이 빈번한 경우
3. Redis
Redis를 사용한 분산 락도 동시성 문제 해결에 유용하다.
Redis 분산 락을 사용하는 경우
- 마이크로서비스 아키텍처에서 동시성 제어가 필요한 경우
- DB 트랜잭션보다 가벼운 락이 필요한 경우
- 짧은 시간 동안의 락이 필요한 경우
- ex) 실시간 채팅 메시지 전송, API 요청 제한
- 분산 환경에서 사용 가능
- DB보다 빠른 성능
- 만료 시간 설정 가능
- Redis 서버 장애 시 전체 시스템에 영향
- ACID 트랜잭션이 필요한 경우에는 부적합
📍 애플리케이션 레벨 해결
1. Synchronized와 @Transactional
@Transactional은 데이터베이스 트랜잭션을 관리하며, 메소드 내에서 발생하는 모든 데이터베이스 작업들을 하나의 트랜잭션으로 묶는다.
Synchronized는 자바에서 동기화를 위해 사용되며, 한 번에 하나의 스레드만 특정 코드 블록에 접근할 수 있도록 제한한다.
// synchronized 메서드
@Service
public class StockService {
private int stock = 100;
public synchronized void decreaseStock(int quantity) {
if (stock >= quantity) {
stock -= quantity;
} else {
throw new IllegalArgumentException("재고 부족");
}
}
}// synchronized 블록
@Service
public class StockService {
private int stock = 100;
private final Object lock = new Object(); // 락 객체
public void decreaseStock(int quantity) {
synchronized(lock) { // 특정 객체에 대한 락
if (stock >= quantity) {
stock -= quantity;
} else {
throw new IllegalArgumentException("재고 부족");
}
}
}
}이때, 메서드 전체에 락이 걸려 한 스레드가 실행 중일 때 다른 스레드는 대기해야 한다.
문제점과 한계
- 트랜잭션이 종료되기 전에 다른 스레드가 동기화된 메소드에 접근할 수 있어, 예기치 않은 상태가 발생할 수 있다.
- 락 획득 시도를 취소할 수 없다.
- 락의 상태를 확인할 수 없음
- 락 획득 순서를 제어할 수 없음
- 대기 중인 스레드 수를 알 수 없음
- 세밀한 제어 불가. 공정성(fairness)을 설정할 수 없음, 여러 조건에 대한 대기/통지를 구현하기 어려움
=> Synchronized는 락 획득을 취소할 수 없고, 해당 메서드나 블록에서는 무조건 락이 걸리고 따라서 여러 조건에 대한 락을 제어할 수 없다. 이 한계를 ReentrantLock으로 극복 가능.
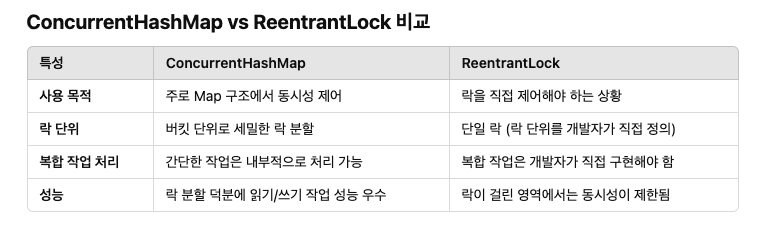
2. ReentrantLock
ReentrantLock은 락을 명시적으로 관리할 수 있는 클래스이다. 동기화 블록을 시작할 때 락을 획득하고, 끝날 때 락을 해제하는 방식으로 동시성을 제어한다.
예시 코드
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class LockExample {
private final Lock lock = new ReentrantLock();
public void performTask() {
lock.lock(); // 락 획득
try {
// Critical section
System.out.println("Thread-safe using Lock");
} finally {
lock.unlock(); // 락 해제
}
}
}주요 특징
- 재진입(Reentrancy): 동일한 스레드가 이미 획득한 락을 다시 획득할 수 있다.
--> 한 스레드가 특정 락을 소유하고 있을 때, 다시 그 락을 요청해도 데드락이 발생하지 않고 성공적으로 락을 획득할 수 있다. 만약 이렇게 하지 못한다면 같은 스레드 임에도 락을 얻지 못하고 대기 상태가 된다. 자기 자신과 경쟁(데드락).
--> 중첩 메서드 호출이나 재귀 호출에서 필요.- 상위 메서드에서 락을 획득했다면, 하위 메서드는 자동으로 그 락의 보호를 받는다.
- 재진입 가능한 락 덕분에 같은 스레드가 다시 락을 요청해도 문제가 발생하지 않는다.
- 락을 추가해야 할지 여부는 하위 메서드가 독립적으로 호출될 가능성이 있는지, 아니면 상위 메서드 내부에서만 호출되는지에 따라 결정된다.
- 락의 상태를 제어 가능: 락을 획득/해제하는 시점을 명시적으로 관리할 수 있다.
- 공정성(Fairness) 옵션 제공: 락을 획득하는 스레드의 순서를 설정할 수 있다.
- Condition 객체 지원: wait와 notify를 대체하는 더 강력한 조건 대기를 지원한다.
- 비차단 시도(TryLock): 락을 즉시 시도하거나 타임아웃을 설정하여 대기한다.
주요 메서드
- lock()
- 현재 스레드가 락을 획득할 때까지 대기.
- 재진입 가능하며, 동일 스레드가 다시 호출하면 락 횟수(counter)가 증가한다.
- unlock()
- 락을 해제한다.
- 락을 획득한 스레드만 호출해야하며, 락 획수가 0이 되면 다른 스레드가 락을 획득할 수 있다.
- tryLock()
- 락을 즉시 시도하며, 성공하면 true, 실패하면 false를 반환한다.
- 시간 제한을 설정하는 오버로드 메서드도 존재한다.
- isLocked()
- 락이 현재 어떤 스레드에 의해 소유되었는지 확인한다.
- getHoldCount()
- 현재 스레드가 획득한 락의 횟수를 반환한다.
- newCondition()
- Condition 객체를 생성하여 세밀한 스레드 대기와 신호를 관리할 수 있다.
내부 메커니즘
원자적 연산이란?
더 이상 나눌 수 없는 연산. 한 번 시작되면 다른 스레드나 작업이 개입하지 못하고 완전히 실행되거나 실행되지 않은 상태로 끝난다.
왜 필요할까?
멀티스레드 환경에서 여러 스레드가 같은 데이터를 동시에 수정하면 경쟁 조건(Race Condition)이 발생할 수 있다. 이를 방지하기 위해, 공유 데이터에 대한 연산을 원자적으로 처리하여 데이터의 일관성을 보장한다.
CAS (Compare-And-Swap)
ReentrantLock은 내부적으로 CAS를 사용하여 락의 상태를 관리한다.
ReentrantLock은 "락을 거는" 역할을 하고, CAS는 ReentrantLock이 실제로 락을 "거는" 과정에서, 락 상태를 갱신하거나 락을 소유한 스레드 정보를 업데이트할 때 사용한다.
--> ReentrantLock은 내부적으로 CAS를 활용하여 락 획득, 해제, 상태 변경 작업을 락 없이 원자적으로 처리한다. 락 획득(lock)과 락 해제(unlock) 과정에서 사용한다.
공유 데이터의 값을 동기화(락) 없이 원자적으로 업데이트하는 메커니즘.
CAS는 다음 과정을 통해 원자적으로 값을 갱신한다.
ㄱ. 메모리의 현재 값과 예상 값을 비교.
ㄴ. 값이 일치하면 새로운 값으로 갱신.
ㄷ. 값이 다르면 실패.
1) 락 획득 시 (lock())
CAS를 사용하여 락 상태를 확인하고 업데이트한다.
만약 락이 현재 사용 중이지 않다면, CAS로 lock state를 변경하여 현재 스레드가 락을 소유하도록 설정한다.
이 과정은 다음과 같이 동작한다.
1. state라는 변수(락 상태 변수)를 읽음.
2. state가 0(사용되지 않음)인지 확인.
3. state를 1(사용 중)로 업데이트.
이 모든 작업은 CAS를 통해 락 없이 수행된다.
예제: 락 획득 시 CAS 사용
if (state == 0) {
if (compareAndSwapState(0, 1)) { // CAS 사용
ownerThread = currentThread;
return true; // 락 획득 성공
}
}2) 락 해제 시 (unlock())
락을 해제할 때도 CAS를 사용하여 state 값을 1 → 0으로 변경한다.
이를 통해 다른 스레드가 락을 즉시 획득할 수 있도록 만든다.
예제: 락 해제 시 CAS 사용
if (state == 1) {
if (compareAndSwapState(1, 0)) { // CAS 사용
ownerThread = null; // 락 소유자 초기화
return true; // 락 해제 성공
}
}
3) 재진입 처리
같은 스레드가 이미 소유한 락을 다시 획득하려고 할 때, CAS를 사용하지 않고 간단히 state 값을 증가시킨다.
재진입은 락의 소유자가 이미 현재 스레드로 설정되어 있기 때문에 별도의 CAS 연산이 필요하지 않.
ReentrantLock의 내부 동작 흐름
-
스레드가 lock() 호출:
- CAS로 락 상태(state)를 업데이트하려고 시도.
- 성공하면 락을 획득하고 반환.
- 실패하면 스레드는 대기열에 들어가 대기.
-
락을 소유한 스레드가 작업 완료 후 unlock() 호출:
- CAS로 락 상태를 1 → 0으로 변경.
- 대기열에 있는 스레드를 깨워 다음 스레드가 락을 획득할 수 있도록 함.
volatile
변수의 값을 메인 메모리에 항상 최신 상태로 유지하도록 보장하는 키워드.
ReentrantLock은 락 상태 변수와 스레드 간의 가시성을 보장하기 위해 volatile 키워드를 사용한다. --> 한 스레드에서 변경한 값이 다른 스레드에게 즉시 반영된다.
volatile은 변수의 읽기/쓰기가 메인 메모리에서 직접 이루어지도록 강제하며, CPU 캐시 불일치 문제를 해결한다.
예를 들어, 락의 소유자나 상태 정보를 나타내는 변수들이 volatile로 선언된다.
한 스레드가 volatile 변수 값을 변경하면, 그 값이 즉시 메인 메모리에 기록된다. volatile 변수 값을 읽을 때 항상 메인 메모리에서 최신 값을 읽는다.
volatile 변수의 동작 과정
1) 스레드 A가 volatile 변수 값을 변경
스레드 A가 volatile 변수 값을 변경하면 해당 값은 스레드 A의 캐시와 메인 메모리에 동시 기록.
다른 스레드의 캐시에 저장된 해당 변수의 값은 즉시 무효화(invalidate).
2) 스레드 B가 volatile 변수 값을 읽음
스레드 B가 값을 읽으려고 할 때 자신의 캐시에 저장된 값이 무효화되었기 때문에, 항상 메인 메모리에서 최신 값을 읽음.
ReentrantLock 내부에서 volatile은 주로 상태 값(state)와 락의 소유자 정보를 저장하는 데 사용된다.
volatile 없이 실행되는 코드
class SharedData {
private boolean running = true; // volatile이 아님
public void stop() {
running = false; // 값 변경
}
public void run() {
while (running) { // running 값을 계속 확인
// 작업 수행
}
System.out.println("Stopped");
}
}문제:
스레드 A가 stop()을 호출하여 running 값을 false로 변경하더라도,
스레드 B는 자신의 CPU 캐시에 저장된 running 값(true)을 계속 확인한다.
결과적으로 스레드 B는 false로 업데이트된 값을 인식하지 못한다.
volatile로 문제 해결
class SharedData {
private volatile boolean running = true; // volatile 선언
public void stop() {
running = false; // 값 변경이 메인 메모리에 반영
}
public void run() {
while (running) { // 항상 메인 메모리에서 값을 읽음
// 작업 수행
}
System.out.println("Stopped");
}
}해결:
stop() 호출 시, running 값이 즉시 메인 메모리에 기록되고,
다른 스레드가 항상 최신 값을 읽기 때문에, running == false를 정확히 인식한다.
ReentrantLock 내부 동작과 volatile의 역할
- 락 획득 (lock)
- state 변수가 0인지 확인: volatile 덕분에 모든 스레드가 메인 메모리에서 state 값을 읽는다.
- CAS 연산으로 state 값을 변경: 성공하면 락을 획득하고, 현재 스레드 정보를 owner에 기록.
public void lock() {
if (compareAndSwapState(0, 1)) { // CAS로 state를 변경
owner = Thread.currentThread(); // 락 소유자 설정
return;
}
// 실패하면 대기열로 들어감
enqueueAndWait();
}- 락 해제 (unlock)
- 현재 스레드가 락을 소유하고 있는지 확인 (owner 변수).
- state 값을 1 → 0으로 변경: volatile로 선언된 state는 다른 스레드가 즉시 락이 해제되었음을 확인할 수 있다.
public void unlock() {
if (Thread.currentThread() != owner) {
throw new IllegalMonitorStateException("Not the lock owner");
}
state = 0; // 락 해제 (volatile로 선언되어 다른 스레드가 즉시 감지)
owner = null; // 락 소유자 초기화
wakeUpNextThread();
}Lock Support
특정 스레드를 일시 중단하거나 재개시키는 기능을 제공한다.
ReentrantLock은 AbstractQueuedSynchronizer (AQS)라는 기반 클래스를 사용하여 락 상태를 관리한다.
AQS는 FIFO 큐를 사용하여 대기 스레드를 관리하며, 공정성과 비공정성을 지원한다.
공정성(Fairness) 설정
- 공정모드(Fair Mode) : 대기열(FIFO)에 따라 오래 기다린 스레드가 먼저 락을 획득. 차례대로 락을 제공하여 "공정"하게 동작한다. (줄을 지키기)
--> 대기열에서 은행을 차례로 작업을 처리해야하는 시스템에 적합. (은행 창구, 티켓 판매 시스템)- true를 전달하여 공정 모드를 활성화한다. 오래 기다린 스레드가 먼저 락을 획득한다.
ReentrantLock lock = new ReentrantLock(true); // 공정 모드- 비공정모드(Non-Fair Mode) : 대기열을 무시하고 즉시 락을 얻을 수 있는 스레드가 락을 선점. 성능이 더 좋지만 일부 스레드가 계속 기다리는 기아 상태가 발생할 수 있음. (새치기 허용)
--> 락을 빠르게 획득하는 것이 더 중요하거나 일부 스레드가 더 자주 작업을 처리해도 문제가 되지 않는 경우. (실시간 시스템, 성능이 중요한 애플리케이션)- false를 전달하거나 아무것도 지정하지 않으면 기본적으로 비공정 모드로 설정.
- 대기중인 스레드를 무시하고 락을 바로 획득할 수 있는 스레드가 락을 선점.
ReentrantLock lock = new ReentrantLock(false); // 비공정 모드
주의사항
- Deadlock: 락을 명시적으로 해제하지 않으면 데드락이 발생할 수 있으므로, 항상 finally 블록에서 unlock()을 호출해야 한다.
- 성능: 공정 락은 비공정 락에 비해 성능이 떨어질 수 있다.
- 적절한 사용: 단순한 동기화에는 synchronized 키워드가 더 적합할 수 있다.
3. ConcurrentHashMap
ConcurrentHashMap은 Java에서 제공하는 스레드 안전한(HashMap과 비슷한) 병렬 Map 구현체.
멀티스레드 환경에서 HashMap을 사용할 때 발생할 수 있는 동시성 문제를 해결하기 위해 설계되었음.
ConcurrentHashMap의 주요 특징
스레드 안전 (Thread-safe)
여러 스레드가 동시에 읽고 쓰는 작업을 수행해도 데이터의 일관성이 유지된다.
락 분할 (Lock Striping)
전체 Map에 락을 거는 대신, 버킷(bucket, 특정 범위의 데이터를 저장하는 단위) 단위로 락을 분할하여 성능을 향상시킨다.
효율적인 동시성
락 분할 덕분에 put, remove 등 쓰기 작업이 병렬로 처리된다.
읽기 작업(get)은 대부분 락 없이 수행되며, 쓰기 작업만 필요한 경우에만 락이 사용된다.
Null 키/값 허용하지 않음
ConcurrentHashMap은 null 키 또는 값을 허용하지 않는다.
(HashMap은 null 키와 값을 허용한다.)
언제 ConcurrentHashMap을 사용하는가?
멀티스레드 환경에서 안전한 Map이 필요할 때
- 여러 스레드가 동시에 데이터를 읽거나 수정해야 하는 경우.
예: 캐싱, 세션 관리, 상태 공유.
읽기 작업이 빈번하지만 쓰기 작업도 간혹 필요한 경우:
- 동시 읽기가 많고, 쓰기가 적은 경우 ConcurrentHashMap이 높은 성능을 발휘한다.
HashTable의 대체:
- HashTable은 전체 Map에 대해 락을 거는 방식으로 동작하기 때문에 성능이 낮다.
ConcurrentHashMap은 더 세밀한 락 분할을 사용하여 더 높은 동시성을 제공합니다.
ConcurrentHashMap 내부 동작
- 락 분할 (Segmented Locking)
ConcurrentHashMap은 데이터를 버킷(bucket)으로 나누고, 각 버킷에 대해 별도의 락을 사용한다.
이 덕분에 다른 버킷에 있는 데이터는 서로 독립적으로 읽고 쓸 수 있다.
각 버킷은 HashMap처럼 동작하며, 락은 쓰기 작업(예: put, remove)이 수행될 때만 사용된다.
읽기 작업(예: get)은 대부분 락 없이 수행된다. - CAS (Compare-And-Swap)
일부 작업에서는 락 대신 CAS를 사용하여 성능을 더욱 향상시킨다.
CAS는 값의 상태를 비교하고, 예상 값이 일치하면 원자적으로 변경한다. - ConcurrentHashMap의 구조
ConcurrentHashMap은 내부적으로 배열과 연결 리스트 또는 트리를 조합하여 데이터를 저장한다.
배열: 버킷들을 저장.
연결 리스트 또는 트리: 각 버킷의 충돌 항목을 저장.
Java 8 이후: 특정 조건(충돌 항목이 많을 때)에서는 연결 리스트를 트리(BST)로 변환하여 검색 성능을 향상. - 락 사용 예시
put, remove: 버킷 단위로 락을 사용.
get: 대부분 락 없이 메모리 가시성을 보장하며 읽기.
ConcurrentHashMap 내부 메서드
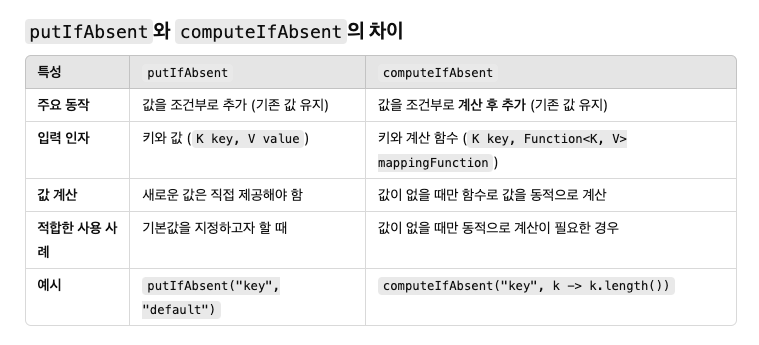
putIfAbsent
putIfAbsent(K key, V value)는 Map에 해당 키가 없을 경우에만 값을 추가한다.
키가 이미 존재하면 기존 값을 유지한다.
키가 존재하지 않으면 지정된 값을 추가하고 추가된 값을 반환한다.
사용 목적 : 키의 존재 여부를 확인하고 값을 설정하는 동작을 스레드 안전하게 수행하기 위해 사용된다.
- 키가 없으면 지정된 값을 추가.
- 값이 항상 고정적일 때 적합.
computeIfAbsent
computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction)는 Map에 해당 키가 없을 경우, 값을 계산하여 추가한다.
값이 없을 때, mappingFunction을 사용하여 값을 계산하고 Map에 추가.
키가 이미 존재하면 기존 값을 반환.
사용 목적 : 값이 없을 경우 동적으로 계산하여 추가하는 작업을 스레드 안전하게 수행. 계산이 필요한 값을 동적으로 생성하거나 초기화하는 로직에 사용.
- 키가 없으면 값을 계산하여 추가.
- 값이 동적으로 생성되거나 초기화 로직이 필요한 경우 적합.
=> 일반적으로 computeIfAbsent가 더 효율적이고 권장됨
ReentrantLock + ConcurrentHashMap
ReentrantLock과 ConcurrentHashMap을 사용하여 특정 사용자 ID에 대해 락을 관리할 수 있다. 이 방식은 높은 동시성을 보장하면서도 성능 최적화에 유리하다.
- ConcurrentHashMap은 키(id)별로 동시 작업을 처리. 각 키가 서로 다른 데이터를 나타내므로, A, B, C 세 사람이 동시에 자신의 데이터를 읽거나 쓰는 작업을 할 때 충돌하지 않는다.
- ReentrantLock은 특정 사용자(A)에 대해 동기화된 작업(충전 -> 사용)을 보장한다.
예시 코드
private final ConcurrentHashMap<Long, ReentrantLock> lockMap = new ConcurrentHashMap<>();
public UserPoint chargePoints(long id, long chargeAmount) {
chargeValidations(id, chargeAmount);
// 사용자 ID별로 락 생성 또는 가져오기
lockMap.putIfAbsent(id, new ReentrantLock());
ReentrantLock lock = lockMap.get(id);
lock.lock();
try {
long prevPoint = 0;
UserPoint userPoint = userPointTable.selectById(id);
if (userPoint != null){
prevPoint = userPoint.point();
}
UserPoint result = userPointTable.insertOrUpdate(id, chargeAmount + prevPoint);
pointHistoryTable.insert(id, chargeAmount, TransactionType.CHARGE, System.currentTimeMillis());
return result;
} finally {
lock.unlock();
}
}4. ConcurrentLinkedQueue
Java에서 제공하는 스레드 안전한 비차단(Non-blocking) 큐
- FIFO (First-In-First-Out) 방식으로 요소를 저장하고 처리.
- 내부적으로 Linked Node 구조를 사용하여 데이터를 관리.
- CAS(Compare-And-Swap) 연산을 활용해 락 없이 동시성을 보장.
ConcurrentLinkedQueue의 주요 특징
비차단(Non-blocking) 큐:
락을 사용하지 않고 동시성을 관리하며, 성능이 뛰어남.
CAS를 기반으로 구현되어 동시 작업에서 성능 우수.
FIFO 순서 보장:
데이터가 들어간 순서대로 처리.
유연한 크기:
큐 크기에 제한이 없으며, 메모리가 허용하는 한 데이터를 계속 추가 가능.
스레드 안전:
여러 스레드가 동시에 삽입(offer) 및 제거(poll) 작업을 수행해도 데이터의 무결성을 유지.
import java.util.concurrent.ConcurrentLinkedQueue;
public class ConcurrentLinkedQueueExample {
public static void main(String[] args) {
ConcurrentLinkedQueue<String> queue = new ConcurrentLinkedQueue<>();
// 요소 추가
queue.offer("A");
queue.offer("B");
queue.offer("C");
System.out.println(queue); // [A, B, C]
// 요소 제거
System.out.println(queue.poll()); // A (제거 및 반환)
System.out.println(queue); // [B, C]
// 요소 확인
System.out.println(queue.peek()); // B (확인만, 제거하지 않음)
}
}
ConcurrentHashMap vs ConcurrentLinkedQueue
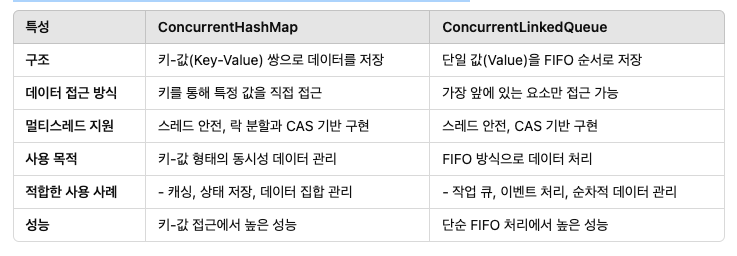
ConcurrentHashMap과 ConcurrentLinkedQueue: 적절한 사용 시기
ConcurrentHashMap이 적합한 경우
- 데이터를 키-값 쌍으로 관리해야 하는 경우.
- 특정 키에 대해 동시 읽기 및 쓰기 작업이 빈번한 경우.
상태 저장, 캐싱, 사용자 데이터 관리 등.
사용자별 상태 저장:
ConcurrentHashMap<String, Integer> userScores = new ConcurrentHashMap<>();
userScores.put("Alice", 50);
userScores.put("Bob", 75);
System.out.println(userScores.get("Alice")); // 50ConcurrentLinkedQueue가 적합한 경우
- 데이터가 순차적으로 처리되어야 하는 경우.
- 작업 큐, 메시지 대기열, 이벤트 큐 등.
- 데이터 접근 순서가 중요하고, FIFO 방식이 필요한 경우.
작업 큐 처리:
ConcurrentLinkedQueue<String> taskQueue = new ConcurrentLinkedQueue<>();
taskQueue.offer("Task1");
taskQueue.offer("Task2");
System.out.println(taskQueue.poll()); // Task1ConcurrentHashMap과 ConcurrentLinkedQueue를 함께 사용하는 사례
예제: 사용자별 작업 관리
- ConcurrentHashMap으로 사용자별 작업 큐를 관리.
- ConcurrentLinkedQueue로 각 사용자의 작업을 FIFO 방식으로 처리.
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentLinkedQueue;
public class UserTaskManager {
private final ConcurrentHashMap<String, ConcurrentLinkedQueue<String>> userTasks = new ConcurrentHashMap<>();
public void addTask(String user, String task) {
userTasks.computeIfAbsent(user, key -> new ConcurrentLinkedQueue<>()).offer(task);
}
public String getNextTask(String user) {
ConcurrentLinkedQueue<String> tasks = userTasks.get(user);
return (tasks != null) ? tasks.poll() : null;
}
public static void main(String[] args) {
UserTaskManager manager = new UserTaskManager();
manager.addTask("Alice", "Task1");
manager.addTask("Alice", "Task2");
manager.addTask("Bob", "Task3");
System.out.println(manager.getNextTask("Alice")); // Task1
System.out.println(manager.getNextTask("Bob")); // Task3
}
}정리!
ConcurrentHashMap:
키-값 데이터 관리에 적합.
캐싱, 상태 저장, 빠른 데이터 접근이 필요한 경우 사용.
ConcurrentLinkedQueue:
FIFO 방식 데이터 처리에 적합.
작업 대기열, 이벤트 처리 등 순차적 데이터 작업이 필요한 경우 사용.
둘 중 어떤 방식이 적절한지 결정하려면:
데이터가 키-값 관계인지(FIFO가 중요하지 않은 경우): ConcurrentHashMap.
데이터가 순차적 처리 순서가 중요한지(FIFO 필요): ConcurrentLinkedQueue.
