🎈Scrapy란?
Scrapy 공식 사이트에서는 "웹사이트에서 필요한 데이터를 추출하기 위한 오픈 소스 및 협업 프레임워크로 빠르고 간단하면서도 확장성이 좋다" 라고 설명
기존에는 Selenium을 이용해서 크롤링을 진행했으나 쉽고 빠르게 익힐 수 있는게 장점이지만 메모리를 많이 잡아먹는 크리티컬한 단점으로 인해 대규모 수집작업에 사용하기 망설이고 있는 상황에서 좋은 기회를 얻었다.
📃공식문서
공식 문서와 구글링을 통해 간단한 네이버 뉴스의 언론사와 기사 제목을 가져와 보았다.
🛒 설치 및 크롤링
1. 터미널에 scrapy 설치부터 시작
pip install scrapy2. 프로젝트 생성 및 구조
scrapy startproject tutorial(프로젝트_이름)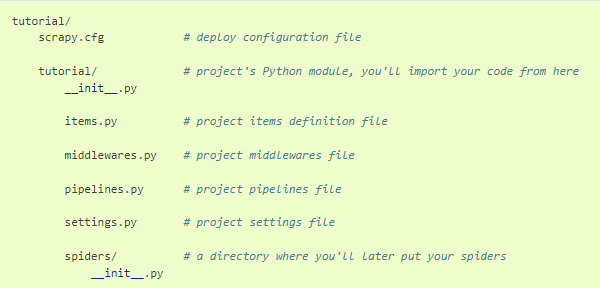
3. 사이트 연결 확인
scrapy shell "https://new.naver.com"
# 작은따옴표를 쓰게되면 https 인식 못하는 경우가 있음
위와 같은 결과를 터미널에서 확인하면 사이트 접속 성공
하지만 바로 되지 않는 경우가 발생할 수 있음(경험담)
네이버의 robots.txt에서 네이버 봇을 제외한 나머지는 수집 금지하는 약속?을 해놓았기 때문
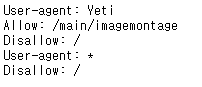
scrapy에서 robots.txt를 준수할지 말지 설정할 수 있음
이를 무시하기 위해서는 setting.py에서 아래 변수 부분을 True에서 Flase로 바꾸기
ROBOTSTXT_OBEY = False변경 후 위의 shell이 포함된 명령어 입력후 response를 출력하여 사이트 연결이 잘 되는지 확인
print(response)
4. 가볍게 데이터 가져와 지는지 확인해보기

분야별로 나누어 놓은 탭부분을 가져오고자 한다.
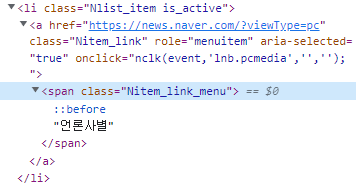
개발자 도구를 통해 해당하는 부분을 가져오게되면 위와 같은데 scrapy는 css selector와 xpath 둘 다 지원한다.
# 둘 다 같은 경로를 나타냄
response.css('a.Nitem_link span.Nitem_link_menu ::text').getall()
response.xpath('/html/body/section/header/div[2]/div/div/div[1]/div/div/ul/li/a/span/text()').getall()
5. spider를 만들어보자
scrapy는 spiders폴더에 spider 파이썬 파일을 만들어서 크롤링하는데 기본적 세팅을 해주는 명령어를 입력해보자
본인은 IT/과학 부분이 흥미로운 부분이라서 해당 URL를 가져왔다.
scrapy genspider newsbot "http://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1=105"
# ex) scrapy genspider 스파이더이름 URL해서 결론적으로
import scrapy
class NewsbotSpider(scrapy.Spider):
name = 'newsbot'
allowed_domains = ['news.naver.com']
start_urls = ["http://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1=105"]
def parse(self, response):
titles = response.css('div.cluster_text a::text').getall()
companies = response.css('div.cluster_text_press::text').getall()
for item in zip(companies, titles):
summery = {
'company' : item[1].strip(),
'title' : item[0].strip(),
}
yield summery다음과 같이 만들었으며 실행하는 코드와 결과는
scrapy crawl newsbot
# ex) scrapy crawl 스파이더이름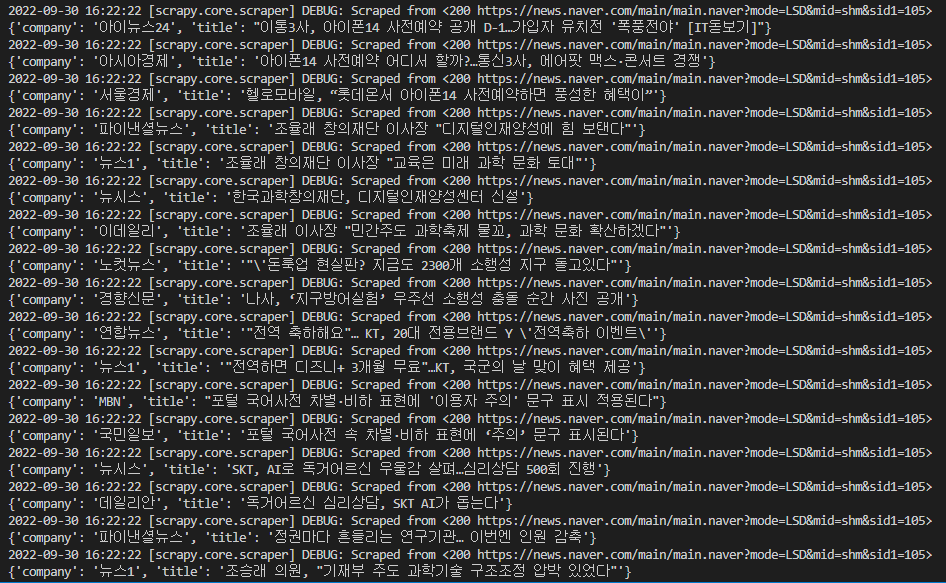
이렇게 가져오는 것을 볼 수 있다.
6. 간단한 json으로 저장
spider 실행할 때 옵션을 넣어주면 쉽게 저장을 할 수 있다.
scrapy crawl newsbot -o news.json
# ex) scrapy crawl 스파이더이름 -o 파일명.json혹시 저장하고 나서 글자가 깨져있다면 이 또한 setting.py에서
FEED_EXPORT_ENCODING = 'utf-8'아래 부분에 원하는 인코딩 양식으로 기입하여 추가해주면 된다.

👍