
Kubeflow 모르면 사서 고생이다...
Kubeflow 란?
Google Cloud에서 시작되었으며, 머신러닝 워크플로우를 Kuberentes 기반 엔진에서 간소화하기 위한 오픈소스 프로젝트.
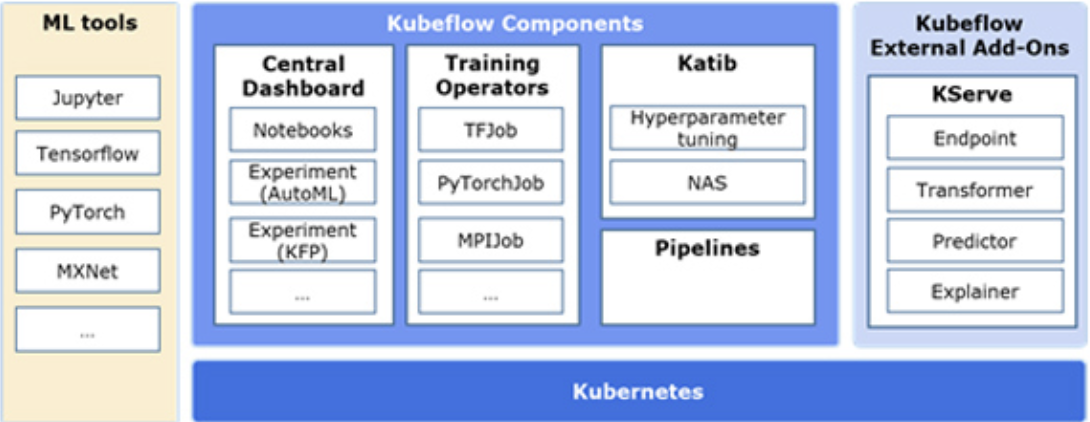
: Kubeflow의 기본적인 구조. 크게 다음과 같은 구성요소를 지니고 있다.
Components of Kubeflow
- Kubeflow Pipelines: Docker 컨테이너를 이용한 이식성 높고 확장가능한 워크플로우를 제공하는 플랫폼
- Katib: AutoML을 위한 k8s-native 프로젝트. 하이퍼파라미터 튜닝과 NAS (Neural Architecture Search)를 지원함
- Training Operators: Kubeflow를 통해 학습할 수 있도록 지원하는 Operator로, Tensorflow / Pytorch / Apache MXNet / MPI 관련 작업을 수행할 수 있도록 도와줌
- Central Dashboard: 클러스터 안해서 배포한 Kubeflow에 UI를 통해 쉽게 접근할 수 있도록 도와주는 컴포넌트
ML Challenges
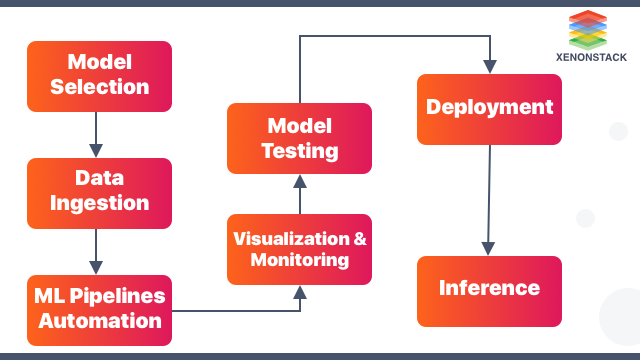
원래 하나의 ML Pipeline을 구축하기 위해서는 다음과 같은 수작업이 필요했다.
- ML 개발 환경 구축
- 모델 학습을 위한 컴퓨팅 리소스 스케일링
- 모델 API 설계 및 모델 서빙
- 생명주기 관리
- Loss를 최소화 하기 위한 지속적인 모델 학습 (최악의 경우, 영원히 모델을 최적화하지 못할 수도 있음)
⇒ 머신러닝 전문가와 DevOps 전문가 없이 이러한 작업들을 일일이 하는 것은 매우 힘든 일.
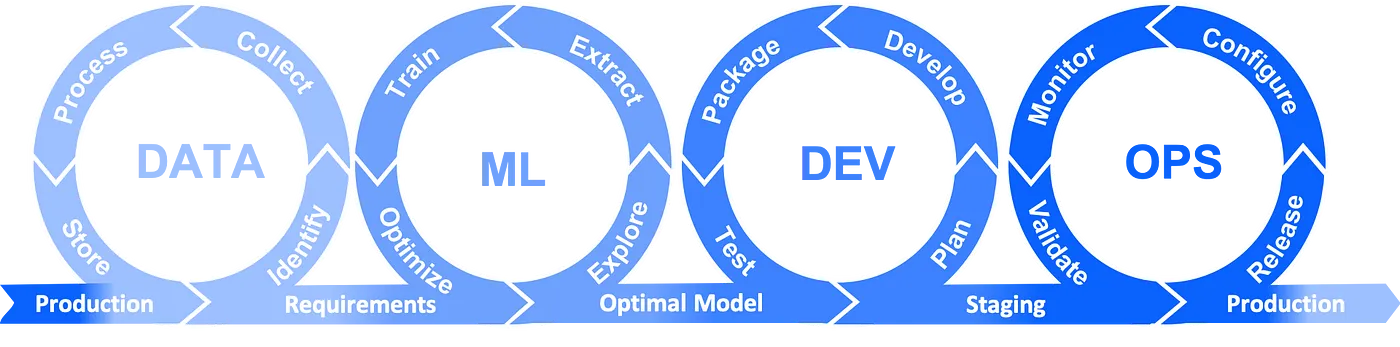
이러한 Challenges를 극복하고자 등장한 점이 바로 ML Automation이며, Kubeflow는 ML Automation을 실현하고자 등장한 프로젝트다.
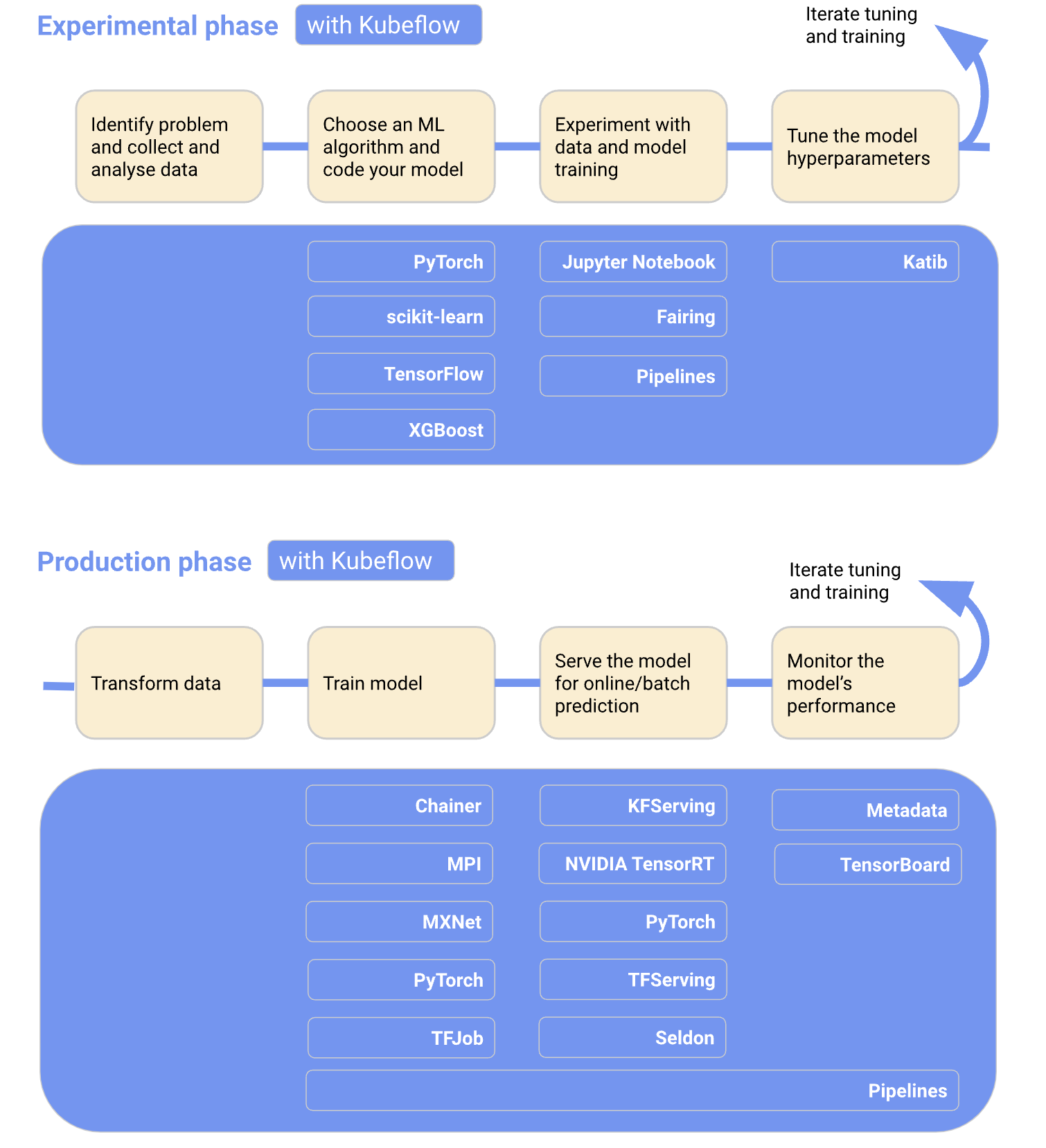
: 모델 선정 및 학습 과정에 도움을 주는 전반적인 Tool들을 제공함으로써 더욱 편리하게 ML Model Training & Deployment를 가능하게 해준다.
Automation with Kubeflow
: Kubeflow는 다양한 기능을 통해 다음과 같은 ML Automation을 실현시킨다.
- 자동화된 ML Code의 컨테이너화
- Kubernetes 클러스터의 생명 주기 자동화
- 오토스케일링
- 분산 학습 자동화
- 자동화된 모델 최적화
- 자동화된 ML metadata 및 로그 관리
- ML Workflow및 Kubernetes Pipeline의 자동화
위에서 기술한 모든 자동화 과정을 지원하는 Tool들이 Kubeflow에 다 있으므로, Tool들만 잘 이용하면 자동화를 손쉽게 실현시킬 수 있다.
ML Code Containerization
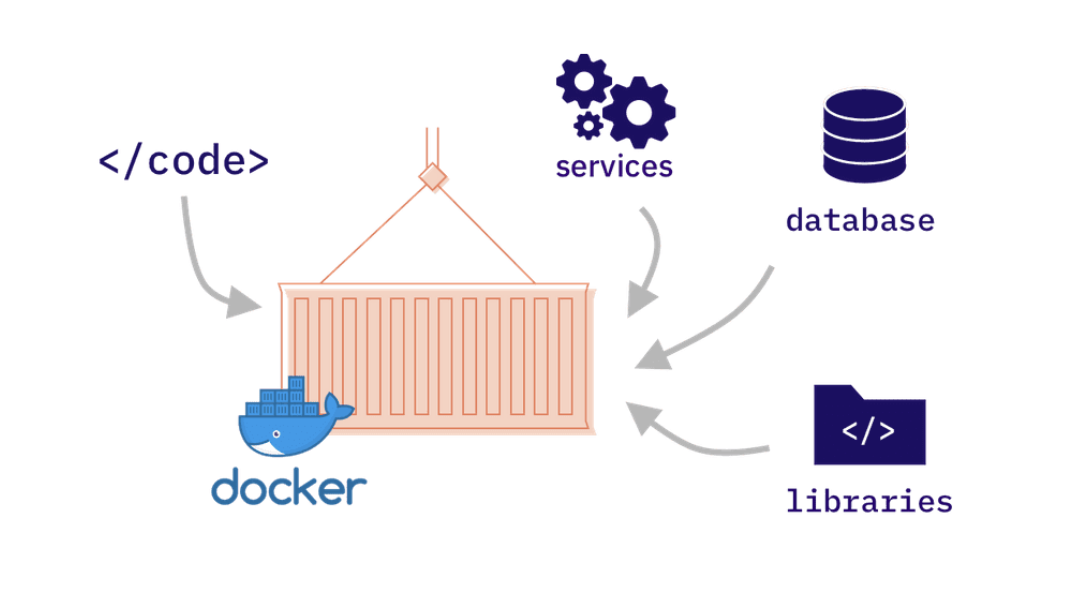
: 컨테이너 환경에서 모델 학습이 이루어지려면 이에 필요한 모든 실행파일들과 라이브러리, 설정 파일들이 필요하다.
💡 만일 모델이 지속적으로 업데이트 된다면??⇒ 이런 ML Code들과 관련 파일들을 자동으로 컨테이너화 하는 것이 Kubeflow Fairing!
Kubeflow Fairing
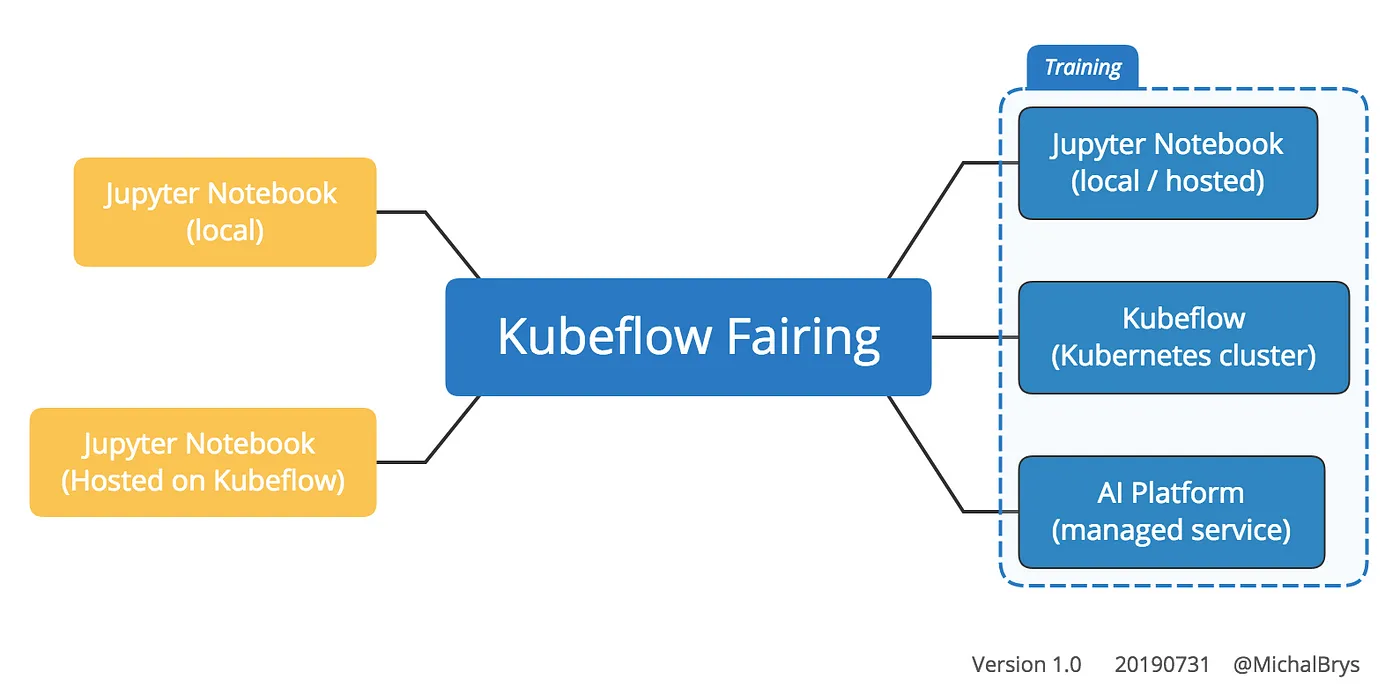
: Kubeflow가 설치된 환경에서 ML Model을 손쉽게 학습 및 배포할 수 있는 파이썬 패키지.
Build, Train, Deploy를 원격으로 수행할 수 있다. 한마디로, ML Code를 컨테이너하기 위해 이미지를 빌드하고 push하고, .yaml 파일 만들고 실행하고… 이걸 단 코드 몇 줄로 수행이 가능하다.
특징:
- ML Code를 손쉽게 컨테이너화 및 배포할 수 있음
- 클라우드 API에 대한 별도의 전문적인 지식 없이 모델을 학습시킬 수 있는 API 지원
Fairing 예시:
import os
import tensorflow as tf
from kubeflow import fairing
# Setting up google container repositories (GCR) for storing output containers
# You can use any docker container registry istead of GCR
DOCKER_REGISTRY = 'localhost:5000'
fairing.config.set_builder(
'append',
base_image='gcr.io/kubeflow-images-public/tensorflow-2.0.0a0-notebook-gpu:v0.7.0',
registry=DOCKER_REGISTRY,
push=True)
fairing.config.set_deployer('job',
namespace='test')
def train():
tf.print(tf.constant(os.environ['PATH']))
if __name__ == '__main__':
print('local train()')
train()
print('remote train()')
remote_train = fairing.config.fn(train)
remote_train()- fairing.config.set_deployer('job', namespace='test')
: Kubeflow에서 Job 형태로 실행 - train(): Local에서 Train 진행
- fairing.config.fn(train): TF-JOB에게 PATH 출력
(fairing) root@jyhwang-XPS-15-9570:/home/jyhwang/fairing# python fairing_append_simple_job.py
# Local Train 실행
local train()
/root/miniconda3/envs/fairing/bin:/root/miniconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games
# Docker Image만들고 Push
remote train()
[W 191217 16:03:35 function:49] The FunctionPreProcessor is optimized for using in a notebook or IPython environment. For it to work, the python version should be same for both local python and the python in the docker. Please look at alternatives like BasePreprocessor or FullNotebookPreprocessor.
[I 191217 16:03:35 config:123] Using preprocessor: <kubeflow.fairing.preprocessors.function.FunctionPreProcessor object at 0x7fde9f42cb50>
[I 191217 16:03:35 config:125] Using builder: <kubeflow.fairing.builders.append.append.AppendBuilder object at 0x7fde66cdbd50>
[I 191217 16:03:35 config:127] Using deployer: <kubeflow.fairing.builders.append.append.AppendBuilder object at 0x7fde66cdbd50>
[W 191217 16:03:35 append:50] Building image using Append builder...
[I 191217 16:03:35 base:105] Creating docker context: /tmp/fairing_context_39wi82qz
[W 191217 16:03:35 base:92] /root/miniconda3/envs/fairing/lib/python3.7/site-packages/kubeflow/fairing/__init__.py already exists in Fairing context, skipping...
[I 191217 16:03:35 docker_creds_:234] Loading Docker credentials for repository 'gcr.io/kubeflow-images-public/tensorflow-2.0.0a0-notebook-gpu:v0.7.0'
[W 191217 16:03:38 append:54] Image successfully built in 2.427372837002622s.
[W 191217 16:03:38 append:94] Pushing image localhost:5000/fairing-job:E11C94...
[I 191217 16:03:38 docker_creds_:234] Loading Docker credentials for repository 'localhost:5000/fairing-job:E11C94'
[W 191217 16:03:38 append:81] Uploading localhost:5000/fairing-job:E11C94
[I 191217 16:03:38 docker_session_:284] Layer sha256:b5ff3e3cab27890dfd0b520eeeaf68baaf0b7e957bea0f567af3e6ea8e15c6ed pushed.
...
# TF-JOB 실행
[W 191217 17:06:20 job:90] The job fairing-job-dhvh6 launched.
[W 191217 17:06:20 manager:227] Waiting for fairing-job-dhvh6-xfscv to start...
[W 191217 17:06:20 manager:227] Waiting for fairing-job-dhvh6-xfscv to start...
[W 191217 17:06:20 manager:227] Waiting for fairing-job-dhvh6-xfscv to start...
[I 191217 17:06:23 manager:233] Pod started running True
...
# 원격에서 Train() 실행
2019-12-17 08:06:23.882515: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1304] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 3117 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1050 Ti with Max-Q Design, pci bus id: 0000:01:00.0, compute capability: 6.1)
/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
[W 191217 17:06:24 job:162] Cleaning up job fairing-job-dhvh6...⇒ 원격으로 image를 만들고 Push 한 후 학습을 시키면, Registry가 생기고 배포가 된다.
Lifecycle Automation & Distributed Learning
: K8s Cluster는 기본적으로 휘발성 환경이기 때문에 모델의 학습 등의 머신러닝 과정 등이 문제없이 돌아가도록 보장하기 어렵다.
⇒ k8s의 파드는 매우 동적이고 재시작이 빈번하게 일어나므로 각 학습 과정이 제대로 되고 있는 지 check 해야 함.
Operator (TF Operator / PyTorch Operator …)
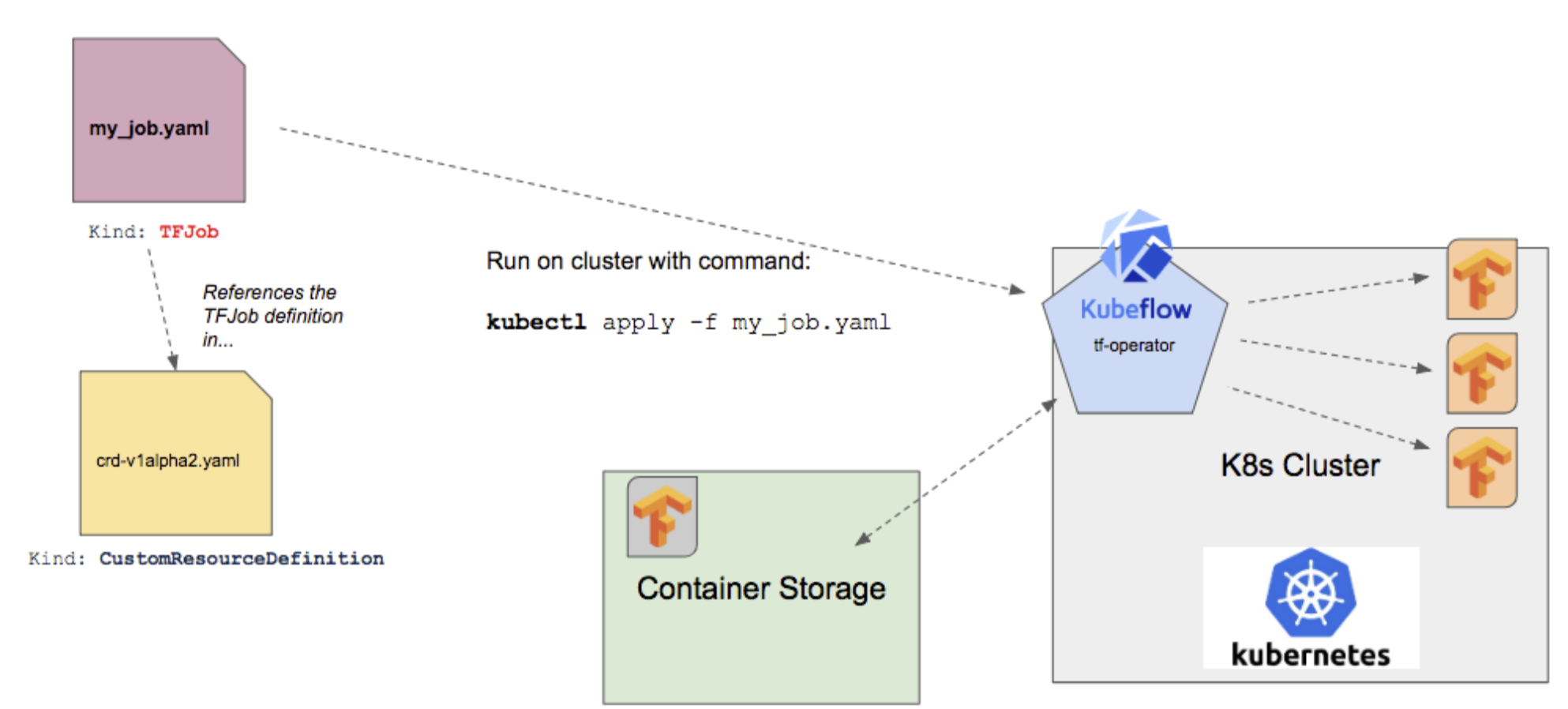
: TF-Job 등, Training Job가 실행되면 이와 관련된 Operator가 작동하여 다음과 같은 역할을 수행한다.
- Lifecycle 관리: Yaml 파일로 선언하여 파드를 통한 K8s Cluster의 Life Cycle을 관리한다.
- 상태 관리: 애플리케이션이 제대로 작동하고 있는지 Health Check를 함으로써 정상적으로 동작하도록 한다.
- 복잡성 감소: 애플리케이션의 내부적인 구조나 구체적인 동작을 알 필요 없이 손쉽게 실행할 수 있도록 함.
ex) TFOperator:
apiVersion: kubeflow.org/v1
kind: TFJob
metadata:
generateName: tfjob
namespace: your-user-namespace
spec:
tfReplicaSpecs:
PS:
replicas: 1
restartPolicy: OnFailure
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
containers:
- name: tensorflow
image: gcr.io/your-project/your-image
command:
- python
- -m
- trainer.task
- --batch_size=32
- --training_steps=1000
Worker:
replicas: 3
restartPolicy: OnFailure
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
containers:
- name: tensorflow
image: gcr.io/your-project/your-image
command:
- python
- -m
- trainer.task
- --batch_size=32
- --training_steps=1000- tfReplicaSpecs: TensorFlow의 파드의 스펙을 정의하는 필드
- 여타 K8s Cluster의 Spec을 정의하는 필드와 거의 유사하다. 다만, 어떤 종류의 Operator를 사용하는지 명시하기 위해 tfReplicaSpecs를 사용
- 보통 TensorFlow의 job는 Chief, Ps, Worker, Evaluator의 프로세스가 있으며 여기서는 Ps, Worker의 spec만 명시했다.
- Chief: 학습과 작업 수행을 오케스트레이션 하는 역할. 분산 학습을 달성하기 위해 파드들을 전반적으로 관리한다.
- Ps: Parameter Server. 모델 파라미터를 저장하는 분산 저장소를 제공 (Replicas: 1 ⇒ 하나의 파드만 사용하여 저장소 제공)
- Worker: 실질적인 모델 학습 작업을 수행하는 역할
- Evaluator: 모델이 학습이 잘 되어있는 지 확인하는 지표를 계산한다.
Autoscaling
: 사용자의 요청이 지나치게 많아지면 ML 추론 서버에 과부하가 생기며, 이로 인한 여러가지 문제점이 발생할 수 있음
⇒ Kubeflow 트래픽에 따른 추론 서버의 Scaling 자동화를 지원하는 기능이 탑재되어 있다.
Knative
보통 Serveless라 하면 강한 벤더 의존성 (AWS Lambda, Azure Functions, Google Cloud Functions, IBM Cloud Functions)을 지니고 있음.
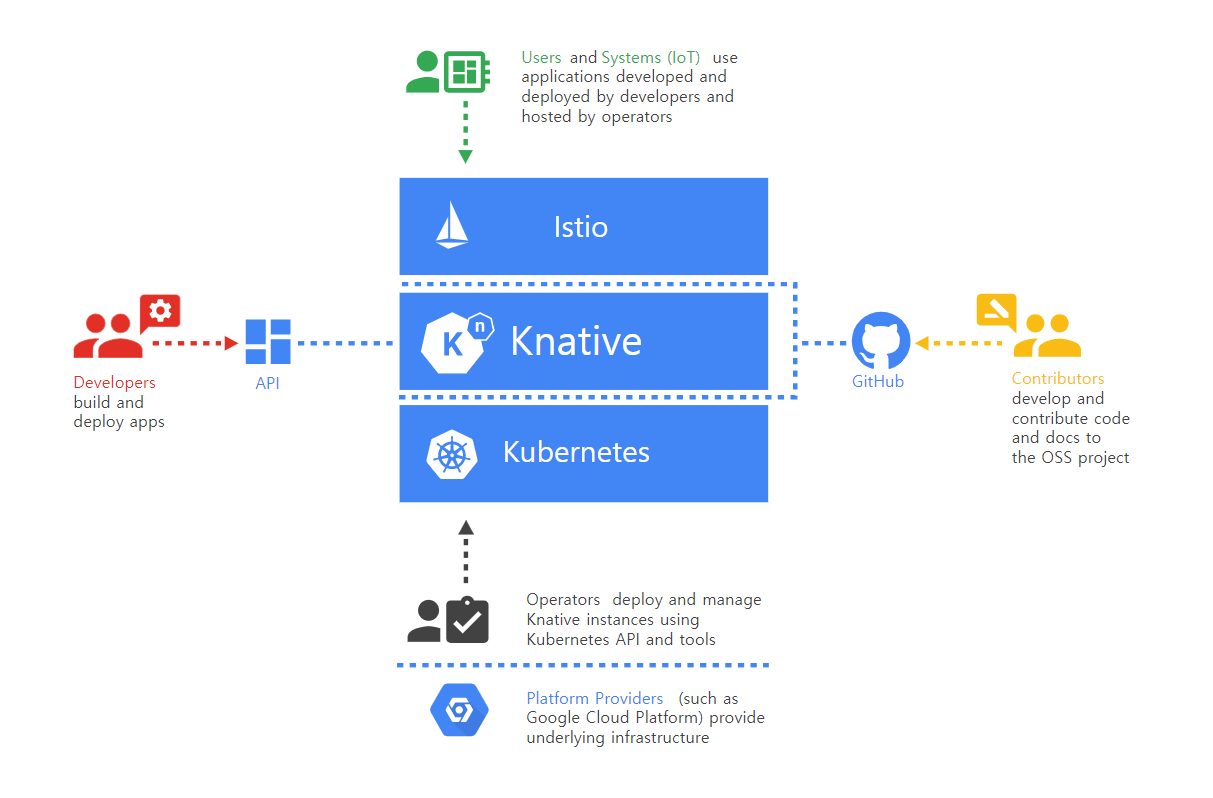
: Stateless app 및 이벤트 핸들링을 위한 모델 제공, 컨테이너를 빌드할 수 있는 환경을 제공하는데, 이 때 Knative에 탑재된 Istio는 다음과 같은 역할을 한다.
Istio
- 보통 MSA를 채택하는 각 서비스들은 복잡한 네트워크 통신을 함
- Istio는 마이크로서비스 아키텍처를 채택하고 있는 애플리케이션의 각 서비스간 통신을 중앙에서 관리하고 보안을 유지해줌
- Knative로 오는 트래픽들을 올바르게 라우팅해줌.
⇒ 즉 추론 서버를 운용할 때, K8s 클러스터를 Istio 기반 라우팅을 통해 효율적이고 빠른 네트워킹 시스템을 구축함
KServe with Knative
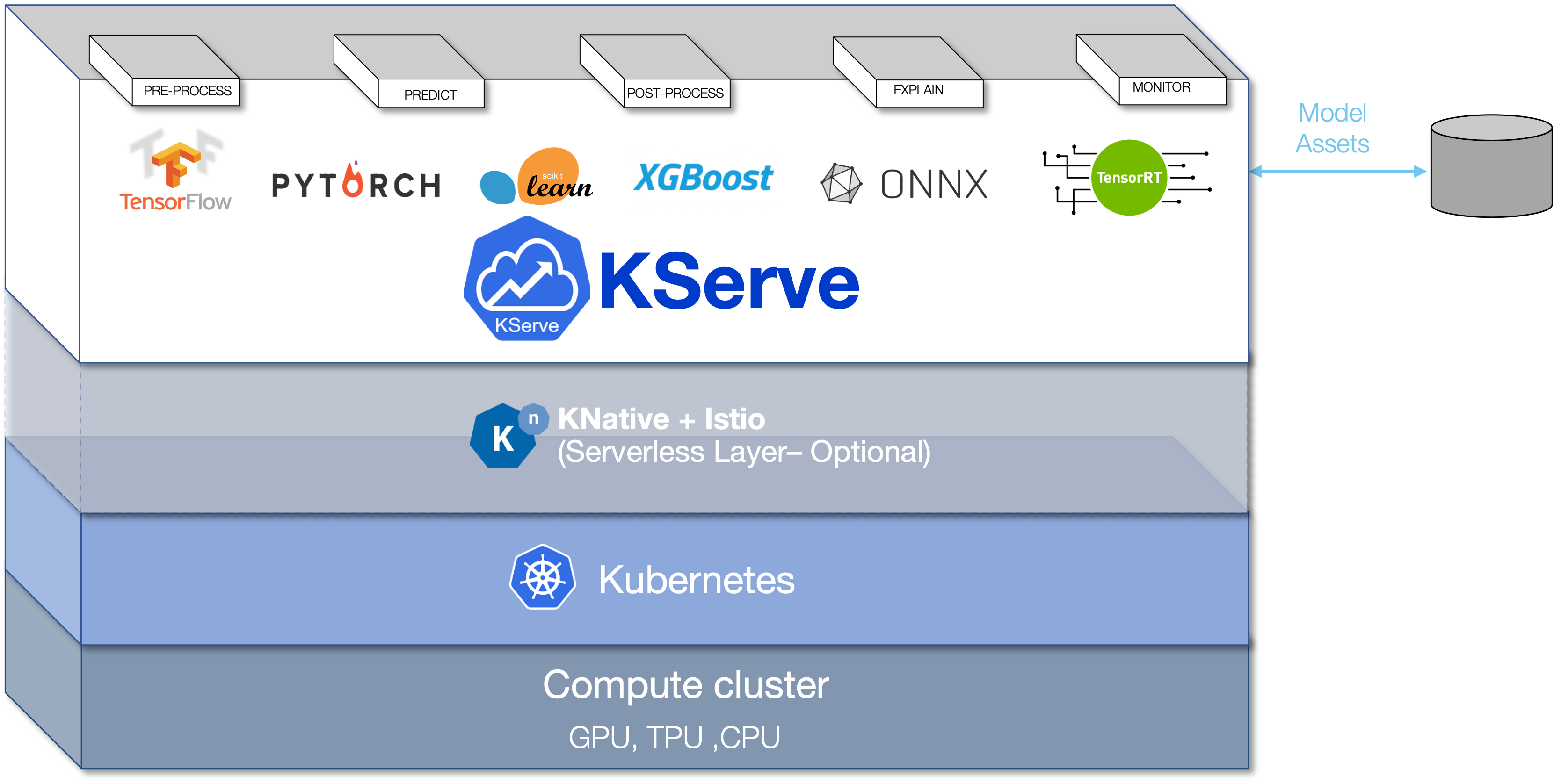
: Kubeflow에서 제공하는 다양한 추론 프레임워크 (Tensorflow, PyTorch, ONXX 등)를 위한 인터페이스 제공 및 k8s를 통한 서버리스 추론 Tool
⇒ 어느 위치에 모델을 저장하고, 이걸 InferenceService라는 커스텀 리소르를 배포하면, 알아서 Pod에 모델을 제공해주고 API도 자동으로 제공해준다.
- Knative를 사용하니 Serverless Inference가 가능해짐
- Istio로 인해 API를 일일이 만들 필요 없이 엔드포인트 관리가 정말로 쉬워짐
- InferenceService라는 manifest 하나만으로 predict, pre/postprocessing, monitoring, explain 등의 동작을 추가하거나 빼는 등 여러가지 형태로 배포할 수 있음.
- Kubernetes 기반 Add-on 이므로 Autoscaling을 지원한다.
How does it work (Kserve)
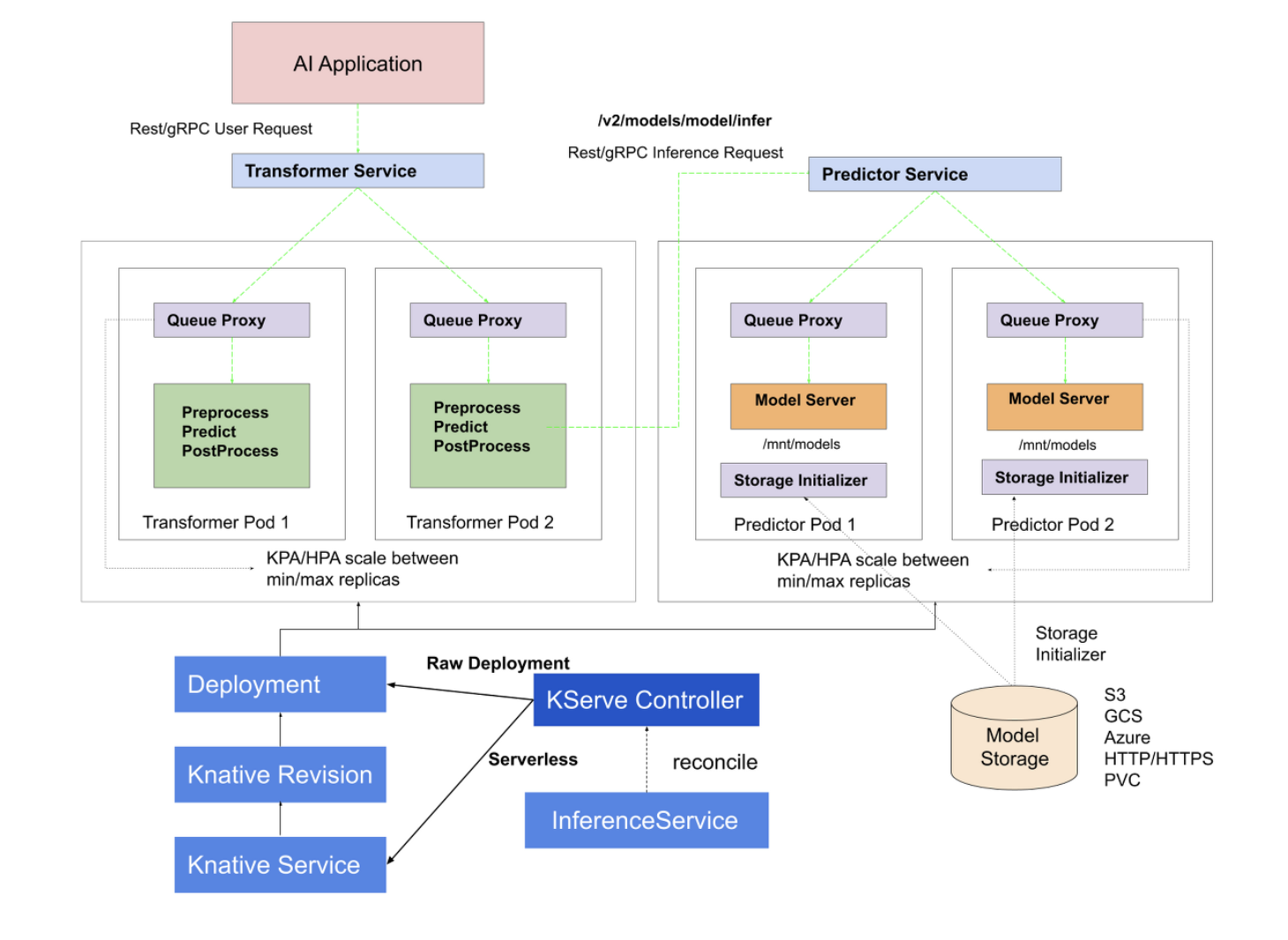
(잘 보면 Transformer Service와 Predictor Service에 연결된 두 종류의 Replicaset들이 min/max replicas 사이에서 Scaling을 한다고 적혀있다.)
- HTTP/gRPC로 사용자가 추론 요청을 보냄
- Transformer(모델 아님, Pod 이름) Pod에는 두 개의 Container (Queue Proxy: 서비스의 요청을 측정하거나 제한하는 Container, Processing Container) 가 있으며 이를 통해 전처리가 수행됨
- 전처리 결과는 Predictor Pod로 보내짐
- Predictor Pod에는 세 개의 컨테이너가 있으며 Storage initializer container를 통해 모델을 마운트 하고, Predict(추론)를 수행함
- 그 후 다시 Transformer Pod로 결과가 전송되고, 이후 후처리를 한 후 다시 반환한다.
- 사용자가 최종 결과를 받아 온다.
⇒ 이 모든 것이 InferenceService라는 Manifest 파일 하나만으로 끝남
InferenceService:
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "sklearn-iris"
spec:
predictor:
model:
modelFormat:
name: sklearn
storageUri: "gs://kfserving-examples/models/sklearn/1.0/model"
EOF실제 구동:
KServe 이 보다 더 쉬운 ML Model Serving 은 없다.
Automated Model Optimization
: 하이퍼파라미터 튜닝 및 모델 아키텍쳐 검색은 계속 시도하면서 고쳐 나가거나 조정해야 하는 등, 여러가지 복잡한 문제점들이 많음.
Katib
: 자동으로 최적화 된 파라미터를 찾고, NAS (Neural Architecture Search) 지원 및 하이퍼파라미터를 최적화하는 Kubeflow의 Add-on;
Automated Hyperparameter Tuning
보통 하이퍼파라미터라면 다음과 같은 전체 프로세스의 상위 변수들을 조절한다:
- Learning Rate
- 신경망의 레이어 갯수
- 각 레이어마다 노드의 갯수
⇒ 이걸 자동으로 설정해준다는 의미. 즉, 최적화된 하이퍼파라미터를 일일이 모델을 학습시키면서 조정할 필요 없이, 알아서 돌려보고 알아서 Best Value를 설정해준다.
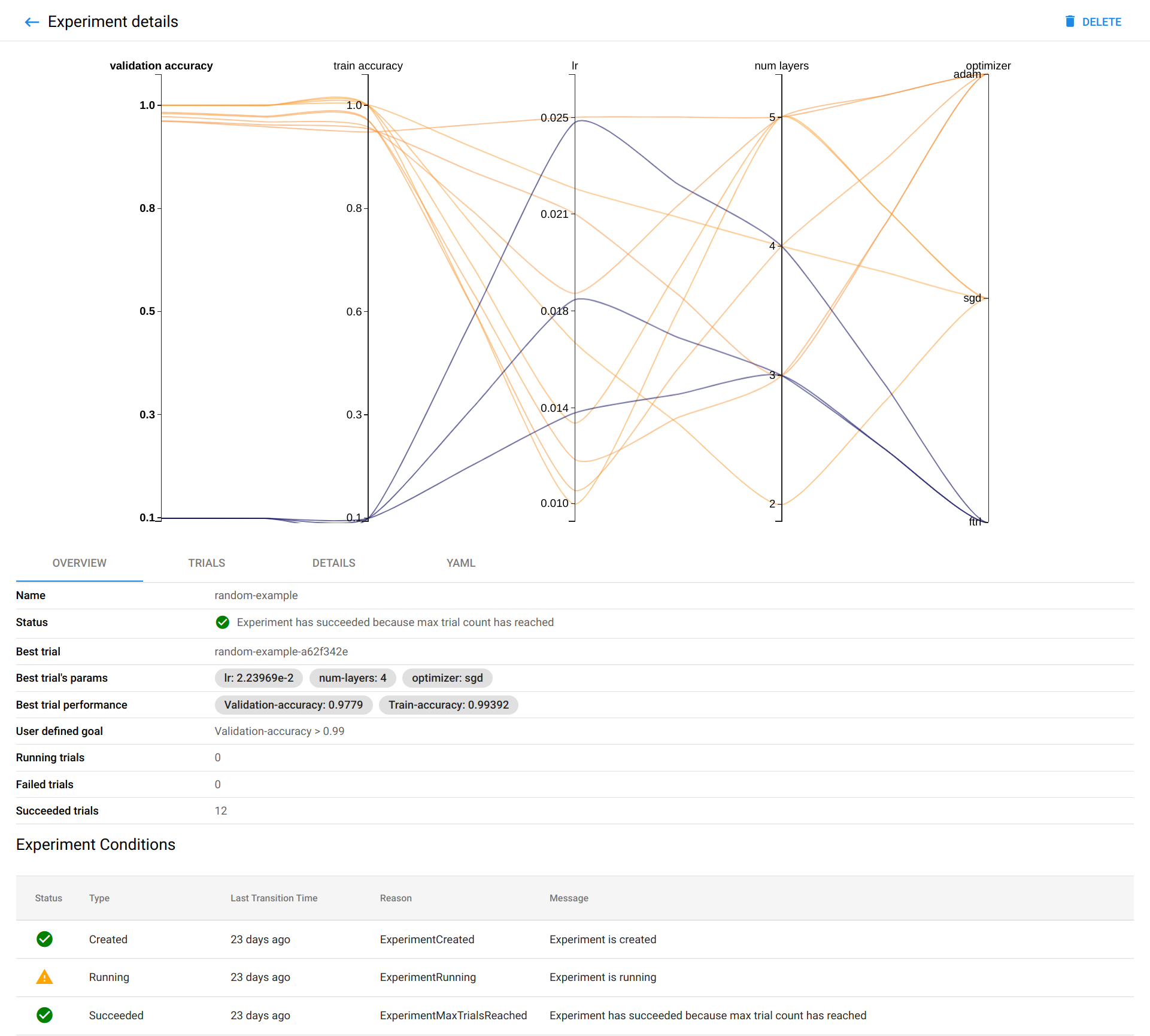
Neural Architecture Search (NAS) Support
: 목표를 달성하기 위해 필요한 인공 신경망을 자동으로 디자인해주고 골라준다. 즉, 모델의 구조와 노드의 가중치, 하이퍼 파라미터들을 최적화해준다는 것.
또한, 다음과 같은 AutoML 알고리즘을 지원한다:
- Bayesian optimization
- Tree of Parzen Estimators
- Random Search
- Covariance Matrix Adaptation Evolution Strategy
- Hyperband
- Efficient Neural Architecture Search
- Differentiable Architecture Search
cf) AutoML
: 데이터 사이언스의 역할에 필요한 전문 지식이나 배경 지식 없이도, 각 구성요소에 대한 최적의 솔루션을 알아서 찾는 검색 알고리즘.
모델에 대한 깊은 이해가 필요없이, 알아서 데이터에 맞는 모델을 찾아준다…???
How Katib Works
MNIST 예제 파일이다. 다음과 같이 어떤 알고리즘을 쓸건지 등의 구체적인 설정을 yaml에 명시한다.
apiVersion: kubeflow.org/v1beta1
kind: Experiment
metadata:
...
name: random
namespace: kubeflow-user-example-com
...
spec:
algorithm:
algorithmName: random
maxFailedTrialCount: 3
maxTrialCount: 12
metricsCollectorSpec:
collector:
kind: StdOut
objective:
additionalMetricNames:
- Train-accuracy
goal: 0.99
metricStrategies:
- name: Validation-accuracy
value: max
- name: Train-accuracy
value: max
objectiveMetricName: Validation-accuracy
type: maximize
parallelTrialCount: 3
parameters:
- feasibleSpace:
max: "0.03"
min: "0.01"
name: lr
parameterType: double
- feasibleSpace:
max: "5"
min: "2"
name: num-layers
parameterType: int
- feasibleSpace:
list:
- sgd
- adam
- ftrl
name: optimizer
parameterType: categorical
resumePolicy: Never
...그 후, 다음 코드를 실행하면 끝이다.
kubectl -n kubeflow describe experiment random그럼, 자동으로 최적의 결과를 알려주는 파라미터 세트를 알려준다.
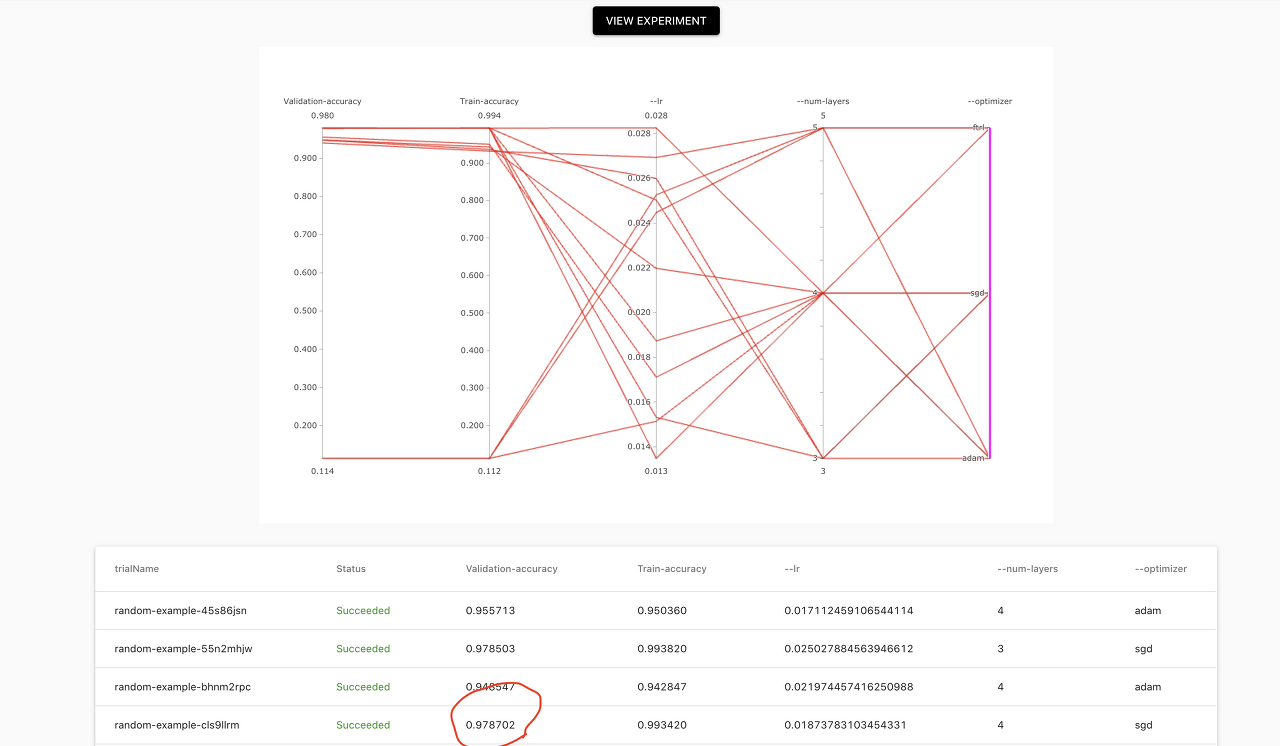
Automated ML Workflow and pipeline
: ML Pipeline을 구성할 때, K8s 클러스터 내에서 각각의 구성요소들을 컨테이너화 시켜 ML Workflow를 구성할 수 있다.
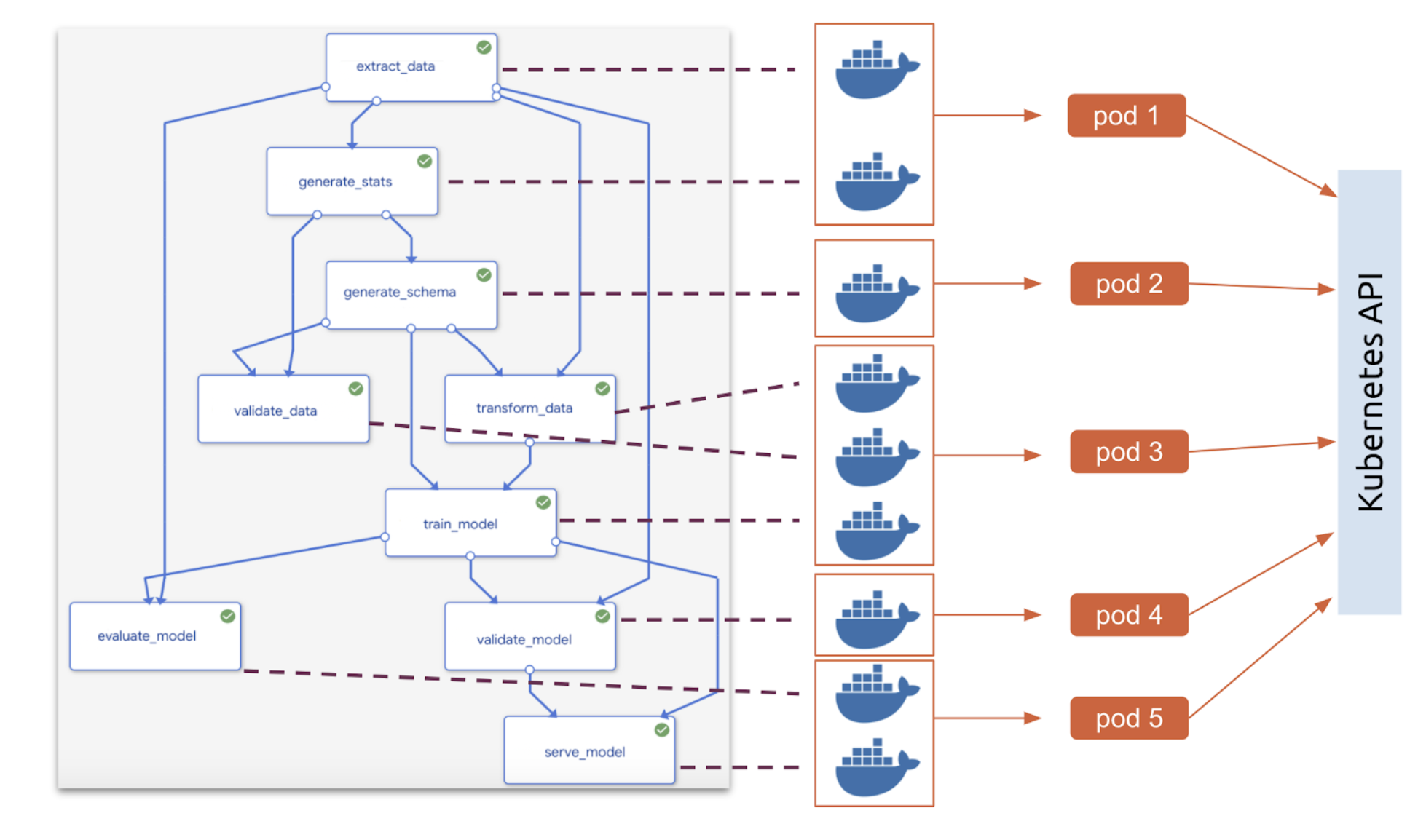
⇒ 다음과 같이 파이프라인의 각 구성요소들을 담당하는 컨테이너들을 파드들로 분리하는 모습. 이렇게 각 컴포너트들을 컨테이너화 시키면 다음과 같은 이점이 있다.
- 재사용, 공유, 교체의 용이성
- Kubeflow 내에서 결과 탐색, 디버그, 조정, 실행을 UI를 통해 더욱 쉽게 할 수 있다.
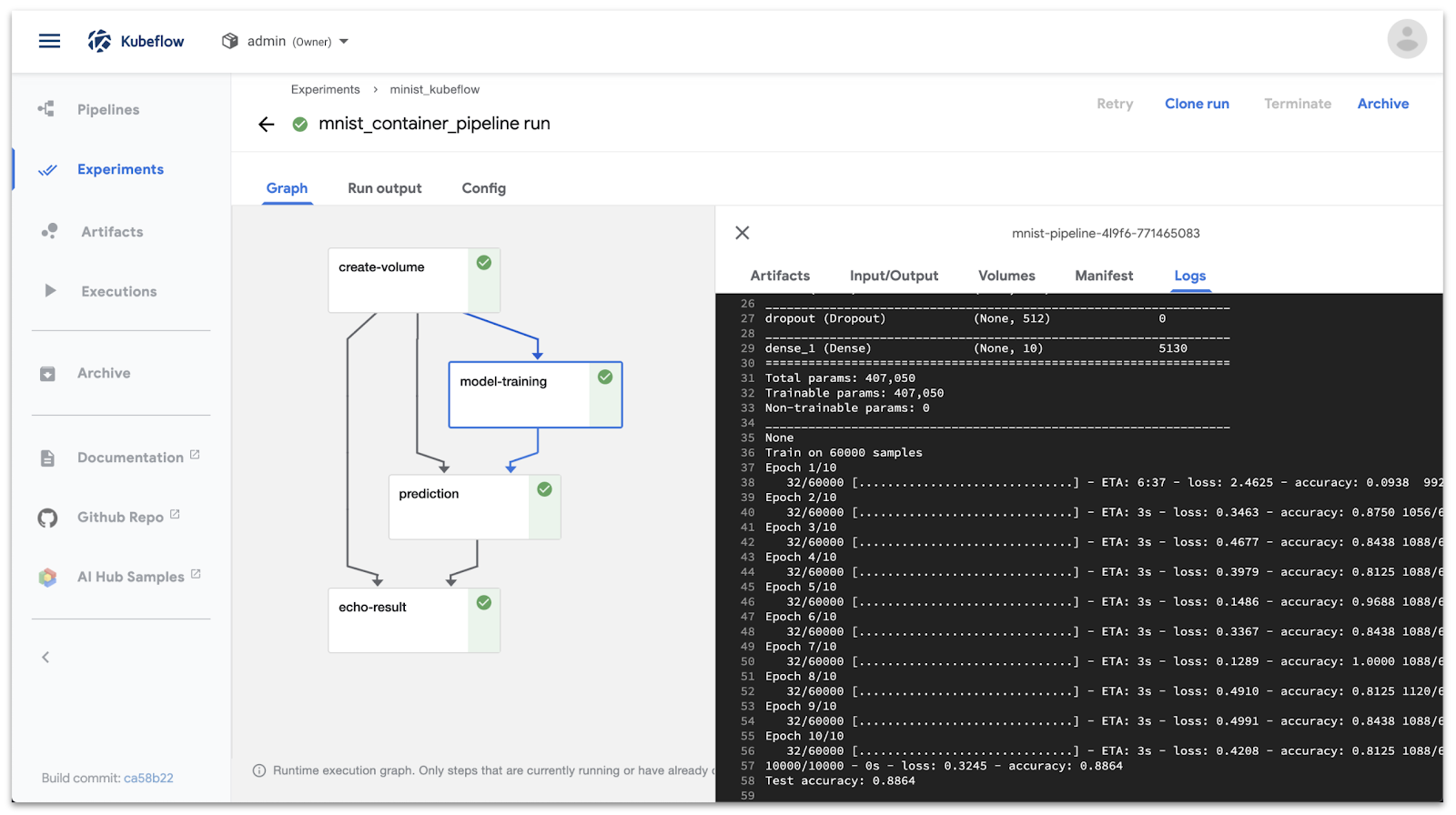
References
Kubeflow and ML Automation: Part 1
Running Distributed TensorFlow Jobs on Kubeflow 3.5

정리가 잘 된 글이네요. 도움이 됐습니다.