이 포스트는 "밑바닥부터 시작하는 딥러닝2 - 파이썬으로 직접 구현하며 배우는 순환 신경망과 자연어 처리 (한빛미디어, 사이토 고키 지음)" 책을 기반으로 공부해서 정리한 내용이다.
Chapter8: 어텐션
8.1 어텐션의 구조
- seq2seq의 근본적인 문제를 해결하고 크게 개선시킬 수 있는 어텐션 메커니즘
- seq2seq의 문제점: encoder의 출력이 고정 길이 벡터 -> 아무리 긴 문장이 입력되더라도 항상 같은 길이의 벡터로 출력해야 함 -> 필요한 정보가 벡터에 다 담기지 못하게 된다
- Encoder 개선
- 출력 길이를 입력 문장의 길이에 따라 바꾸기
- 시각별 LSTM 계층의 은닉 상태 벡터를 모두 사용
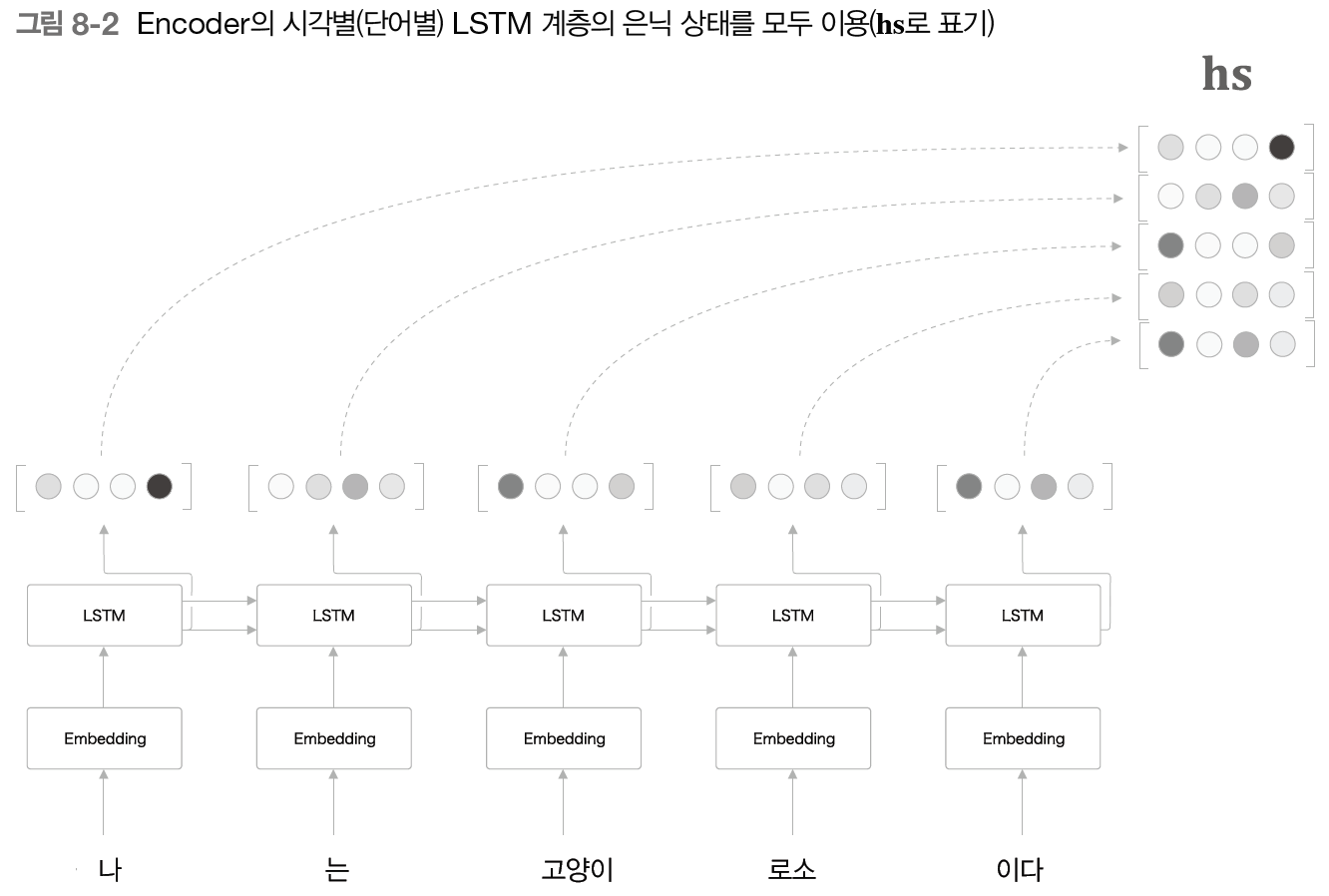 - 결국 이 hs의 각 행은 직전에 입력된 단어에 대한 정보가 많이 포함, 즉 각 단어에 해당하는 벡터들의 집합이라 할 수 있음
- 결국 이 hs의 각 행은 직전에 입력된 단어에 대한 정보가 많이 포함, 즉 각 단어에 해당하는 벡터들의 집합이라 할 수 있음
++ 많은 딥러닝 프레임워크에서 RNN(LSTM, GRU) 계층을 초기화할 때 모든 시각의 은닉 상태 벡터 반환/마지막 은닝 상태 벡터만 반환 선택 가능 - Decoder 개선
- 입력과 출력의 여러 단어 중 어떤 단어끼리 서로 관련되어 있는지, 즉 고양이와 cat이 대응관계에 있는 것처럼 이러한 대응 관계를 seq2seq에 학습시켜야 한다(단어 또는 문구의 대응 관계를 나타내는 alignment 자동화)
- 필요한 정보에만 주목하여 도착어 단어와 대응 관계에 있는 출발어 단어의 정보를 골라내기
- 각 시각에서 decoder에 입력된 단어와 대응 관계인 단어의 벡터를 hs(encoder 출력값)에서 선택하기 -> 선택 과정을 미분 가능한 연산으로 바꾸기(오차역전파법 가능)
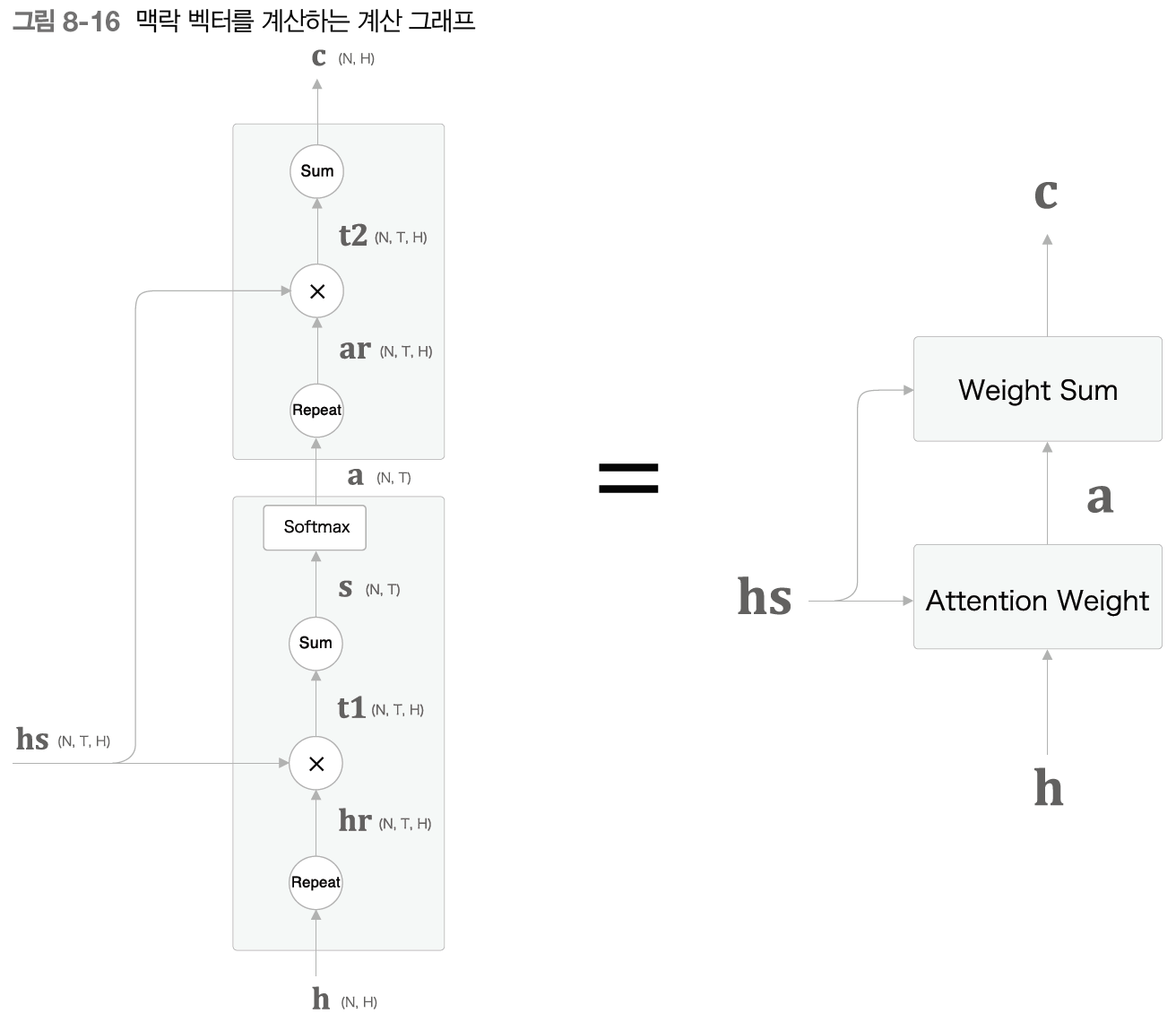 - Attention Weight 계층: encoder가 출력하는 각 단어의 벡터 hs에 주목하여 해당 단어의 가중치 a 구함
- Attention Weight 계층: encoder가 출력하는 각 단어의 벡터 hs에 주목하여 해당 단어의 가중치 a 구함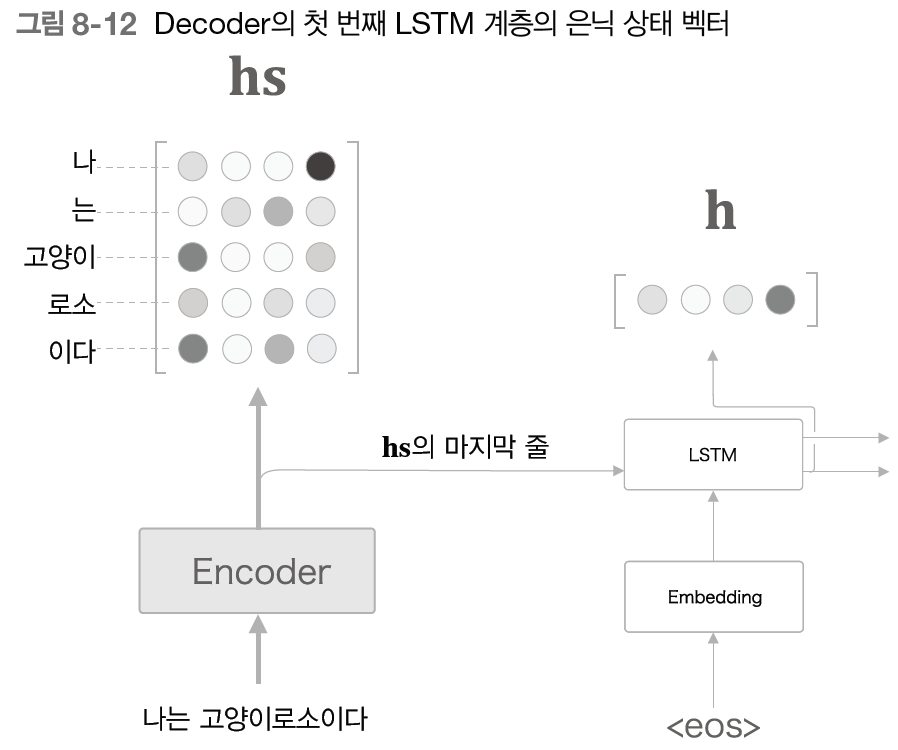 - 은닉 벡터 h와 hs의 각 행의 유사도를 내적을 이용해 산출 -> softmax를 통한 정규화 -> 가중치 값으로 사용
- 은닉 벡터 h와 hs의 각 행의 유사도를 내적을 이용해 산출 -> softmax를 통한 정규화 -> 가중치 값으로 사용
- Weight Sum 계층: a와 hs의 가중합을 구하고 그 결과를 맥락 벡터 c로 출력
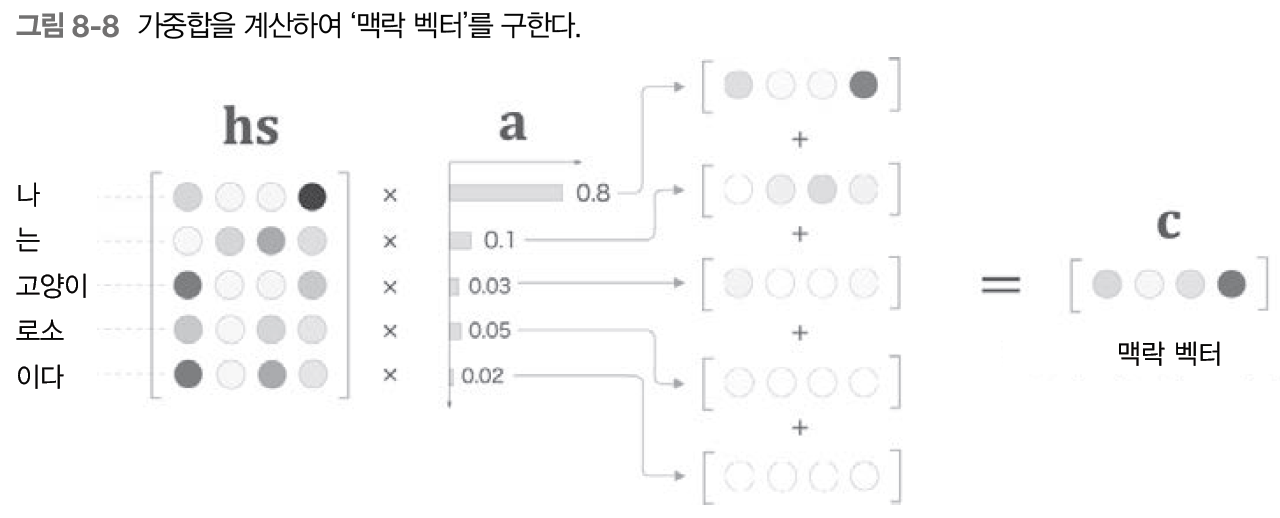 - 선택하는 작업을 이 가중합으로 대체, 만약 하나의 가중치가 1이고 나머지가 0이라면 그 벡터를 선택하는 것과 똑같은 효과
- 선택하는 작업을 이 가중합으로 대체, 만약 하나의 가중치가 1이고 나머지가 0이라면 그 벡터를 선택하는 것과 똑같은 효과 - 최종
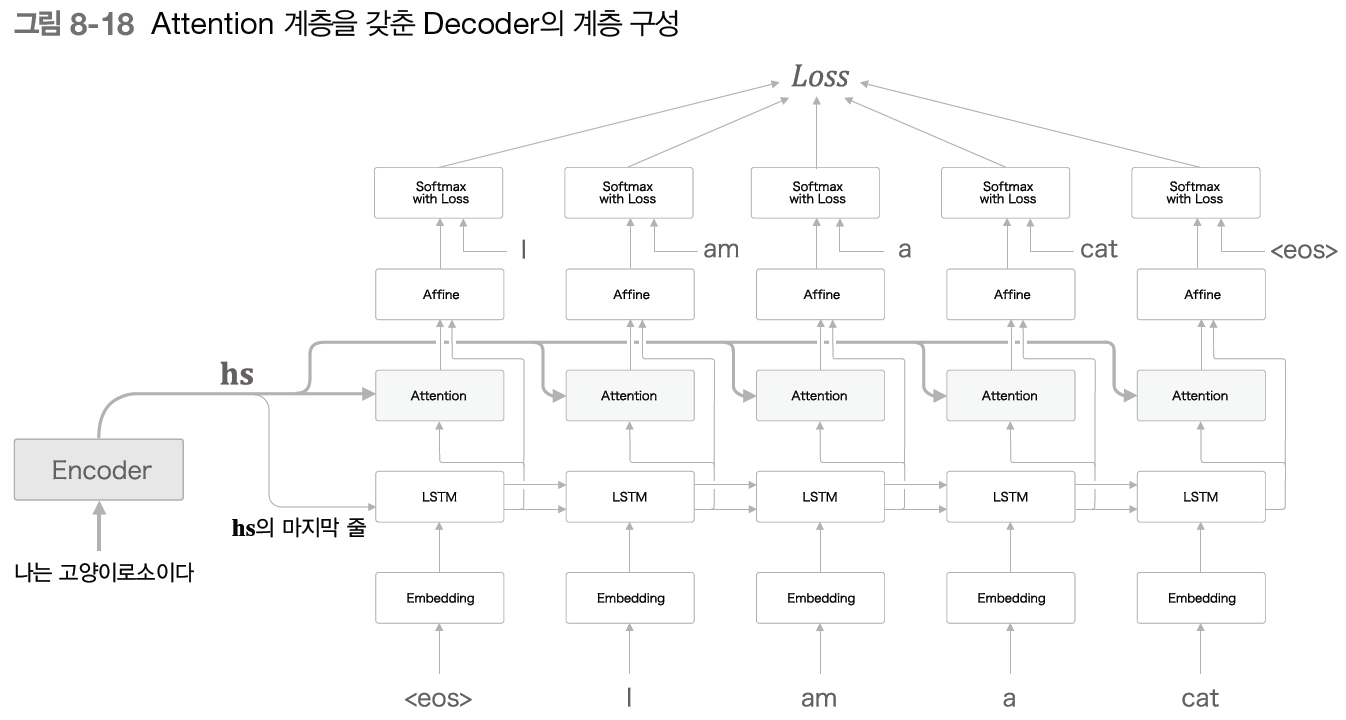 - affine 계층에는 은닉 상태 벡터뿐만 아니라 맥락 벡터가 추가적으로 입력된다
- affine 계층에는 은닉 상태 벡터뿐만 아니라 맥락 벡터가 추가적으로 입력된다
8.2 어텐션을 갖춘 seq2seq 구현
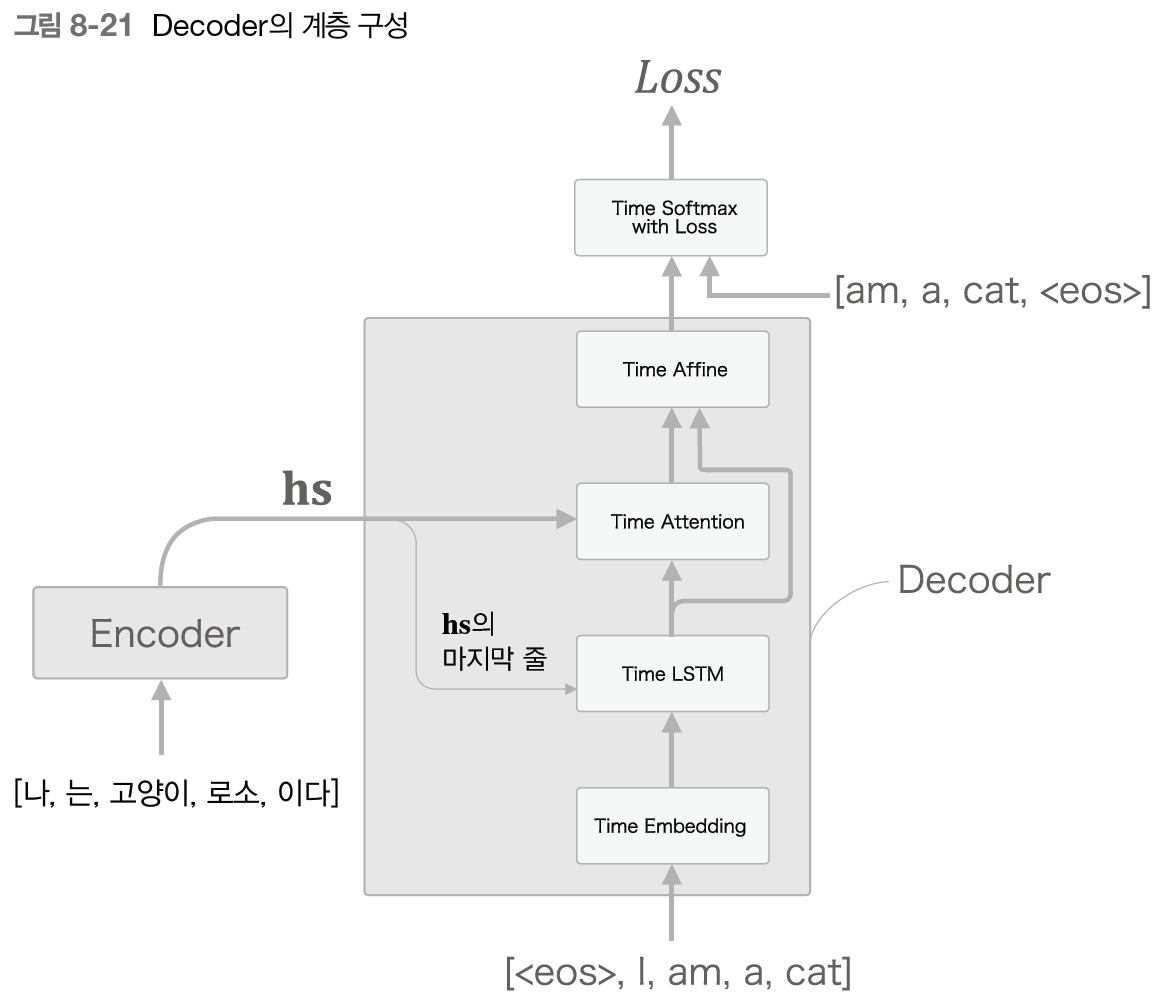
- encoder: 모든 은닉 상태 반환
- decoder: 순전파, 역전파, 새로운 문장 생성 / attention 계층 연결
8.3 어텐션 평가
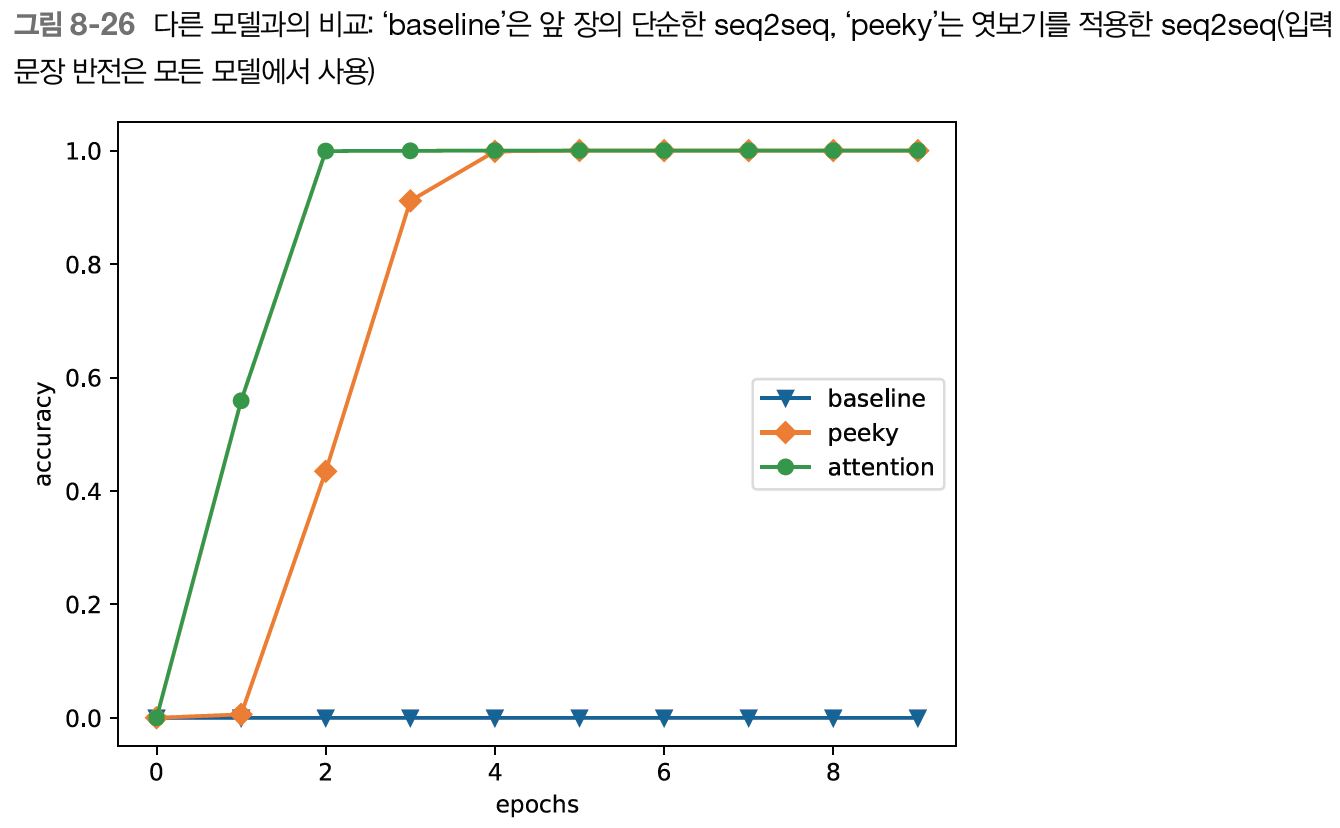
- 날짜 형식 변경하는 문제 테스트
 - 간단하지 않음, 입력과 출력에 년,월,일 대응 관계 존재 -> 어텐션이 올바르게 주목하는지 확인 가능
- 간단하지 않음, 입력과 출력에 년,월,일 대응 관계 존재 -> 어텐션이 올바르게 주목하는지 확인 가능 - 학습 결과 및 어텐션 시각화
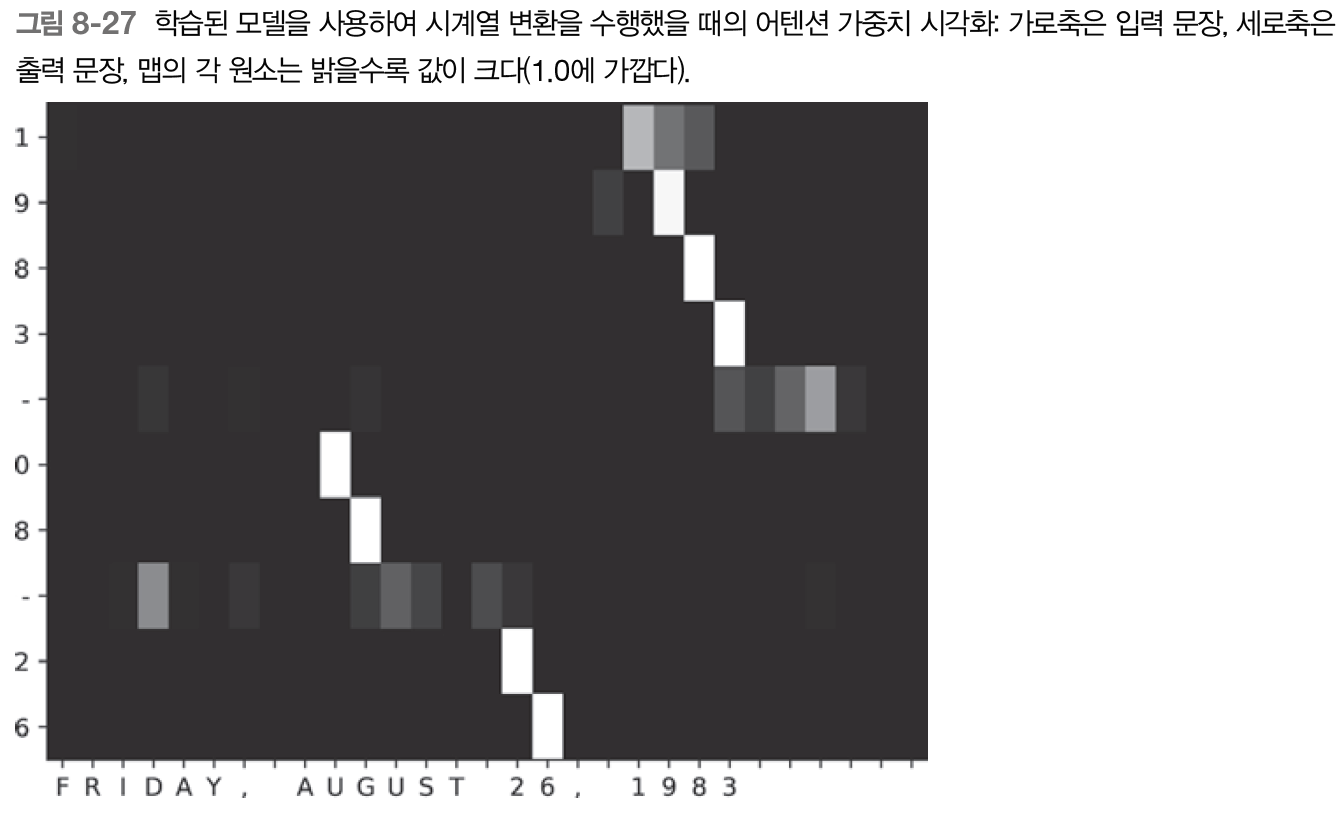
- 어텐션에서는 모델의 처리 논리가 인간의 논리를 따르는지를 판단 가능
8.4 어텐션에 관한 남은 이야기
- 양방향 RNN
- 단어의 주변 정보를 균형있게
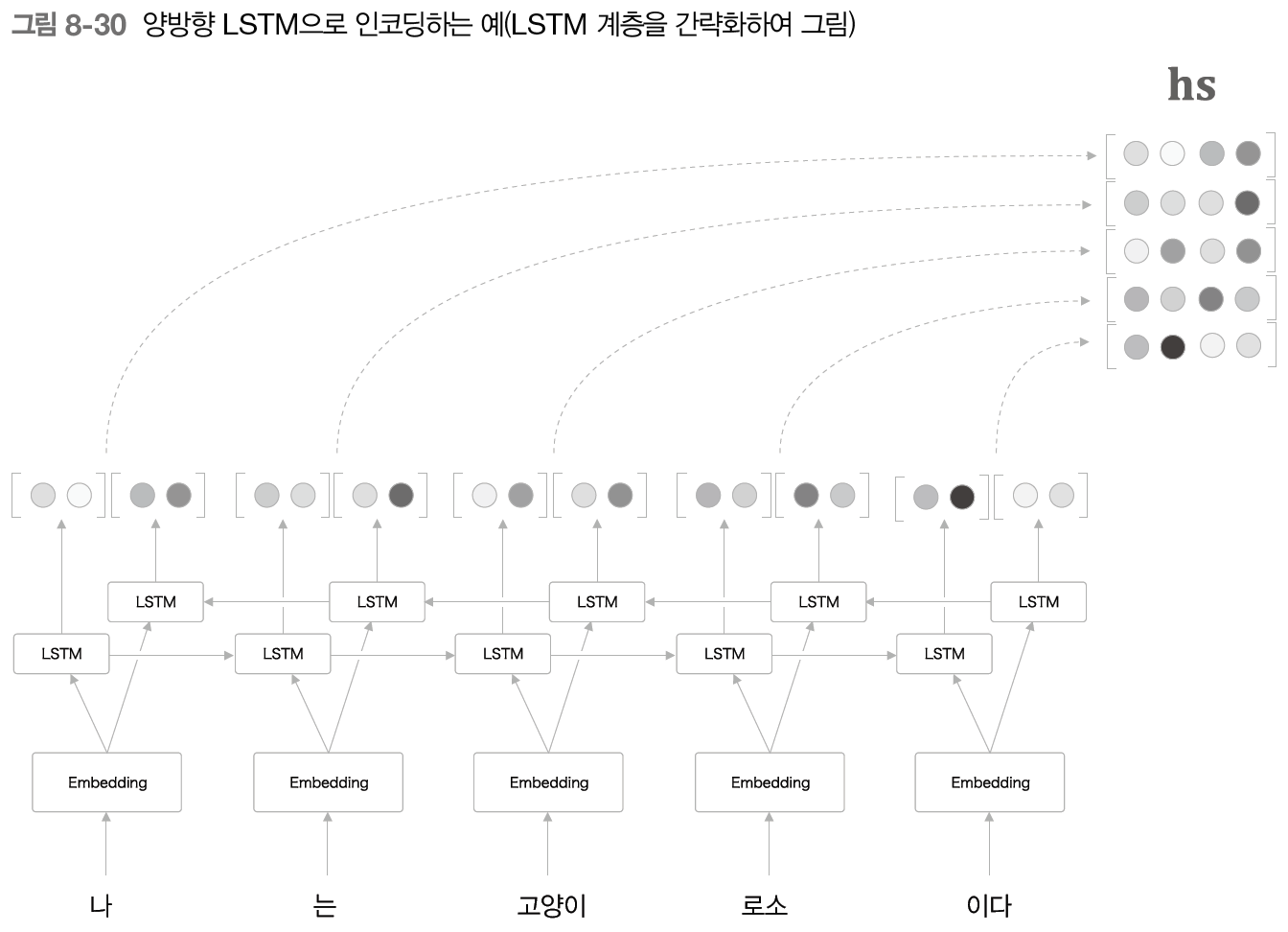 -구현 방법 중 한 가지는 2개의 LSTM 계층을 준비한 후 입력 단어의 순서를 조정
-구현 방법 중 한 가지는 2개의 LSTM 계층을 준비한 후 입력 단어의 순서를 조정 - attention 계층의 위치
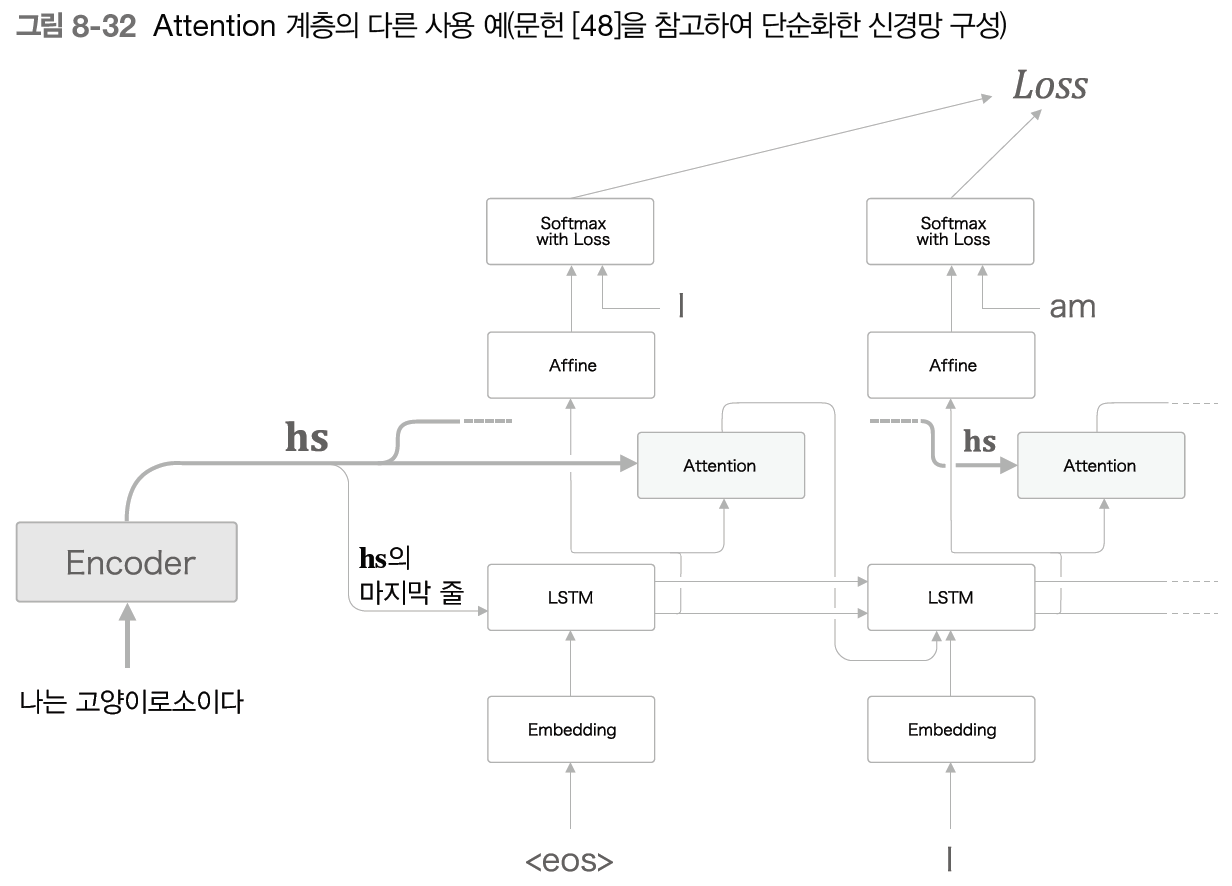 - 앞 절에서 본 계층 구성이 좀 더 구현하기 쉬움, 쉽게 모듈화 가능
- 앞 절에서 본 계층 구성이 좀 더 구현하기 쉬움, 쉽게 모듈화 가능 - seq2seq 심층화
- LSTM 계층을 깊게 쌓으면 표현력 높은 모델 쌓을 수 있음
- 일반적으로 encoder와 decoder에서 같은 층수의 lstm 사용
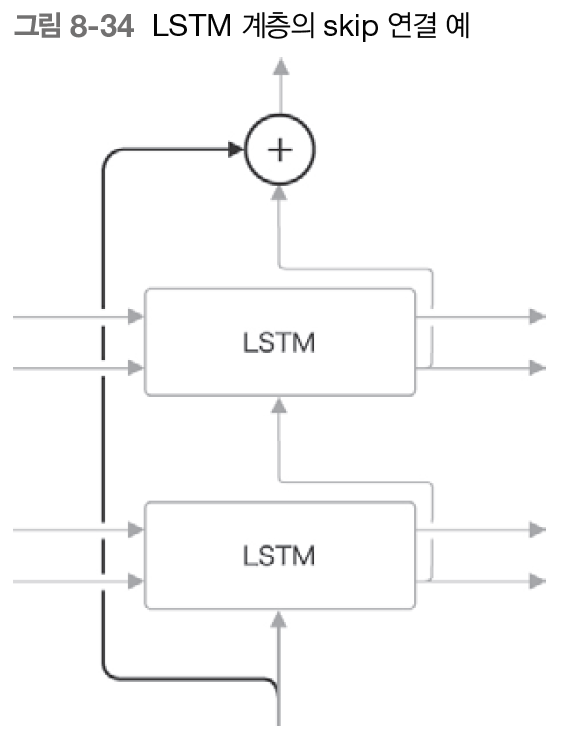
- 계층을 깊게 할 때는 일반화 성능을 떨어뜨리기 않기 위해 드롭아웃, 가중치 공유 등 사용 - skip 연결(잔차 연결, 숏컷)
- 층을 깊게 할 때 사용되는 중요한 기법
- 계층을 넘어 선을 연결, 계층을 건너뛴다
- 접속부에서 원소별 덧셈 -> 역전파 시 기울기를 그대로 흘려보내므로 기울기 손실/폭발 위험성 줄여 좋은 학습 가능
- RNN 시간 방향에서 기울기 소실: 게이트 달린 RNN, 기울기 폭발: 기울기 클리핑, RNN 깊이 방향 기울기 소실: skip 연결 효과적
8.5 어텐션 응용
- 구글 신경망 기계 번역(GNMT)
- LSTM 계층 다층화, 양방향 LSTM, skip 연결, GPU 분산 학습 - 트랜스포머
- 딥러닝 학습은 GPU를 이용한 병렬 계산 환경에서 이루어짐, 하지만 RNN은 시간방향으로 병력적 계산이 불가능함
-> RNN을 없애거나 병렬 계산할 수 있는 RNN 연구 활발
-> 트랜스포머 모델: RNN이 아닌 어텐션을 사용해 처리
- self-attention: 하나의 시계열 데이터 내에서 각 원소가 다른 원소들과 어떻게 관련되어있는지
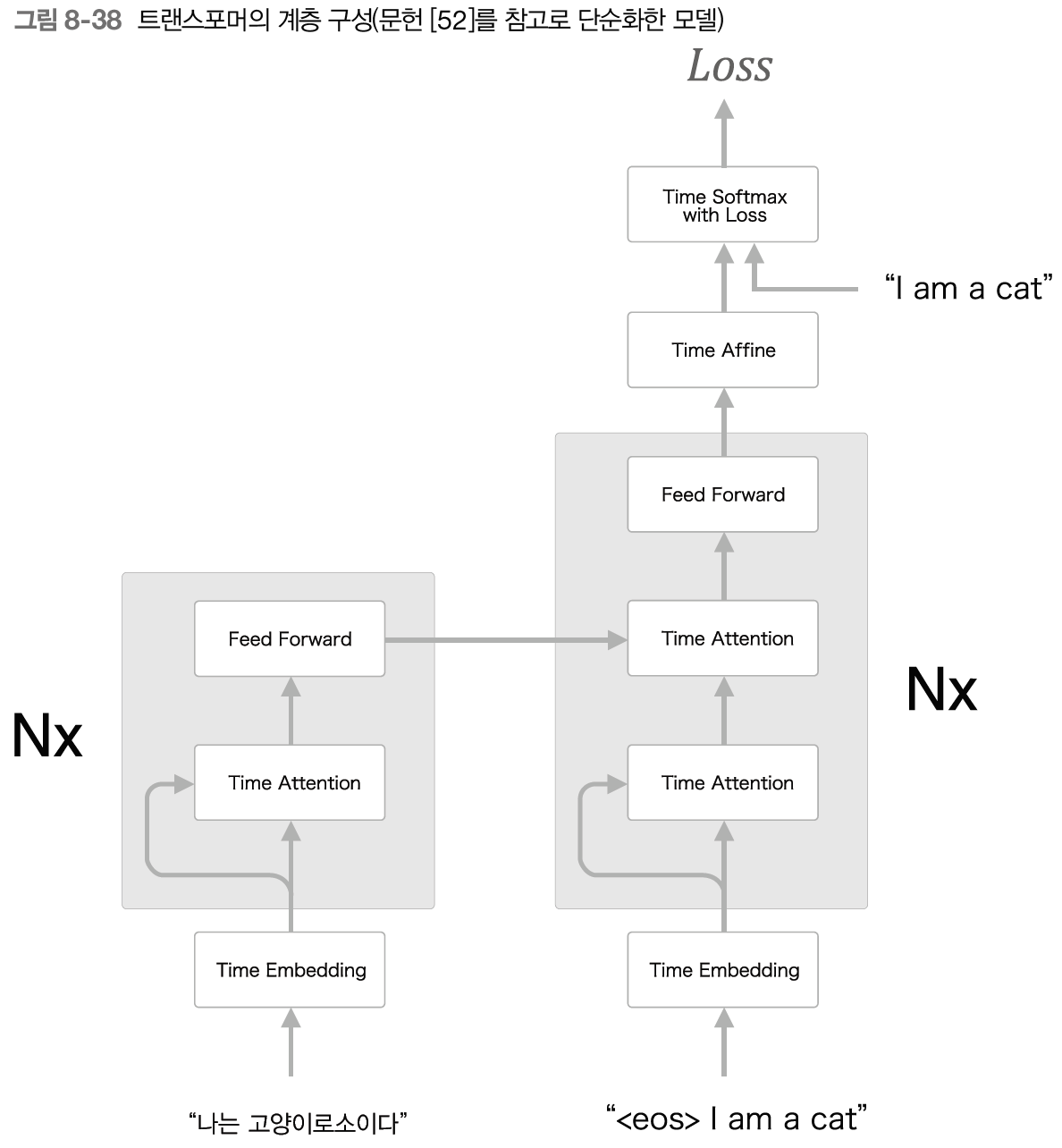 - 하나의 시계열 데이터 내에서 원소 간 대응 관계 구해짐
- 하나의 시계열 데이터 내에서 원소 간 대응 관계 구해짐
- 피드포워드 신경망: 시간 방향으로 독립적으로 처리
- GNMT보다 학습 시간을 큰 폭으로 줄이고 번역 품질도 상당히 올릴 수 있음
-> 어텐션은 RNN을 대체하는 모듈로도 사용 가능하다 - 뉴럴 튜링 머신(NTM)
- 외부 메모리를 통한 혹장
- encoder가 필요한 정보를 메모리에 적고, decoder가 메모리로부터 필요한 정보를 읽어 들인다
- 이러한 메로리 조작을 미분 가능한 계산으로 구축 -> 학습 가능
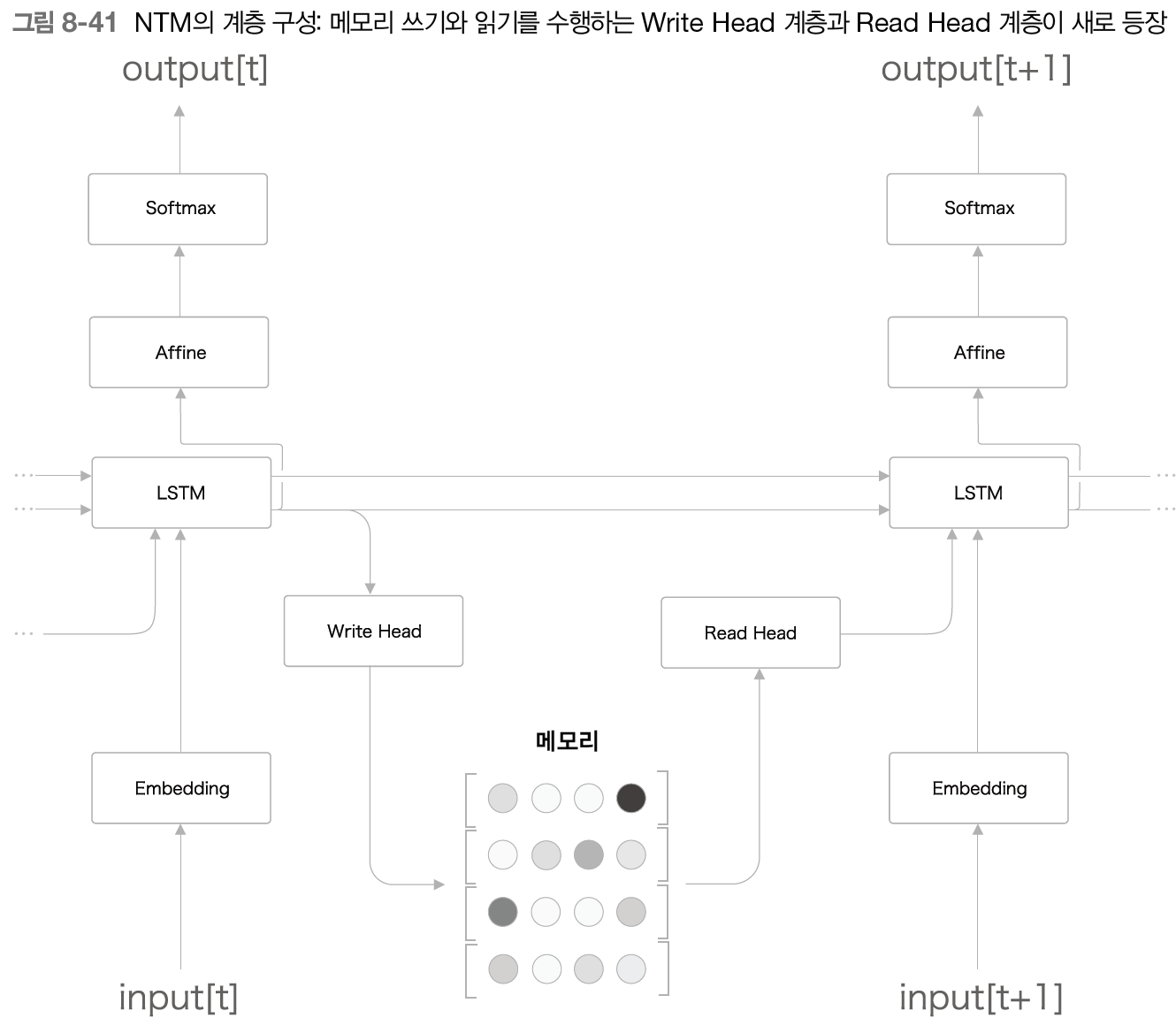 - LSTM 계층이 컨트롤러 역할
- LSTM 계층이 컨트롤러 역할
- 콘텐츠 기반 어텐션(입력 벡터와 비슷한 벡터를 메모리로부터 찾아냄), 위치 기반 어텐션(이전 시각에서 주목한 메모리의 위치를 기준으로 그 전후로 이동, 1차원의 합성곱 연산으로 구현) - 외부 메모리를 사용함으로써 알고리즘을 학습하는 능력, 긴 시계열 기억 문제와 정렬 문제 해결 가능
학습한 코드는 여기에서
https://github.com/syi07030/NLP_study
위 코드는 이 책의 코드와 아래의 코드를 바탕으로 작성했습니다.
https://github.com/WegraLee/deep-learning-from-scratch-2
사진 출처 또한 여기에서: https://github.com/WegraLee/deep-learning-from-scratch-2

잭과 근나물