이 포스트는 "밑바닥부터 시작하는 딥러닝2 - 파이썬으로 직접 구현하며 배우는 순환 신경망과 자연어 처리 (한빛미디어, 사이토 고키 지음)" 책을 기반으로 공부해서 정리한 내용이다.
Chapter7: RNN을 사용한 문장 생성
7.1 언어 모델을 사용한 문장 생성
- 언어 모델: 지금까지 주어진 단어들에서 다음에 출현하는 단어의 확률분포를 출력
- 다음 단어를 생성하기 위해서는?
- 결정적 방법: 확률이 가장 높은 단어를 선택
- 확률적 방법: 각 후보 단어의 확률에 맞게 선택 -> 매번 선택되는 단어가 달라질 수 있음 - 이렇게 학습된 단어의 정렬 패턴을 이용해(학습이 끝난 가중치를 통해) 새로운 문장을 생성하는 것이 가능
- 더 좋은 언어 모델로 더 자연스러운 문장을 생성
7.2 seq2seq
- 시계열 데이터 ex) 언어 데이터, 음성 데이터, 동영상 데이터
- 시계열 데이터 -> 시계열 데이터 ex) 기계 번역, 음성 인식, 챗봇, 컴파일러
- seq2seq: 시계열 데이터를 다른 시계열 데이터로 변환하는 보델(여기서는 2개의 RNN 사용)
- Encoder: 입력 데이터를 인코딩, Decoder: 인코딩된 데이터를 디코딩
- 인코딩된 정보에는 번역에 필요한 정보가 조밀하게 응축되어 있음
- 디코더는 이러한 응축된 정보를 바탕으로 도착어 문장 생성
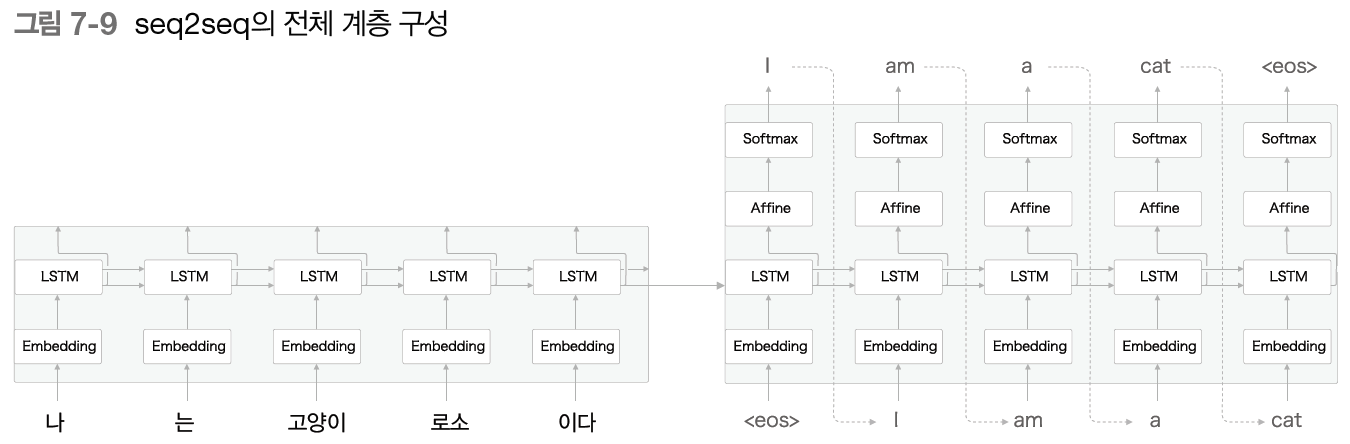 - Encoder에서 출력되는 벡터는 마지막 은닉 상태 h: 번역하는 데 필요한 정보가 인코딩, 고정 길이 벡터
- Encoder에서 출력되는 벡터는 마지막 은닉 상태 h: 번역하는 데 필요한 정보가 인코딩, 고정 길이 벡터
- 즉 인코딩 == 임의 길이의 문장을 고정 길이 벡터로 변환하는 것
- 이 h가 encoder, decoder를 이어주는 가교 역할, 순전파 때는 인코딩된 정보가 전해지고, 역전파일 때는 기울기가 전해짐 - 장난감 문제 테스트(머신러닝을 평가하고자 만든 간단한 문제, 덧셈 테스트)
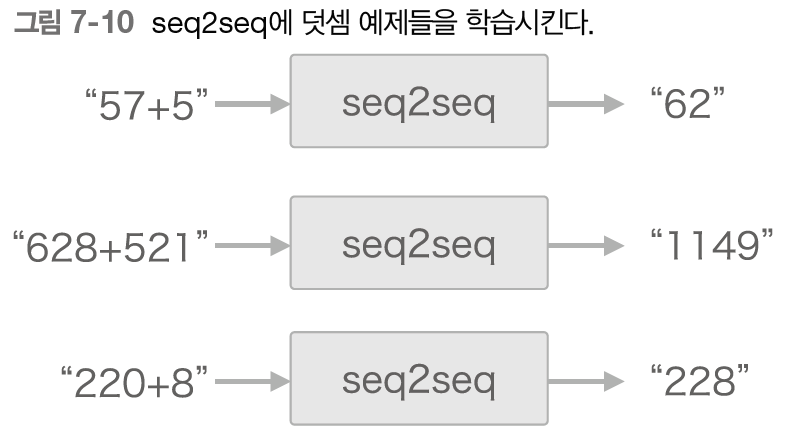 - 문장을 단어가 아닌 문자 단위로 분할
- 문장을 단어가 아닌 문자 단위로 분할
- 가변 길이 시계열 데이터가 입력으로 -> 패딩 필요(정확도를 높이기 위해서는 패딩값이 결과에 반영되지 않도록 softmax with loss 계층에 마스크 기능을 추가하거나 lstm 계층에서 패딩 값이 들어오면 이전 시각의 입력을 그대로 출력하거나 등등의 작업이 필요)
++ 정석적인 방식으로는 데이터셋 3개 필요(훈련용, 검증용-하이퍼파라미터 튜닝, 테스트용)
7.3 seq2seq 구현
- Encoder: Time embedding + Time LSTM -> 마지막 은닉 벡터 h decoder로 전달
- Decoder: Time embedding + Time LSTM + Time Affine
- 학습: + Time softmax with loss
- 문장 생성: + argmax 노드(affine 계층의 출력 중 값이 가장 큰 원소의 인덱스를 반환) - 학습: 미니배치 선택 -> 기울기 계산 -> 매개변수 갱신
- 평가: 현재 모델로는 덧셈 테스트에서 그다지 좋은 정답률을 보이지는 않음
7.4 seq2seq 개선
- 입력 데이터 반전(reverse)
 - 직관적으로 기울기 전파가 원활해지기 때문(문장의 앞쪽 단어는 반전하게 되면 대응하는 변환 후 단어와 가까워지므로 기울기가 더 잘 전해져 학습 효율이 좋아진다)
- 직관적으로 기울기 전파가 원활해지기 때문(문장의 앞쪽 단어는 반전하게 되면 대응하는 변환 후 단어와 가까워지므로 기울기가 더 잘 전해져 학습 효율이 좋아진다)
- 많은 경우 학습 진행이 빨라짐, 결과적으로 최종 정확도도 좋아짐 - 엿보기(peeky)
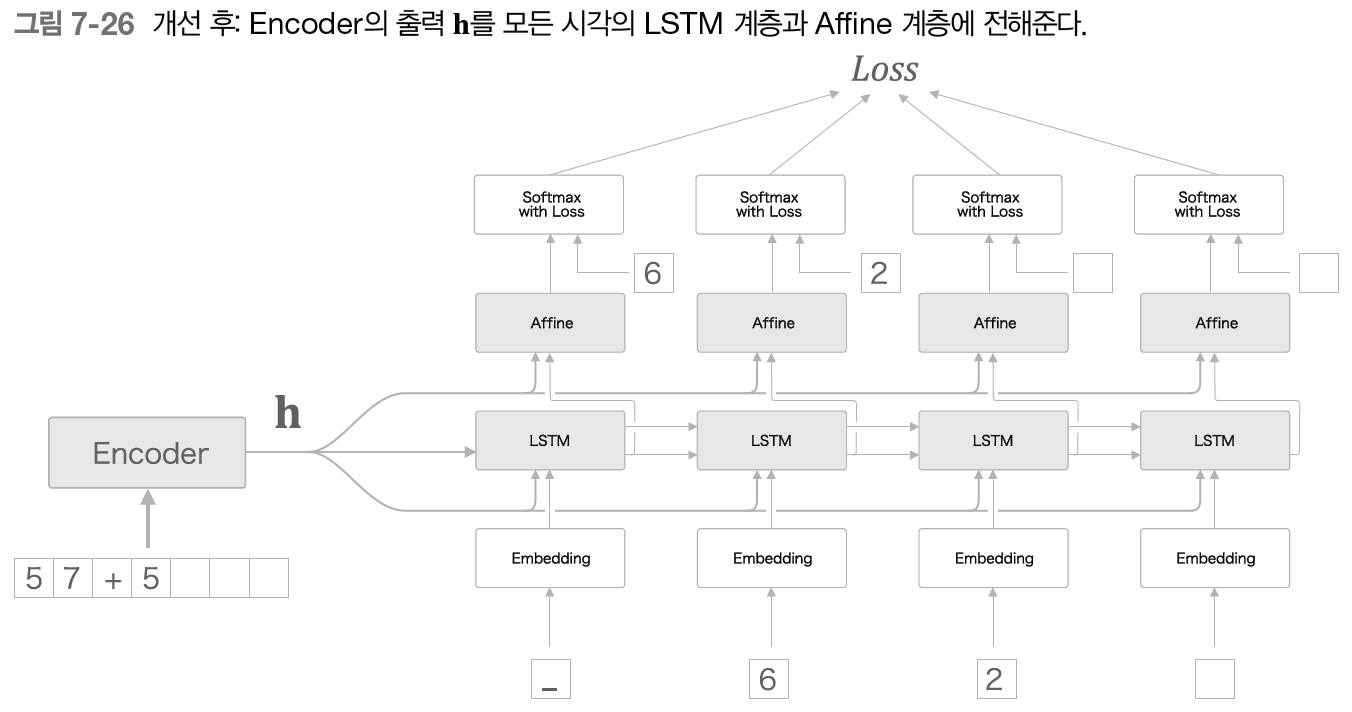 - Decoder에게 있어 h는 매우 중요한 정보
- Decoder에게 있어 h는 매우 중요한 정보
- h를 여러 계층에 공유해서 집단지성과 같은 효과
- 하지만 가중치 매개변수가 커지므로 계산량이 늘어남
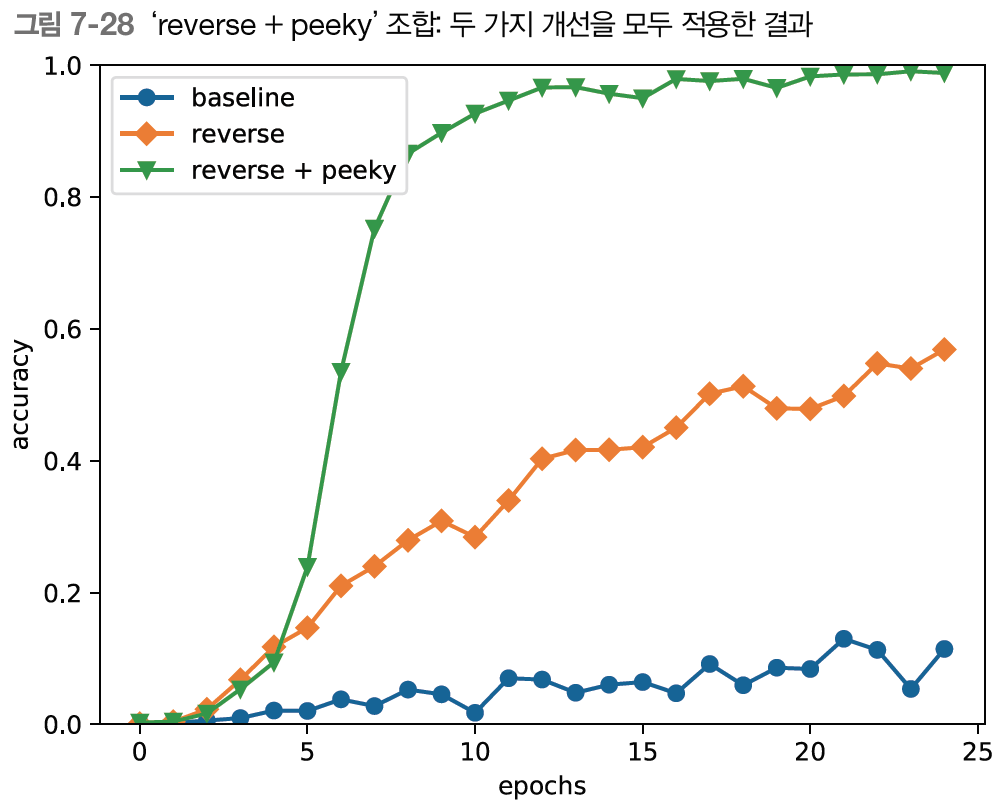
- seq2seq의 정확도는 파이퍼파라미터에 영향을 크게 받음
7.5 RNNLM 추가 개선
- 기계번역, 자동 요약, 질의응답, 메일 자동 응답
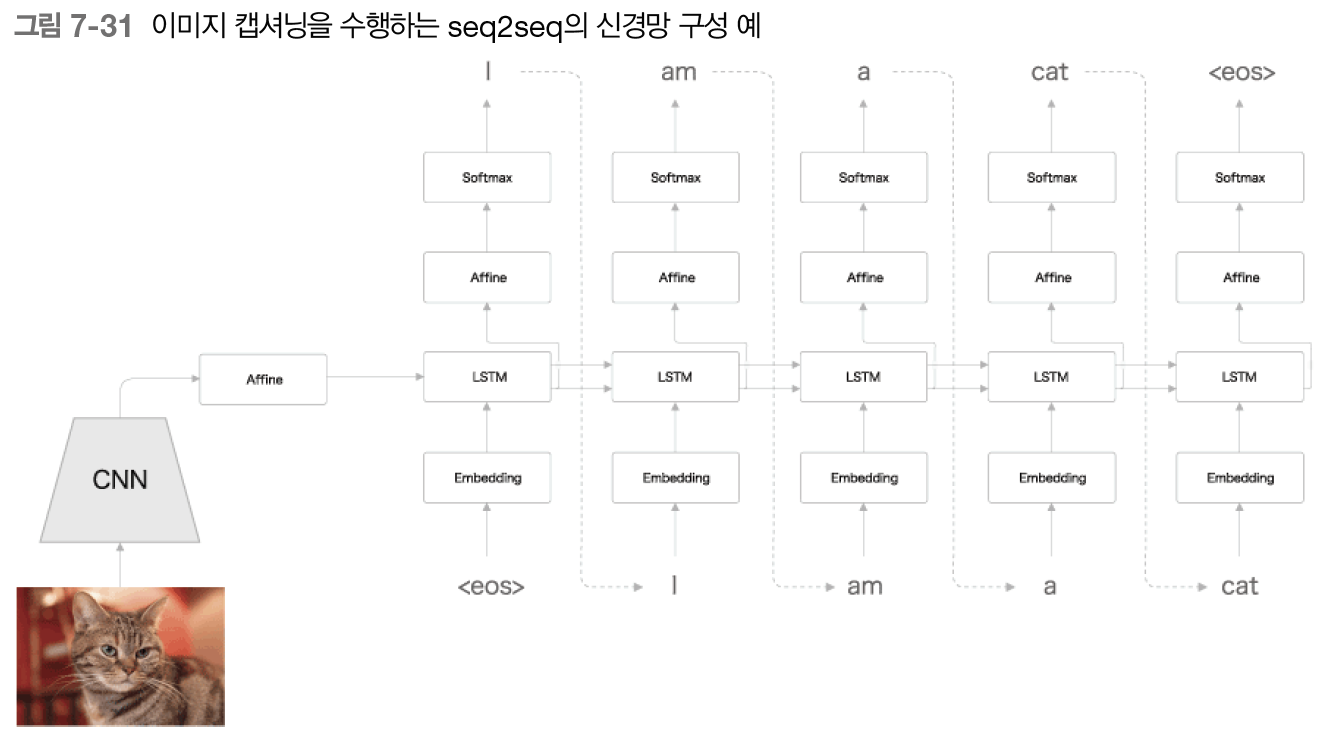
- 챗봇, 알고리즘 학습, 이미지 캡셔닝(이미지 -> 문장, encoder를 합성곱 신경망[CNN]으로 대체)
++CNN: 최종 출력은 특징 맵(높이, 폭, 채널) -> decoder의 LSTM이 처리할 수 있도록 1차원으로 flattening 후 affine 계층에서 변환, VGG,ResNet 등의 입증된 신경망 사용, 가중치로는 다른 이미지 데이터셋으로 학습을 끝낸 것을 이용
학습한 코드는 여기에서
https://github.com/syi07030/NLP_study
위 코드는 이 책의 코드와 아래의 코드를 바탕으로 작성했습니다.
https://github.com/WegraLee/deep-learning-from-scratch-2
사진 출처 또한 여기에서: https://github.com/WegraLee/deep-learning-from-scratch-2

잭과 근나물