2주 전에 제출했지만 지금 올리기
스타벅스 이디야 매장 데이터 분석
- 스타벅스 매장 찾기 https://www.starbucks.co.kr/store/store_map.do
- 서울시로 한정, selenium, beautifulSoup
- 이디야 매장 찾기 https://ediya.com/contents/find_store.html#c
- 서울시
문제 1) 서울시의 스타벅스 매장의 이름과 주소, 구 이름을 pandas data frame으로 정리하기
from selenium import webdriver
from selenium.webdriver.common.by import By
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pandas as pd
from selenium.common.exceptions import UnexpectedAlertPresentException, NoAlertPresentException
from tqdm.notebook import tqdm# 페이지 접근
driver = webdriver.Chrome()
driver.get('https://www.starbucks.co.kr/store/store_map.do')# 지역 검색 들어가기
driver.find_element(By.CSS_SELECTOR, '#container > div > form > fieldset > div > section > article.find_store_cont > article > header.loca_search > h3 > a').click()# 서울시
driver.find_element(By.CSS_SELECTOR, '#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a').click()html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
print(soup.prettify())# 구 이름 가져오기
guList= driver.find_elements(By.CLASS_NAME, 'set_gugun_cd_btn')
guList[2].text
>>>
'강동구'gu = []
for option in guList:
gu.append(option.text)
gu = [option.text for option in guList]
# '전체', '' 제거
gu.pop(0)
gu = [element for element in gu if element != '']- 스크롤하면서 정보 가져오기
scroll = driver.find_element(By.ID, 'mCSB_2_container')
driver.execute_script('arguments[0].style.top = "-93px";', scroll)# 구 이름 가져오기
guList_2= driver.find_elements(By.CLASS_NAME, 'set_gugun_cd_btn')
gu_2 = []
gu_2 = [option.text for option in guList_2]
# '' 제거
gu_2 = [element for element in gu_2 if element != '']# gu, gu_2 합치기
i = gu_2.index('용산구')
gu_2 = gu_2[i+1:]gu_final = gu + gu_2구 별로 주소, 이름 불러오기
def collect(gu):
# 구 이름 클릭
gu_click = driver.find_element(By.LINK_TEXT, gu)
gu_click.click()
time.sleep(0.5)
html_2 = driver.page_source
soup_2 = BeautifulSoup(html_2, 'html.parser')
# 검색결과 수
trashNum = soup_2.select_one('#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step3 > div.result_num_wrap > span')
trashNum = int(trashNum.text)
shops_gu = [] # 구
shops_name = [] # 이름
shops_add = [] # 주소
shops_lat = [] # 위도
shops_lng = [] # 경도
shops = [shops_gu, shops_name, shops_add, shops_lat, shops_lng]
for i in range(1, trashNum+1):
shops_gu.append(gu)
shops_name.append(soup_2.select_one(f'#mCSB_3_container > ul > li:nth-child({i})').get('data-name'))
shops_add.append(soup_2.select_one(f'#mCSB_3_container > ul > li:nth-child({i}) > p').text[:-9])
shops_lat.append(soup_2.select_one(f'#mCSB_3_container > ul > li:nth-child({i})').get('data-lat'))
shops_lng.append(soup_2.select_one(f'#mCSB_3_container > ul > li:nth-child({i})').get('data-long'))
return list(shops)# 지역검색 -> 서울
driver.find_element(By.CSS_SELECTOR, '#container > div > form > fieldset > div > section > article.find_store_cont > article > header.loca_search > h3 > a').click()
time.sleep(0.5)
driver.find_element(By.CSS_SELECTOR, '#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a').click()
time.sleep(0.5)import time
from tqdm import tqdm_notebook
# 구 별로 데이터 모으고 합치기
df_added = pd.DataFrame()
for i in tqdm_notebook(range(0, len(gu_final))):
if i>=19:
scroll = driver.find_element(By.ID, 'mCSB_2_container')
driver.execute_script('arguments[0].style.top = "-93px";', scroll)
# 구별로 매장 dataframe 만들기
final = collect(gu_final[i])
df = pd.DataFrame({
'구': final[0],
'매장이름': final[1],
'주소': final[2],
'위도': final[3],
'경도': final[4]
})
# 행 추가하기
df_added = pd.concat([df_added, df])
# 지역검색 -> 서울
driver.find_element(By.CSS_SELECTOR, '#container > div > form > fieldset > div > section > article.find_store_cont > article > header.loca_search > h3 > a').click()
time.sleep(1)
driver.find_element(By.CSS_SELECTOR, '#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a').click()
time.sleep(1)문제 2) 서울시의 이디야커피 매장의 이름과 주소, 구 이름을 pandas data frame으로 정리하기
# 페이지 접근
driver = webdriver.Chrome()
driver.get('https://ediya.com/contents/find_store.html#c')driver.find_element(By.CSS_SELECTOR, '#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a').click()- 검색어(구) 입력, 구 별 매장 정보 찾기
- '중구' 는 범위가 너무 넓어서 이디야 사이트에서 검색 결과가 너무 많다는 창이 뜬다. 범위를 좁히기 위해서 중구에 있는 스타벅스 매장의 도로명을 추출하여 검색했다.
# 중구 스타벅스 매장 도로명 추출
filtered = df_added[df_added['구'] =='중구']
dong = [add.split(' ')[2] for add in filtered['주소']]
dong = list(set(dong))def collect_ediya(gu):
# 검색어 입력
keyword = driver.find_element(By.CSS_SELECTOR, '#keyword')
keyword.clear()
keyword.send_keys(gu)
# 검색 클릭
driver.find_element(By.CSS_SELECTOR, '#keyword_div > form > button').click()
time.sleep(1) # 검색하고 로딩 기다리기
html_ed = driver.page_source
soup_ed = BeautifulSoup(html_ed, 'html.parser')
ediya_list = soup_ed.select('#placesList > li')
ediya_gu = [] # 구
ediya_name = [] # 이름
ediya_add = [] # 주소
ediyas = [ediya_gu, ediya_name, ediya_add]
for shop in ediya_list:
parts = shop.text.split(' ', 1) # '강남구청역아이티웨딩점 서울 강남구 학동로 338 (논현동, 강남파라곤)' 을 첫 번째 공백 기준으로 split
ediya_gu.append(parts[1].split(' ')[1]) # 구 정보
ediya_name.append(parts[0])
ediya_add.append(parts[1])
return list(ediyas)# 구 별로 데이터 모으고 합치기
ediyaAdded = pd.DataFrame()
for j in tqdm_notebook(range(0, len(gu_final))):
if gu_final[j]=='중구':
for d in dong:
try:
ediyaFinal = collect_ediya(d)
result = driver.switch_to.alert
result.accept()
time.sleep(1)
# 검색결과 없을 시 경고창 처리
except UnexpectedAlertPresentException:
continue
except NoAlertPresentException:
continue
ediyaDf = pd.DataFrame({
'구': ediyaFinal[0],
'매장이름': ediyaFinal[1],
'주소': ediyaFinal[2],
'위도': None,
'경도': None
})
else:
# 구 별로 매장 dataframe 만들기
ediyaFinal = collect_ediya(gu_final[j])
ediyaDf = pd.DataFrame({
'구': ediyaFinal[0],
'매장이름': ediyaFinal[1],
'주소': ediyaFinal[2],
'위도': None,
'경도': None
})
# 행 추가하기
ediyaAdded = pd.concat([ediyaAdded, ediyaDf])- 이디야 위, 경도 정보 추가
import googlemapsgmaps_key = "~"
gmaps = googlemaps.Client(key=gmaps_key)ediyaAdded['위도'] = None
ediyaAdded['경도'] = NoneediyaAdded.reset_index(inplace=True)# 이디야 매장 위도, 경도 정보 추가
for idx, rows in ediyaAdded.iterrows():
address = rows['주소']
# 상세하지 않은 주소는 기입하지 않음
adList = address.split(' ')
print(adList)
if len(adList) <= 3:
ediyaAdded.loc[idx, '위도'] = None
ediyaAdded.loc[idx, '경도'] = None
print(address)
tmp = gmaps.geocode(address, language='ko')
# tmp 비어있을 경우 기입하지 않음
if not tmp or 'geometry' not in tmp[0]:
ediyaAdded.loc[idx, '위도'] = None
ediyaAdded.loc[idx, '경도'] = None
continue
print(tmp[0].get('formatted_address'))
print('-'*30)
lat = tmp[0].get('geometry')['location']['lat']
lng = tmp[0].get('geometry')['location']['lng']
ediyaAdded.loc[idx, '위도'] = lat
ediyaAdded.loc[idx, '경도'] = lng문제 3) 문제 1과 2의 결과를 가지고 이디야 커피는 스타벅스 커피 매장 근처에 있는지 분석하기
- 커피 매장의 주소에서 위도/경도 정보를 가져와서 물리적인 거리 측정
- 도로명 주소로 유추
- folium으로 시각화한 후 육안으로 확인
이디야 지도 시각화
import json
import folium
import warnings
warnings.simplefilter(action='ignore', category='FutureWarning')geo_path = './02. skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding='utf-8'))
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=12, tiles='CartoDB positron')
for idx, rows in ediyaAdded.iterrows():
latitude = rows['위도']
longitude = rows['경도']
if latitude is not None and longitude is not None:
folium.CircleMarker(
location=[rows['위도'], rows['경도']],
radius=1,
color='lightblue'
).add_to(my_map)
my_map- 이디야 지도
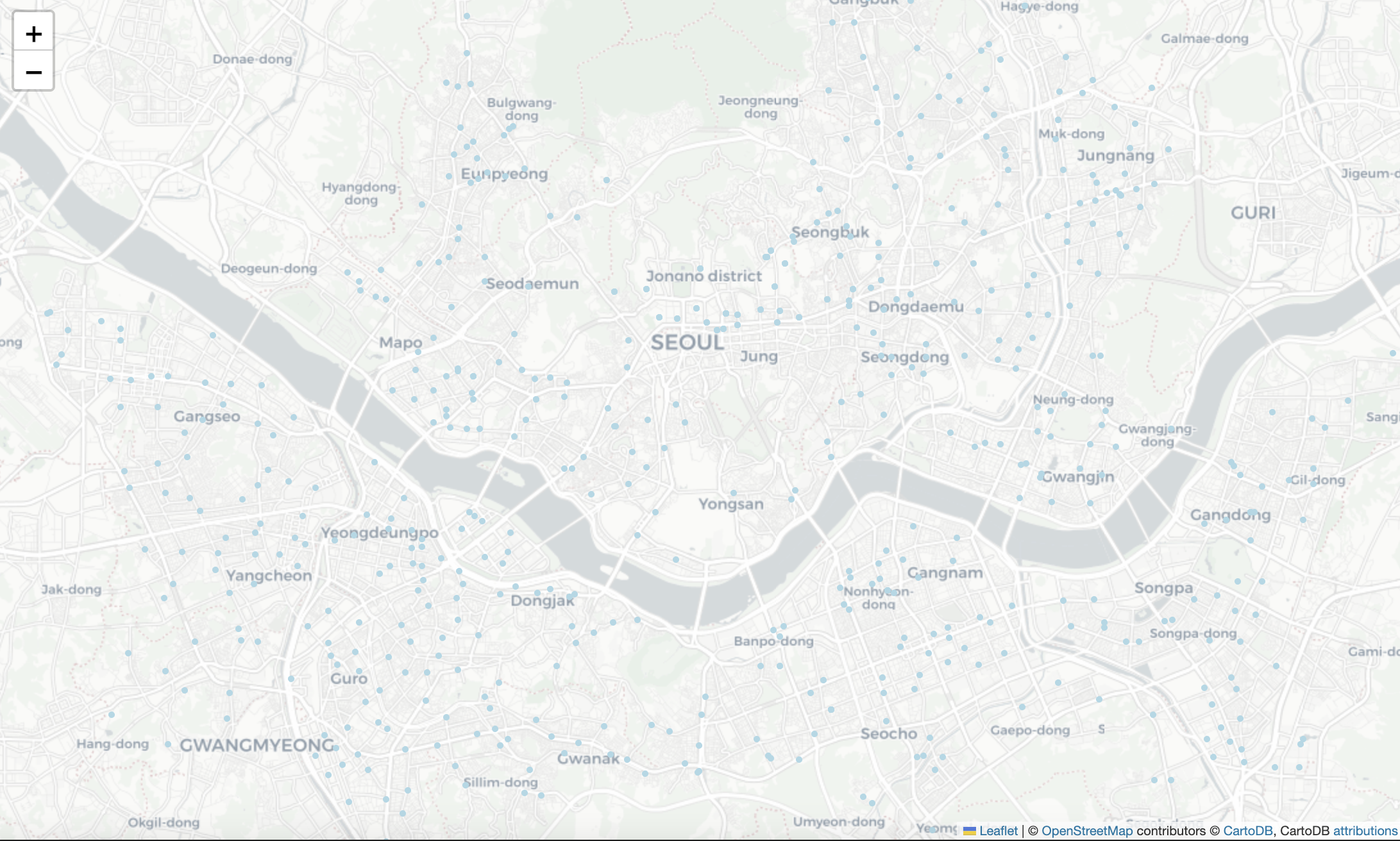
스타벅스 지도 시각화
df_added.reset_index(inplace=True)my_map_2 = folium.Map(location=[37.5502, 126.982], zoom_start=12, tiles='CartoDB positron')
for idx, rows in df_added.iterrows():
latitude = rows['위도']
longitude = rows['경도']
if latitude is not None and longitude is not None:
folium.CircleMarker(
location=[rows['위도'], rows['경도']],
radius=1,
color='green'
).add_to(my_map_2)
my_map_2- 스타벅스 지도
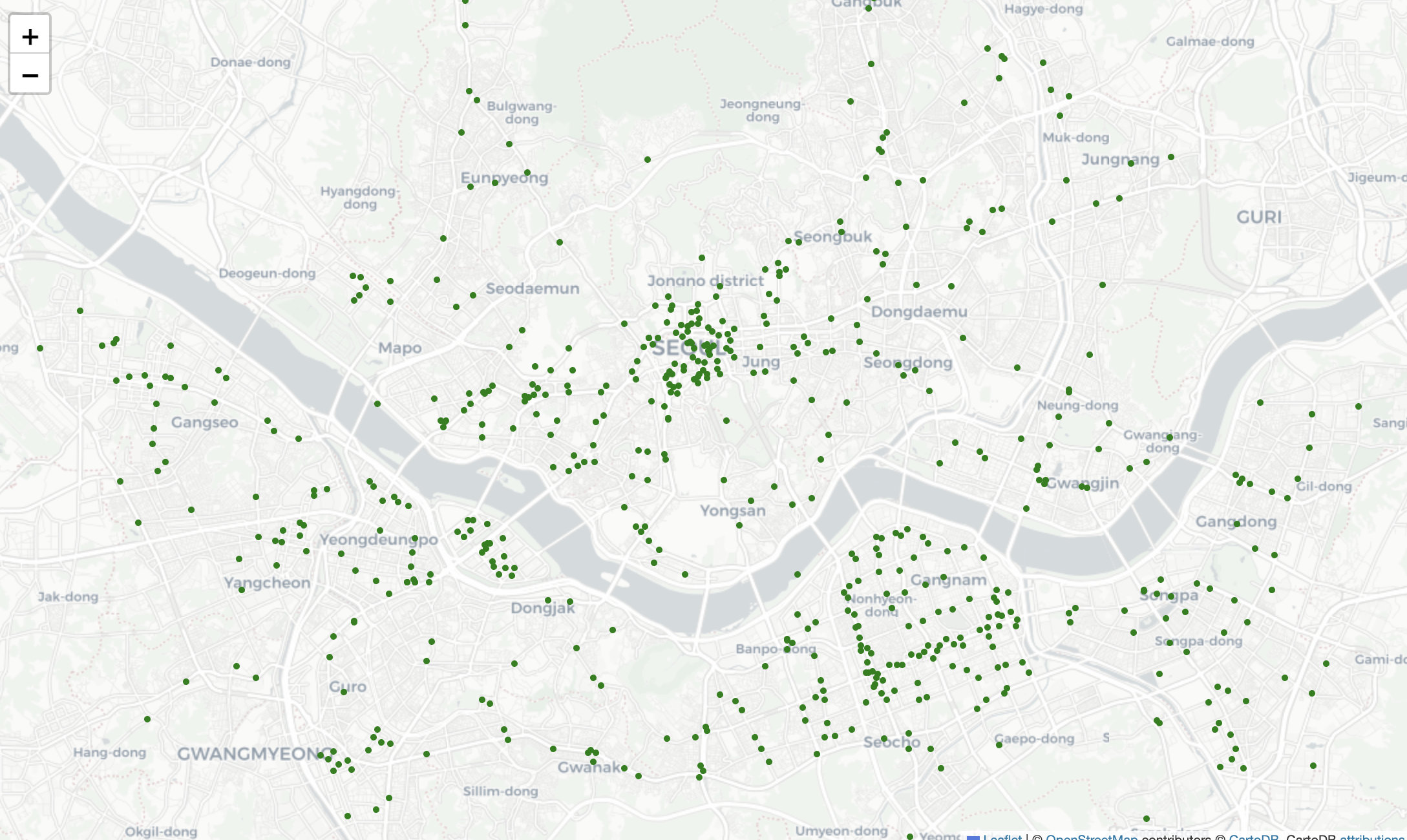
스타벅스, 이디야 지도 시각화 합치기
my_map_3 = folium.Map(location=[37.5502, 126.982], zoom_start=12, tiles='CartoDB positron')
# 이디야
for idx, rows in ediyaAdded.iterrows():
latitude = rows['위도']
longitude = rows['경도']
if latitude is not None and longitude is not None:
folium.CircleMarker(
location=[rows['위도'], rows['경도']],
radius=1,
color='red',
legend_name='이디야'
).add_to(my_map_3)
# 스타벅스
for idx, rows in df_added.iterrows():
latitude = rows['위도']
longitude = rows['경도']
if latitude is not None and longitude is not None:
folium.CircleMarker(
location=[rows['위도'], rows['경도']],
radius=1,
color='green',
legend_name='스타벅스'
).add_to(my_map_3)
my_map_3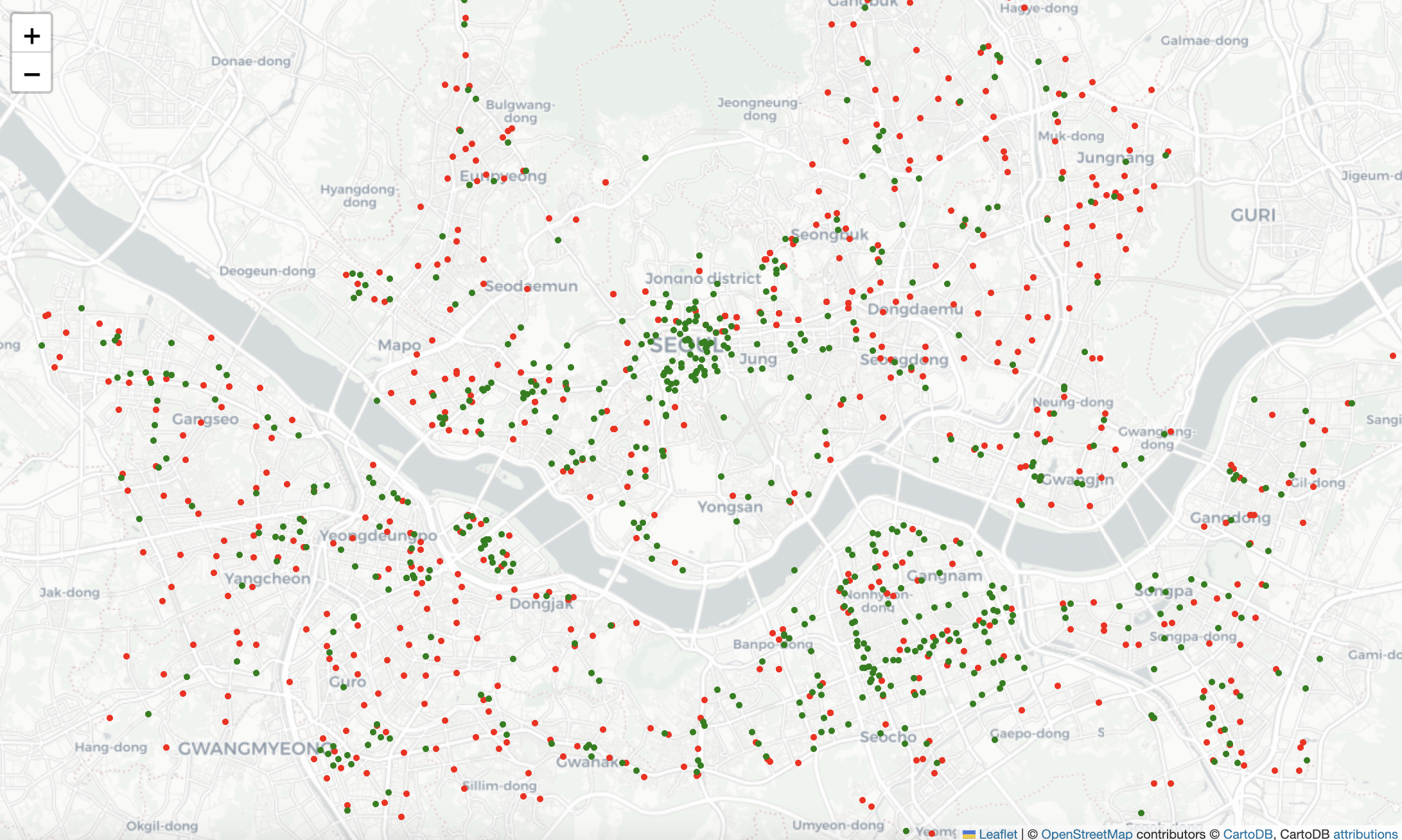
- 이후 이디야와 스타벅스 매장의 위, 경도 차이를 분석하려고 했는데 시간 부족으로 실패했다. 첫 과제라 허둥지둥하고 코드도 비효율적으로 짠 것 같지만 어쨌든 완성~
