- GoogleMaps, Folium, Seaborn, Pivot_table(Pandas)
import numpy as np
import pandas as pd# 데이터 읽기
crime_raw_data = pd.read_csv('../data/02. crime_in_Seoul.csv', thousands=',', encoding='euc-kr') # thousands 숫자값을 문자로 인식할 수 있어서 설정
crime_raw_data.head()- nan
# nan 값 얼마나 있는지 확인
crime_raw_data[crime_raw_data['죄종'].isnull()].head()
# nan 값 없는 데이터만 가져오기
crime_raw_data = crime_raw_data[crime_raw_data['죄종'].notnull()] 📌 Pivot table
- index, value
# Name 컬럼을 인덱스로 설정(Name 기준으로 정리 - values 써주기)
pd.pivot_table(df, index="Name", values=['Account', 'Quantity', 'Price'])
or
df.pivot_table(index='Name', values=['Account', 'Quantity', 'Price'])# 멀티 인덱스 설정
df.pivot_table(index=["Name", 'Rep', 'Manager'], values=['Account', 'Quantity', 'Price'])- aggfunc
# Price column sum 연산 적용
df.pivot_table(
index=['Manager', 'Rep'],
values='Price',
aggfunc=np.sum
)- columns 설정
# Product를 컬럼으로 지정
df.pivot_table(
index=['Manager', 'Rep'],
values='Price',
columns = 'Product',
aggfunc=np.sum
)# Nan 값 설정 : fill_value
df.pivot_table(
index=['Manager', 'Rep'],
values='Price',
columns = 'Product',
aggfunc=np.sum,
fill_value=0
)# aggfunc 2개 이상 설정
df.pivot_table(index=['Manager', 'Rep', 'Product'],
values=['Price', 'Quantity'],
aggfunc=np.sum,
fill_value=0,
margins=True) #총계(All) 추가📌 서울시 범죄 현황 데이터 정리
- droplevel
# 다중 컬럼에서 특정 컬럼 제거
crime_station.columns = crime_station.columns.droplevel([0, 1]) 📖 pip 명령과 conda 명령
pip 명령
- python의 공식 모듈 관리자
pip list: 현재 설치된 모듈 리스트 반환pip install module_name: 모듈 설치pip uninstall module_name: 설치된 모듈 제거- jupyter notebook: 앞에 ! 쓰거나 get_ipython().system("명령")
!pip listorget_ipython().system("pip list")conda 명령
pip응 사용하면 conda 환경에서 dependency 관리가 정확하지 않을 수 있으므로 아나콘다에서는 가급적 conda 명령으로 모듈을 관리하는 것이 좋다.
conda list: 설치된 모듈 listconda install module_name: 모듈 설치conda uninstall module_name: 모듈 제거conda install -c channel_name module_neme: 지정된 배포 채널에서 모듈 설치
📌 Google Maps API 설치
import googlemaps
gmaps_key = "발급받은 geocoding api key 값"
gmaps = googlemaps.Client(key=gmaps_key)
gmaps.geocode("서울영등포경찰서", language='ko')📌 Python의 반복문
list comprehension
[n ** 2 for n in range(0, 10)]
>>>
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]Pandas에 잘 맞춰진 반복문용 명령 iterrows()
- Pandas 데이터 프레임은 대부분 2차원
- 이럴 때 for문을 사용하면, n번째라는 지정을 반복해서 가독률이 떨어짐
- Pandas 데이터 프레임으로 반복문을 만들 때 iterrows() 옵션을 사용하면 편함
- 받을 때, 인덱스와 내용으로 나누어 받는 것만 주의
📌 Google Maps를 이용한 데이터 정리
tmp = gmaps.geocode("서울영등포경찰서", language='ko')
type(tmp[0].get("geometry")["location"]) # dict
print(tmp[0].get("geometry")["location"]["lat"]) # 위도
print(tmp[0].get("geometry")["location"]["lng"]) # 경도tmp[0].get("formatted_address").split()
>>>
['대한민국', '서울특별시', '영등포구', '국회대로', '608']- 컬럼 추가 -> NaN 값으로 초기화
crime_station["구별"] = np.nan
crime_station["lat"] = np.nan
crime_station["lng"] = np.nan- 반복문 이용해서 NaN 채워주기
count = 0
for idx, rows in crime_station.iterrows():
station_name = "서울" + str(idx) + "경찰서"
tmp = gmaps.geocode(station_name, language="ko")
tmp[0].get("formatted_address")
tmp_gu = tmp[0].get("formatted_address")
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
crime_station.loc[idx, 'lat'] = lat
crime_station.loc[idx, 'lng'] = lng
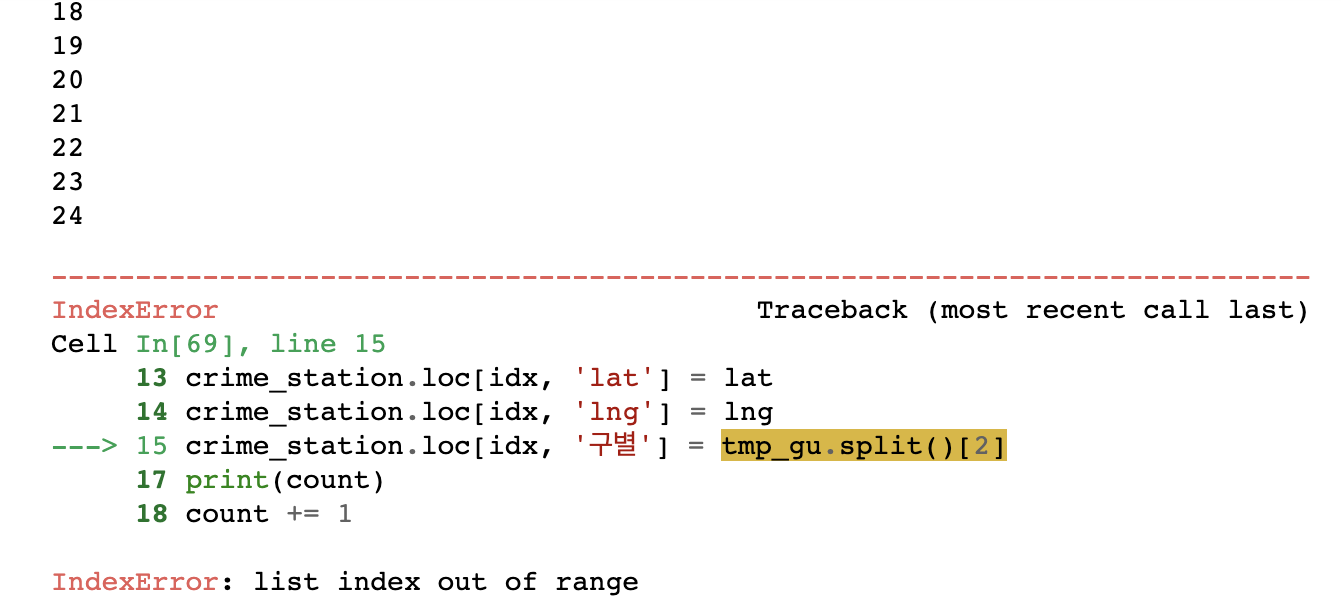
crime_station.loc[idx, '구별'] = tmp_gu.split()[2]
print(count)
count += 1
IndexError 가 떴다.for idx, rows in crime_station.iterrows(): station_name = "서울" + str(idx) + "경찰서" tmp = gmaps.geocode(station_name, language="ko") print(tmp[0].get('formatted_address'))
불러온 자료를 확인해 보니, 왜인지 모르겠지만 은평구 자리가 비어 있었다.count = 0 for idx, rows in crime_station.iterrows(): station_name = "서울" + str(idx) + "경찰서" tmp = gmaps.geocode(station_name, language="ko") tmp[0].get("formatted_address") tmp_gu = tmp[0].get("formatted_address") lat = tmp[0].get("geometry")["location"]["lat"] lng = tmp[0].get("geometry")["location"]["lng"] crime_station.loc[idx, 'lat'] = lat crime_station.loc[idx, 'lng'] = lng # 은평구 오류 if idx == "은평": crime_station.loc[idx, '구별'] = "은평구" continue crime_station.loc[idx, '구별'] = tmp_gu.split()[2] print(count) count += 1그래서 그냥 은평구는 수동으로 추가..
crime_station찍어서 확인해 보면 잘 들어가 있다.

crime_station.columns.get_level_values(0)
>>>
Index(['강간', '강간', '강도', '강도', '살인', '살인', '절도', '절도', '폭력', '폭력', '구별', 'lat',
'lng'],
dtype='object', name='죄종')crime_station.columns.get_level_values(0)[2] + crime_station.columns.get_level_values(1)[2]
>>>
'강도검거'- list comprehension
tmp = [
crime_station.columns.get_level_values(0)[n] + crime_station.columns.get_level_values(1)[n]
for n in range(0, len(crime_station.columns.get_level_values(0)))
]전: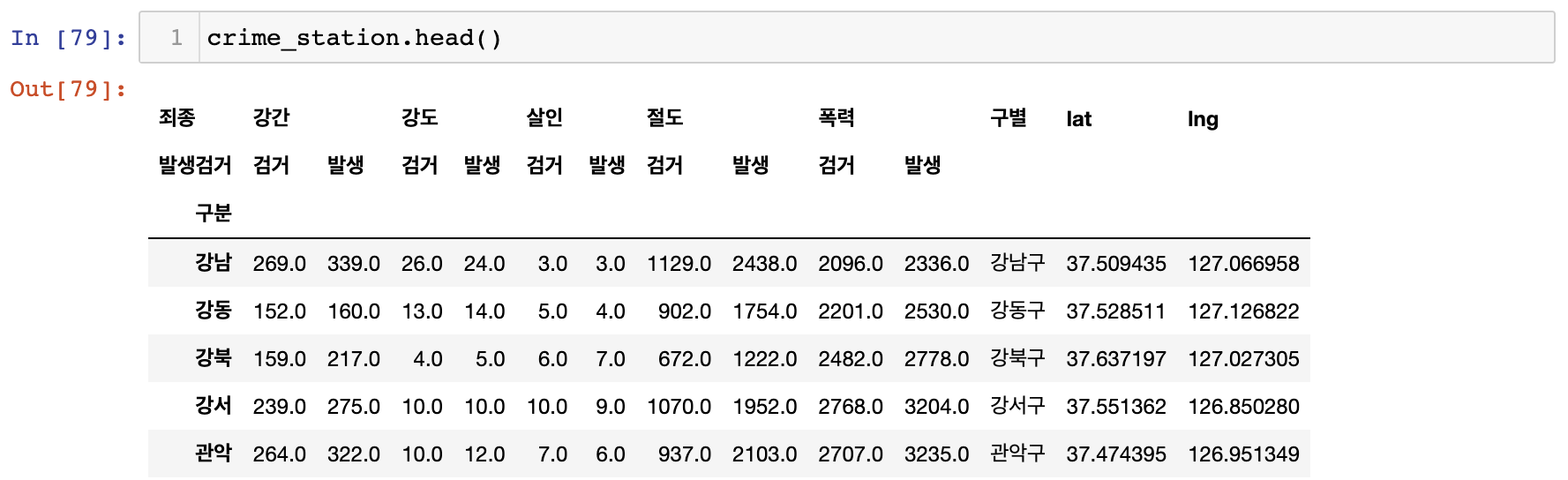
후: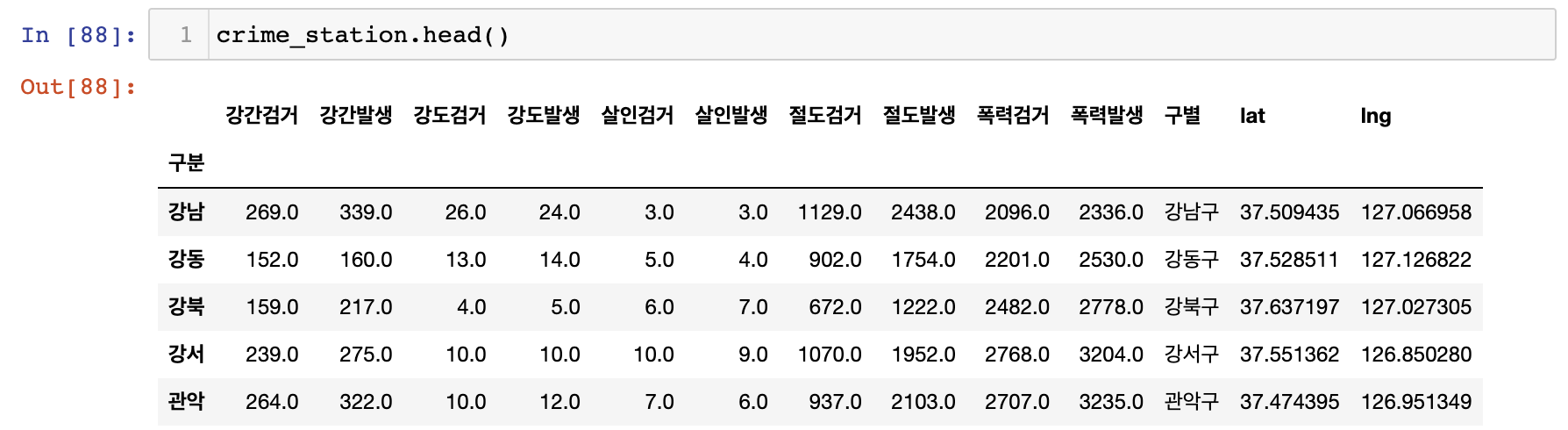
# 데이터 저장
crime_station.to_csv("../data/02. crime_in_Seoul_raw.csv", sep=',', encoding='utf-8')