Iris Classification
- 품종 분류: Versicolor, Virginica, Setosa
- 꽃잎(petal), 꽃받침(sepal)의 길이/너비 정보
from sklearn.datasets import load_iris
iris = load.iris()- sklearn의 datasets은 python의 dict형과 유사
iris.keys()print(iris['DESCR'])print(iris['target_names'])print(iris['target'])iris.datapandas
import pandas as pd
# dataframe으로 만들기
iris_pd = pd.DataFrame(iris.data, columns=iris.feature_names)
# 품종 정보 포함
iris_pd['species'] = iris.target
iris_pd.head() matplotlib, seaborn
import matplotlib.pyplot as plt
import seaborn as snsboxplot
plt.figure(figsize=(12, 6))
sns.boxplot(x='sepal length (cm)', y='species', data=iris_pd, orient='h')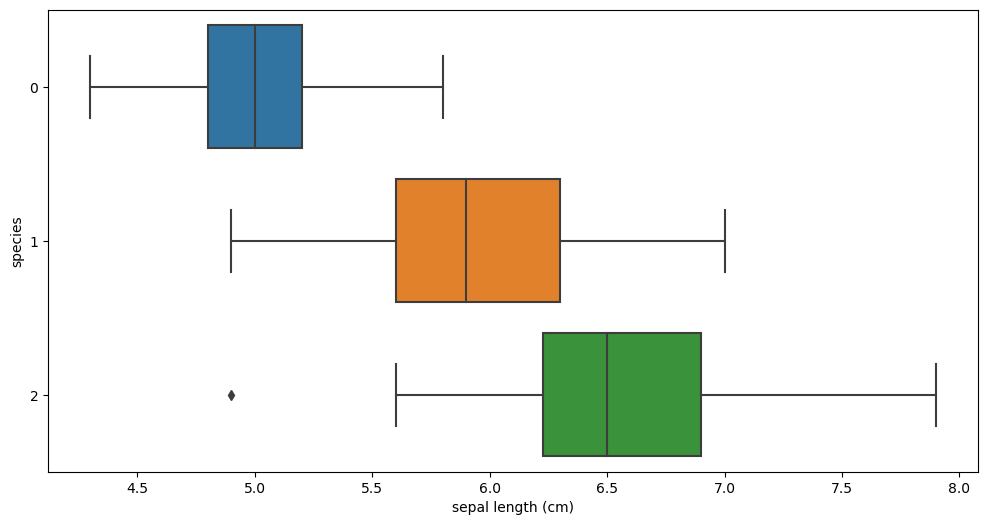
plt.figure(figsize=(12, 6))
sns.boxplot(x='petal length (cm)', y='species', data=iris_pd, orient='h');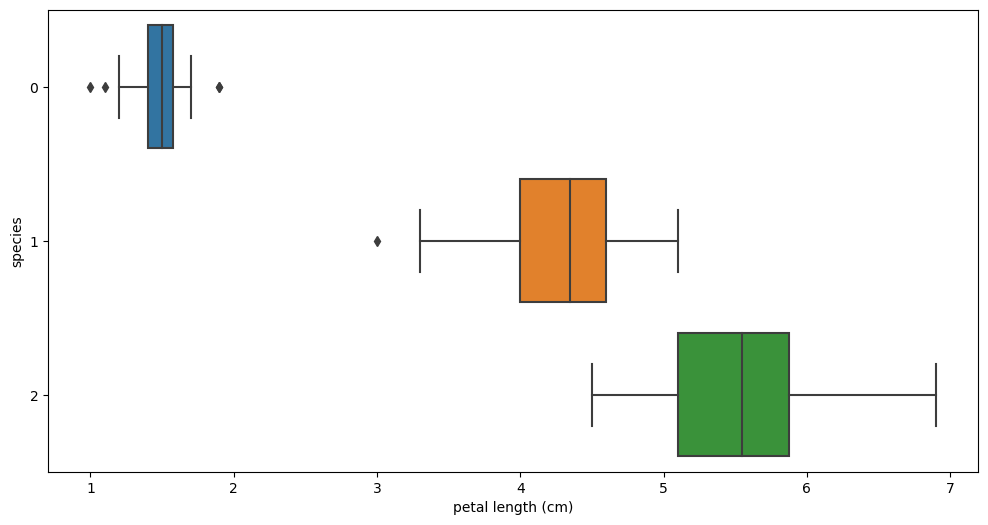
plt.figure(figsize=(12, 6))
sns.boxplot(x='petal width (cm)', y='species', data=iris_pd, orient='h');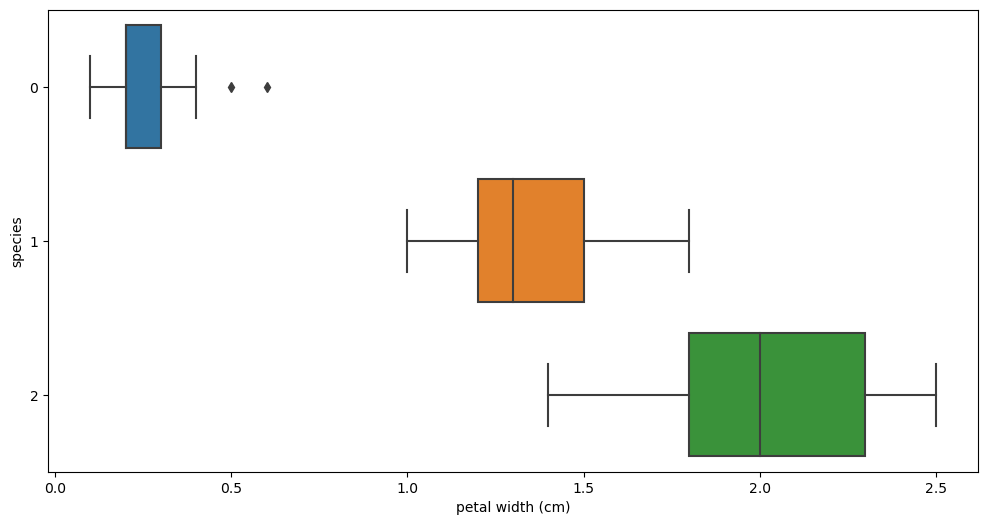
pairplot
sns.pairplot(iris_pd, hue='species');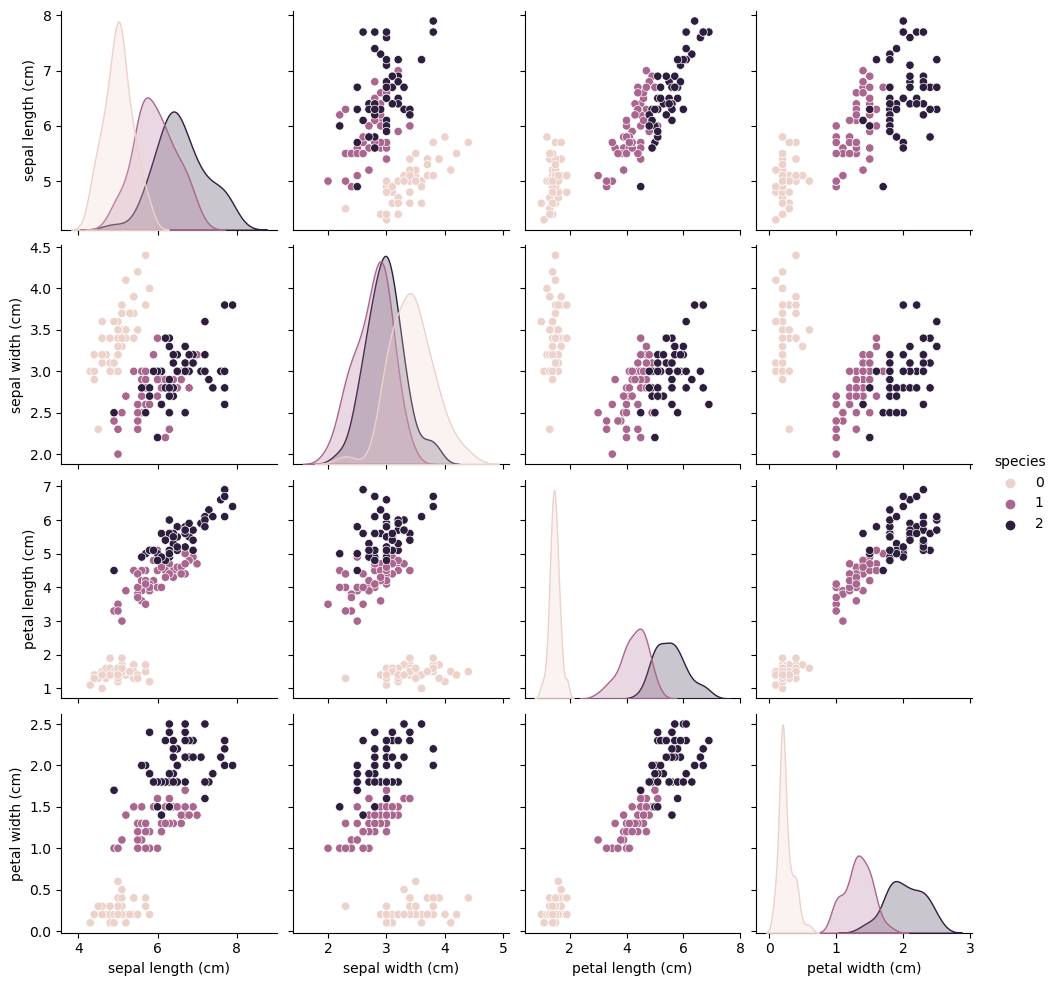
Decision Tree
scatterplot
plt.figure(figsize=(12, 6))
sns.scatterplot(x='petal length (cm)', y='petal width (cm)',
data=iris_pd, hue='species', palette='Set2');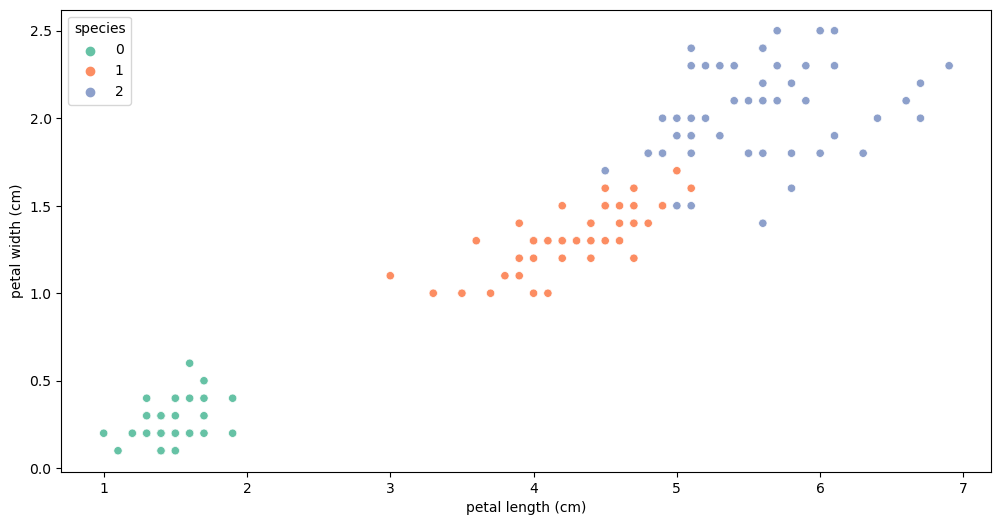
- 데이터 변경
iris_12 = iris_pd[iris_pd['species']!=0] # setosa 뺌DT 분할 기준 (split criterion0
import numpy as np
# 엔트로피
p = np.arange(0.001, 1, 0.001) # 0.001 부터 1까지 0.001 간격
plt.grid()
plt.title('$-p \log_{2}{p}$')
plt.plot(p, -p*np.log2(p));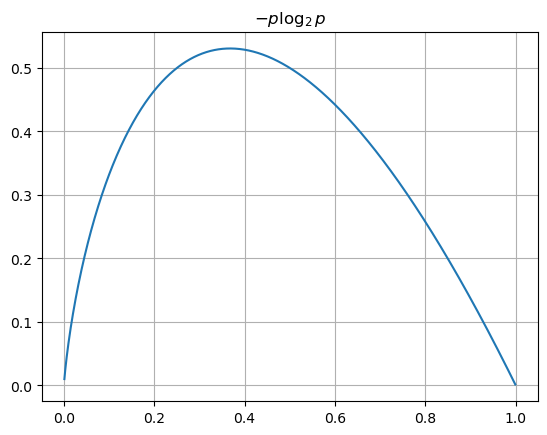
scikit learn
iris.data.shape --> (150, 4) == 150행 4열
- fit: 학습해
fit(학습재료, 정답)
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier()
iris_tree.fit(iris.data[:, 2:], iris.target)- accuracy 확인
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree.predict(iris.data[:, 2:])
y_pred_tr# 원래 정답
iris.target# 정확도
accuracy_score(iris.target, y_pred_tr)- tree model visualization 시각화
from sklearn.tree import plot_tree
plt.figure(figsize=(12, 8))
plot_tree(iris_tree);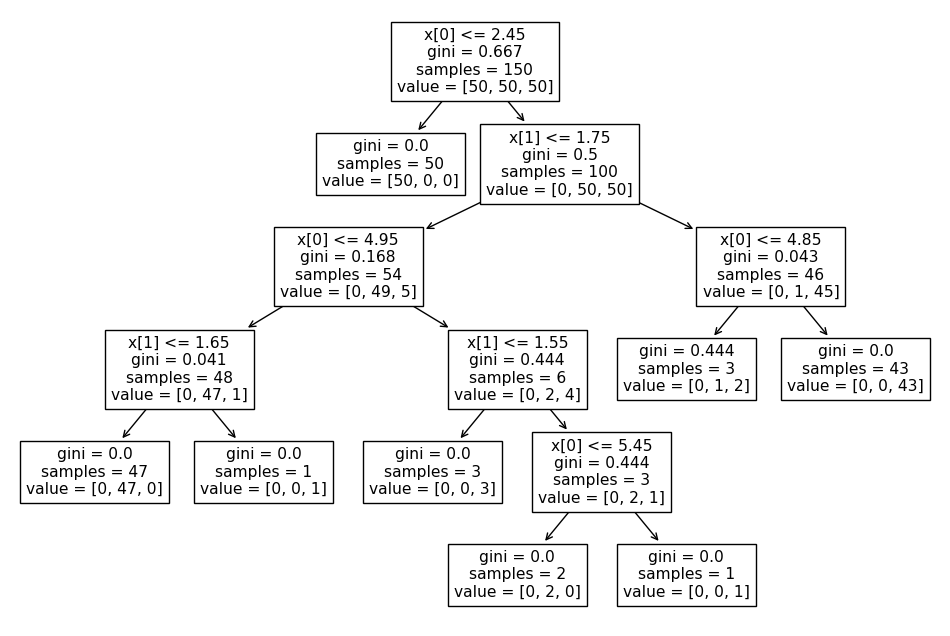
- DT가 어떻게 데이터 분류했는지 확인
- 결정 경계 확인
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14, 8))
plot_decision_regions(X=iris.data[:, 2:], y=iris.target, clf=iris_tree, legend=2)
plt.show()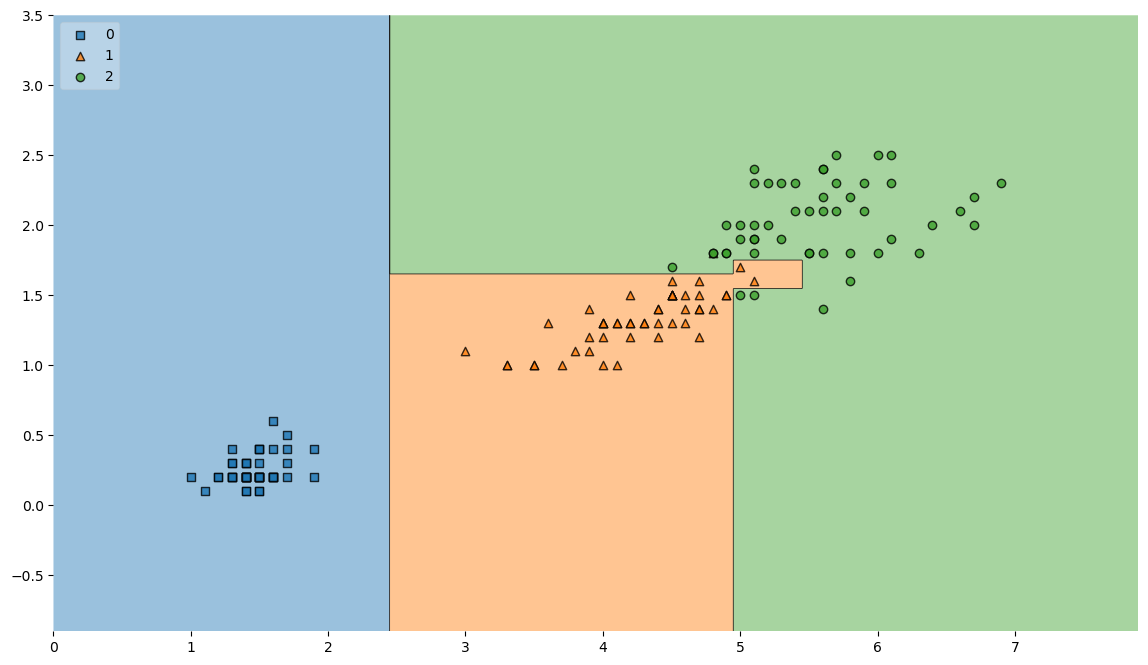
--> 결정 경계 복잡함, accuracy 높음
데이터 나누기
- 데이터를 train/test 로 분리
from sklearn.model_selection import train_test_split
features = iris.data[:, 2:]
labels = iris.target# test data: 20%, 훈련용: 80%
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=13) X_train.shape, X_test.shape--> ((120, 2), (30, 2))
np.unique(y_test, return_counts=True)--> (array([0, 1, 2]), array([ 9, 8, 13]))
- 이상적: [10개, 10개, 10개] --> stratify option으로 맞추기
- train 비율 맞추기 -
stratify
X_train, X_test, y_train, y_test = train_test_split(features, labels,
test_size=0.2,
stratify=labels,
random_state=13) np.unique(y_test, return_counts=True)- train만 대상으로 decision tree model 만들어 보기
tree depth: tree 세로길이, depth 깊을수록 내가 준 데이터 대상 성능 높아짐 --> 규제 - 너무 최적화 안 되게 모델 제한
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)plt.figure()
plot_tree(iris_tree);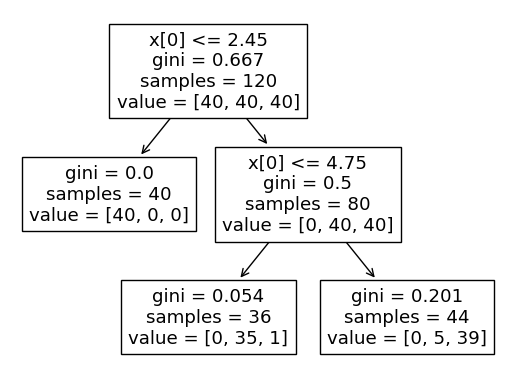
- accuracy
y_pred_tr = iris_tree.predict(iris.data[:, 2:])
accuracy_score(iris.target, y_pred_tr)--> 0.9533333333333334
- 결정경계
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14, 8))
plot_decision_regions(X=X_train, y=y_train, clf=iris_tree, legend=2)
plt.show()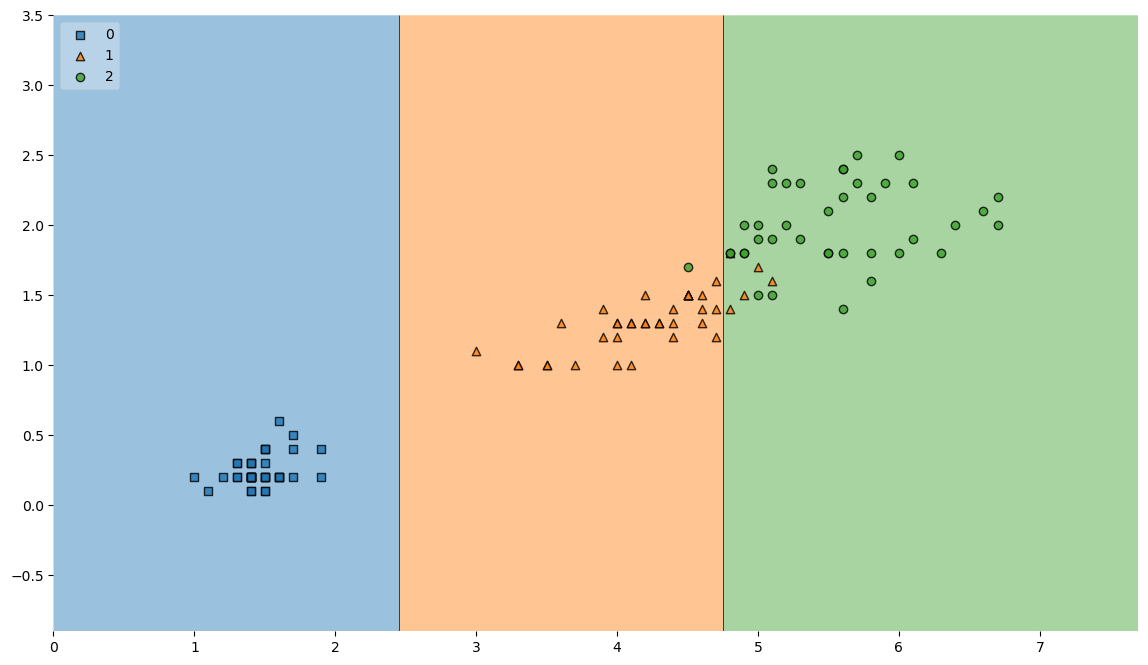
# feature 4개
features = iris.data
labels = iris.target
X_train, X_test, y_train, y_test = train_test_split(features, labels,
test_size=0.2,
stratify=labels,
random_state=13
)
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)plt.figure()
plot_tree(iris_tree);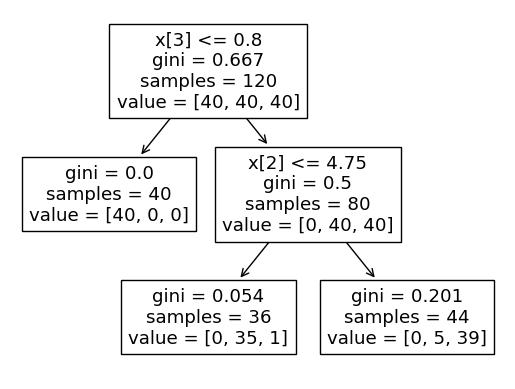
모델 사용법
- 길에서 주운 iris: sepal 과 petal length, width
test_data = np.array([[4.3, 2., 1.2, 1.]])
iris_tree.predict(test_data)iris_tree.predict_proba(test_data) --> array([[0. , 0.97222222, 0.02777778]])
--> setosa 일 확률 0, versicolor 97%, virginica 2% by 내 decision tree 모델
- 주요 특성 확인
iris_tree.feature_importances_zip, unpacking
결과 보여주는 기술
dict(zip(iris.feature_names, iris_tree.feature_importances_))
# petal length, petal width 가 중요{'sepal length (cm)': 0.0,
'sepal width (cm)': 0.0,
'petal length (cm)': 0.42189781021897804,
'petal width (cm)': 0.578102189781022}
- list을 tuple로 zip
list1 = ['a', 'b', 'c']
list2 = [1, 2, 3]
pairs = [pair for pair in zip(list1, list2)]
pairs--> [('a', 1), ('b', 2), ('c', 3)]
dict(zip(list1, list2))--> `{'a': 1, 'b': 2, 'c': 3}
x, y = zip(*pairs)--> x: ('a', 'b', 'c'), y: (1, 2, 3)
