Python 크롤링
먼저 크롤링을 하려면 2가지를 해야한다.
원하는 웹페이지에 Request(요청) -> requests를 가지고 활용할 수 있다.
import requests # requests 라이브러리 설치 필요
r = requests.get('URL')
rjson = r.json()F12를 눌러서 가지고 오고자하는 곳을 찍고 Elements 창에서 copy -> copy select를 한다.
이렇게 복사를 해서 파이참에 붙여넣으면 공통되는 부분이 있다는 것을 알 수 있다.
#old_content > table > tbody > tr:nth-child(3) > td.title > div > a
#old_content > table > tbody > tr:nth-child(4) > td.title > div > a이부분의 공통으로 들어가는 부분을
movies = soup.select('#old_content > table > tbody > tr')select를 이용해 묶어주었다.
그리고 for문으로
for movie in movies:
a = movie.select_one('td.title > div > a')
if a is not None:
print(a.text)movies안에 movie를 select_one을 사용해서 공통 부분을 넣어주고
None이 아니면 a를 text로 출력하게 해서 콘솔에 영화목록을 가지고 올 수 있었다.
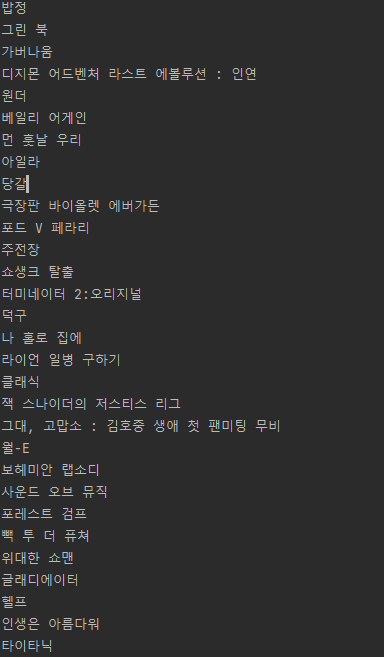
순위와 평점 크롤링하기!
순위 가져오기
순위를 개발자도구에서 찍고, 위의 공통된 태그는 제외하고
select_one으로 순위를 가지고 온다. 순위는 alt에 숫자로 표기되어
rank = movie.select_one('td:nth-child(1) > img')['alt']
로 구할 수 있다.
star 도 공통된 태그를 제외하고
select_one을 가지고 코드를 작성하면
star = movie.select_one('td.point').text
평점을 가지고 온다. 점수는 text기 때문에 .text를 사용한다.
크롤링
크롤링을 하면서 하나하나 작성할 때 마다 어떤 것이 표기가 되는지 콘솔로 다시 한번
확인을 해볼 필요가 있겠다.
.... 심심하면 크롤링을 해서 가져오는 콘텐츠도 한번 해봐야겠다.

#공부중 #협업 #소통중시 #백엔드개발자 #능동적 #워커홀릭 #스파르타코딩 #항해99 #미니튜터 #Nudge #ENTJ #브레인스토밍 #아이디어뱅크