페이징 쿼리?

- 데이터베이스와 어플리케이션 성능최적화에 있어 중요한 역할을 함
페이징 쿼리 작성

-
LIMIT & OFFSET 구문 사용 보통
-
항상 최선의 방식이 아님
-
오히려 DBMS 서버에 더많은 부하 발생
-
데이터베이스는 오프셋에 지정된 위치까지 모든 레코드를 순차적으로 읽은후에야 원하는 데이터 반환
-
이것은 디비가 특정 오프셋 이후 데이터만 가져올 수 없다는 것을 뜻함
-
앞에꺼를 다읽고 가져와야 되는구나
-
페이지 오프셋 값이 올라갈수록 더 많은 데이터를 읽어야되고 시스템은 더 큰 부담을 줌

- 쿼리의 효율 성능적인 부분 고려.. LIMIT OFFSET 사용하지 말고
- 범위 기반
- 데이터 개수 기반 방식
범위 기반 방식


-
어떤 범위로 나눠서 데이터 나눠서 조회
-
쿼리에서 LIMIT 절이 사용 되지않는 다는 점에서 기존 페이징 방식과 구별 됨.
-
테이블에 대해 날짜나 숫자 기반의 일정한 범ㅇ뉘로 데이터 나눠서 조회 시 유리함 (대량 데이터)
-
EX) 테이블 생성일자 컬럼 기준으로 한달치 데이이터를 일주일 단위로 나눠
-
처리하거나 오토 인크리먼트 컬럼 값 바탕으로 일정한 숫자 범위나눠서 처리
-
장점: 쿼리 단순성 여러 쿼리 나눠실행해도 사용하는 컬럼 동일 유지
-
특정 날짜 컬럼에 대해 기간을 나누어 조회하는 경우 쿼리 성능향상을 위해
-
해당 컬럼에 대한 인덱스 미리 생성해 두는 것이 좋음
데이터 개수 기반 방식


- 10~20건과 같이 지정된 건수만 큼 결과 데이터 반환
- 대량의 데이터를 다루는 배치작업보단 , 일반 서비스에서 사용자 단위 데이터등 조회할 때 주로 사용
- ORDER BY와 리밋절이 함께 사용 됨
- 처음 조회시 그 이후 쿼리 실행시 형태가 달라짐
- 인피니트 스크롤 방식 쿼리 인거같다
- 쿼리에서 오더바이절이 사용되 쿼리처리시 내부적으로 정렬이 발생되지않고
- 지정된 건수만큼 데이터 읽어서 반환할수 있도록 적절한 인덱스를 사전에 생성해 두는 것이 중요
- 예시 쿼리의 경우 페이먼트 테이블에 유저아이디와 아이디로 구성된 인덱스가
- 있으므로 이를 사용해 정렬을 수행하지않고 리밋절에 명시된 갯수만큼 반환함
데이터 개수 기반 방식 (범위 조건 사용시)

- ID 와 날짜를 인덱스
왜 ORDER BY 절에 FINISHED_AT이 포함되어야 할까?

예제 N회차 이후

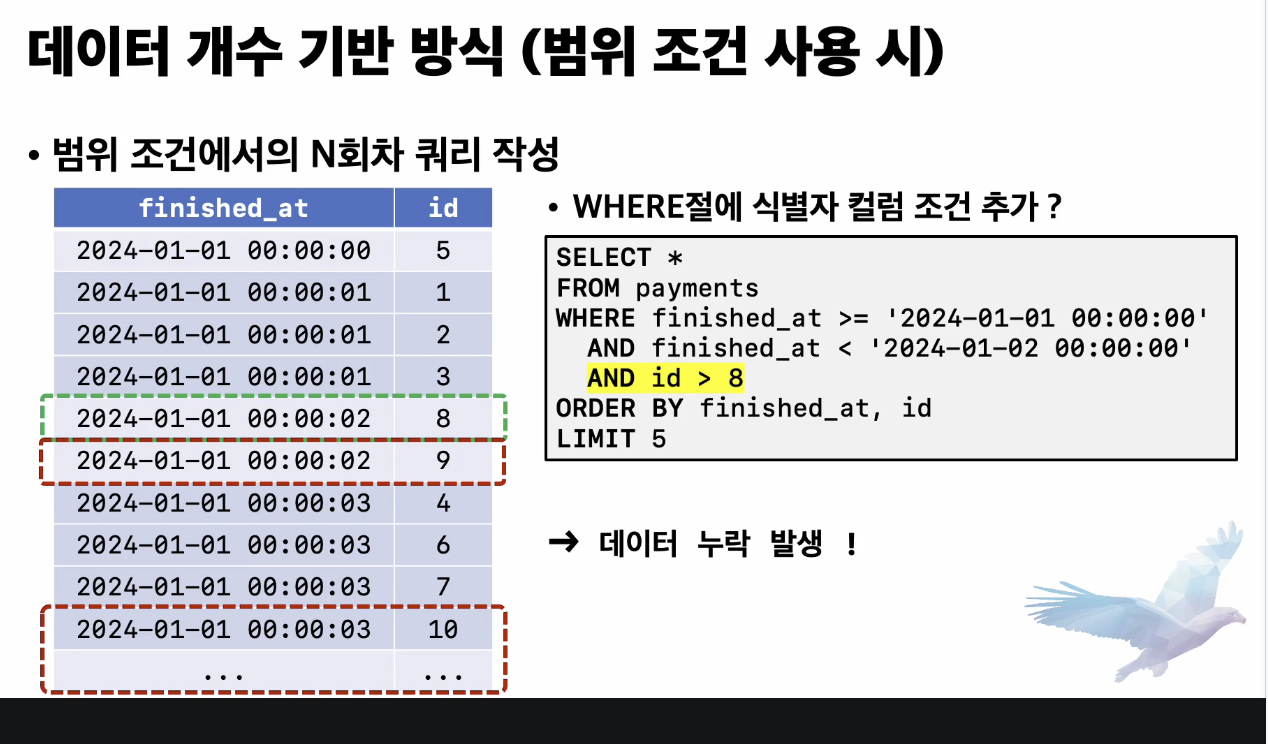
- N회차 쿼리 조회시 주의사항
- 누락이 발생될 수 있다
- 그림에서와같이 8이상의 데이터들로 조회시
- 중간의 3개의 데이터가 누락됨
- FINISHIED_aT 컬럼과 ID 컬럼의 값 순서가 다르기 때문에 이처럼
- 다음 순서의 데이터를 읽기 위해 쿼리에 ID 컬럼에 대한 조건만 추가해서는 안됨
수정

-
누락을 방지하기위해 오른쪽과 같이 쿼리를 작성해야됨
-
계속보다보니 인피니트 스크롤 쿼리구현시 예제랑 똑같다
-
두개의 조건이 OR로 연결
첫번째 조건 : 마지막 순서에 해당되는 FINISHED_AT , ID 값이 조건으로 주어지고
마지막 데이터의 FINISED_AT 과 같으면서 ID 값은 더큰 조건 -
이전에 반환된 마지막 데이터의 경우 같은 finishedAt값을 가지는 데이터가 여러개 있고
-
같은 값을 가지는 데이터중 그 다음 순서에 해당되는 데이터를 읽어와야 됨으로
-
finishiedAt 값은 이전에 반환된 마지막 데이터와 동일하면서 id 값은 이보다 큰
-
데이터를 반환하도록 조건이 주어짐
두번째 조건 : 그 다음 순서의 finished_at 값에 해당하는 데이터를 불러와야 됨
이전에 반환된 마지막 데이터의 finsished_at 보다 크고 최초 조건으로 주어졌던
2024 1/2 일보다는 작은 날짜 값을 가지는 경우 대한 조건이 or 로 추가 됨범위 조건 사용하는 경우
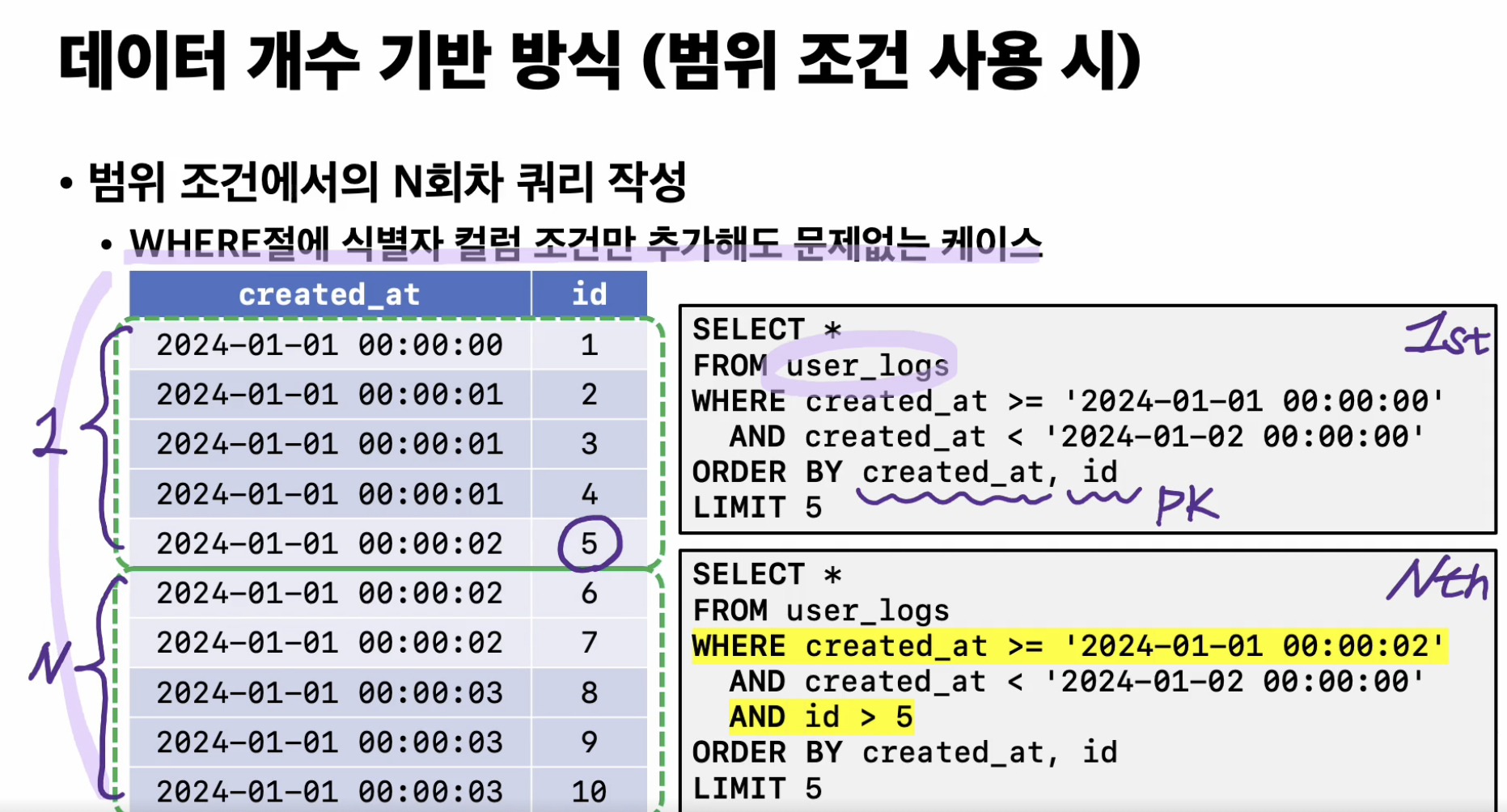
-
where절에 식별자 컬럼 조건만 추가해도 문제없는 케이스
-
created A 컬럼의 값순서와 id 컬럼의 값 순서가 동일한 경우
-
쿼리 처능상향을위해 create_at 이전에 반환된 마지막 날짜 값으로 지정해줘야 된다.
-
이처럼 범위 조건으로 주어진 컬럼과 식별자 컬럼인 ID 컬럼의 값순서가 동일한 경우
-
n 회차 쿼리가 1회차 쿼리의 식별자 컬럼에 대한 조건만 추가적으로 명시하는 형태로 사용 될 수 있다
마무리(정리)



LIMIT & OFFSET 구문의 문제점
- 이 방식은 데이터베이스가 OFFSET까지 모든 레코드를 읽어야 해서 비효율적
- 페이지 번호가 커질수록 데이터베이스에 더 큰 부담을 줌
- 예를 들어, 1000번째 페이지를 요청하면 데이터베이스는 999페이지 분량의 데이터를 읽고 버린 후에야 원하는 데이터를 반환
범위 기반 방식
-
주로 배치 작업 등에서 많이 사용되는 방식
-
이 방식은 날짜나 ID 같은 특정 컬럼의 값을 기준으로 데이터를 나눠서 조회
-
예를 들어, "2023년 1월 1일부터 1월 7일까지의 데이터"처럼 범위를 정해서 조회합니다. 이 방식은 LIMIT을 사용하지 않아 데이터베이스 부하를 줄일수 있다.
데이터 개수 기반 방식
- 이 방식은 주로 사용자 인터페이스에서 많이 사용. "다음 20개 항목 보기"와 같은 기능을 구현할 때 유용
- ORDER BY와 LIMIT을 함께 사용하며, 첫 번째 쿼리 이후의 쿼리는 이전에 마지막으로 받은 데이터의 ID를 기준으로 조회
인덱스의 중요성
- 효율적인 쿼리 실행을 위해 적절한 인덱스를 생성하는 것이 중요.
- 예를 들어, ORDER BY에 사용되는 컬럼들로 구성된 인덱스가 있으면 데이터베이스는 정렬 작업 없이 빠르게 데이터를 반환
데이터 누락 방지
- 날짜와 ID를 함께 사용할 때, 날짜가 같은 데이터가 여러 개 있을 경우 일부 데이터가 누락
- 이를 방지하기 위해 두 가지 조건(같은 날짜의 다음 ID, 다음 날짜의 첫 ID)을 OR로 연결하여 쿼리를 작성
