
- 실제 카운트 올 쿼리가 성능이 나은 경우보단 / 셀렉트 올 쿼리와 거의 동일한 경우가 더 많다
- 일반적으로 서비스 구현 요건상 셀렉트 올 쿼리는 리미트 조건이 거의 일반적으로 같이 사용이 됨
- 그런데 카운트 올 쿼리는 리미트 조건없이 실행되는 경우가 일반적임
- 설령 countAllQuery limit 조건이 있다 하더라도 여기에 사용된 limit 조건은 의미가 없다
- mysql 서버가 제거를 해버리기 때문!
- 그래서 selectAllQuery보다는 countAllQuery의 부하가 훨씬 크고 많이 시간이 많이 걸림
- 최근 ORM을 사용하면 직접 사용하면 개발자가 직접쿼리를 안봐서 확인하지 않는다
- 단순히 레코드 건수 확인 위해 orm 기능 호출 했을 뿐인데 실제 orm라이브러리는
- 의도치 않게 훨씬 부하가 높은 count distinct쿼리를 실행 하는 경우도 있음
- 실제 count All 과 count distinct 작동 방식이 차이가 있어 큰 성능 차이 보일 수 있음
정리
COUNT() vs SELECT
- 일반적으로 COUNT()와 SELECT 의 성능이 비슷한 경우가 많음
- 하지만 실제 상황에서는 COUNT(*)가 더 느릴 수 있다.
- COUNT(*)는 모든 행을 세야 하므로, 큰 테이블에서는 시간이 오래 걸림
LIMIT 조건의 영향
- SELECT * 쿼리는 주로 LIMIT와 함께 사용
- COUNT(*) 쿼리는 보통 LIMIT 없이 사용
- COUNT(*) 쿼리에 LIMIT를 사용해도 MySQL이 이를 무시
- MySQL 옵티마이저는 COUNT(*)에서 LIMIT가 의미 없다고 판단하여 제거
ORM 사용 시 주의점
- ORM을 사용하면 개발자가 실제 쿼리를 확인 잘 안함
- 단순한 레코드 수 확인이 의도치 않게 복잡한 쿼리로 변환될 수 있다.
COUNT(*) vs COUNT(DISTINCT)
- COUNT(DISTINCT)는 COUNT(*)보다 더 많은 리소스를 사용합니다.
- 큰 데이터셋에서 성능 차이가 크게 날 수 있음
- COUNT(DISTINCT)는 중복을 제거하고 세야 하므로 추가적인 처리가 필요

-
countALL 과 selectALL 쿼리 차이를 확인하기 위해 두개의 쿼리를 작동해보자
-
where 조건절에는 ix-fd 조건은 인덱스를 사용할 수 있지만
-
non-ix-fd 조건은 인덱스를 사용 X
-
결론적으로 두 개의 쿼리는 커버링 인덱스 실행 계획 사용 X
-
ix-fd 컬럼의 인덱스 이용해 대상 레코드 찾은 후에 데이터파일에서 레코드를 가져오고 non-ixfd 컬럼값이 b인지 비교
-
최종적 반환
-
두개의 쿼리는 동일한 성능
-
select count 는 결과값의 바이트수가 적어 네트워크 사용량이 적지만
-
select all 쿼리는 모든 결과를 보내야 되 결과 바이트가 커짐 네트워크 사용량 많아짐
-
실제 mytsql서버가 데이터파일과 버퍼풀의 페이지를 읽어서 가공하는 작업은 거의 동일한 양 수행하게 됨
-
많은 레코드를 가져와도 표시못해서 limit 으로 페이징으로 가져감
-
결론적으로 select ALL 하고 count는 바이트수가 그리 큰차이는 아님
-
반면 count는 where 조건제를 일치하는 모든 레코드를 잃어야해서 (위에페이징은 일부분만)
-
전체 건수를 확인할 수 있어서 selcet counter 쿼리시간은 처리해야 하는 레코드 건수에 따라서
-
엄청 느려질 수 있음
-
ex) 게시판 갯수 100만건 select ALL은 20건만 count ALL은 100만건 읽어 5만배 정도의 쿼리 시간이 더많이 걸리게
됨
정리
쿼리 실행 과정
- 두 쿼리 모두 인덱스를 사용할 수 있는 ix-fd 조건과 사용할 수 없는 non-ix-fd 조건을 가정
- 커버링 인덱스는 사용되지 않음
쿼리 처리 성능
- 서버에서의 데이터 처리 과정은 두 쿼리가 거의 동일
- COUNT(*)는 결과 크기가 작아 네트워크 사용량이 적다
- ELECT *는 모든 결과를 전송하므로 네트워크 사용량이 더 많다
LIMIT의 영향
- SELECT * 쿼리는 주로 LIMIT와 함께 사용되어 일부 레코드만 가져옴
- COUNT(*)는 모든 레코드를 읽어야 함
성능 차이의 주요 원인
- SELECT *: LIMIT로 인해 일부 레코드만 처리
- COUNT(*): 모든 레코드를 읽어야 함
실제 예시
- SELECT * LIMIT 20: 20건만 처리
- COUNT(*): 100만 건 모두 처리
- 5만배 차이.
커버링 인덱스란
- 쿼리를 처리하는 데 필요한 모든 데이터가 인덱스에 포함되어 있어, 데이터 파일을 직접 읽지 않고도 인덱스만으로 쿼리를 처리할 수 있는 경우
- 빠른 쿼리 실행: 데이터 파일 접근이 필요 없어 처리 속도가 빠릅니다.
- 디스크 I/O 감소: 인덱스만 읽으므로 디스크 접근이 줄어듭니다.
예시:
테이블: users(id, name, email, age)
인덱스: (name, email)
쿼리: SELECT name, email FROM users WHERE name = 'John';
- 이 경우, name과 email 컬럼만으로 구성된 인덱스가 커버링 인덱스\
- WHERE 절의 조건에 사용되는 컬럼들이 인덱스에 포함
- SELECT 절에서 요청하는 모든 컬럼들도 같은 인덱스에 포함 조건임.

-
count(*) 성능개선
-
정확한 레코드 건수를 확인해야 하는 경우에는 최고의 성능 튜닝은
-
커버링 인덱스 실행계획으로 쿼리를 처리해주게 하면 됨
-
ix-fd1 컬럼 ix-fd2 컬럼으로 인덱스 준비되있따하자
-
select count(*) where ix-fd1 = ? and ix-fd21=?
-
이 2개의 쿼리는 인덱스의 컬럼만으로 쿼리가 처리될 수 있기 때문에 테이블의 데이터를 읽지 않고
-
인덱스만 읽으면 쿼리 처리 완료
-
select count(*) where ix_fd1=? and non_ix_fd1=?
-
select count(non_ix_fd1) where ix_fd1= ?
-
이 두개의 쿼리는 non-ixfd1 컬럼을 사용하고 있는데 이 컬럼은
-
인덱스 정의 컬럼이 아니기 때문에 mysql 서버는 인덱서를 통해 1차 대상 레코더를 찾은 후
-
데이터 파일에서 non-ixfd1 컬럼읽어서 where 조건에 일치하는지 비교해봐야 반환여부 결정
-
다음 쿼리는 non-ixfd1컬럼이 안늘인? notnull인 레코드의 끈수를 카운트해야하기 때문에
-
여전히 데이터 파일을 읽어야함 커버링 인덱스 처리 안됨
-
커버링 인덱스로 쿼리의 실행 계획이 최적화될 수 있도록 함으로서 카운트 올 쿼리의 성능을 매우 빠르게 만듬
-
모든 쿼리를 커버링 인덱스로 튜닝하는건 적절하지 않음
-
일반적으로 서비스에서 카운트 올 쿼리라 하더라도 웨어 조건절에 많은 컬럼들의 비교조건이
-
사용되는데 이 모든 컬럼들을 인덱스에 추가하기에는 사실 성능적인 장점 보단 단점이 훨씬더 커질수 잇음
-
그래서 커버링 인덱스를 이용한 튜닝은 꼭 필요한 경우에만 권장
정리
커버링 인덱스를 이용한 최적화
- 인덱스만으로 쿼리를 처리할 수 있게 하는 방법
- SELECT COUNT(*) WHERE ix_fd1 = ? AND ix_fd2 = ?
- 이 경우 테이블 데이터를 읽지 않고 인덱스만으로 처리 가능
인덱스에 포함되지 않은 컬럼 사용 시
- 예: SELECT COUNT(*) WHERE ix_fd1 = ? AND non_ix_fd1 = ?
- 인덱스로 1차 검색 후 데이터 파일에서 추가 확인 필요
NULL이 아닌 레코드 카운트
- SELECT COUNT(non_ix_fd1) WHERE ix_fd1 = ?
- 데이터 파일 접근이 필요하여 커버링 인덱스 처리 불가
커버링 인덱스 사용의 장단점:
-
장점: 매우 빠른 쿼리 처리
-
단점: 모든 조건 컬럼을 인덱스에 추가하면 성능 저하 가능성
-
꼭 필요한 경우에만 커버링 인덱스 사용 권장
-
모든 쿼리를 커버링 인덱스로 튜닝하는 것은 부적절

-
내부적으로 매우 다른 방식인 두 쿼리
-
countAll은 조건에 일치하는 레코드를 찾아 건수만 확인
-
count Distinct query는 많은 메모리 공간과 cpu 자원을 소모하는 편
-
중복된 레코드를 배제하고 유니크한 값들의 조합인 레코드 대해서만 레코드 건수 반환
-
mysql 서버는 중복 제거용 임시테이블 생성
-
where 조건ㅇ절에 일치하는 레코드를 찾아 임시 테이블에 저장해야 함.
-
이때 임시 테이블에 그냥 인서트하는게 아니라
-
먼저 임시 테이블에서 중복된 값이 있는지 셀럭터 먼저해서 확인하고 중복된 경우 무시 중복되지 않는경우 인서트
-
이렇게 반복 웨어 조건절에 일치하는 레코드를 찾아서 임시테이블에 인서트 하고
-
mysql server는 임시 테이블의 레코더 건수 확인해서 최종적으로 클라이언트로 반환
-
그래서 카운트 디스팅크를 위해서 mysql server는 레코드 건별로 셀럭트와 인서트를 한번 씩 더 실행
-
내부적으로 성능적으로 2~3배 더느려지는 작업방식
-
레코더 건수가 매우 많다면 mysql 서버는 너무 큰 임시테이블이 메모리에 상주하는것을 막기 위해
-
적절한 시점에 임시 테이블에 디스크로 다시 옮겨서 저장하는 작업도 처리하게 됨
-
이렇게 되면 메모리나 cpu 뿐만아니라 디스크 작업까지 과중되면서 쿼리의 성능이 더 느려짐
-
orm 사용한다해도 최종적으로 mysql server로 어떻게 실행되는 지확인해 보자
-
제너럴 로그 활성화해두고 제너럴 로그를 살펴보면서 성능 이슈를 발생하는 쿼리가 있는지 검토하는게 좋음
정리
COUNT(*) vs COUNT(DISTINCT)
- COUNT(*): 조건에 맞는 모든 레코드 수를 셈
- COUNT(DISTINCT): 중복을 제외한 유일한 값의 수를 셈
COUNT(DISTINCT)의 처리 과정
a. 임시 테이블 생성
b. 조건에 맞는 레코드를 찾아 임시 테이블에 저장
- 중복 체크 후 저장 (SELECT → INSERT)
c. 임시 테이블의 최종 레코드 수 반환
COUNT(DISTINCT)의 성능 특성
- 메모리와 CPU 자원을 많이 사용
- 레코드마다 SELECT와 INSERT 작업 수행
- 일반적으로 COUNT(*)보다 2~3배 느림
- 대량 데이터 처리 시 디스크로 임시 테이블 이동 가능
성능 모니터링
- ORM 사용 시에도 실제 실행되는 SQL 확인 필요
- General Log를 활용하여 성능 이슈 있는 쿼리 탐지
COUNT(*) 튜닝

-
응용 프로그램 로직을 변경하지 않고 count-all-query는 커버링 인덱스 실행 계획을 사용하도록 하는 것이 유일한 튜닝 방법
-
응용 프로그램의 로직을 변경하면서 count-all-query를 튜닝할 수 있는 방법을 좀 더 살펴 보자
-
먼저 카운트 올 쿼리 최고 튜닝은 쿼리 자체 제거
-
의외로 이경우가 많다
-
페이지 번호 없이 이전 이후 페이지 이동 기능으로 구현 하면 손쉽게 카운트 올 쿼리 제거 가능
-
만약 카운트 올쿼리 제거 못하면
-
대략적인 건수 활용
- 필요한 레코드 건수까지만 확인하자
- ex) 한페이지의 20개 레코드를 표시하는데 페이지 네이게션을 위해서 10개까지 보여준다 하면
- 전체 레코드 건수는 필요하지않고 200건 까지의 레코드가 있는지만 확인하면 된다.
- ex) select count(*) from (selcet 1 from table limit 200) z;
- 200건인지 그 미만인지만 확인
- 그럼 server는 200건 이상 조회하지 않고 만약 200건 미만이면 정확한 레코드 건수를 가져 올수 있음
- 그리고 10 ~20 페이지까지는 리미트 400까지만 뒤로 이동할 수록 뒤로 갈 수록 쿼리 성능은 느려지겠지만
- 대부분 사람들이 앞쪽 페이지를 몇개를 집중하는 조회하는 패턴이 일반적인대 이런걸 고려해보면 의외로 간단하게 튜닝 가능
- 카운터 쿼리 실행하지않고 임이의 페이지 번호 표기
-
처음 10개 페이지가 있는 것처럼 페이지 번호를 1부터 10번까지 표시해주고
-
실제 해당 페이지로 이동하면 countAllquery 날려서 결과 존재 여부를 페이지 존재여부를 갱신
-
즉 사용자가 7페이지 클릭하면 selectAllFromLimit 10, offset60 쿼리가 실행되게 되는데 결과가
-
10개 미만이면 7페이를 마지막 번호로 표시해주고 10개면 페이지 번호를 그대로 10까지 유지
-
이 때 7페이지 데이터 조회하는 결과가 한건도 없다면 카운트 all 쿼리를 실행해서 전체 레코드 건수를 확인하고
-
페이지 번호를 고쳐주면 되는데 이 경우 카운트 올 쿼리를 실행하지만 실제 레코드 건수는 많지 않기 때문에 성능 적으로 큰 우려가 되지않는다.
-
구글도 약간 이런 느낌 튜닝인듯?
- 통계 정보

- mysql 서버에서는 information Schema의 tables라는 뷰이용하면
- 특정 테이블의 전체 레코더 건수 확인 가능
- 만약 countAllQuery가 별도의 where 조건없이 테이블의 전체 레코더 건수를
- 조회하는 경우 이 통계 정보 테이블의 레코더 예측치를 조회해서 사용 가능
- countAllQuery가 where 조건절을 가진 경우 countAllQuery의 where조건들이 인덱스를 사용할 수 있도록
- 튜닝하고 쿼리 실행 계획에서 rows 컬럼을 이용해서 예측된 값을 확인하는 방법도 생각해 볼 수 있다.
- 조인이나 서브쿼리시 사용이 어려움, 그렇지 않는 경우 적절히 인덱스 활용하면 근접한 값 가져올수 있다
- countAllQuery 보다 정확도가 많이 떨어 질 수 있지만 많은 레코드 건수 카운트 경우 매우빠르고
- 자원효율적 건수 확인 가능
정리
쿼리 제거
- 가장 좋은 방법은 COUNT(*) 쿼리 자체를 제거
- 페이지 번호 없이 이전/다음 페이지 이동 기능으로 구현
대략적인 건수 활용
- 필요한 레코드 건수까지만 확인
- SELECT COUNT(*) FROM (SELECT 1 FROM table LIMIT 200) z;
- 정확한 전체 건수 대신 필요한 범위 내의 건수만 확인
- 사용자는 보통 맨 뒤에 까지 조회 하지 않으니.. 뒤로 갈수록 성능저하가 일어나지만
임의의 페이지 번호 표기
- 처음에는 가상의 페이지 번호를 표시하고, 실제 페이지 이동 시 COUNT 쿼리 실행
- 사용자가 뒷 페이지로 이동할 때만 실제 COUNT 쿼리 실행
통계 정보 활용
- MySQL의 information_schema.tables 뷰를 이용해 대략적인 레코드 수 확인
- 쿼리 실행 계획의 rows 컬럼을 이용해 예측 값 확인
이러한 방법들이 효과적인 이유
- 불필요한 연산 감소: 전체 레코드를 세는 대신 필요한 범위만 확인하여 연산량 감소
- 사용자 경험 개선: 빠른 응답 시간으로 사용자 경험 향상
- 리소스 효율성: 데이터베이스 서버의 리소스 사용 최적화
- 점진적 로딩: 필요한 시점에 정확한 정보를 로드하여 초기 로딩 시간 단축
COUNT(*) 튜닝 - 2

- countAllQuery 튜닝시 쿼리 자체를 제거해야 되는 경우와
- 인덱스를 이용하도록 튜닝해야경우를 구분 할 수있다
where 조건없는 count(*)
- where 조건에 일치하는 레코드 건수가 많은 count(*)
- 이 두가지는 제거하는게 좋다 -> 제거 할수 없으면 통계정보 이용하거나 예측건수 이용해서 페이징
인덱스 활용하여 최적화 대상
- 정확한 count(*)가 필요한 경우
- count(*) 대상 건수가 소량인 경우
- where 조건이 인덱스로 처리될 수 있는 경우 (커버링 인덱스)
- 일반적인 OLTP 쿼리에서는 몇만 건이내에 건수확인 정도는 인덱스 튜닝으로 최적화 가능
- 그 이상 레코더 경우 빠른 성능 보장되기 어려움 다른 방법으로 튜닝하는게 좋음


-
타입 ORM을 이용해서 샵 테이블과 코멘트 테이블을 조인해 정렬한 뒤
-
20건만 조회하는 쿼리를 실행해 보자
-
잘 만든 쿼리처럼 보인다
-
샵테이블과 코멘트 테이블은 1대 n 관계이고 distinct-alliance 의 코멘트 id 컬럼은 기본키인 id 컬럼
-
실제 이쿼리는 distinct 는 불필요함 기본키는 유니크하니까
-
type orm 서브쿼리까지하면서 distinct 이용해 쿼리작성하지만
-
실제는 쓸모없는작업 기본키가있으니까!
-
오른쪽 처럼 짜야지 의도대로 라면
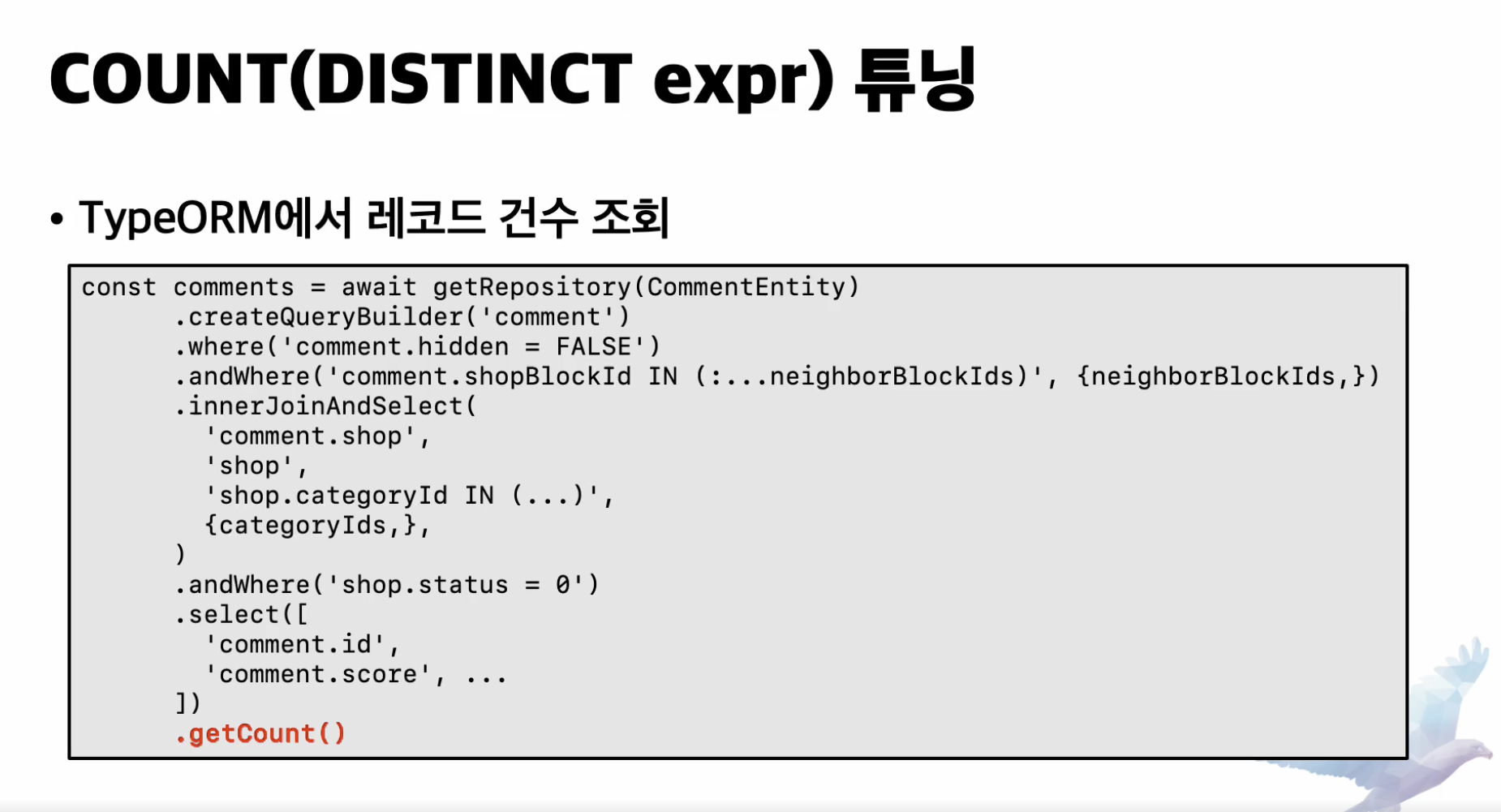
-
이 쿼리는 페이징 쿼리로 사용되는 것 인데 페이징 작업을 위해서
-
사용 되는 것인데 countALl 쿼리가 필요하고 타입 orm 에서는 이렇게 마지막에 getCount 함수를 호출하도록함
-
이 경우 어떤 문제 쿼리를 생성했을까?

- count distinct 쿼리를 만들었다!
- 기본키를 포함해서 .. 이러면 필요없는데 유니크하잔아
- 다른 orm에서도 이런 최적화가 많이 부족하다.

- 원래 이렇게 만들어져야 최적화된 쿼리이다
- orm 도구를 사용하면 반드시확인하고 사용하자
정리
COUNT(*) 쿼리 튜닝 방법 구분:
a) 쿼리 제거가 좋은 경우
- WHERE 조건 없는 COUNT(*)
- WHERE 조건에 일치하는 레코드가 많은 COUNT(*)
인덱스를 활용한 최적화가 좋은 경우
- 정확한 COUNT(*)가 필요한 경우
- COUNT(*) 대상 건수가 적은 경우
- WHERE 조건이 인덱스로 처리 가능한 경우
ORM 사용 시 주의사항:
a) 불필요한 DISTINCT 사용
- ORM이 기본키에 대해 불필요하게 DISTINCT를 사용하는 경우가 있음
- 기본키는 이미 유니크하므로 DISTINCT가 필요 없음
COUNT 쿼리 최적화
- 예: COUNT(DISTINCT) 사용 시 기본키에 대해 불필요하게 적용
- ORM이 생성하는 실제 SQL을 확인하고 최적화가 필요한지 검토
