01. 캘린더 작성
TABLE
create table POST ( id int auto_increment, memberId int not null, contents varchar(100) not null, createdDate date not null, createdAt datetime not null, constraint POST_id_uindex primary key (id) );
- 캘린더 작성 코드는 contents만 받아서 작성할 수 있도록 간단히 구현했다.
- 인가처리를 구현하지 않음
- 후에 날짜별로 내가 쓴 캘린더 갯수를 조회 하기 위해 작성함
1-1. 300만건 Insert
- SpringbootTest를 이용한 bulk Insert 진행
PostServiceCode
public class PostWriteService { public void bulkInsert(List<Post> posts) { String sql = String.format(""" INSERT INTO `%s` (memberId, contents, createdDate, createdAt) VALUES (:memberId, :contents, :createdDate, :createdAt) """, TABLE); SqlParameterSource[] params = posts .stream() .map(BeanPropertySqlParameterSource::new) .toArray(SqlParameterSource[]::new); namedParameterJdbcTemplate.batchUpdate(sql, params); } }
VALUES에 Array를 이용해 삽입합니다.
Bulk Insert가 매번 쿼리를 날리는 것보다 속도가 빠른 이유는 한 번의 쿼리 전후로 이루어지는 작업들을 한 번만(혹은 줄여주기) 때문입니다.
1-1-1. EasyRandom 객체 사용
PostFixture
public class PostFixtureFactory { public static EasyRandom get(Long memberId, LocalDate firstDate, LocalDate lastDate) { Predicate<Field> idPredicate = named("id") .and(ofType(Long.class)) .and(inClass(Post.class)); Predicate<Field> memberPredicate = named("memberId") .and(ofType(Long.class)) .and(inClass(Post.class)); return new EasyRandom(new EasyRandomParameters() .excludeField(idPredicate) .dateRange(firstDate, lastDate) .randomize(memberPredicate, () -> memberId)); } }
-
EasyRandom 라이브러리를 이용한 쉽게 랜덤객체를 사용할 수 있다.
- EasyRandom github을 보면 사용예제와 함께 사용방법을 알 수 있음
-
randomize를 사용해 memberId를 고정
-
excludeField를 사용해 id는 랜덤값을 제외
1-1-2. 테스트코드 작성
SpringbootTest
@SpringBootTest public class PostBulkInsertTest { @Autowired private PostRepository postRepository; @Test void bulkInsert() { //given EasyRandom easyRandom = PostFixtureFactory.get(3L, LocalDate.of(1970, 1, 1), LocalDate.of(2023, 2, 1) ); //when int tenThousand = 10000; StopWatch stopWatch = new StopWatch(); stopWatch.start(); List<Post> posts = IntStream.range(0, tenThousand * 100) .mapToObj(i -> easyRandom.nextObject(Post.class)) .toList(); stopWatch.stop(); System.out.println("객체 생성 시간 : " + stopWatch.getTotalTimeSeconds());
주의
100만건 데이터 삽입 시 heap memory를 많이 사용해 작동을 멈췄는데
intelliJ ide vm option에서 힙 메모리 공간을 변경하여(2048MB -> 4096MB) 테스트 진행
(test는 기본으로 gradle설정으로 실행하게 되는데, 이를 ide설정으로 시작할 수 있도록 바꾸는 조치 필요)
StopWatch로 확인
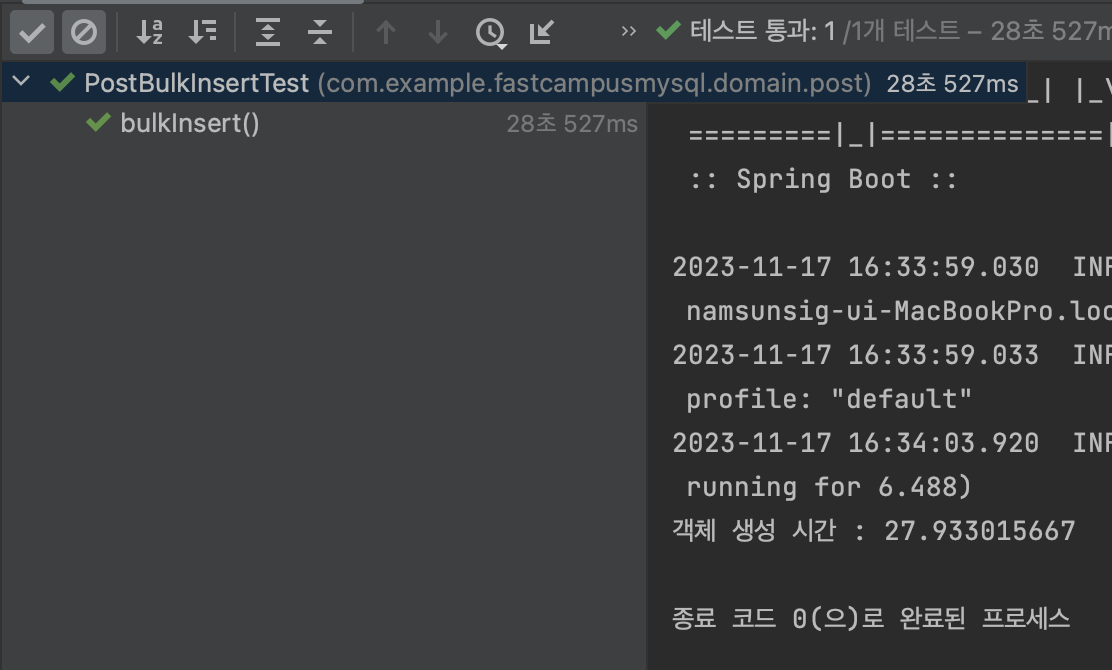
- EasyRandom을 이용해 100만개 객체 생성시간 = 27s
데이터 삽입
StopWatch queryStopWatch = new StopWatch(); queryStopWatch.start(); postRepository.bulkInsert(posts); queryStopWatch.stop(); System.out.println("데이터베이스 삽입 시간 : " + queryStopWatch.getTotalTimeSeconds());
조회성능 확인을 위한 유의미한 갯수를 위해 100만개씩 3번 진행
-
터미널에서 top -pid "mysql pid_num"사용하면 cpu 사용량을 볼 수 있음

-
100만개 데이터삽입이 커밋이 일어날 때 125%까지 cpu사용량이 늘어났었음
-
StopWatch로 확인한 결과 100만개 데이터 커밋 시간 = 37s

결과
SELECT count(id)
FROM Post-
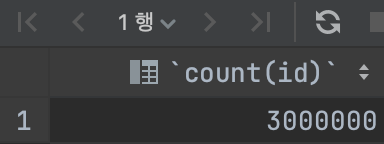
-
이 후에 memberId = 4로 100만건 추가 총 400만건 가지고 조회할 것임
02. 날짜별 내가 쓴 캘린더 조회
초기
private static final String TABLE = "Post"; String sql = String.format(""" SELECT createdDate, memberId, count(id) as count FROM %s WHERE memberId = :memberId and createdDate between :firstDate and :lastDate GROUP BY memberId, createdDate """, TABLE);
- NamedParameterJdbcTemplate를 사용해 Repository를 작성 중 이는 생략
2-1. 문제
- 해당 쿼리 사용할 때 데이터가 많아짐에 따라 분명한 성능 저하
Query
SELECT createdDate, memberId, count(id) as count FROM POST WHERE memberId = 3 and createdDate between '1900-01-01' and '2024-01-01' GROUP BY memberId, createdDate


- 쿼리가 1초 이상이 걸렸음
- cpu 사용률을 보면 말도 안되게 높은 숫자를 기록하는 것을 확인할 수 있다.
(스크린샷을 할 수 없지만 100%도 넘김, 평균 80)- 쿼리 한번에 1초 이상도 문제
- 실제 프로덕트에서 쿼리한번에 cpu 사용률이 100%에 가까운 것은 대형사고
2-1-1. mysql옵티마이저 전략, 데이터 분포도 확인
explain으로 전략 확인
explain SELECT createdDate, memberId, count(id) as count
FROM POST
WHERE memberId = 3 and createdDate between '1900-01-01' and '2024-01-01'
GROUP BY memberId, createdDate;결과

분포도
1.memberId로 그룹화
SELECT memberId, count(id)
from POST
group by memberId;결과
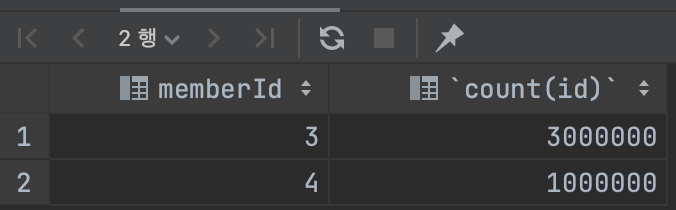
- 유니크한 created_date 개수
SELECT count(distinct (createdDate))
from POST;결과

2-1-2 인덱스
index 추가
# memberId 단일 인덱스 추가 create index POST__index_member_id on POST (memberId); # created_date 단일 인덱스 추가 create index POST__index_created_date on POST (createdDate); # memberId, create_date 복합 인덱스 추가 create index POST__index_member_id_created_date on POST (memberId, createdDate);
1. memberId 단일 인덱스 사용
SELECT createdDate, memberId, count(id) as count
FROM POST use index (POST__index_member_id)
WHERE memberId = 1 and createdDate between '1900-01-01' and '2024-01-01'
GROUP BY memberId, createdDate;- memberId = 3일때
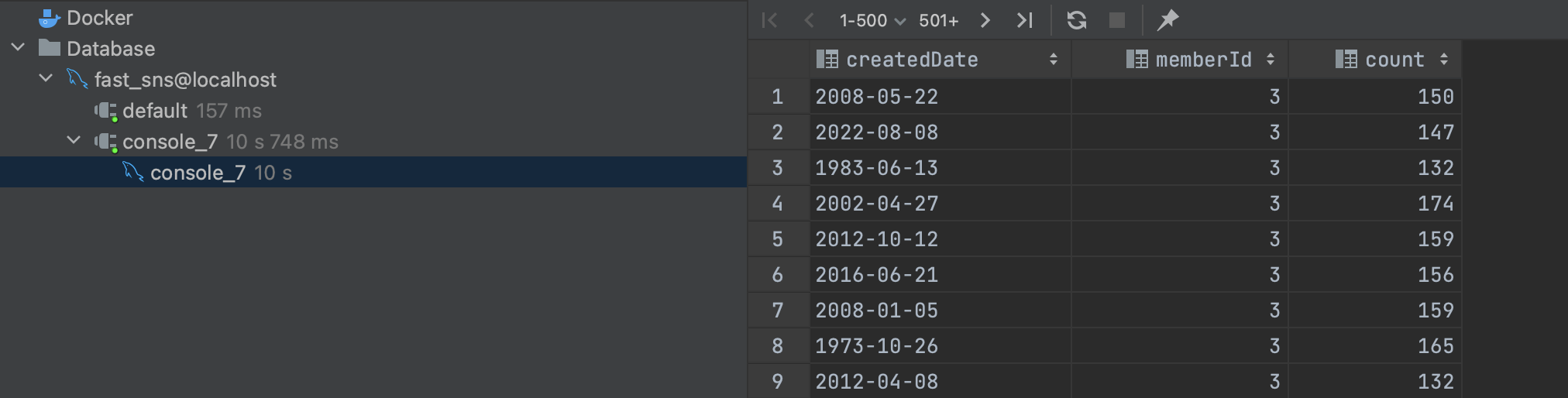
- 굉장히 느리다. (10s)
- 인덱스를 걸지 않는 것이 더 빨랐다.
- memberId로 300만개와 100만개로 나눠져도 인덱스 조회 시 변별력이 없어 오래걸린다.
- memberId = 1 일때 (데이터가 없을 때)

- 굉장히 빠르다. (25ms)
- memberId = 1 데이터가 없기 때문에, 인덱스 조회가 빠르다.
- 굉장히 빠르다. (25ms)
2. created_date 단일 인덱스 사용
SELECT createdDate, memberId, count(id) as count
FROM POST use index (POST__index_created_date)
WHERE memberId = 1 and createdDate between '1900-01-01' and '2024-01-01'
GROUP BY memberId, createdDate;-
memberId = 3일 때

- 빠르다. (421ms)
- 유니크한 created_date가 1만9천개가 있기 때문에 인덱스 조회 시 이점이 있다.
- 빠르다. (421ms)
-
memberId = 1일 때 (데이터가 없을 때)

- 느리다. (14s)
- created_date 인덱스를 조회할 때 memberId = 1인 값이 존재하지 않기 때문에 전체조회보다 느리다.
- 느리다. (14s)
3. memberId, create_date 복합 인덱스 사용
SELECT createdDate, memberId, count(id) as count
FROM POST use index (POST__index_member_id_created_date)
WHERE memberId = 1 and createdDate between '1900-01-01' and '2024-01-01'
GROUP BY memberId, createdDate;- memberId = 3일 때
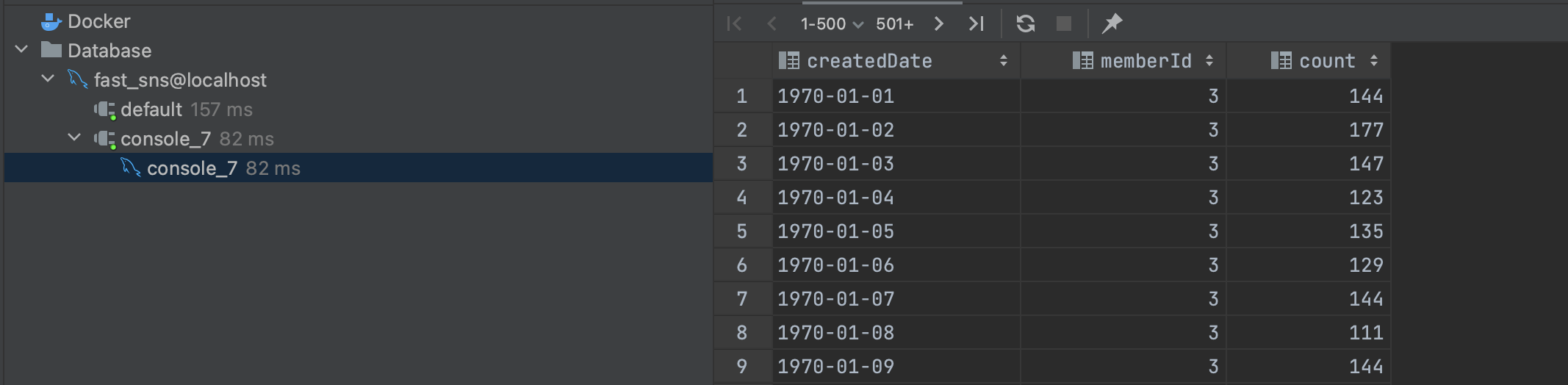
- 빠르다. (82ms)
- 앞선 create_date 인덱스보다도 몇 배는 빠르다.
- memberId로 탐색을 시작하고 created_date로 탐색을 줄이기 때문에 인덱스 조회 시 이점이 있다.
- 빠르다. (82ms)
- memberId = 1일 때
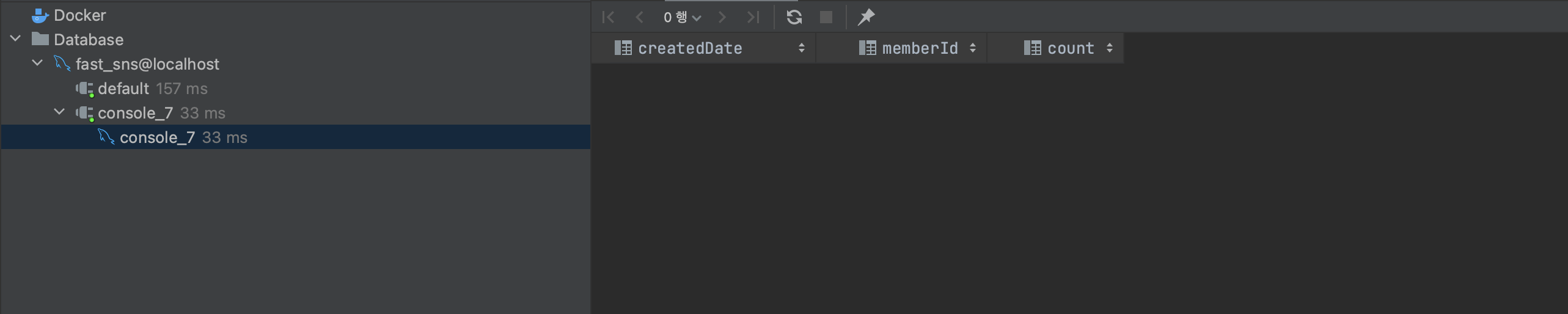
- 빠르다. (33ms)
- 마찬가지로 memberId로 조회 시 memberId = 1인 값이 없기 때문에 빠르다.
- 빠르다. (33ms)
03. 결론
옵티마이저 전략 확인
explain SELECT createdDate, memberId, count(id) as count
FROM POST
WHERE memberId = 1 and createdDate between '1900-01-01' and '2024-01-01'
GROUP BY memberId, createdDate;결과

-
36ms
-
memberId, created_daate, memberId & created_date 세 개의 인덱스 중 memberId & created_date 복합 인덱스를 사용했음
- 옵티마이저가 통계값에 영향을 받을 수 있음
- 더 좋은 인덱스가 있어도 성능이 좋지 않은 인덱스를 사용할 수 있음
- 항상 explain으로 옵티마이저가 가지는 전략을 확인하는 것도 필요
-
인덱스를 사용하면 10s가 걸리던 쿼리도 100ms이내로 줄일 수 있다.
-
반대로 30ms 걸리던 쿼리도 10s이상 걸릴 수 있다.
똑같은 인덱스라도 파라미터의 분포도에 따라서 유의미한 성능의 차이가 난다.
- 인덱스 사용시 데이터 분포도 고려해야함
- 어떤 컬럼이 조건에 들어가는지 고려해야함
인덱스도 비용이다.
- 쓰기 저하 조회 향상
- 꼭 인덱스로만 해결할 수 있는 문제인지 고려
병목인 DB가 느려져서 느린 것이기 때문에 API테스트는 생략
