01. 조회 최적화를 위한 Index 이해
Note :
- 인덱스는 정렬된 자료구조
- 인덱스의 핵심은 탐색범위를 최소화 하는 것
- 인덱스도 데이터의 주소값을 가진 테이블
인덱스가 없는 데이터베이스의 탐색
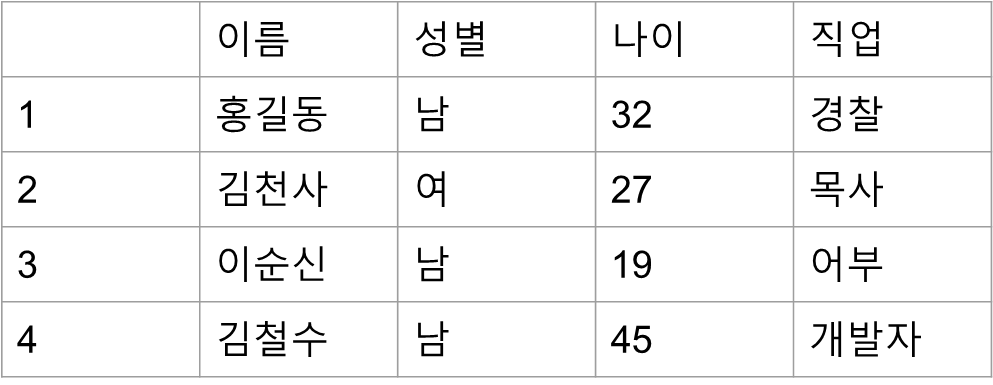
- 나이가 제일 어린 사람의 데이터를 찾고 싶다면 1 ~ 4 까지 모든 데이터를 다 찾아봐야한다.
인덱스가 있는 데이터베이스의 탐색
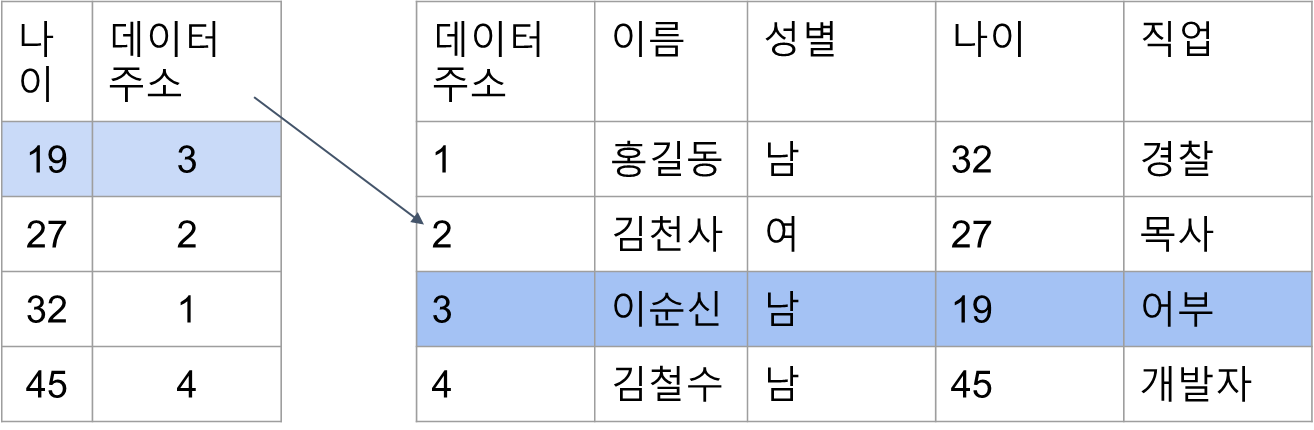
- 인덱스(나이순으로 정렬된)테이블을 살펴보고 최상단에 있는 데이터 주소를 조회 하면된다.
1-1. 자료구조
1-1-1. 검색이 빠른 자료구조
- HashMap
- 단건 검색 속도 O(1)
- 범위 탐색 속도 O(N)
- 전방 일치 탐색 불가
ex) like%'AB%'
- List
- 정렬되지 않는 리스트의 탐색 O(N)
- 정렬된 리스트의 탐색 O(logN)
- 정렬되지 않은 리스트의 정렬 시간 복잡도는 O(N) ~ O(N*logN)
- 삽입 / 삭제 비용이 매우 높음
(중간에 삽입/삭제 되는 경우)
- Tree
- 트리 높이에 따라 복잡도가 결정됨
(트리의 높이를 최소화하는 것이 중요) - 한쪽으로 노드가 치우치지 않도록 균형을 잡아주는 트리 사용
ex) Red-Black Tree, B+Tree
- 트리 높이에 따라 복잡도가 결정됨
1-1-2. 인덱스는 B+Tree를 사용
Note :
- 삽입 / 삭제시 항상 균형을 이룸
- 하나의 노드가 여러 개의 자식 노드를 가질 수 있음(Tree의 높이를 최소화할 수 있음)
- 리프노드에만 데이터 존재
- 연속적인 데이터 접근 시 유리
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
해당 링크를 통해 어떤 방식으로 B+Tree의 삽입/삭제 연산이 동작하는지 확인 가능
실제 예제
다음은 실제 데이터베이스가 어떻게 인덱스를 탐색하는지를 보여주는 장표이다.
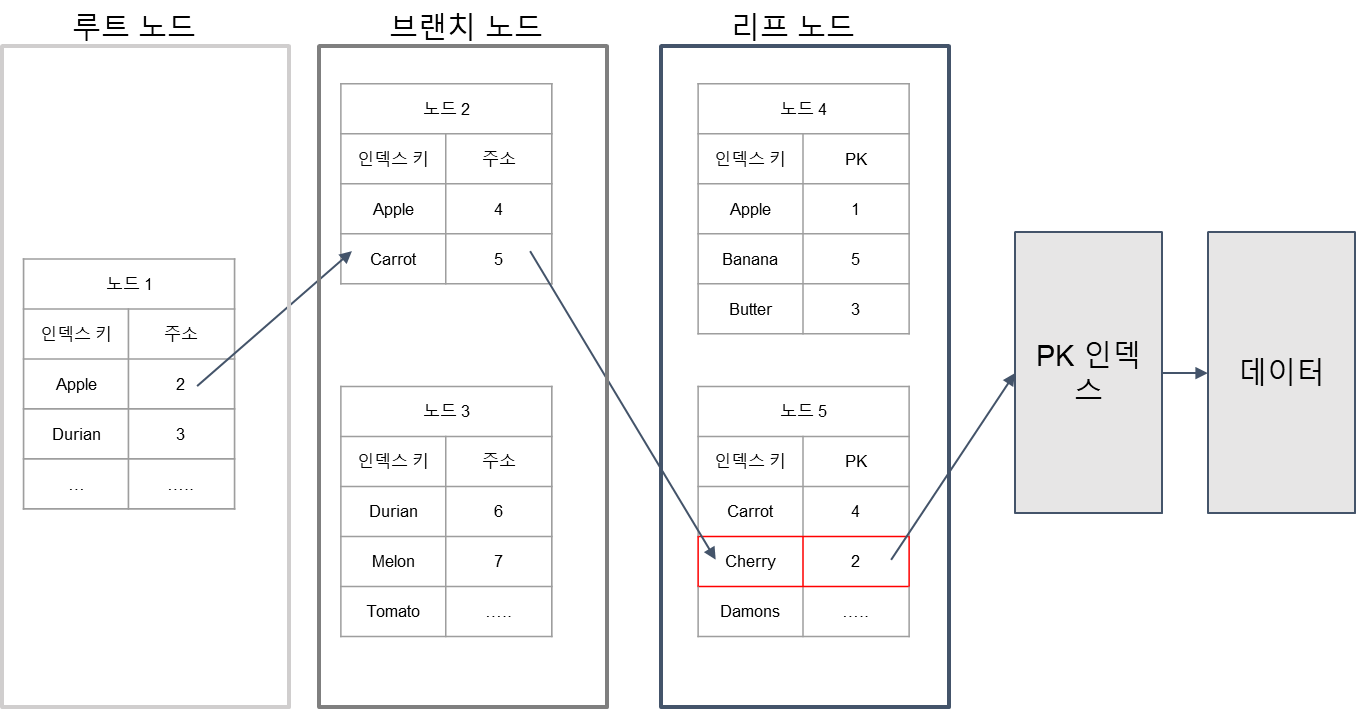
이그림에서 내가 찾고 싶은 과일은 Cherry이다.
- (사전순으로 정렬된) 과일 이름 인덱스 테이블
- Cherry는 루트 노드의 Apple과 Durian 사이 -> Apple이 가지고 있는 주소값 2 -> 2번 노드
- Cherry는 2번 노드의 Carrot의 다음 -> Carrot 이 가지고 있는 주소값 5 -> 5번 노드
- 리프노드(5번 노드)가 가지고 있는 PK 값을 찾을 수 있게 된다. -> PK = 2
Note :
인덱스를 사용하게 되면 조회의 성능을 높힐 수 있지만,
데이터를 추가하거나 삭제할 때 함께 B+Tree자료구조의 삽입/삭제 동작이 일어나기 때문에 쓰기의 성능을 낮출 수 밖에 없다.
- 밸런스를 잡는게 중요 = 읽기 / 쓰기 사이의 트레이드 오프
1-2. 클러스터 인덱스
Note :
- 클러스터 인덱스는 데이터 위치를 결정하는 키 값이다
- MySQL의 PK는 클러스터 인덱스 이다.
- MySQL에서 PK를 제외한 모든 인덱스는 PK를 가지고 있다.
1-2-1. 클러스터 인덱스는 데이터위치를 결정

- 4번이 insert되면서 5번이 뒤로 밀려났다.
- 최악의 상황(제일 앞에 데이터가 추가되는 경우)에서 N개가 뒤로 밀려난다.
정리
- 클러스터 키는 정렬된 자료구조이고 클러스터 키 순서에 따라 데이터의 위치가 변경된다.
- 클러스터 키 삽입 / 갱신 시 에 성능이슈 발생
1-2-2. MySQL PK = 클러스터 인덱스
- 클러스터 키는 정렬된 자료구조이고 클러스터 키 순서에 따라 데이터의 위치가 변경된다.
= PK는 정렬된 자료구조이고 PK 순서에 따라 데이터의 위치가 변경된다. - 클러스터 키 삽입 / 갱신 시 에 성능이슈 발생
= MySQL PK 삽입 / 갱신 시 성능이슈 발생
따라서 MySQL에서 PK를 설정하는 것은 매우 중요한 일이다.
MySQL PK 설정 UUID vs Auto Increment
1-2-3. MySQL에서 PK를 제외한 모든 인덱스는 PK를 가지고 있다
제목만으로도 매우 중요한 특징
- MySQL 인덱스는 PK를 가지고 있기 때문에 PK의 데이터 위치가 변경 될 때도 영향이 덜하다.
- 세컨더리 인덱스(보조 인덱스, PK를 제외한 모든 인덱스)만으로는 데이터를 찾아갈 수 없다.
PK인덱스를 항상 검색해야함
- 세컨더리 인덱스(보조 인덱스, PK를 제외한 모든 인덱스)만으로는 데이터를 찾아갈 수 없다.
장점
- PK를 활용한 검색(특히 범위 검색)이 빠름.
공간적 캐시 이점을 누릴 수 있음 - 세컨더리 인덱스들이 PK를 가지고 있어 커버링에 유리
인덱스 테이블 자체만으로도 데이터 응답을 내려줄 수 있어서 테이블까지 가지 않아도 된다.
예제
다음 그림은 PK인덱스가 동작하는 과정 이다.
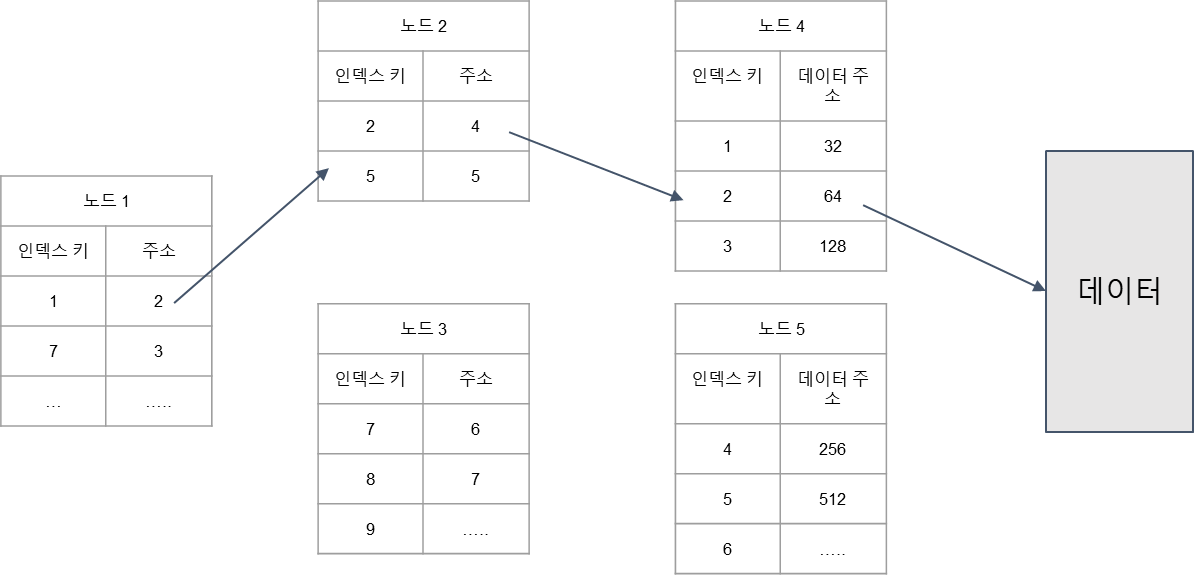
- 맨 위에 (과일)인덱스에서 찾으려는 Cherry가 PK 2번을 가지고 있었다.
- 2는 1과 7사이 -> 2번 노드
- 2번노드에서 2는 4를 가르키고 있다. -> 4번 노드
- 4번노드(리프노드)에서 데이터 주소 64를 찾을 수 있다.
Note :
- 세컨더리 인덱스들은 PK인덱스를 거치게 된다.
- 세컨더리 인덱스의 리프노드들은 모두 PK를 가지고 있다.
결론
인덱스는 읽기와 쓰기의 트레이드 오프이다.
균형을 유지하는 것이 좋다.

응집력있는 시간을 보내기 위한 블로그