락 기반의 병행 자료 구조
자료구조에 락을 추가하여 쓰레드가 사용할 수 있도록 만들면, 그 구조는 쓰레드 사용에 안전(thread safe)하다고 할 수 있다.
핵심 질문: 자료구조에 락을 추가하는 방법
- 자료구조에 어떤 방식으로 락을 추가해야 정확하게 동작하게 만들 수 있을까?
- 자료구조에 락을 추가하여 여러 쓰레드가 그 자료구조를 동시에 사용이 가능하도록 하면(병행성), 고성능을 얻기 위해 무엇을 해야할까?
1. 병행 카운터
확장성이 없는 카운팅
typedef struct _ _counter_t {
int value;
pthread_mutex_t lock;
} counter_t;
void init(counter_t *c) {
c−>value = 0;
Pthread_mutex_init(&c−>lock, NULL);
}
void increment(counter_t *c) {
Pthread_mutex_lock(&c−>lock);
c−>value++;
Pthread_mutex_unlock(&c−>lock);
}
void decrement(counter_t *c) {
Pthread_mutex_lock(&c−>lock);
c−>value−−;
Pthread_mutex_unlock(&c−>lock);
}
int get(counter_t *c) {
Pthread_mutex_lock(&c−>lock);
int rc = c−>value;
Pthread_mutex_unlock(&c−>lock);
return rc;
}- 자료구조를 조작하는 루틴을 호출할 때 락 추가, 호출문이 리턴될 때 락 해제를 한다.
- 모니터(monitor)를 사용하여 만든 자료구조와 유사하다.
(객체에 대한 메소드를 호출하고 리턴할 때 자동적으로 락 획득/해제) - 성능 테스트
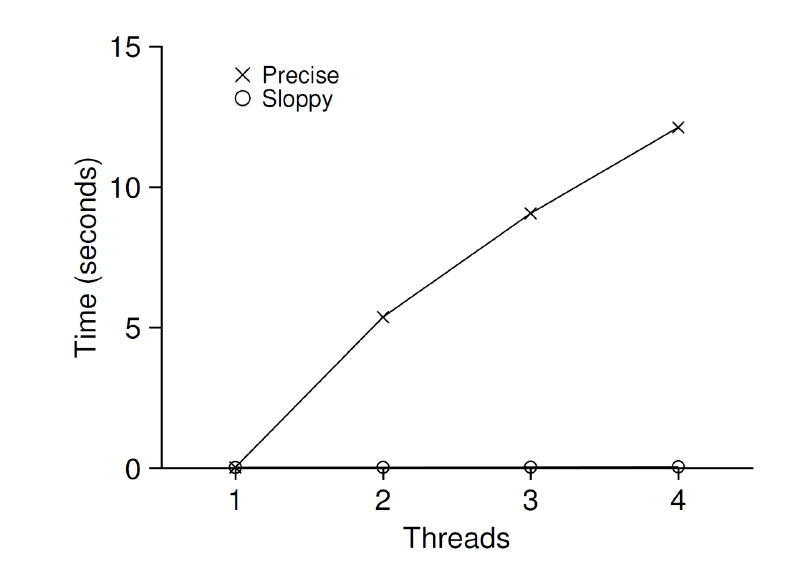
- 카운터를 백만 번 증가시켰을 때 총 걸린 시간에 대한 벤치마크
(X 표시된 범례에 주목) - 쓰레드가 2개만 되어도 5초 이상 걸림
- 카운터를 백만 번 증가시켰을 때 총 걸린 시간에 대한 벤치마크
하나의 쓰레드가 하나의 CPU에서 작업을 끝내는 것처럼, 멀티프로세서에서 실행되는 쓰레드들도 빠르게 작업을 처리하고 싶을 것이다.
이를 완벽한 확장성(perfect scaling)이라고 한다.
확장성 있는 카운팅
완벽한 확장성(perfect scaling): 더 많은 작업을 처리하더라도 각 작업이 병렬적으로 처리되어 완료 시간이 늘어나지 않는 것
엉성한 카운터(sloppy counter)
-
CPU 코어마다 물리적인 지역 카운터와 전역 카운터로 구성되어 있다.
- CPU 4개면 4개의 지역 카운터, 4개의 전역 카운터를 갖는다.
-
지역/전역 카운터들을 위한 락이 존재한다.
-
기본 개념
- 쓰레드는 지역 카운터를 증가시킨다.
(지역 카운터는 지역 락에 의해 보호된다) - 각 CPU는 저마다 지역 카운터를 갖기 때문에 CPU들에 분산되어 있는 쓰레드들은 지역 카운터를 경쟁 없이 갱신할 수 있다.
- 카운터 갱신은 확장성이 있다!
- 쓰레드가 카운터의 값을 읽기때문에 전역 카운터를 최신으로 갱신해야 한다.
- 최신 값으로 갱신하기 위해서 지역 카운터의 값은 주기적으로 빈도
S마다 전역 카운터로 전달한다.- 이때 전역 락을 사용하여 지역 카운터의 값을 전역 카운터의 값에 더하고, 그 지역 카운터의 값은 0으로 초기화한다.
- 작은
S의 값: 확장성 X, 전역 카운터의 값이 정확해짐 - 큰
S의 값: 확장성 O, 전역 카운터의 값이 부정확해짐
- 쓰레드는 지역 카운터를 증가시킨다.
-
엉성한 카운터의 흐름
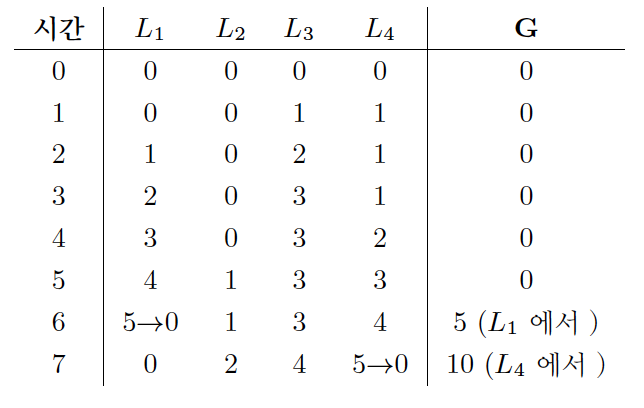
- 한계치가 5인 경우, 지역 카운터(L1~L4)가 5 이상일 때 전역 카운터의 값을 갱신한다.
-
엉성한 카운터의 성능
S=1024인 경우의 성능이다.
(이번에는 O 표시된 범례에 주목)- 4개의 프로세서에서 카운터의 값을 4백만 번 갱신하는 것과 1개의 프로세서에서 백만 번 갱신하는 것에 속도차이가 크지 않다.
-
엉성한 카운터의 확장성
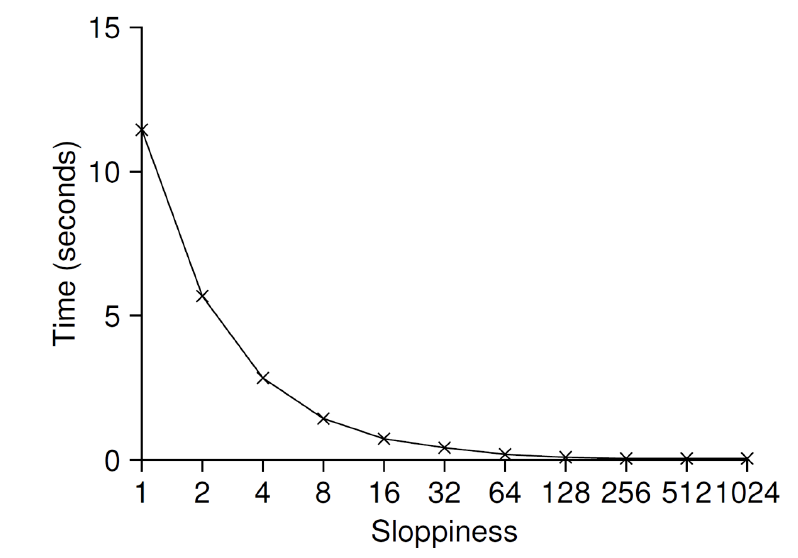
- S 값이 낮으면 성능이 낮은 대신 전역 카운터의 값이 정확해진다.
- S 값이 높으면 성능이 좋은 대신 전역 카운터의 값이 부정확해진다.
-
엉성한 카운터의 구현
typedef struct __counter_t { int global; // 전역 카운터 pthread_mutex_t glock; // 전역 카운터 int local[NUMCPUS]; // 지역 카운터 (cpu당) pthread_mutex_t llock[NUMCPUS]; // ... 그리고 락들 int threshold; // 갱신 빈도 } counter_t; // init:한계치를 기록하고 락과 지역 카운터 // 그리고 전역 카운터의 값들을 초기화함 void init(counter_t *c, int threshold) { c−>threshold = threshold; c−>global = 0; pthread_mutex_init(&c−>glock, NULL); for (int i = 0; i < NUMCPUS; i++) { c−>local[i] = 0; pthread_mutex_init(&c−>llock[i], NULL); } } // update: 보통은 지역 락을 획득한 후 지역 값을 갱신함 // '한계치' 까지 지역 카운터의 값이 커지면, // 전역 락을 획득하고 지역 값을 전역 카운터에 전달함 void update(counter_t *c, int threadID, int amt) { pthread_mutex_lock(&c−>llock[threadID]); c−>local[threadID] += amt; // amt > 0을 가정 if (c−>local[threadID] >= c−>threshold) { // 전역으로 전달 pthread_mutex_lock(&c−>glock); c−>global += c−>local[threadID]; pthread_mutex_unlock(&c−>glock); c−>local[threadID] = 0; } pthread_mutex_unlock(&c−>llock[threadID]); } // get: 전역 카운터의 값을 리턴 (정확하지 않을 수 있음) int get(counter_t *c) { pthread_mutex_lock(&c−>glock); int val = c−>global; pthread_mutex_unlock(&c−>glock); return val; // 대략의 값임! }
2. 병행 연결 리스트
// 기본 노드 구조
typedef struct __node_t {
int key;
struct __node_t *next;
} node_t;
// 기본 리스트 구조 (리스트마다 하나씩 사용)
typedef struct __list_t {
node_t *head;
pthread_mutex_t lock;
} list_t;
void List_Init(list_t *L) {
L−>head = NULL;
pthread_mutex_init(&L−>lock, NULL);
}
int List_Insert(list_t *L, int key) {
pthread_mutex_lock(&L−>lock);
node_t *new = malloc(sizeof(node_t));
if (new == NULL) {
perror("malloc");
pthread_mutex_unlock(&L−>lock);
return −1; // 실패
}
new−>key = key;
new−>next = L−>head;
L−>head = new;
pthread_mutex_unlock(&L−>lock);
return 0; // 성공
}
int List_Lookup(list_t *L, int key) {
pthread_mutex_lock(&L−>lock);
node_t *curr = L−>head;
while (curr) {
if (curr−>key == key) {
pthread_mutex_unlock(&L−>lock);
return 0; // 성공
}
curr = curr−>next;
}
pthread_mutex_unlock(&L−>lock);
return −1; // 오류
}- 삽입 연산을 시작하기 전에 락 획득, 리턴 직전에 해제
- 드물지만, malloc()이 실패할 경우 실패 처리 전에 락을 해제해야 한다.
그렇다면 삽입 연산이 병행하여 진행되는 상황에서 실패를 하더라도 락 해제를 호출하지 않으면서 삽입과 검색이 올바르게 동작하도록 수정할 수 있을까?
- 가능하다.
- 삽입 코드에서 임계 영역을 처리하는 부분만 락으로 감싸도록 한다.
- before
// malloc 포함 전부 감싸는 모습 pthread_mutex_lock(&L−>lock); node_t *new = malloc(sizeof(node_t)); if (new == NULL) { perror("malloc"); pthread_mutex_unlock(&L−>lock); return −1; // 실패 } new−>key = key; new−>next = L−>head; L−>head = new; pthread_mutex_unlock(&L−>lock); - after
... new−>key = key; // Insert 전체를 감싸지 않고, 임계 영역만 락으로 보호 pthread_mutex_lock(&L−>lock); new−>next = L−>head; L−>head = new; pthread_mutex_unlock(&L−>lock); - 사실 검색 코드의 일부는 락이 필요 없기 때문에 경쟁 조건을 신경쓰지 않아도 된다.
- before
- 또한 검색 루틴의 while 문 안에 break를 삽입하여 검색이 성공하면 바로 빠져나오게 수정한다.
- before
pthread_mutex_lock(&L−>lock); node_t *curr = L−>head; while (curr) { if (curr−>key == key) { pthread_mutex_unlock(&L−>lock); // 불안한 코드 return 0; // 성공 } curr = curr−>next; } pthread_mutex_unlock(&L−>lock); return −1; // 오류 - after
int rv = -1; pthread_mutex_lock(&L−>lock); node_t *curr = L−>head; while (curr) { if (curr−>key == key) { rv = 0; break; } curr = curr−>next; } pthread_mutex_unlock(&L−>lock); return rv; // 성공과 실패를 나타냄 - 이렇게 하면 검색 성공이나 실패의 경우 모두 동일한 리턴 코드를 실행한다.
- 이렇게 하면 코드에서 락을 획득하고 해제하는 문장 수를 줄일 수 있다.
- 버그 (락을 해제하지 않고 리턴하는 것과 같은) 발생 여지가 줄어 든다.
- before
개선된 병행 연결 리스트 전체 코드
void List_Init(list_t *L) {
L−>head = NULL;
pthread_mutex_init(&L−>lock, NULL);
}
void List_Insert(list_t *L, int key) {
// 동기화할 필요 없음
node_t *new = malloc(sizeof(node_t));
if (new == NULL) {
perror("malloc");
return;
}
new−>key = key;
// 임계 영역만 락으로 보호
pthread_mutex_lock(&L−>lock);
new−>next = L−>head;
L−>head = new;
pthread_mutex_unlock(&L−>lock);
}
int List_Lookup(list_t *L, int key) {
int rv = -1;
pthread_mutex_lock(&L−>lock);
node_t *curr = L−>head;
while (curr) {
if (curr−>key == key) {
rv = 0;
break;
}
curr = curr−>next;
}
pthread_mutex_unlock(&L−>lock);
return rv; // 성공과 실패를 나타냄
}
확장성 있는 연결리스트
병행이 가능한 연결리스트를 갖게 되었지만 확장성이 좋지 않다는 문제가 있다. 이러한 병행성 문제를 개선하기 위해 hand-over-hand locking(또는 lock coupling) 기법을 개발했다.
hand-over-hand locking
- 전체 리스트에 하나의 락이 있는 것이 아니라 개별 노드마다 락을 추가한다.
- 그리고 리스트 순회 시 다음 노드의 락을 먼저 획득하고 현재 노드의 락을 해제하는 방법이다.
- 개념적으로는 리스트 연산에 병행성이 높아지므로 좋을 것 같지만, 실제로는 락을 하나 두는 방법에 비해 속도 개선을 기대하기 어렵다.
- 각 노드에 락을 획득하고 해제하는 오버헤드가 매우 크기 때문이다.
결론: 큰 락을 사용하는 것이 병행 자료구조를 만들기에 표준이다.
3. 병행 큐
typedef struct __node_t {
int value;
struct __node_t *next;
} node_t;
typedef struct __queue_t {
node_t *head;
node_t *tail;
pthread_mutex_t headLock;
pthread_mutex_t tailLock;
} queue_t;
void Queue_Init(queue_t *q) {
node_t *tmp = malloc(sizeof(node_t));
tmp−>next = NULL;
q−>head = q−>tail = tmp;
pthread_mutex_init(&q−>headLock , NULL);
pthread_mutex_init(&q−>tailLock , NULL);
}
void Queue_Enqueue(queue_t *q , int value)
node_t *tmp = malloc(sizeof(node_t));
assert(tmp != NULL);
tmp−>value = value;
tmp−>next = NULL;
pthread_mutex_lock(&q−>tailLock);
q−>tail−>next = tmp;
q−>tail = tmp;
pthread_mutex_unlock(&q−>tailLock);
}
int Queue_Dequeue(queue_t *q , int *value)
pthread_mutex_lock(&q−>headLock);
node_t *tmp = q−>head;
node_t *newHead = tmp−>next;
if (newHead == NULL) {
pthread_mutex_unlock(&q−>headLock);
return −1; // 큐가 비어있음
}
*value = newHead−>value;
q−>head = newHead;
pthread_mutex_unlock(&q−>headLock);
free(tmp);
return 0;
}- 병행 큐에는 락이 head와 tail에 각각 하나씩 사용된다.
- 큐 삽입/추출 연산에 병행성을 부여하는 것이다.
- 큐는 멀티 쓰레드 프로그램에서 자주 사용되지만, 락 기능만 있는 큐는 사용하기 어렵다.
- 큐가 비었거나 가득 찬 경우, 쓰레드가 대기하도록 하는 기능이 필요하다
- 조건 변수(condition variable)을 이용하여 유한 큐를 만들 수 있다. (다음 장에 배울 것)
4. 병행 해시 테이블
#define BUCKETS ()
typedef struct __hash_t {
list_t lists[BUCKETS];
} hash_t;
void Hash_Init(hash_t *H) {
for (int i = 0; i < BUCKETS; i++) {
List_Init(&H−>lists[i]);
}
}
int Hash_Insert(hash_t *H , int key) {
int bucket = key % BUCKETS;
return List_Insert(&H−>lists[bucket] , key);
}
int Hash_Lookup(hash_t *H , int key) {
int bucket = key % BUCKETS;
return List_Lookup(&H−>lists[bucket] , key);
}- 이전에 학습한 병행 리스트를 사용하여 구현한 병행 해시테이블이다.
- 전체 자료구조에 하나의 락을 사용하지 않고, 해시 버켓마다 락을 사용하였다.
- 해시 테이블은 확장성이 좋다.
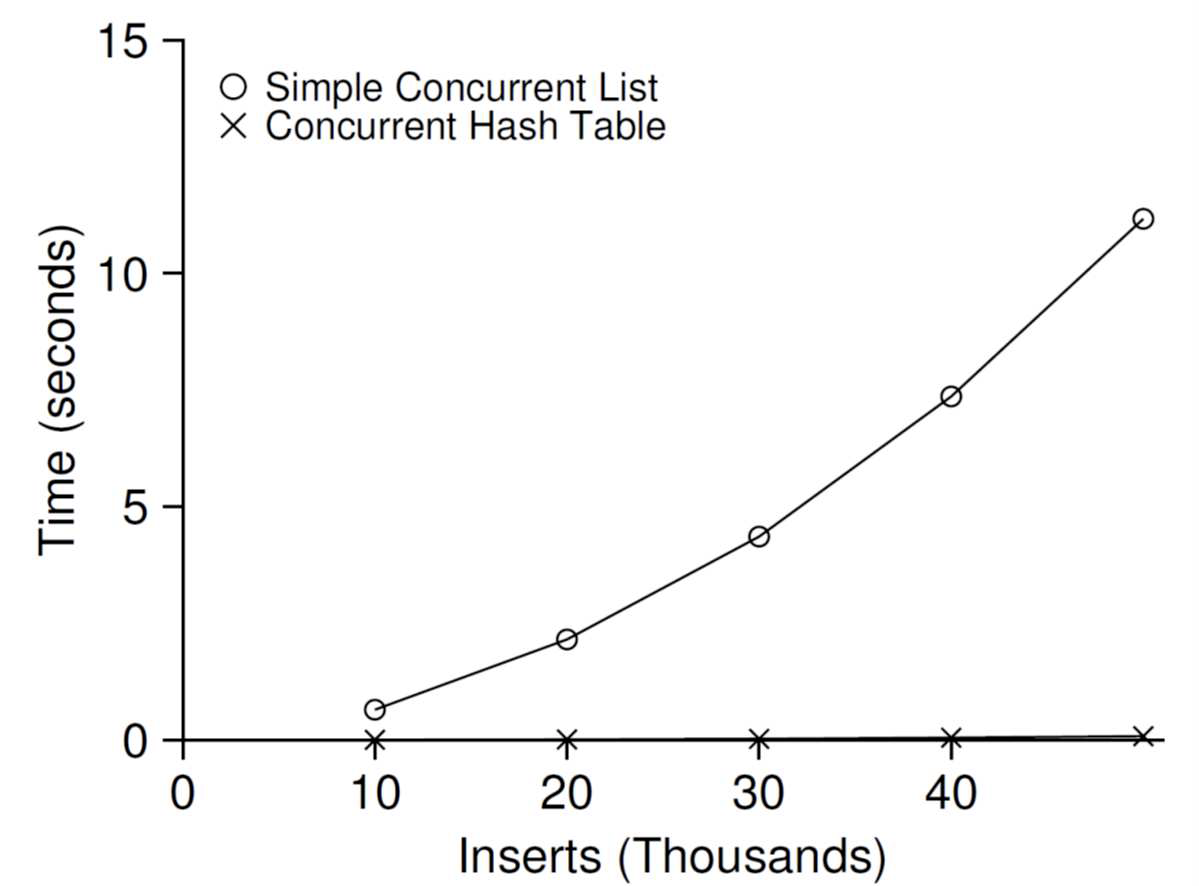
- 4개의 CPU를 갖는 시스템에서 4개의 쓰레드가 해시 테이블에 각각 1만 개에서 5만 개의 갱신 연산을 수행할 때의 성능이다.
- 범례 O는 단일 락을 사용하는 병행 리스트, 범례 X는 병행 해시 테이블이다.
5. 요약
- 락 획득/해제 시 코드의 흐름에 매우 주의를 기울여야 한다.
- 병행성 개선이 반드시 성능 개선으로 이어지는 것은 아니다.
- 성능 개선은 성능에 문제가 생길 경우에만 해결책을 간구해야 한다는 것이다.
- 미숙한 최적화(premature optimization)를 피하자.
- 병행 자료 구조를 만들 때는 하나의 큰 락을 추가하여 동기화 접근을 제어하는 가장 간단한 방법에서 시작하자.
- 그렇게 하면 제대로 동작하는 락을 만들 수 있게 된다.
- 성능 하락이 문제된다고 판단이 되면 그때 개선을 하자.

코딩연습