
컴퓨터 비전을 본격적으로 공부하기 시작하면서 명강의라고 평가 받는 스탠포드의 CS231n 강의를 정리하고자 한다.
원래 강의 자료는 여기서 볼 수 있다.
https://cs231n.github.io/classification/
Image Classification
컴퓨터는 이미지를 어떻게 분류하는 가?
Image Classificaiton이란 말 그대로 이미지를 분류하는 것이다.
이미지를 보고 어떤 카테고리에 넣어야할지 정하는 것.
우리는 바로 고양이인지 강아지인지 분류할 수 있지만, 기계에게는 이것이 매우 어렵다. 따라서 컴퓨터는 어떻게 생각하는지 생각해보자.
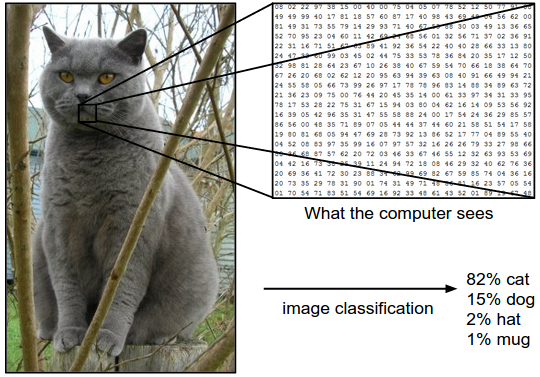
Challenge
이렇듯 이미지를 숫자로 인식한다. 우리는 여기서 Semantic Gap (사람과 컴퓨터가 인식하는 차이) 이라는 문제를 고려해야한다.
사람은 고양이가 움직이든, 숨어있든 고양이라는 것을 알 수 있다. 반면 컴퓨터가 위의 픽셀을 고양이라고 판단하였다고 해도, 카메라의 위치, 필터 등으로 픽셀이 조금이라도 변하면 고양이라는 것을 까먹을 수도 있다. 따라서 컴퓨터를 위한 알고리즘은 다음과 같은 문제를 고려해야 한다.
- ViewPoint variation : 카메라가 보여지는 곳, 각도 등
- Scale variation : 이미지 크기, 규모
- Occulusion : 다른 물체에 의해 가려지거나 안 보이는
- Illumination conditions : 조명
- background clutter : 주위 배경 때문에 고양이를 확인하기 어렵다.
- Intra-class variation : 고양이마다 다른 색과 모양을 가지고 있다.
고양이 마다 다른 색과 모양을 가지고 있음
이런 문제를 해결할 직관적이고 명시적인 알고리즘이 존재하지 않다.
해결하기 위해 이미지에서 edges를 계산하고 coners와 edges를 카테고리로 정리하여 규칙 집합을 써내려가는 방법을 고안하였으나 잘 동작하지는 않는다.
다음의 접근 방식을 이용해보자.
Data-Driven Approach
- 이미지와 라벨 데이터 셋을 모음
- 머신러닝으로 train
- 새로운 이미지를 이용하여 평가
Pipeline
이러한 아이디어에서의 image classification 파이프라인, machine learning의 key sight는 이렇다.
- input :이미지와 레이블 셋
- 학습
- 평가
train함수 : 입력은 이미지와 레이블, 출력은 모델
predict 함수 : 입력은 모델, 출력은 이미지 예측값
Nearest Neighbor Classifier
위의 방식으로 가장 간단한 알고리즘은 Nearest Neighbor 분류이다.
모든 데이터를 기반으로 학습하고, 가장 유사한 이미지로 라벨을 예측한다.
train 할 때는 O(1)이, predict 할 때는 O(N)이 걸린다.
하지만 우리는 빨리 test하기를 원한다. 목적에 정반대인 알고리즘인 것이다.
(뒤에서 이를 보완한 알고리즘을 소개한다.)

위 예시 이미지를 보게 되면 가장 유사한 이미지 순으로 되어 있다.
그렇다면 pair한 이미지가 있다면 어떻게 할까? 어떻게 두 이미지를 비교할 수 있을까?
Distance Metric
픽셀 간의 차이를 계산하는 방법이다. NN에서 사용할 수 있는 것은 다음과 같다. 둘 중 어느 것을 사용할지는 problem dependent 이다.
L1(Manhattan) Distance
픽셀 간의 차이 값 계산하고 절대값 취한다.
좌표계에 의존적이다. (데이터가 그런지 판단하고 사용할 것)
이를 이용한 NN 예시 코드이다.
import numpy as np
class NearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
""" X is N x D where each row is an example. Y is 1-dimension of size N """
# the nearest neighbor classifier simply remembers all the training data
self.Xtr = X
self.ytr = y
def predict(self, X):
""" X is N x D where each row is an example we wish to predict label for """
num_test = X.shape[0]
# lets make sure that the output type matches the input type
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
# loop over all test rows
for i in range(num_test):
# find the nearest training image to the i'th test image
# using the L1 distance (sum of absolute value differences)
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances) # get the index with smallest distance
Ypred[i] = self.ytr[min_index] # predict the label of the nearest example
return YpredL2(Euclidean) distance
좌표계와 연관 없음
특징 벡터가 일반적 벡터이고 요소들간의 실질 의미를 잘 모를 때 사용하면 좋다.
distances = np.sqrt(np.sum(np.square(self.Xtr - X[i,:]), axis = 1))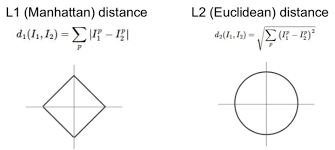
둘의 차이는 그래프로도 확인할 수 있다. 자신의 문제에 맞춰 잘 사용하면 된다.
K-Nearest Neighbors
NN은 가장 가까운 것을 찾기 때문에 모든 데이터에 대해 잘 고른 것이 아닐 수도 있다. 예를 들어, 강아지를 엄청 닮은 고양이 이미지를 골랐다고 하자. 고양이의 전체 데이터 셋에서는 동 떨어져 있을 것이다. 다음 그림에서 보면 NN으로 분류하면 동 떨어진 데이터들을 확인할 수 있다.

반면 오른쪽 그림은 보다 스무스한 것을 볼 수 있다. 이것이 K-NN 분류 방식이다.
가까운 이웃을 K개 만큼 찾고 투표를 해서 찾는 것 (majority vote)
K는 적어도 1보다 큰 값이다. (decision boundary가 부드러움)
Hyperparameter 찾기
하이퍼 파라미터는 우리가 train 하면서 직접 선택해야한다.
K가 무엇인지, distace를 어떻게 정할지와 같은 문제이다.
여러가지 시도해보고 좋은 것 선택해야 한다.
좋은 하이퍼 파라미터를 찾는 방법
-
idea #1 : 데이터에 가장 좋게 작동할 때 (학습데이터를 얼마나 잘 맞추는 것은 상과없음. 예측을 잘해야함) BAD
-
idea #2 : train시키고 test데이터에 적용하여 하이퍼 파라미터 선택 BAD -> 한번도 보지 못했던 데이터에 대해 예측을 잘 해야하기 때문에 (test set에서만 작동을 잘하는 거일 수도 있으니까)

-
idea #3 : 데이터를 세개로 나누는 것, train, val, test로 나눈다.
train set 학습시키고, val로 검증 (가장 좋았던 하이퍼파라미터 선택), 테스트 셋으로 단 한번만 수행 (이게 최종 수치)
validation data와 test data를 나눠두는 것이 중요 BETTER

-
idea #4 : Cross-Validation 트레이닝 데이터를 여러 부분으로 나눔. 좋지만, 계산량이 많아 실제로 잘 쓰지는 않음
? 여기서 validation set이란? train set과 비슷하게 느껴지지만 이 set에서는 레이블을 볼 수 없다. 알고리즘이 얼마나 잘 동작하는지만 확인 가능
- 다만, K-nn이 너무 느려서 이미지에 잘 쓰지는 않는다. 위에서 말했다시피 test하는데에 너무 오래걸린다.
L1/L2 distance도 이미지에 사용하기에 좋지 않다- perception decision 문제 (이미지 간의 시각적 유사성을 확인하는 척도로 좋지 않다.)
- Curse of dimensionality 문제 존재 (차원이 늘어나면 필요한 train data가 기하급수적으로 증가
Linear Classification
CNN 알고리즘을 위한 가장 기본 블럭 중 하나인 linear classification이다. 다른 모델들의 기본이 되기에 잘 알고 있어야 한다.
parametric model 이다.
데이터가 특정 분포를 따른다고 가정하고, 학습을 하면서 결정해야 하는 분포의 parameter 종류의 수가 명확하게 정해져 있다.
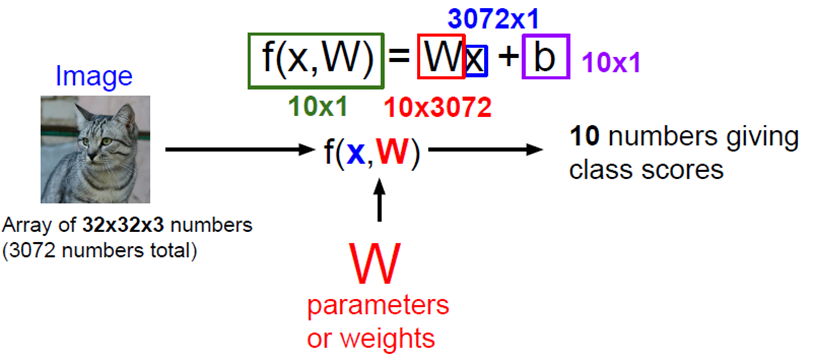
parameter W에 가중치를 다 모은다. test에 train set이 필요하지 않음
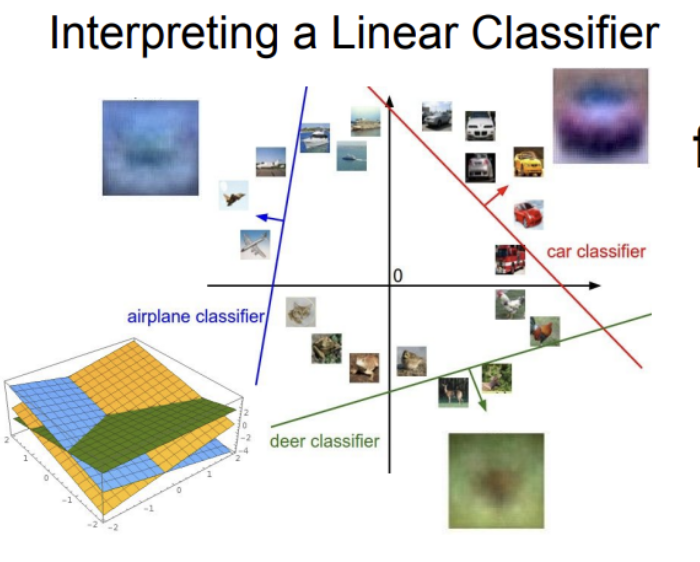
다만,, 각 클래스에 따라 하나의 템플릿만 학습한다. 다양한 모습이 있더라도 하나 뿐이다.
예를 들어 오른쪽을 보고 있는 말, 왼쪽을 보고 있는 말의 이미지를 학습한다면, 머리가 두개 달린 말의 이미지가 W에 쌓일 수도 있다.
위와 같이 선형 관계를 그어준다.
따라서 다음과 같은 경우에는 사용하기가 어렵다.
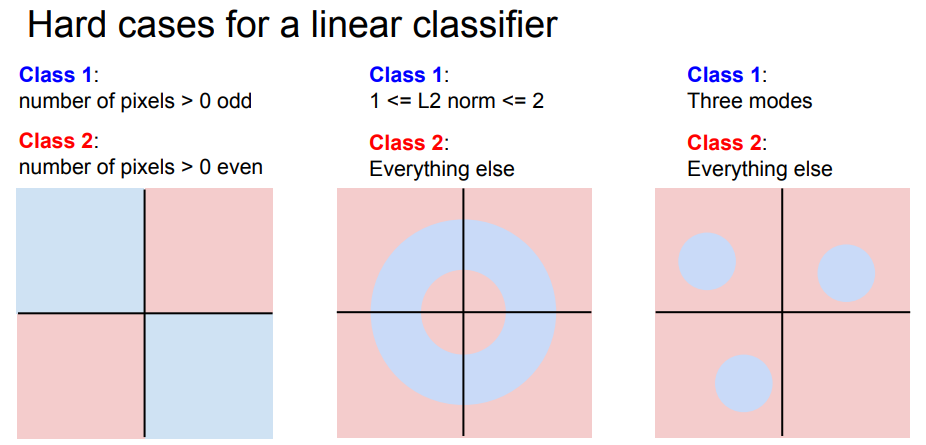
선을 긋는다고 class1과 class2가 분류될 수 있는 것이 아니기 때문이다.
사담
역시 stanford라 그런지 엄청 알아듣기가 쉽다...wow

Well done! Thanks for the post :)