원본 논문 여기서 보기
초록
- 3배 더 큰 UNet 백본
- 파라미터 증가 - attention block, 더 넓은 범위의 cross-attention context, 두번째 text 인코더 사용
- cross-attention
- Self-attention: 한 시퀀스 내의 토큰들 사이의 관계를 학습. 예를 들어, 문장 내의 단어들 사이의 관계나 문맥을 학습
- Cross-attention: 두 다른 시퀀스 간의 토큰들 사이의 관계를 학습. Encoder - Decoder 구조시. 예를 들어 encoder은 원문을 처리, decoder는 번역. decoder가 생성하는 단어나 토큰에 대해 원문의 적절한 부분에 주목해야하는데, 주목하는 매커니즘이 cross-attention.
- cross-attention
- 새로운 condition 스키마, 여러 aspect ratio(종횡비)로 훈련
- 개선된 모델 : post hoc image - to image 기법으로 시각적 fidelity 향상
- SD와 black-box state-of-the-art image generator 비교
- 내부 작동 원리가 불투명하지만 현재까지의 최고 성능을 나타내는 기술이라는 것
1 서론
- SD의 크게 개선된 버전인 SDXL
- 텍스트 to 이미지의 latent diffusion 모델인 stable diffusion과 그 활용에 대한 간단 설명
- SDXL은 stable diffusion 보다 뛰어난 성능을 보인다
- 3배 큰 UNet 백본
- 어떠한 형태의 추가 supervision도 필요하지 않은 두 가지 간단하지만 효과적인 추가 컨디셔닝 기술
- 샘플의 시각적 품질을 개선하기 위해 SDXL에서 생성된 latent에 noising-denoising process를 적용하는 별도의 diffusion 기반 정제 모델
- 미디어 생성 분야에서 블랙박스 모델의 불투명성 문제 존재, SDXL은 오픈 모델
2 개선된 Stable Diffusion
본 논문은 Stable Diffusion 아키텍처에 대한 개선 사항을 제시. 이들은 모듈식이며 개별적으로 또는 함께 사용하여 모든 모델을 확장 가능. 전략들은 LDM에 대한 확장으로 구현되지만 대부분은 픽셀 space의 DM에도 적용 가능.
inference
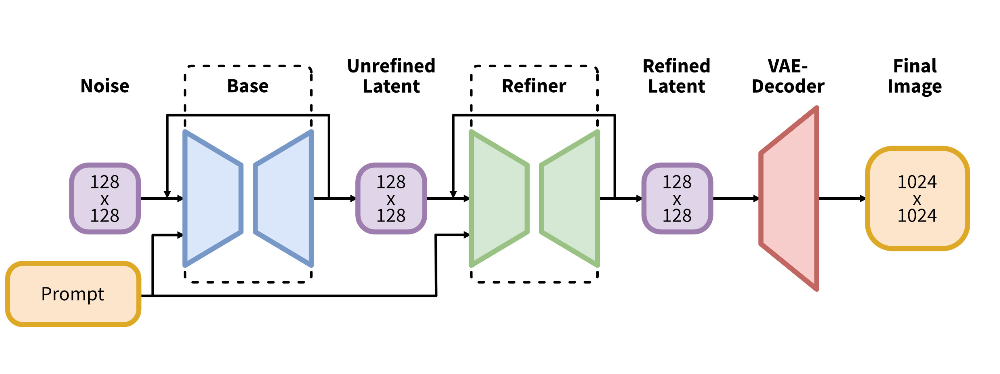
SDXL을 사용하여 128 x 128의 초기 latent 생성, refiner을 사용하여 latent에 SDEdit 적용, 이 때 같은 autoencoder 사용
- Prompt : 사용자 제공 입력 (지시)
- Refiner : 이미지 보정 및 개선
- VAE-Decoder(Variational Autoencoder Decoder) : latent 공간에서의 표현을 실제 이미지로 디코딩 (고해상도 출력)
- 추가 용어 latent : 데이터의 압축된, 은닉된 표현 / 원본 데이터의 복잡성을 줄이고 중요한 특성만 캡쳐 원본 데이터와 생성된 데이터 간의 차이를 점차적으로 줄이는 방식으로 작동 Stable Diffusion 모델은 이러한 점진적인 접근 방식을 사용하여 높은 품질의 이미지나 출력을 생성
2.1 아키텍쳐와 스케일
- 배경
- 초기 : Diffusion Models가 이미지 합성을 위한 강력한 생성모델
- 이후 convolutional UNet 아키텍처가 주요
- foundational DMs의 발전, 기본 아키텍쳐 발전
- self-attention 및 개선된 업스케일링 레이어 추가
- 텍스트를 이미지로 합성하기 위한 cross-attention
- 순수 transformer-based 아키텍처
- 추가 용어
- DM : 이미지나 텍스트 같은 데이터의 분포를 학습하여 새로운 샘플을 생성하는 모델. 원본 데이터를 점진적으로 변형하거나 확산하는 방식으로 작동
- Self-attention : 입력 데이터의 각 부분이 다른 부분과 얼마나 연관되어 있는지를 학습하는 메커니즘. 이를 통해 모델은 입력 데이터의 전체적인 문맥을 고려하여 작업 수행
- Cross-attention : 두 종류의 입력 (예: 텍스트와 이미지) 사이의 관계를 학습하는 메커니즘입니다. text-to-image 합성에서는 텍스트 설명과 관련된 이미지 부분을 집중적으로 학습
- pure transformer-based architecture : attention 매커니즘을 기반으로 하는 neural network architecture, 모델이 transformer만을 사용하여 구성됨
- attention 매커니즘 : 모든 입력 부분이 동일한 중요도를 가지는 것이 아니라, 특정 작업을 수행하는 동안 어떤 입력 부분은 다른 부분보다 더 중요할 수 있다는 것

Transformer(언어모델) 기반의 아키텍쳐, UNet과 결합
- transformer 계산의 대부분을 UNet의 하위 레벨 feature로 이동
- UNet 내에서 transformer 블록의 heterogeneous 분포를 사용 (불균일하게)
- highest feature level에서는 생략 (가장 낮은 해상도의 특성을 학습하는 level에는 transformer 블록이 없다는 것을 의미)
- low level 에서는 2-10개 블록 사용 (세부 정보를 학습하는 초기 level에 2개에서 10개 사이의 transformer 블록)
- UNet의 lowest level은 전체적으로 제거됨(가장 고해상도의 level이 모델에서 제거, 8 x 다운샘플링 - 가로와 세로 해상도 모두 1/8로)
- 텍스트 인코더 : 사전 훈련된 인코더 사용하여 텍스트 조건 적용. OpenCLIP ViT-bigG와 CLIP ViT-L을 결합. 인코더의 출력을 채널 축을 따라 연결
- 텍스트 입력 조건 : cross-attention 레이어 사용. OpenCLIP 모델에서 가져온 텍스트 임베딩으로 모델을 추가로 조건
- 모델 크기 : UNet에는 총 26억의 파라미터가 있으며, 텍스트 인코더에는 총 8.17억개의 파라미터
2.2 Micro-Conditioning
Conditioning the Model on Image Size
LDM의 한계점 - 최소 이미지 크기 필요 (2 step 아키텍쳐 때문)
가능한 해결법
- 특정 최소 해상도 아래의 모든 훈련 이미지 버림 ex. SD 1.4/1.5는 512 아래 버림
-
이미지 해상도에 따라 train data의 상당 부분이 버려질 수 있음 > 성능 저하
256^2 픽셀 미만의 샘플을 폐기하면 39%가 날아간다
-
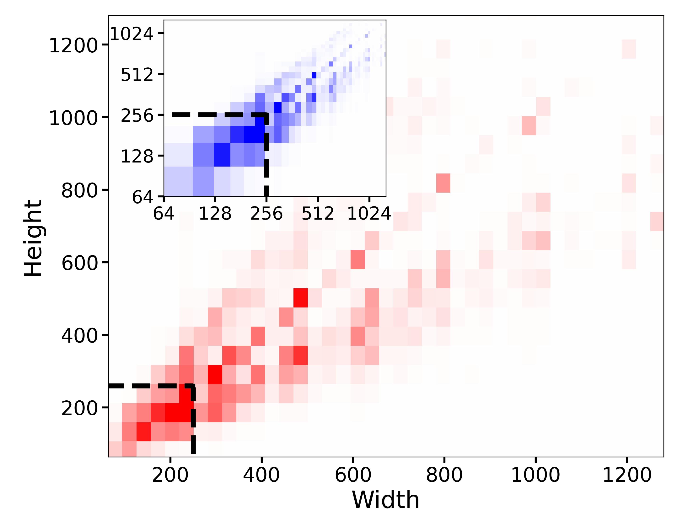
- 작은 이미지 업스케일
- 업스케일 아티팩트 도입 - 최종 모델 출력에 아티팩트 도입 > 흐릿한 샘플 생성 가능
제안된 해결법
- UNet 모델을 원본 이미지 해상도에 따라 컨디셔닝 (train 중에 쉽게 가능)
- 리스케일링 전의 원래 이미지의 높이와 너비를 모델에 추가 조건으로 제공 csize = (horiginal, woriginal)
- 각 구성 요소는 Fourier feature encoding을 사용하여 독립적으로 임베딩되며 이러한 인코딩은 timestep 임베딩에 concat되어 모델에 공급하는 단일 벡터가 된다
- 리스케일링 전의 원래 이미지의 높이와 너비를 모델에 추가 조건으로 제공 csize = (horiginal, woriginal)
- 추가 설명
각 구성 요소(예: 크롭 정보, 사이즈 정보 등)는 Fourier feature encoding을 통해 벡터 형태로 변환(임베딩)되며, 이 변환된 벡터들은 timestep 임베딩과 함께 연결(concatenate)됨. 이렇게 연결된 벡터는 모델에 입력으로 제공되는 하나의 긴 벡터가 됨

inference 시 유저는 이 크기 컨디셔닝을 통해 이미지의 원하는 겉보기 해상도를 설정할 수 있다. 모델은 컨디셔닝 csize를 주어진 프롬프트에 해당하는 출력의 모양을 수정하는 데 활용할 수 있는 해상도에 의존하는 이미지 feature와 연결하는 방법을 배웠다.
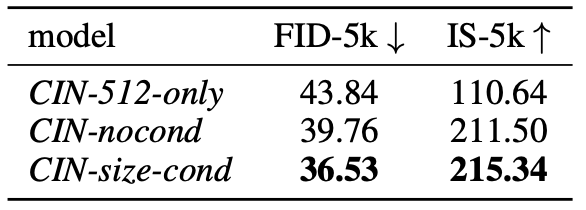
- CIN-512-only : 512 픽셀보다 작은 모든 훈련 예제 제외 > 70k 이미지만 사용 (훈련데이터 양 오버피팅)
- CIN-nocond : 모든 훈련 예제, 조건화 X (흐릿한 샘플 때문에)
- CIN-size-cond : csize = (512, 512) 조건화
이러한 고전적인 정량적 점수가 기본 DM의 성능을 평가하는 데 적합하지 않지만, FID와 IS의 backbone이 ImageNet에서 학습되었기 때문에 ImageNet에서 합리적인 메트릭으로 유지된다.
- 1024가 아닌 512인 이유 크기 컨디셔닝의 효과는 최종 SDXL 모델에 사용하는 이어지는 multi-aspect (ratio) fine-tuning 후에 명확하게 보이지 않기 때문 두 단계를 연속해서 진행하면, 첫 번째 단계에서 얻은 효과가 두 번째 단계에서 상대적으로 덜 중요하게 되어, 크기 컨디셔닝의 효과가 뚜렷하지 않게 될 수 있음 둘이 보완재라 그런듯함
Conditioning the Model on Cropping Parameters

위에서 보듯 머리가 잘리거나 할 수 있음
훈련 중 random crop을 사용하면서 문제가 생길 수 있음
- 동일한 크기의 텐서가 필요하기 때문에, 통상적으로 이미지 크기를 조정하고 더 긴 축을 따라 이미지를 무작위로 잘라내는 처리 파이프라인이 사용
- 데이터 증강에서 많이 쓰지만 이렇듯 문제가 생길 수 있음
해결법
- dataloading 과정에서 crop 좌표 Ctop Cleft를 균일하게 샘플링
- 위의 크기 컨디셔닝과 균일하게 Fourier feature embedding을 통해 컨디셔닝 파라미터로 모델에 입력
- 그런 다음 concat된 임베딩 Ccrop이 추가 컨디셔닝 파라미터로 사용
- 어떤 DM에서도 사용 가능
- 큰 규모의 데이터셋이 평균적으로 객체 중심적이라는 경험을 감안하여, infer 중에는 (ctop, cleft) = (0, 0)으로 설정하고 훈련된 모델에서 객체 중심의 샘플을 얻음

Crop 컨디셔닝과 크기 컨디셔닝을 쉽게 결합할 수 있다. 이러한 경우 UNet의 timestep 임베딩에 추가하기 전에 채널 차원을 따라 feature 임베딩을 concat힌다.

이러한 조합이 적용되는 경우 학습 중에 Ccrop과 Csize를 샘플링하는 방법
이미지의 크기와 cropping을 고려하여 모델을 조건화 하는 방법
# 훈련데이터셋 D, 훈련을 위한 목표 이미지 크기 s
# 크기를 변경하는 함수 R, 이미지를 잘라내는 함수 C
# 모델 훈련 단계 T
while not coverged do # converged는 모델이 수렴할 때까지 반복을 위한 조건
x ~ D # x는 데이터셋 D에서 무작위로 선택한 이미지
w_original = 원래이미지의 너비
h_original = 원래 이미지의 높이
c_size = (h_original, w_original)
x = R(x, s) # 이미지 x를 목표 크기 s로 리사이징
if h_original <= w_original :
c_left = 왼쪽에서 잘라내는 픽셀 수를 무작위로 선택 #데이터 증강과 동일
c_top = 0 # 위쪽에서는 잘라내지 않음
elif h_original > w_original :
c_top = 위쪽에서 잘라내는 픽셀 수를 무작위로 선택
c_left = 0 # 왼쪽에서는 잘라내지 않음
c_crop = (c_top, c_left)
x = C(x, s, c_crop) # 선택된 자표를 기반으로 자르기
converged = T(x, c_size, c_crop) # 잘라낸 이미지, 원래 이미지, 크롭 좌표로 모델 훈련이런 식으로 진행하면 cropping을 통한 data augmentation 이점을 얻음과 동시에 생성 프로세스로 유출되지 않도록 함. 실제로 이미지 합성 프로세스를 더 잘 제어하기 위해 이를 유리하게 사용 가능. 또한 구현하기 쉽고 추가 데이터 전처리 없이 학습 중에 온라인 방식으로 적용 가능
2.3 Multi-Aspect Training
실세계의 이미지의 다양한 종횡비를 고려하여 모델을 더 유연하게 만드는 방향으로 진행
실제 데이터셋에는 다양한 크기와 종횡비 이미지가 존재함.
모델의 출력 해상도는 보통 정사각형 이미지인데 부자연스러운 선택일 수 있음 (현실세계는 16:9이니까)
→ 여러 가로세로비(aspect-ratios)를 동시에 처리하도록 모델을 fine-tuning
- 데이터를 다양한 종횡비의 bucket으로 나눔
- 픽셀 수는 최대한 1024x1024를 유지하면서 높이와 너비를 64의 배수로 조절
- 훈련 중 bucket 사용
- 같은 버킷의 이미지로 train batch 구성
- 각 train 단계마다 bucket 크기를 번갈아 사용
- 해당 bucket 크기를 conditioning으로 받아들여 튜플 형태의 정수 Car = (Htgt, Wtgt)로 표현돼서 퓨리에 공간으로 임베딩
즉, 실제로 고정된 종횡비 및 해상도에서 모델을 사전 학습한 후 fine-tuning 단계로 multi-aspect 학습을 적용하고 채널 축을 따라 concatenation을 통해 컨디셔닝 기술과 결합
Crop 컨디셔닝과 multi-aspect 학습은 보완 작업이며 crop 컨디셔닝은 버킷 경계 (일반적으로 64픽셀) 내에서만 작동한다. 그러나 구현의 용이성을 위해 multi-aspect 모델에 대해 이 제어 파라미터를 유지하도록 선택한다
크기, 자르기, 종횡비 conditioning, 풀링된 텍스트 인코더 출력에 대한 퓨리에 임베딩을 생성하고 이를 채널 차원을 따라 연결하여 반환하는 과정
- 퓨리에 쓰는 이유 퓨리에 변환 : 시간 도메인의 신호를 주파수 도메인으로 변환하는 방법. 이 변환을 통해 신호의 주기적인 패턴과 성분을 분석 가능 퓨리에 임베딩이 필요한 이유 : 데이터 내의 주기적 패턴을 캡쳐하는 데에 도움이 됨. 시퀸스 데이터에서 위치 정보나 순서 정보를 주기적인 형태로 제공할 때 유용 text-to-image에서 : 데이터에 특정 조건을 부여하여 모델의 출력을 제어하고자 할 때, 조건 정보를 임베딩하여 모델에 제공해야 함. 퓨리에 임베딩은 이러한 조건 정보 (예: 이미지의 크기, 종횡비)를 주기적인 형태로 변환하여 모델에 추가 정보를 제공. 이렇게 함으로써 모델은 주어진 조건에 따라 더 적절한 출력을 생성하게 됨. x, y 축 픽셀이 어떻게 바뀌는지 캡쳐가능 속도에 따라 어떤 이미지인지 다름
from einops import rearrange import torch
batch_size =16
pooled_dim = 512 # 텍스트 인코더의 풀링된 출력의 채널 차원
def fourier_embedding(inputs, outdim=256, max_period=10000):
"""
다른 디퓨전 모델에서 일반적으로 사용되는 전통적인 삼각함수 timestep 임베딩을 생성하는 함수
:param inputs: batch of integer scalars shape [b,] 배치의 정수 스칼라
:param outdim: embedding dimension 주어진 차원의 임베딩
:param max_period: max freq added
:return: batch of embeddings of shape [b, outdim] """
...
def cat_along_channel_dim(x:torch.Tensor ,) -> torch.Tensor:
# 주어진 입력을 퓨리에 임베딩으로 변환하고 채널 차원을 따라 연결
if x.ndim == 1: #입력이 1차원이면 2차원으로 확장
x = x[...,None]
assert x.ndim == 2 #확장 후 x는 반드시 2차원이어야 함
b, d_in = x.shape #입력 텐서 크기
x = rearrange(x, "b din -> (b din)") #텐서 모양 변경
emb = fourier_embedding(x) # 퓨리에 임베딩을 적용하여 추가 차원 생성
d_f = emb.shape[-1] # 임베딩된 텐서의 마지막 차원 크기 저장
# 임베딩된 텐서의 모양을 다시 조정
emb = rearrange(emb, "(b din) df -> b (din df)", b=b, din=d_in , df=d_f)
return emb
def concat_embeddings(c_size:torch.Tensor, c_crop:torch.Tensor, c_ar:torch.Tensor , c_pooled_txt:torch.Tensor) -> torch.Tensor:
# 크기, 크롭, 종횡비 컨디셔닝에 대한 퓨리에 피쳐 계산
c_size_emb = cat_along_channel_dim(c_size)
c_crop_emb = cat_along_channel_dim(c_crop)
c_ar_emb = cat_along_channel_dim(c_ar)
# 모든 컨디션을 채널 차원에 따라 연결
return torch.cat([c_pooled_txt , c_size_emb , c_crop_emb , c_ar_emb], dim=1) # simulating c_size and c_crop as in Sec. 3.2
# 크기, 자르기 컨디션 시뮬레이션
c_size=torch.zeros((batch_size , 2)).long()
c_crop=torch.zeros((batch_size , 2)).long()
# 종횡비 조건 및 풀링된 텍스트 인코더 출력을 시뮬레이션
c_ar=torch.zeros((batch_size , 2)).long()
c_pooled=torch.zeros((batch_size , pooled_dim)).long()
# 조건을 바탕으로 임베딩을 연결하여 최종 결과 생성
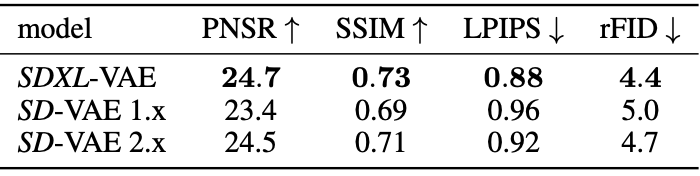
c_concat = concat_embeddings(c_size, c_crop, c_ar, c_pooled)2.4 Improved Autoencoder
- 오토인코더란
-
인공 신경망의 한 종류로, 입력 데이터를 압축하는 인코더와 압축된 데이터를 원래의 데이터로 복원하는 디코더로 구성
인코더: 입력 데이터를 더 낮은 차원의 잠재 공간(latent space)로 매핑 / 이 과정에서 데이터의 주요 특징이 추출됩니다.
디코더: 잠재 공간의 데이터를 다시 원래의 차원으로 매핑하여 원본 데이터를 재구성
목표는 입력 데이터와 재구성된 데이터 간의 차이, 즉 재구성 오차를 최소화
-
Stable Diffusion : 오토인코더의 사전 학습된 latent space에서 작동하는 LDM (Latent Diffusion Model)
Semantic 구성의 대부분 - LDM에 의해 수행
BUT 오토인코더를 개선하여 생성된 이미지에 로컬한 고주파 디테일 개선 가능
→ 개선
- 배치 크기 : 원래 SD에서 사용된 오토인코더 아키텍처를 사용해 더 큰 배치크기로 훈련(256 vs 9)
- 더 많은 데이터 한번에 처리 → 안정적
- 지수 이동 평균 : 모델의 가중치를 exponential moving average로 추적. 가중치 변동을 안정화하는 데에 도움
- EMA 시계열 데이터 분석에서 자주 사용되는 방법 최근의 데이터 포인트에 더 많은 가중치를 부여하여 과거의 데이터보다 최근의 데이터가 더 중요하다고 가정 → 최근의 변화에 더 민감하게 반응하는 특성EMA는 시간 t에서 지수 이동 평균 Price는 t에서의 실제 관측 값 alpha는 감쇠 계수 - 크면 최근 값에 더 많은 가중치, 작으면 과거의 가격에 더 많은 가중치 최근의 가중치 변화에는 더 큰 가중치를 부여하면서도, 이전의 가중치 정보도 어느 정도 포함하고 있음. 이로 인해 갑작스런 변화나 잡음(noise)에 대해 덜 민감하게 반응하게 됨. 이렇게 가중치의 변화를 부드럽게 추적함으로써 학습 도중 발생할 수 있는 급격한 변동을 완화시킴
- EMA 시계열 데이터 분석에서 자주 사용되는 방법 최근의 데이터 포인트에 더 많은 가중치를 부여하여 과거의 데이터보다 최근의 데이터가 더 중요하다고 가정 → 최근의 변화에 더 민감하게 반응하는 특성
- 뛰어난 성능~
2.5 Putting Everything Together
SDXL을 학습시키는 과정 (다단계 절차)
- 모델 구성: 위의 오토인코더 + 1000 단계의 discrete-time diffusion schedule
- 기본 모델 pretrain:
- 내부 데이터셋에 기반하여 SDXL의 기본 모델을 pretrain
- 학습은 256 × 256 픽셀 해상도에서 60만개 최적화 스텝
- 배치 크기는 2048
- 위의 크기와 크롭 조절 기법을 사용
- 512 × 512 픽셀 이미지 학습 계속:
- 해상도를 높여 512 × 512 픽셀 이미지로 학습을 200,000번의 추가 최적화 스텝 동안 계속
- 다양한 종횡비로 학습:
- Sec. 2.3에서 설명한 다양한 aspect ratio를 가진 이미지로 학습
- 이때 offset-noise 수준은 0.05
- 최종적으로 약 1024 × 1024 픽셀 영역의 다양한 ratio 를 갖는 이미지로 모델을 학습
Refinement Stage
실험 결과에서 부분적으로 낮은 품질의 샘플을 생성함
→ 향상 방법
- 기본 모델의 샘플 품질을 향상시키기 위해 같은 latent 공간에서 고해상도, 고품질 데이터에 특화된 별도의 LDM을 학습시킴
- SDEdit에서 소개된 방법을 사용하여 기본 모델의 noising-denoising process를 적용
- image to image pipeline 이미지 논문 (SDEdit) - guide image 줌. 노이즈를 add(완전 랜덤x, 원본 이미지 데이터 존재) > denoising
- 이 refinement 모델은 처음 200개의 노이즈 스케일에 특화시킴
- Inference하는 동안 base SDXL에서 latent를 렌더링하고 동일한 텍스트 입력을 사용하여 정제 모델로 latent space에서 직접 diffuse하고 denoise
- 선택사항이지만 성능이 좋았다 ~
3 Future Work
모델을 더욱 개선할 수 있는 방법
- Single stage : 현재 SDXL에서 최고의 샘플을 생성하기 위해 추가 개선 모델을 사용한 두 단계 접근법을 사용함. 이로 인해 두 개의 큰 모델을 메모리에 로드해야 하므로 접근성과 샘플링 속도가 떨어짐.
- 텍스트 합성: 모델의 크기와 확장된 텍스트 인코더 덕분에 텍스트 렌더링 능력이 개선되었지만, 바이트 수준의 토크나이저를 포함하거나 모델을 더 크게 확장하는 것이 텍스트 합성을 더 개선
- 아키텍처: 탐색 단계에서 UViT와 DiT와 같은 트랜스포머 기반 아키텍처를 실험했지만 즉각적인 이점을 발견하지 못함. But 하이퍼파라미터 연구를 통해 트랜스포머 중심의 아키텍처로 더 크게 확장할 수 있을 것으로 기대합니다.
- Distillation(증류): 원래 Stable Diffusion 모델에 대한 개선이 크지만, infer 비용이 늘어남. 미래의 연구는 추론에 필요한 계산량을 줄이고, 샘플링 속도를 늘리는데에 중점
- 모델 학습 : 모델은 discrete-time 형식으로 학습되며, 미적으로 만족스러운 결과를 위해 offset-noise 가 필요. Karras 등의 EDM-프레임워크는 연속 시간에서의 수식화로 샘플링 유연성을 높이며, 노이즈 일정 수정이 필요하지 않기 때문에 미래의 모델 학습을 위한 유망한 후보
- 추가 용어 offset-noise : 생성된 이미지나 데이터에 추가되는 노이즈. 이런 노이즈 추가는 종종 생성 모델의 결과를 더 자연스럽게 만들기 위해 사용됨 discrete-time : 시간이 연속적이지 않고 일정 간격으로 나뉘어진 것을 의미. 예를 들어, 디지털 시스템에서 시간이 일정한 간격으로 표본화되어 처리되는 경우 이를 '이산 시간’ 이라 함. 즉 학습 과정이 일정한 시간 간격으로 진행 (그냥 정수랑, 실수로 표현해도 discrete함) 노이즈 레벨 표현 요즘은 continuous 모델이 대세
Appendix
Limitation
- 모델은 인간의 손과 같은 복잡한 구조를 합성할 때 문제에 직면 가능
- 다양한 범위의 데이터에 대해 학습을 받았지만 인체의 복잡성으로 인해 지속적으로 정확한 표현을 달성하는 데 어려움이 있음.
- 이러한 현상이 발생하는 이유는 손과 유사한 물체가 사진에서 매우 높은 분산으로 나타나며 이 경우 모델이 실제 3D 모양 및 물리적 한계에 대한 지식을 추출하기 어렵기 때문일 수 있음
- 생성된 이미지에서 놀라운 수준의 사실감을 달성하지만 완벽한 포토리얼리즘을 달성하지는 못함
- 미묘한 조명 효과 또는 미세한 질감 변화와 같은 특정 뉘앙스가 생성된 이미지에 여전히 없거나 덜 충실하게 표현될 수 있다.
- 모델의 학습 프로세스는 대규모 데이터셋에 크게 의존하므로 실수로 사회적 및 인종적 편견을 도입할 수 있다.
- 길고 읽기 쉬운 텍스트를 렌더링할 때 여전히 어려움에 직면
- 때때로 생성된 텍스트는 임의의 문자를 포함하거나 불일치를 나타낼 수 있음
- 샘플에 여러 개체 또는 주제가 포함된 특정 경우 모델에서 “concept bleeding”이라는 현상이 나타날 수 있음
- 이 문제는 의도하지 않은 병합 또는 고유한 시각적 요소의 겹침으로 나타난다. (여러 개념이 하나의 출력에 섞이는 현상)

파란색 선글라스 대신 주황색 선글라스가 관찰되는데 이는 주황색 스웨터에서 개념이 번진 것이다. 이것의 근본 원인은 사용된 사전 학습된 텍스트 인코더에 있을 수 있다. 텍스트 인코더는 모든 정보를 단일 토큰으로 압축하도록 학습되어 올바른 속성과 객체만 바인딩하는 데 실패할 수 있다. 또한 contrastive loss도 이에 기여할 수 있다. 동일한 batch 내에서 바인딩이 다른 부정적인 예가 필요하기 때문이다.
-
자세히
contrastive loss를 계산할 때 동일한 배치 내에서 서로 다른 카테고리나 클래스의 데이터 포인트가 필요하다는 것을 의미. 이렇게 되면, 모델이 동일한 배치의 데이터 포인트들 사이에서 높은 차별성을 학습하려고 할 때, 여러 개념들이 서로 섞일 위험이 있음 -
디퓨전 모델과의 차이
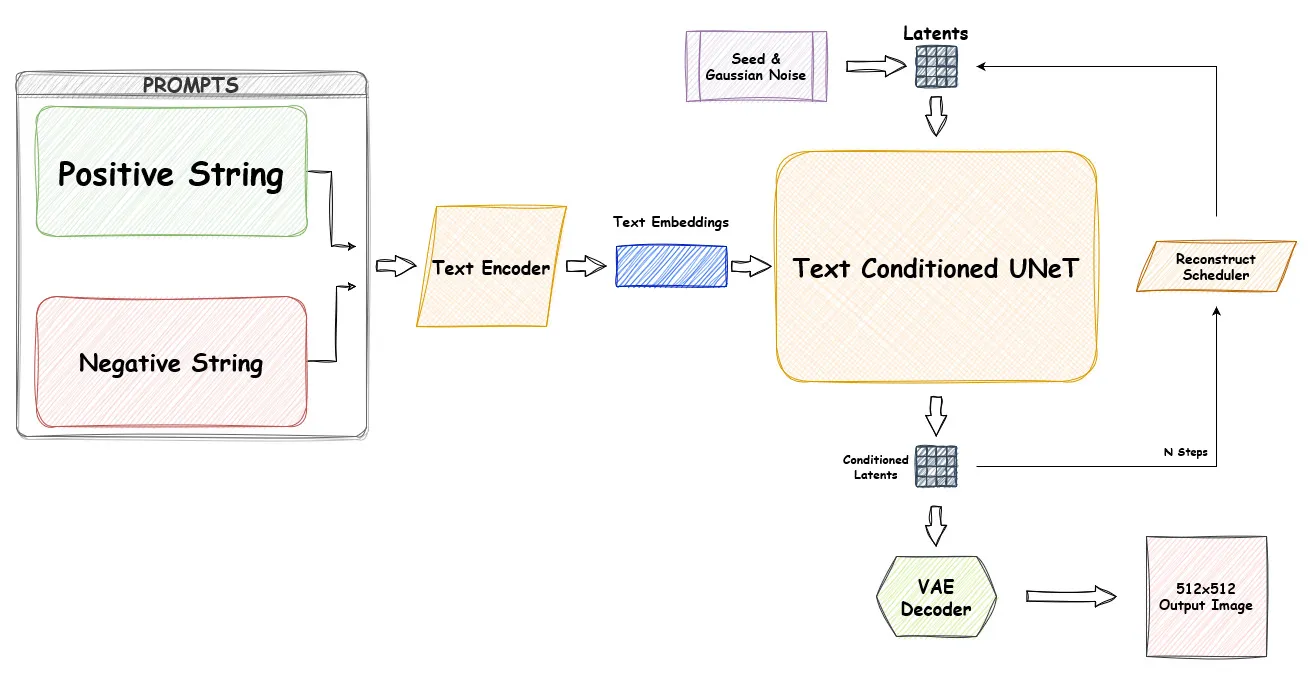
위의 그림에 이것저것을 추가한 SDXL
--
어렵지만,,, 흥미로운,,,
