
자료구조란?
자료구조란, 데이터를 표현하고 저장하는 방법이다.
- 정수를 저장하기 위한
int형 변수 - 개인정보를 저장하기 위한
구조체 - 다양한 정보를 한꺼번에 저장하기 위한
배열
등등 다양한 형태가 가능하다.
어떤 자료구조가 있는지 자세히 확인해보자!
자료구조의 종류
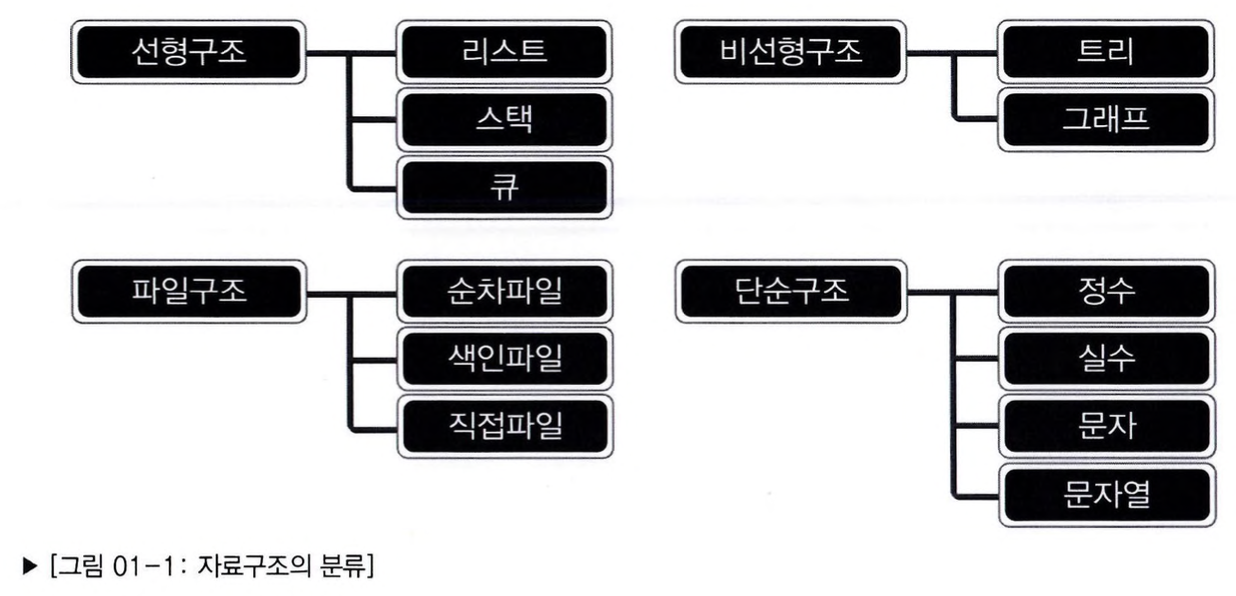
위의 이미지와 같이 자료구조는 크게 선형구조, 비선형구조, 파일구조, 단순구조로 구분할 수 있다.
여기서 우리는 선형 자료구조와 비선형 자료구조에 집중하여 공부할 것이다.
선형 자료구조란 말그대로 데이터를 선의 형태로 나란히 혹은 일렬로 저장하는 자료구조이고,
비선형 자료구조란 데이터를 나란히 저장하지 않는 구조이다.
자료구조와 알고리즘
자료구조와 알고리즘은 뗄래야 뗄 수 없는, 아주 밀접한 관련이 있다.
자료구조는 앞서 데이터의 표현 및 저장 방법을 의미한다고 소개했는데,
알고리즘은 자료구조를 통해 표현 및 저장된 데이터를 대상으로 하는 문제의 해결 방법을 의미한다.
즉, 자료구조가 결정되어야 그에 따른 효율적인 알고리즘을 결정할 수 있다.
= 자료구조에 따라 알고리즘이 달라진다.
= 알고리즘은 자료구조에 의존적이다.
여기서, 효율적인 알고리즘이란 무엇일까?
어떤 알고리즘을 효율적인 알고리즘이라고 할 수 있는 것일까?
시간 복잡도와 공간 복잡도
알고리즘의 효율성을 판단하는 기준에는 시간 복잡도와 공간 복잡도가 있다.
-
시간복잡도란, 속도에 해당하는 알고리즘의 수행시간 분석 결과이다.- 어떤 알고리즘이 어떤 상황에서 더 빠르고 느리냐?
-
공간복잡도란, 메모리 사용량에 대한 분석 결과이다.- 어떤 알고리즘이 어떠한 상황에서 메모리를 적게 쓰고 또 많이 쓰냐?
당연하게도 최적의 알고리즘은 메모리를 적게 쓰고, 속도도 빠른 알고리즘을 의미한다.
But, 일반적으로 알고리즘을 평가할 때는 실행속도에 초점을 둔다!
그렇다면 알고리즘의 실행 속도는 어떻게 측정할 수 있을까?
시간복잡도를 계산하는 방법 = 연산의 횟수 세기
연산의 횟수를 통해 알고리즘의 빠르기를 판단할 수 있다. (연산의 횟수가 적을수록 빠른 알고리즘)
연산의 횟수를 파악했다면, 데이터의 수 n에 대한 연산횟수의 함수 T(n)을 구성한다.
연산횟수의 함수 T(n)을 정의하면, 데이터 수의 증가에 따른 연산횟수의 변화 정도를 판단할 수 있다.
말로만 들어서는 감이 잘 잡히지 않을 수 있다.
이해를 위해 간단한 탐색 알고리즘 2가지로 시간 복잡도를 계산해보자!
순차 탐색(Linear Search) 알고리즘과 시간 복잡도 분석의 핵심 요소
순차탐색 알고리즘이란, 맨 앞에서부터 순서대로 탐색을 진행하는 알고리즘을 의미한다.
for(i=0; i<len; i++)
{
if(ar[i] == target)
return i;
}위 코드는 보다시피 ar 배열에 원하는 target이 있는지 확인하고, 있다면 인덱스를 반환하는 알고리즘이다.
위 코드를 토대로 (1)시간 복잡도를 분석하여, (2)데이터의 수 n에 대한 연산횟수의 함수 T(n)을 구해보자.
-
위 알고리즘에서 사용된 연산자 파악
<,++,== -
좋은 탐색 알고리즘이 되기 위해 적게 수행하면 좋을 연산자 파악
= 알고리즘의 핵심이 되는 연산 파악탐색 알고리즘에서의 핵심: 동등비교를 하는 비교 연산
다른 연산들은
==에 의존적이다.
→ 값의 동등을 비교하는==연산을 적게 수행하는 탐색 알고리즘이 좋은 탐색 알고리즘이다.
→==연산의 횟수를 대상으로 시간 복잡도를 분석하면 된다.알고리즘의 시간 복잡도를 계산하기 위해서는, 핵심이 되는 연산이 무엇인지 잘 판단해야 한다!
-
최악의 경우의 연산횟수 파악
데이터 수가 n개일 때, 최악의 경우에 해당하는 연산횟수는(비교연산의 횟수는) n이다.
-
데이터 수 n에 대한 연산횟수의 함수 T(n) 도출
T(n) = n
이진 탐색(Binary Search) 알고리즘
이진탐색 알고리즘이란, 정렬되어 있는 리스트에서 탐색 범위를 절반씩 좁혀가며 데이터를 탐색하는 알고리즘이다.
배열을 대상으로 이진 탐색을 적용하기 위해서는, 배열에 저장된 데이터가 정렬되어 있어야 한다.
- 정렬된 데이터가 아니면 적용이 불가능하다.
- 정렬의 기준 및 방식은 상관 없다.

위의 배열을 arr이라고 할 때, arr에 '3'이 있는지 없는지를 이진 탐색 알고리즘을 통해 확인해보자.
-
배열의 가운데 인덱스 값 찾기 (시작: 0, 끝: 8 → 중간:
4) -
arr[4]에 3이 있는지 확인 -
3이 없으므로,
arr[4]와 3의 대소 비교 진행 -
arr[4]값이 3보다 크므로, 탐색의 범위를 0~3으로 제한함 -
인덱스 0~3의 가운데 인덱스 값 찾기 (시작: 0, 끝: 3 → 중간:
1(나머지 버림)) -
arr[1]에 3이 있는지 확인 -
3이 없으므로,
arr[1]과 1의 대소 비교 진행 -
arr[1]값이 3보다 작으므로, 탐색의 범위를 2~3으로 제한함 -
...
이진탐색: 탐색의 대상을 반복해서 반씩 떨구어냄
순차 탐색 알고리즘에 비해 좋은 성능을 보임
이진 탐색 알고리즘의 구현
- 이진탐색은
first <= last인 경우까지 탐색을 진행한다.즉, first가 last보다 큰 경우에 탐색이 종료된다.
def binary_search(arr, target):
first = 0
last = len(arr) - 1
while first <= last:
mid = (first + last) // 2 # 탐색 대상의 중앙 찾기
if target == arr[mid]:
return mid
else:
if target < arr[mid]:
last = mid - 1
else:
first = mid + 1
return -1
print(binary_search([1, 3, 5, 7, 9], 7))
# result: 3이진 탐색 알고리즘의 시간 복잡도 계산하기
- 이진 탐색 알고리즘의 연산횟수를 대표하는 연산 찾기
while first <= last:
mid = (first + last) // 2 # 탐색 대상의 중앙 찾기
if target == arr[mid]:
return mid
else:
...이진 탐색 알고리즘 역시, 순차 탐색 알고리즘과 마찬가지로 == 연산이 연산횟수를 대표한다.
-
데이터의 수가 n개일 때, 최악의 경우 발생하는 비교연산의 횟수 파악
데이터의 수 n이 n/2, n/4, n/8 ... 로 줄어서 1이 될 때까지 비교연산을 한 번씩 진행하고,
마지막으로 n이 1일 때 비교연산을 한 번 더 진행함 -
데이터 수 n에 대한 연산횟수의 함수 T(n) 도출
(도출 과정은 직접 유도해볼 것!)T(n) = log2n
위처럼 도출한 연산횟수의 함수 T(n)을 알고리즘의 복잡도로 그대로 사용하기엔, 복잡한 구석이 없지 않다.
이때 사용하는 것이 빅-오 표기법이다!
빅-오 표기법(Big-Oh Notation)
빅오 표기법이란, 데이터 수의 증가에 따른 연산횟수의 증가 형태를 나타내는 표기법 (증가율의 상한선을 표현하는 표기법)을 의미한다.
ex. T(n) = n2 + 2n + 1 인 경우,
T(n) = n2로 간략화하는 것
→ O(n2)
대표적인 빅-오
| Big-Oh | 설명 |
|---|---|
| O(1) | 상수형 빅오 데이터 수에 상관없이 연산횟수가 고정 |
| O(logn) | 로그형 빅오 데이터 수의 증가율에 비해 연산 횟수의 증가율이 훨씬 낮음 |
| O(n) | 선형 빅오 데이터의 수와 연산횟수가 비례 |
| O(nlogn) | 선형로그형 빅오 데이터의 수가 두 배로 늘 때, 연산횟수는 두 배를 조금 넘게 증가 |
| O(n2) | 데이터 수의 제곱에 해당하는 연산횟수 요구 이중으로 중첩된 반복문 내에서 연산이 진행되는 경우에 발생 |
| O(n3) | 데이터 수의 세 제곱에 해당하는 연산횟수 요구 삼중으로 중첩된 반복문 내에서 연산이 진행되는 경우에 발생 |
| O(2n) | 지수형 빅오 사용하기에 매우 무리가 있는, 사용하는 것 자체가 비현실적인 알고리즘 |
빅오 성능 정리
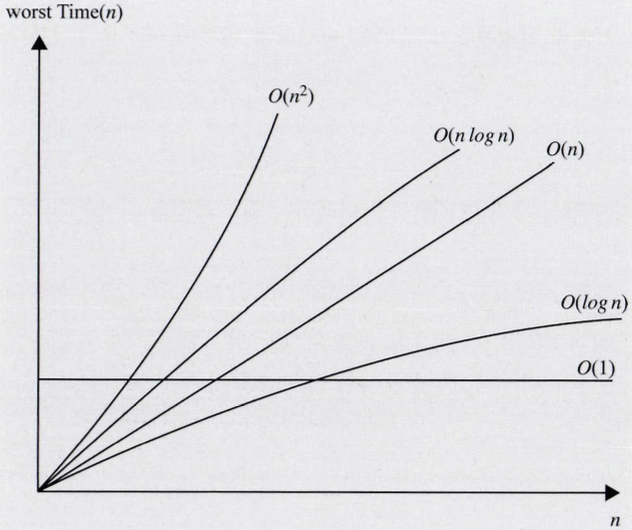
O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(n3) < O(2n)
Reference
