원핫 인코딩(One-Hot Encoding)
원핫 인코딩은 가변수라고도 하는데, 이것은 사람이 이해할 수 있는 데이터를 컴퓨터에게 주입시키기 위한 가장 기본적인 방법이다. 이 기술은 데이터를 수많은 0과 한개의 1의 값으로 데이터를 구별하는 인코딩이다. 파이썬으로 원핫 인코딩으로 구현하면 다음과 같다.
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
str = "저는 인공지능에 관심이 많습니다."다음과 같이 선언을한다.
tokenizer = Tokenizer()
tokenizer.fit_on_texts([str])
print(tokenizer.word_index)
# > {'저는': 1, '인공지능에': 2, '관심이': 3, '많습니다': 4}결과는 공백을 기준으로 데이터를 분리한다.
더 쉽게 이해하자면 배열의 각자리의 인덱스를 공백을 기준으로 나눈 데이터라고 생각하면 된다.
'저는' = [1,0,0,0]
'인공지능에' = [0,1,0,0]
'관심이' = [0,0,1,0]
'많습니다.' = [0,0,0,1]와같이 표현을 할 수 있다.
원핫 인코딩을 사용하는 이유
원핫 인코딩을 사용하는 이유는 한 데이터은 동시에 한 가지 유형만이 될 수 있어 매우 직관적이다. 따라서 데이터가 서로 관련이 없고 명확하지 않은 경우 활용된다. 또한 문자 데이터 같은 경우에는 숫자로 변환을 해야 데이터를 다루기가 쉽기 때문이다.
Pandas에서 원핫 인코딩 사용법
Pandas에서도 원핫 인코딩을 도와주는 함수가 있다. 바로 get_dummies()이다. get_dummies() 사용법은 다음과 같다.
import numpy as np
import pandas as pd
fruit = pd.DataFrame({'name':['apple', 'banana', 'cherry', 'durian', np.nan],
'color':['red', 'yellow', 'red', 'green', np.nan]}) # np.nan = nan(null)값 입력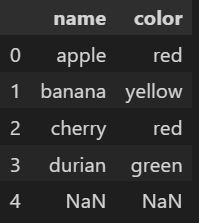
여기서 'name'열을 get_dummies()로 원핫 인코딩을 하면
pd.get_dummies(fruit['name'])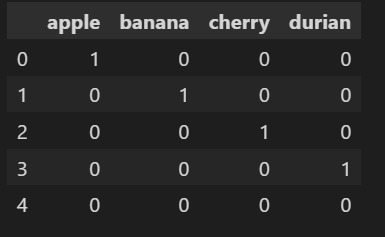
결측치(Nan)을 제외하고 0과 1로 변환되었다.
만약 데이터프레임 전체를 하게되면
pd.get_dummies(fruit)
보면 color_red는 10100인데 이것은 apple도 red이고, cherry도 red이기 때문에 두 컬럼을 의미하는 인덱스가 전부 1이 된것이다.
-> 10000(apple), 00100(cherry) ==> 10100(red)
이제 데이터프레임에서 특정 열만을 인코딩을 하면
pd.get_dummies(fruit, columns = ['name'])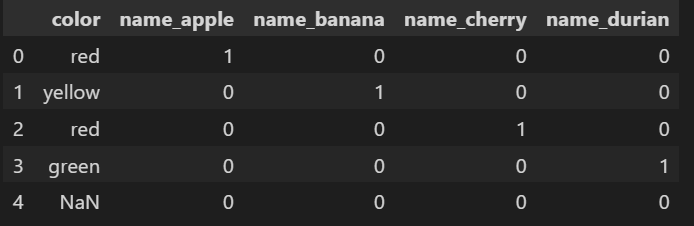
지정되지 않은 열은 그대로이고, 지정된 열만 인코딩 되었다.
만약 결측치값도 같이 처리를 하고 싶다면
pd.get_dummies(fruit['name'], dummy_na=True)처럼 하면 결측치도 같이 처리가 된다
