데이콘에서 데이콘 입문하는데 처음으로 나오는 대회(?), 프로젝트이다. 그래서 천천히 해볼려고 한다.
데이콘 링크 : https://dacon.io/competitions/open/235536/overview/description
링크를 들어가서 데이터 파일들을 다운 받으면 된다.
데이터 불러오기
일단 간단하게 데이터를 pandas를 통해서 불러오면 된다.
import pandas as pd # pandas 라이브러리를 불러온다.
train = pd.read_csv('movies_train.csv') # train셋 불러옴
test = pd.read_csv('movies_test.csv') # test셋 불러옴다음과 같이 데이터 셋을 불러온다.
데이터 전처리
train.info() #train의 값 요약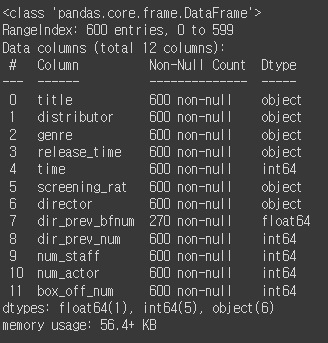
다음과 같이 나온다. 보면 dir_prev_bfnum 컬럼만이 수가 부족하다. 그리고 결측치, 비어있는 값이 있는지 확인을 해 본다.
train.isnull() # train에서 결측치, null이 있는지 확인함다음을 실행하면 행과 열로 나와서 True, False로 나눠진다. True는 null인 것이고, False는 값이 있다는 것을 의미한다.
train.isnull().sum()다음의 코드를 실행하면 각 컬럼마다 null 값의 합을 출력한다.
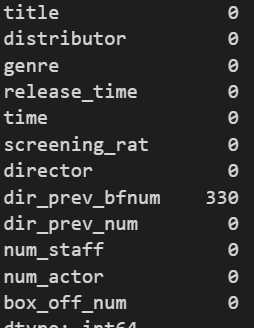
출력하면 다음과 같이 나오는데, dir_prev_bfnum 에서 결측치가 상당히 많이 나온다.
보면 수와 결측치가 있는 dir_prev_bfnum는 예측을 하는데 좋지 않는 컬럼으로 생각할 수 있어서 dir_prev_bfnum 컬럼은 없애는게 더 좋을 듯 하다.
train = train.drop(['dir_prev_bfnum'], axis = 1)
test = test.drop(['dir_prev_bfnum'], axis = 1)train과 test 모두 없애줘야만 한다. 그이유는 지도학습을 하기 때문에 test에서도 같이 없애줘야만 한다.
drop 함수에서는 (원하는 컬럼 또는 인덱스, axis = (0 or 1))의 꼴이다.
axis는 축을 지정하는 것이다. 1일 경우는 컬럼(열)을, 0은 인덱스(행)를 뜻한다. 따라서 컬럼 또는 인덱스 중 고르는 것과 axis의 값이 같아야만 한다. 예로 컬럼을 삭제를 원하면 axis의 값은 1, 인덱스는 0. 그렇지 않고 하면 에러가 난다.
이제는 예측에 딱히 영향력이 없는 컬럼들을 삭제할 것이다.

다음에서 관객수에 관계가 없다고 생각이 드는 컬럼은 dir_prev_num이라고 생각이 든다. 그래서 이 컬럼은 삭제할 것이다.
train = train.drop(['dir_prev_num'], axis=1)
test = test.drop(['dir_prev_num'], axis=1)감독 이름은 많기도하고, 굳이 필요할까라는 생각이 들어서 삭제하였다.
train = train.drop(['director'], axis = 1)
test = test.drop(['director'], axis = 1)이제 개봉일을 보면 다음과 같다.
train['release_time']
object 타입으로 구성되어있다. 이것을 조금 더 보기 편하고, 다루기 쉽게 년,월로 컬럼을 나눠서 재구성을 할 것이다.
train['년'] = train['release_time'].apply(lambda x: int(x[:4]))
train['월'] = train['release_time'].apply(lambda x: int(x[5:7]))
train = train.drop(['release_time'],axis = 1)
test['년'] = test['release_time'].apply(lambda x: int(x[:4]))
test['월'] = test['release_time'].apply(lambda x: int(x[5:7]))
test = test.drop(['release_time'],axis = 1)와 같이 하면 된다. 여기서 .apply(lamba x : int(x[:4]))에서 lambda는 함수로, x는 매개변수, : 뒤에는 매개변수를 활용한 식이다. 위에 코드는 x는 train에서의 release_time 컬럼의 값을 의미하고, 뒤에서는 처음부터 4-1자리까지의 값을 정수형으로 바꾼다음 train에 '년'이라는 컬럼을 생성하고 그 값을 넣는 것이다. '월'도 같다.
