1. 논리 데이터베이스 설계
1) 데이터 베이스 설계
- 요구 조건 분석
- 구현: 목표 DBMS의 DDL(데이터 정의어)로 DB 생성, 트랜잭션 작성
- 개념적 설계 → 논리적 설계 → 물리적 설계
- 개념적 설계(정보 모델링, 개념화)
현실의 추상화
- 개념 스키마 모델링, 트랜잭션 모델링
- DBMS에 독립적인 ERD, 개념 스키마
- 논리적 설계(데이터 모델링)
목표 DBMS에 맞는 논리 스키마, 트랜잭션 인터페이스 설계
현실 자료 → 논리적 자료
- 데이터 타입(필드), 타입 간 관계로 표현되는 논리적 구조의 데이터로 모델화
- 개념적 설계는 개념 스키마 설계 단계 → 논리적 설계: 개념스키마 평가/정제
- 관계형 DB라면 테이블 설계 단계
- 물리적 설계(데이터 구조화)
목표 DBMS에 맞는 물리적 구조의 데이터로 변환
- 처리 성능을 위해 DB 파일의 저장 구조 및 액세스 경로 결정
- 데이터가 컴퓨터에 저장되는 방법 묘사: 저장 레코드의 양식, 순서, 접근 경로, 조회가 집중되는 레코드
- 고려 사항: 트랜잭션 처리량, 응답 시간, 디스크 용량, 저장 공간 효율화
2) 데이터 모델
현실 정보를 단순화, 추상화한 개념적 모형
- 구성 요소
- 개체: DB에 표현하려는 것, 현실 세계의 대상체
- 속성: 데이터의 가장 작은 논리적 단위. 데이터 필드, 항목
- 관계: 개체 간 관계, 속성 간 논리적 연결
- 표시할 요소
- 구조: 개체 타입들 간 관계, 데이터 구조 및 정적 성질을 표현
- 연산: 실제 데이터 처리 작업에 대한 명세, DB 조작 기본 도구
- 제약조건
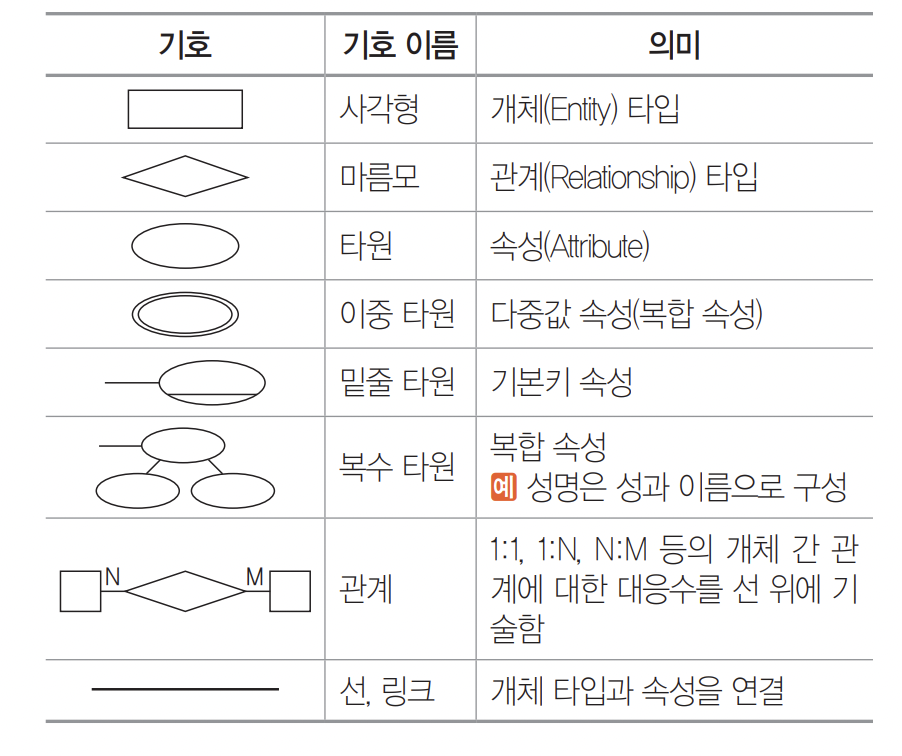
3) E-R 모델
피터 첸, 대표적인 개념적 데이터 모델
- 개체타입(Entity Type), 관계 타입(Relationship Type) 이용
- 데이터를 개체(Entity), 관계(Relationship), 속성(Attribute)으로 묘사
- DBMS 독립적
- ERD로 표현, 1:1, 1:N, N:M 등의 관계를 제한없이 표현 가능
- ERD
4) 관계형 데이터 모델
가장 널리 사용됨, 2차원 표(table)를 이용하여 데이터 관계 정의하는 DB 구조
- 구성한 테이블을 하나의 DB로 묶고, 속성/테이블 간 관계 설정
- PK, FK로 관계 표현
- 계층 모델, 망 모델을 단순화 시킨 모델
- 대표적인 언어: SQL
- 1:1, 1:N, N:M 등의 관계를 제한없이 표현 가능
- 관계형 DB의 Relation 구조
릴레이션 스키마: 테이블의 구조
릴레이션 인스턴스: 실제 값
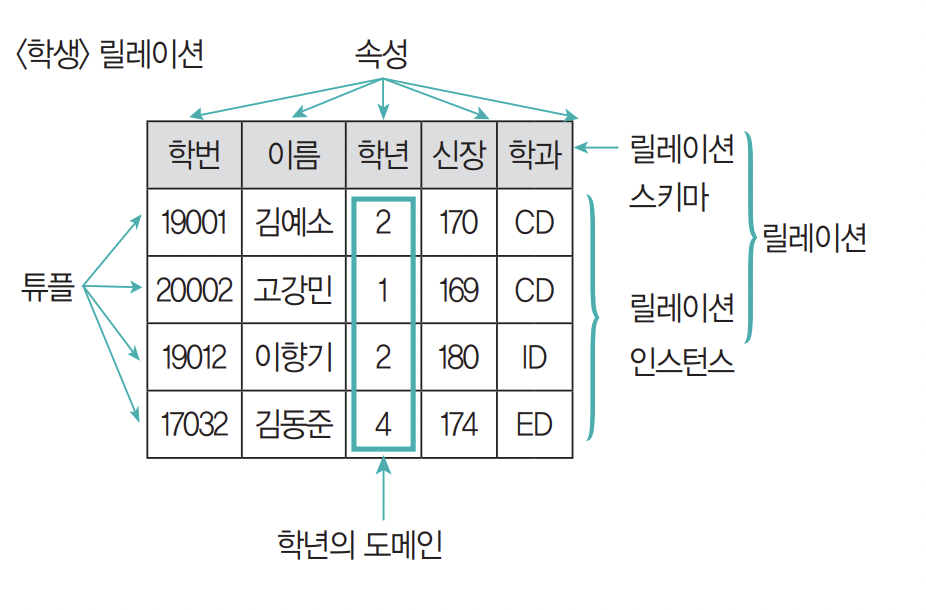
- 튜플: 각 행, 속성의 모임, (파일 구조)레코드와 같은 의미, 튜플의 수 == 카디널리티 / 기수 / 대응 수
- 속성: DB 구성의 가장 작은 논리적 단위, (파일 구조)데이터 항목/필드, 개체 특성 기술, 속성의 수 == 디그리, 차수
- 도메인: 하나의 attribute가 취할 수 있는 같은 타입의 원자값들의 집합, 실제 애트리뷰트 값의 합법 여부를 시스템이 검사하는 데에도 이용
- 릴레이션의 특징
- 한 릴레이션에는 똑같은 튜플 X
- 튜플 사이 순서 X (서로 순서 바꿔도 상관 없음)
- 튜플들의 삽입, 삭제로 인해 릴레이션은 시간에 따라 변함
- 속성 간 순서 X
- 속성의 명칭은 유니크, 값은 X
- 튜플 식별을 위해 속성의 부분집합을 key로 설정
- 속성 값은 원자값
- 키
조건 만족하는 튜플 찾거나 정렬할 때, 튜플 구분 기준이 되는 애트리뷰트
- 후보키: 기본키로 사용가능한 속성, 유일성과 최소성 만족해야
- 기본키: 후보키 중 선정된 주 키(main key), 중복 불가, 튜플 유니크 구분, not null
- 대체키: 보조키, 후보키 중 기본키 제외한 것들
- 슈퍼키: 속성들의 집합으로 구성된 키, 유일성O, 최소성X
- 외래키
5) 무결성
DB 저장 값과 현실 세계의 값이 일치하는 정확성
- 개체 무결성(Entity Integrity, 실체 무결성): 기본키는 not null, unique
- 도메인 무결성(영역 무결성): 속성 값은 도메인에 속한 값이어야함
- 참조 무결성(Referential): 외래키는 null이거나 참조 릴레이션의 PK → 참조 불가능한 FK 안됨
- 사용자 정의 무결성: 제약조건 만족
6) 관계 대수
RDB에서 원하는 정보 검색을 위한 절차적 언어
- 연산자, 규칙을 제공하는 언어 (피연산자 == 릴레이션, 결과도 릴레이션)
- 연산 순서 명시
- 순수 관계 연산자, 일반 집합 연산자로 이루어짐
- 순수 관계 연산자: SELECT, PROJECT, JOIN, DIVISION
- 일반 집합 연산자: UNION, INTERSECTION, DIFFERENCE, CARTESIAN PRODUCT
- 순수 관계 연산자
- Select
- 조건 만족 튜플의 부분집합으로 새로운 릴레이션 만듦
- 수평연산: 릴레이션의 행 추출 / 연산자 기호 == 시그마(σ)
- Project
- 속성 리스트에 제시된 값만 추출하여 새로운 릴레이션
- 중복 제거됨
- 수직연산: 릴레이션의 열 추출 / 연산자 기호 == 파이(π)
- Join
- 공통 속성으로 두 개의 릴레이션 하나로 / ▷◁
- Division
- X ⊃ Y인 R(X)와 S(Y)가 있을 때, R의 속성이 S의 속성값을 모두 가진 튜플에서 S가 가진 속성을 제외한 속성만을 구하는 연산
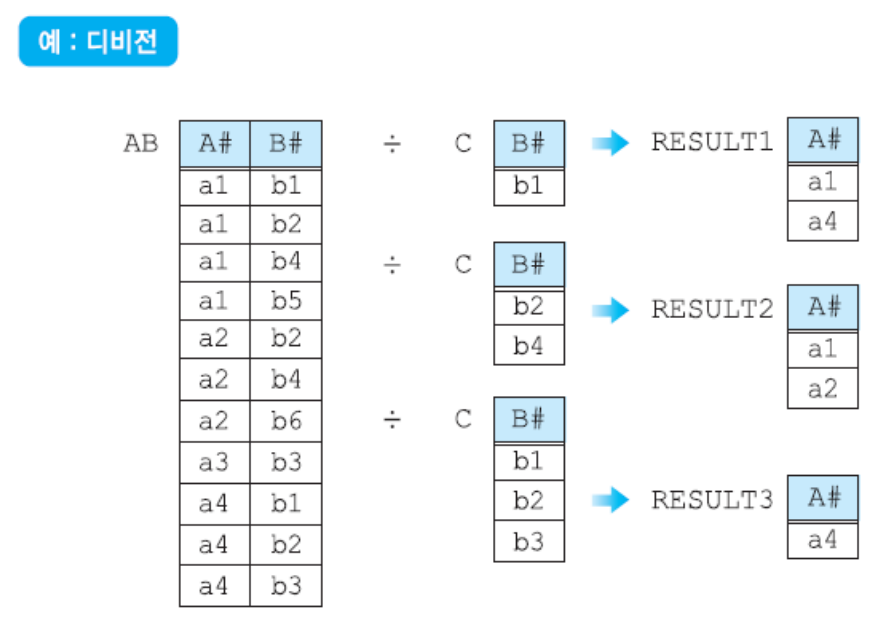
- X ⊃ Y인 R(X)와 S(Y)가 있을 때, R의 속성이 S의 속성값을 모두 가진 튜플에서 S가 가진 속성을 제외한 속성만을 구하는 연산
- 일반 집합 연산자
카디널리티(튜플 수), 디그리(속성 수)
- UNION(합집합): 중복 제거 → 합집합의 카디널리티 <= 두 릴레이션 카디널리티의 합
- INTERSECTION(교집합)
- DIFFERENCE
- CARTESIAN PRODUCT(교차곱): 튜플의 순서쌍
- 교차곱 디그리 == 두 릴레이션의 디그리의 합
- 카디널리티 == 두 릴레이션의 카디널리티 곱
7) 관계 해석
관계 데이터 모델의 제안자 코드(Codd)가 Predicate Calculus(술어 해석)에 기반을 두고 관계형 DB를 위해 제안
- 데이터의 연산을 표현, 계산 수식 사용
- 비절차적 특성: 원하는 정보가 무엇인지만 정의
- 튜플 관계 해석, 도메인 관계 해석이 있다
- 관계 해석, 관계 대수는 RDB 기능/능력 면에서 동등
- 관계 대수로 표현한 식은 관계 해석으로 표현할 수 있다
- 질의어로 표현
- 논리 기호
- ∃: 존재한다(하나라도 일치하는 튜플이 있음), 존재정량자
- ∈: t가 r에 속함( t ∈ r )
- ∀: 모든 튜플에 대하여(for all), 전칭정량자
- ∪: 합집합
8) 정규화
스키마 예쁘게 만들기
종속성 이론 활용
- 하나의 종속성이 하나의 릴레이션에 표현되게끔 분해
- 제 1, 2, 3, BCNF, 4, 5 정규형 → 높아질수록 제약조건 늘어남
- 논리적 설계 단계에서 수행
- 논리적 처리, 품질에 영향 ↑
- 데이터의 일관성, 정확성, 단순성, 비중복성, 안정성 보장
- 목적
- 안정성, 무결성 유지
- 어떤 릴레이션이든 DB 내에서 표현 가능하게
- 효과적인 검색 알고리즘 생성
- 데이터 중복 배제 → 이상현상 방지 및 저장공간 최소화
- 삽입 시 릴레이션 재구성 필요성 ↓
- 데이터 모형 단순화
- 속성의 배열상태 검증
- 개체 속성, 누락여부 확인
- 자료 검색, 추출의 효율성 추구
- 이상(Anomaly)의 개념, 종류
데이터 중복으로 릴레이션 조작 시 예기치 못한 오류 발생하는 것
→ 삽입 이상, 삭제 이상, 갱신 이상
- 정규화 과정
- 비정규 릴레이션
- 1NF: 도메인이 원자값
- 2NF: 부분적 함수 종속 제거
- 3NF: 이행적 함수 종속 제거
- BCNF: 결정자이면서 후보키가 아닌 것 제거
- 4NF: 다치 종속 제거
- 5NF: 조인 종속성 이용
도부이결다조 ㅋㅋ
> 이행적 종속, 함수적 종속
- 이행적 종속: A → B, B → C일 때, A → C인 관계
- 함수적 종속: 데이터들이 어떤 기준값에 의해 종속되는 것
- 수강 릴레이션이 (학번, 이름, 과목명)일 때, 학번이 결정되면 과목명에 상관없이 같은 이름이 대응됨
- 이 경우, 이름을 학번에 함수 종속적
- 반정규화
시스템 성능 향상, 개발/운영의 편의성을 위해 의도적으로 정규화 원칙 위배
- 시스템 성능 향상, 관리 효율성 증가 / 데이터 일관성, 정합성 저하 → 우선순위 정해야함
- 과도하면 오히려 성능 저하
- 방법
- 테이블 통합
- 매번 JOIN 시 하나로 합치기
- 테이블 분할
- 수평분할, 수직 분할
- 중복 테이블 추가
- 여러 테이블, 다른 서버 테이블 이용 시 중복
- 집계 테이블, 진행 테이블, 특정 부분만 포함하는 테이블
- 중복 속성 추가 등
- JOIN 조회 경로 단축 → 자주 사용하는 속성 추가 해버리기
- 테이블 통합
9) 시스템 카탈로그
시스템 데이터베이스
- DBMS의 사용자, 데이터 객체, 명세 등을 유지관리하는 시스템 테이블
- 카탈로그는 데이터사전에 저장
- 시스템 카탈로그에 저장된 정보 == 메타데이터
- SQL로 내용 검색 가능
- INSERT, DELETE, UPDATE 불가
- DB 시스템에 따라 다름
- DBMS가 스스로 생성하고 유지
- 카탈로그의 갱신: 사용자가 SQL로 변화를 주면 시스템이 자동으로 갱신
- Data Directory
- 데이터 사전에 수록된 데이터에 실제로 접근하는데 필요한 정보를 관리, 유지하는 시스템
- 시스템 카탈로그는 사용자와 시스템 모두 접근 가능 / 데이터 디렉터리는 시스템만 접근 가능
2. 물리 데이터베이스 설계
1) 트랜잭션
한꺼번에 모두 수행되어야 할 일련의 연산
- DB 병행 제어 및 회복 작업 시 처리되는 논리적 단위
- 사용자의 서비스 요구 시 시스템이 응답하기 위한 상태 변환 과정의 작업 단위
- 상태
- 활동(active): 트랜잭션 실행 중
- 실패(failed)
- 철회(aborted): 트랜잭션 비정상 종료 → 롤백 수행한 상태
- 부분 완료(partially committed): 커밋 직전
- 완료: 커밋까지 완료
- 특성
- 원자성: commit or rollback
- 일관성: commit 시 언제나 일관성있는 DB 상태 보장
- 독립성(격리성, 순차성): 한 트랜잭션이 다른 트랜잭션 사이에 끼어들 수 없음
- 영속성: 시스템이 고장나더라도 영구적 반영
2) CRUD 분석
테이블에 발생하는 트랜잭션 주기별 발생 횟수 파악, 연관된 테이블 분석 → 저장되는 데이터 양 유추 가능
3) 인덱스
레코드에 빠르게 접근하기 위해 <키 값, 포인터> 쌍으로 구성되는 데이터 구조
- 데이터의 물리적 구조와 밀접, 접근법 제공
- 빠름
- 삽입, 삭제가 빈번한 경우 인덱스 개수 최소화
- DDL로 CUD 가능
- 인덱스의 종류
- 트리 기반 인덱스: 상용 DBMS에서는 트리 기반 B+ 트리 인덱스 주로 사용
- 비트맵 인덱스: 컬럼 데이터를 bit 값인 0, 1로 변환하여 인덱스 키로 사용
- 함수 기반 인덱스: 컬럼에 특정 함수를 적용한 값 → B+트리, 비트맵 인덱스 생성 / 부하 발생 가능
- 비트맵 조인 인덱스: 조인된 객체로 인덱스 → 액세스 방법 상이
- 도메인 인덱스: custom, 확장된 인덱스
4) 뷰
접근 허용된 자료만 제한적으로 보여주는 가상 테이블
- 물리적 존재 X, 논리적 독립성 O
- 데이터 보정, 처리 과정 시험 등 임시 작업 용도 사용 가능
- 기본 테이블 PK를 포함시켜야 CUD 가능
- 장단점
장점
- 논리적 데이터 독립성
- 동일 데이터에 대해 동시 접근 가능
- 데이터 관리 간편
- 접근 제어를 통한 자동 보안
단점
- 독립적 인덱스 X
- 뷰 정의 변경 X
- 삽입, 삭제, 갱신에 제약
5) 파티션
대용량 테이블, 인덱스를 작은 논리적 단위인 파티션으로 나누는 것
- 중요한 몇 개 테이블에만 집중적으로 데이터 증가 → 분산 시키면 성능 저하 방지, 데이터 관리 쉬워짐
- 종류
- 범위 분할: 일별, 월별, 분기별
- 해시 분할: 해시 결과값에 따라 분할 → 범위분할 개선(데이터 고르게 분산)
- 특정 데이터가 어디에 있는지 판단 불가
- 고객번호, 주민번호 등 데이터가 고른 컬럼에 효과적
- 조합 분할: 범위 분할 후 해시 분할
- 목록 분할: 특정 열 값에 대한 목록 기준으로 분할
- 한국, 미국, 일본 → 미국 제외 목적으로 아시아 목록 만들기
- 라운드 로빈 분할: 레코드 균일 분배 → 순차적 분배, PK 필요 없음
6) 분산 데이터베이스
논리적 하나, 물리적으론 여러 시스템의 데이터베이스
- 구성 요소
- 분산 처리기: 지리적으로 분산된 컴퓨터 시스템
- 분산 데이터베이스
- 통신 네트워크: 분산 처리기를 통신망으로 연결, 하나의 시스템처럼 작동하게끔
- 목표
- 위치 투명성: DB 실제 위치 알 필요 없이 DB 논리적 명칭으로 액세스 가능
- 중복 투명성: 동일 데이터가 여러곳에 있더라도, 사용자는 마치 하나만 있는 것처럼 사용
- 병행 투명성: 다수 트랜잭션 동시 실현 시 결과 영향 받지 않음
- 장애 투명성: 트랜잭션, DBMS, 네트워크, 컴퓨터 장애에도 트랜잭션 정확히 처리
- 장단점
- 장점: 지역 자치성, 자료의 공유성, 분산 제어, 시스템 성능, 중앙 컴퓨터의 장애에 독립적, 효용성/융통성, 신뢰성/가용성, 점진적 용량 확장 용이
- 단점: DBMS 수행 기능 복잡, 설계 까다로움, 개발비용/처리비용/잠재적 오류 증가
7) 암호화
암호화, 복호화
- 개인키 암호 방식(비밀키)
동일한 키로 데이터 암호화/복호화
- 대칭 암호방식, 단일키 암호 방식
- 비밀키는 노출 X
- 전위 기법, 대체 기법, 대수 기법, 합성 기법(DES, LUCIFER)
- 공개키 암호 방식
다른 키로 데이터 암호화/복호화
- 공개키는 공개, 비밀키는 비밀
- 비대칭 암호화 방식, RSA
8) 접근통제 기술
- 임의 접근통제
- 사용자 신원에 따른 접근 권한
- 소유자가 권한 지정, 제어
- GRANT, REVOKE
- 강제 접근통제
- 주체, 객체 등급 비교로 접근 권한
- 시스템이 권한 지정
- DB 객체 별 보안 등급 부여, 사용자별 인가 등급 부여 가능
- 주체는 보안 등급 높은 객체 CRUD 불가, 같은 객체는 CRUD 가능, 낮은 객체는 읽기 가능
- 역할기반 접근통제
- 사용자 역할에 따라 접근 권한 부여
- 중앙 관리자가 접근 통제 권한 지정
- 위 두 개의 단점 보완, 다중 프로그래밍에 최적화된 방식
- 중앙 관리자가 권한을 부여하면, 사용자들은 역할에 해당하는 권한 사용 가능
- 강제 접근통제의 보안 모델
> 벨 라파듈라 모델
- 상하관계가 구분된 정보 보호
- 보안 취급자 등급 기준으로 읽/쓰 권한 제한
- 본인의 보안 레벨 이상의 문서 작성 가능, 이하 문서 읽기 가능
> 비바 무결성 모델
- 벨 라파듈라 모델 보완, 무결성을 보완하는 최초의 모델
- 비인가자의 데이터 변형 방지
> 클락-윌슨 무결성 모델
- 무결성 중심의 상업용 모델
- 사용자의 직접적인 객체 접근 불가, 프로그램에 의해 접근 가능
> 만리장성 모델
- 이해 충돌 관계의 객체간 정보 접근을 통제
9) 서버-저장장치 연결 방식
- DAS(Direct Attached Storage)
서버와 저장장치를 케이블로 직접 연결
(컴퓨터에 외장하드 연결하기)
- 서버에서 저장장치 관리
- 속도 빠르고 설치, 운영 쉬움
- 초기 구축, 유지보수 저렴
- 직접 연결이므로 다른 서버 접근, 공유 불가
- 확장성, 유연성 ↓
- 저장 데이터가 적고 공유 필요 없는 환경
- NAS(Network Attached Storage)
네트워크로 연결
- NAS Storage가 내장된 저장장치 관리
- Ethernet 스위치로 다른 서버에서 접근 가능
- DAS에 비해 확장성, 유연성 ↑
- 접속 증가 시 성능 저하
- SAN(Storage Area Network)
DAS(빠름) + NAS(파일 공유)
서버-저장장치 연결 네트워크 별도 구성
- 광 채널(FC) 스위치로 네트워크 구성 → 속도 빠름
- 저장장치 공유 → 여러 장비 단일화 가능
- 확장성, 유연성, 가용성 ↑
- 높은 트랜잭션 처리에 효과적
- 기존 시스템 장비 업그레이드 필요, 초기 설치 시 네트워크 구축 비용
3. SQL 응용
1) DDL(데이터 정의어)
SCHEMA, DOMAIN, TABLE, VIEW, INDEX 정의, 변경, 삭제
- 논리적/물리적 DB의 구조와 사상 정의
- DB 관리자, 설계자가 사용
- CREATE, ALTER, DROP
- CREATE TABLE
CREATE TABLE 테이블명
(속성명 데이터타입 [DEFAULT 기본값] [NOT NULL], ...)- PRIMARY KEY
- UNIQUE
- FOREIGN KEY ~ REFERENCES ~
- ON DELETE, ON UPDATE
- CONSTRAINT
- CHECK
- ALTER TABLE
ALTER TABLE 테이블명
ADD 속성명 타입
ALTER 속성명
DROP COLUMN 속성명ALTER TABLE student ADD grade VARCHAR(3);
ALTER TABLE student ALTER 학번 VARCHAR(10) NOT NULL;
- DROP
DROP SCHEMA, DOMAIN, TABLE, VIEW, INDEX, CONSTRAINT [CASCADE | RESTRICT]- CASCADE: 참조 개체 함께 제거
- RESTRICT: 참조 중이면 제거 취소
DROP TABLE 학생 CASCADE;
2) DML(데이터 조작어)
데이터 실질적 처리
SELECT, INSERT, DELETE, UPDATE
- INSERT INTO 테이블명 ~ VALUES
INSERT INTO 편집부원(이름, 생일, 주소, 기본급)
SELECT 이름, 생일, 주소 기본급
FROM 사원
WHERE 부서 = "편집";- DELETE FROM ~
cf) DROP
- UPDATE 테이블 ~ SET
- SELECT
- PREDICATE: ALL, DISTINCT(중복 시 첫번째 한 개만), DISTICNTROW(중복 제거, 튜플 전체 대상)
3) DCL(데이터 제어어)
보안, 무결성, 회복, 병행 수행 제어 등
COMMIT, ROLLBACK, GRANT, REVOKE, SAVEPOINT
- GRANT, REVOKE
> 사용자 등급
GRANT 사용자등급 TO 사용자_ID_리스트 [IDENTIFIED BY 암호];
-- DB, 테이블 생성 권한
GRANT RESOURCE TO NABI;
-- 검색 권한
GRANT CONNECT TO STAR;
REVOKE 사용자등급 FROM 사용자_ID_리스트;> 테이블 권한 부여 및 취소
GRANT 권한_리스트 ON 개체 TO 사용자 [WITH GRANT OPTION];
REVOKE [GRANT OPTION FOR] 권한 리스트 ON 개체 FROM 사용자 [CASCADE];- 권한 종류: ALL, SELECT, INSERT, DELETE, UPDATE, ALTER 등
- WITH GRANT OPTION: 권한 부여 권한 주기
- GRANT OPTION FOR: 권한 부여 권한 취소
- CASCADE: 연쇄적 권한 취소
-- 권한 부여 권한
GRANT ALL ON 고객 TO NABI WITH GRANT OPTION;
-- update 권한 부여 권한만 취소
REVOKE GRANT OPTION FOR UPDATE ON 고객 FROM STAR;- COMMIT
일관성을 위해 변경 내역 반영
auto commit
- ROLLBACK
4) 조건 연산자 / 우선순위
-
조건 연산자
- 비교 연산자: =, <>, >, < ...
- 논리 연산자: NOT, AND, OR
- LIKE 연산자: %(모든 문자), _(문자 하나), #(숫자 하나)
-
우선 순위: 산술 → 관계 → 논리
5) 하위 질의
조건절에 주어진 질의를 먼저 수행 → 그 검색 결과를 조건절 피연산자로 활용
SELECT 이름, 주소
FROM 사원
WHERE 이름 = (SELECT FROM 여가활동 WHERE 취미 = '나이트 댄스');
SELECT 부서
FROM 사원
WHERE EXISTS (SELECT 이름 FROM 여가활동 WHERE 여가활동.이름 = 사원.이름);6) SELECT 2: WINDOW, GROUP BY, HAVING
WINDOW 함수
- GROUP BY 절을 이용하지 않고 속성 값 집계
- PARTITION BY: 적용 범위
- ORDER BY: 정렬 기준
SELECT 부서, COUNT(*) AS 사원 수
FROM 상여금
WHERE 상여금 >= 100
GROUP BY 부서
HAVING COUNT(*) >= 2;- 그룹 함수
STDDEV(표준편차), VARIANC(분산)
7) 집합 연산자를 이용한 통합 질의
SELECT ~ FROM ~
UNION | UNION ALL | INTERSECT(교) | EXCEPT(차)
SELECT ~ FROM ~- SELECT 속성 개수, 타입 똑같아야 함
8) INNER JOIN
조건 없는 INNER JOIN 수행 시 CROSS JOIN과 동일 결과
- EQUI JOIN: 공통속성 기준 조인
- WHERE, NATURAL JOIN, JOIN ~ USING
- FROM 학생 NATURAL JOIN 학과
- FROM 학생 JOIN 학과 USING(학과코드)
4. SQL 활용
1) 트리거
CUD 이벤트마다 자동 수행하는 절차형 SQL
- DB에 저장, 데이터 변경/무결성 유지, 로그 목적
- DCL 사용 불가, DCL 포함된 프로지서/함수도 사용 불가
2) DBMS 접속 기술
프레임워크
- JDBC
Java DataBase Connectivity
자바 표준, 썬 마이크로시스템, 드라이버 필요
- ODBC
- Open DataBase Connectivity
- 표준 개방형 API, 언어 독립적, 마이크로소프트
- 드라이버는 필요 하지만 odbc 문장으로 sql 작성 시 드라이버 관리자가 DBMS 인터페이스에 맞게 연결해줌 → DBMS 종류 몰라도 됨
- MyBatis
- JDBC 단순화, SQL Mapping 기반 오픈소스 접속 프레임워크
- XML, Mapping, SQL 실행
- ORM
객체-DB 데이터 연결
- 가상의 객체지향 DB(코드, DB와 독립적) 만들어 코드와 데이터 연결
- SQL 직접 입력 X
3) 쿼리 성능 최적화
- APM(쿼리 성능 측정 도구)
- 옵티마이저가 수립한 실행 계획 검토 → SQL 코드, 인덱스 재구성
- RBO vs. CBO
규칙 기반 옵티마이저(Rule Based), 비용 기반 옵티마이저(Cost)
| 기준 | RBO | CBO |
|---|---|---|
| 최적화 기준 | 규칙 | 액세스 비용 |
| 성능 기준 | 개발자의 SQL 숙련도 | 옵티마이저의 예측 성능 |
| 특징 | 실행 계획 예측 쉬움 | 복잡 |
| 고려사항 | 개발자의 규칙 이해도, 효율성 | 비용 산출 공식의 정확성 |
5. 데이터 전환
1) 데이터 전환
기존 저장 데이터 추출 → 새 정보 시스템에서 운영하기 위해 변환, 적재
- ETL(Extraction, Transformation, Load)
- 데이터 이행(Data Migration), 데이터 이관
- 데이터 검증
데이터 전환 과정 검증
- 오류 데이터 정제
오류 관리 목록 분석 → 원천 데이터 정제, 전환 프로그램 수정
> 오류 데이터 분석 상태
- Open: 오류 보고 but 분석 X
- Assigned: 개발자에게 전달)
- Fixed: 오류 수정
- Closed: 수정 후 테스트 통과
- Deferred: 오류 수정 연기
- Classified: 관련자 확인했을 때 오류가 아니라고 확인됨
