1. 데이터 입출력 구현
1) 자료 구조
- 선형 구조: 배열, 선형 리스트(연속/연결 리스트), 스택, 큐, 데크
- 비선형 구조: 트리, 그래프
2) 선형 구조
- 선형 리스트
> 연속 리스트
- 연속되는 기억장소(≒배열)
- 기억장소 이용 효율 가장 좋음 (밀도 1)
- 데이터 중간 삽입 시 빈 공간 필요, 삽입/삭제 시 자료 이동 필요
> 연결 리스트
- 자료를 임의의 기억공간에 기억, 노드로 연결 → 삽입/삭제 용이
- 기억 공간이 연속적으로 놓여있지 않아도 저장 가능
- 순차 리스트 대비 기억 공간 효율 ↓
- 접근 속도 느림: 포인터 찾아야함
- 중간 노드 끊어지면 다음 노드 찾기 어려움
- 스택
- 한쪽 끝으로만 삽입, 삭제 (LIFO)
- 스택 full인 상태에서 데이터 삽입 → 오버플로
- 빈 스택에서 데이터 삭제 → 언더플로
> 응용 분야
함수 호출 순서 제어, 인터럽트 처리, 수식 계산, 컴파일러의 언어 번역, 복귀 주소 저장
- 큐
- 한 쪽에서 삽입, 다른 쪽에서 삭제 (FIFO)
- 시작과 끝을 표시하는 두 개의 포인터
3) 비선형 구조
- 그래프
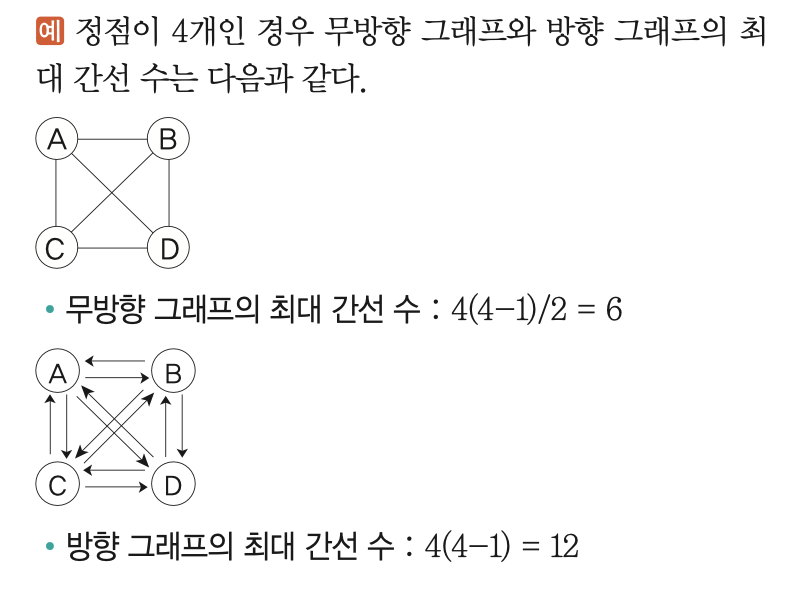
> 방향/무방향 그래프의 최대 간선 수
정점 n개
- 무방향 그래프: n(n-1)/2
- 방향 그래프: n(n-1)
- 트리
> 정의
정점(노드)과 선분(브랜치)를 이용하여 사이클을 이루지 않도록 구성한 특수한 그래프
> 관련 용어
- 노드: 자료 항목 + 가지(branch)
- 근 노드(Root Node): 최상위 노드
- 디그리(차수): 각 노드에서 뻗어나온 가지의 수
- 단말 노드(Terminal Node): 잎 노드(Leaf Node), 자식이 하나도 없는 노드, 디그리 0
- 자식 노드 / 부모 노드 / 형제 노드
- 트리의 디그리: 디그리 최대값
> 운행법
- Preorder 운행: Root → Left → Right
- Inorder 운행: Left → Root → Right
- Postorder 운행: Left → Right → Root
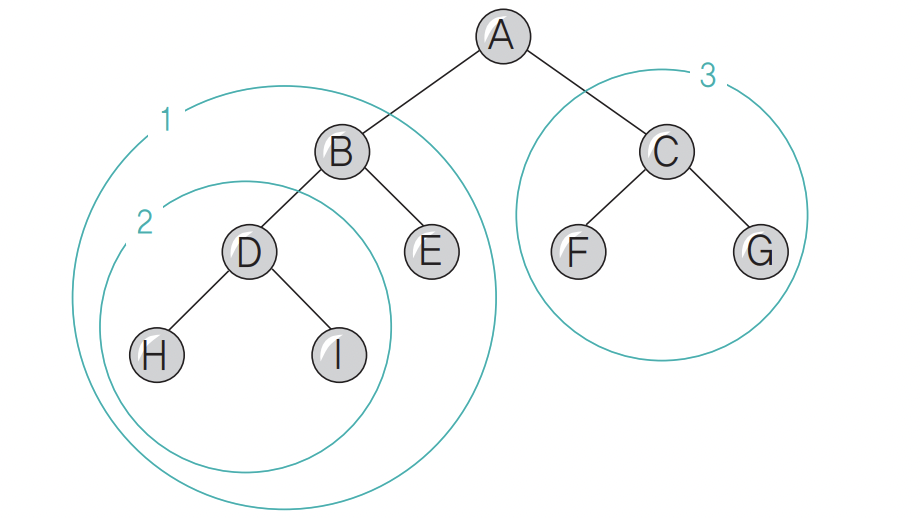
- Preorder
- A13 → AB2E3 → ABDHIE3 → ABDHIECFG
- Inorder
- 1A3 → 2BEA3 → HDIBEA3 → HDIBEAFCG
- Postorder
- 13A → 2EB3A → HIDEB3A → HIDEBFGCA
4) 수식의 표기법
- 표기법
- 전위 표기법(Prefix): +AB
- 중위 표기법(InFix): A+B
- 후위 표기법(PostFix): AB+
- Infix → PreFix, PostFix
X = A / B * (C + D) + E
- PreFix
=X+*/AB+CDE - PostFix
XAB/CD+*E+=
- PostFix → Infix
A B C - / D E F + * +
A / (B - C) + D * (E + F)
- PreFix → Infix
+ / A - B C * D + E F
A / (B - C) + D * (E + F)
5) 정렬
- 삽입 정렬
key 요소를 기존의 정렬된 자료 사이의 올바른 자리를 찾아 삽입
key 요소는 두번째 요소부터 시작
- 8 5 6 2 4
- 5 8 | 6 2 4
- 5 6 8 | 2 4
- 2 5 6 8 | 4
- 2 4 5 6 8
- 선택 정렬
해당 순서에 원소를 넣을 위치는 이미 정해져 있고, 어떤 원소를 넣을지 선택하는 알고리즘
최소값 찾기 → 맨 앞 값과 교체 → 계속 반복
- 8 5 6 2 4
- 2 8 5 6 4
- 2 4 8 5 6
- 2 4 5 8 6
- 2 4 5 6 8
- 버블 정렬
인접 요소끼리 비교해서 크면 한 칸씩 뒤로 보냄 (매번 비교 + 교환)
- 8 5 6 2 4
- 5 8 6 2 4 → 5 6 8 2 4 → 5 6 2 8 4 → 5 6 2 4 8
- 5 2 6 4 8 → 5 2 4 6 8
- 2 5 4 6 8 → 2 4 5 6 8
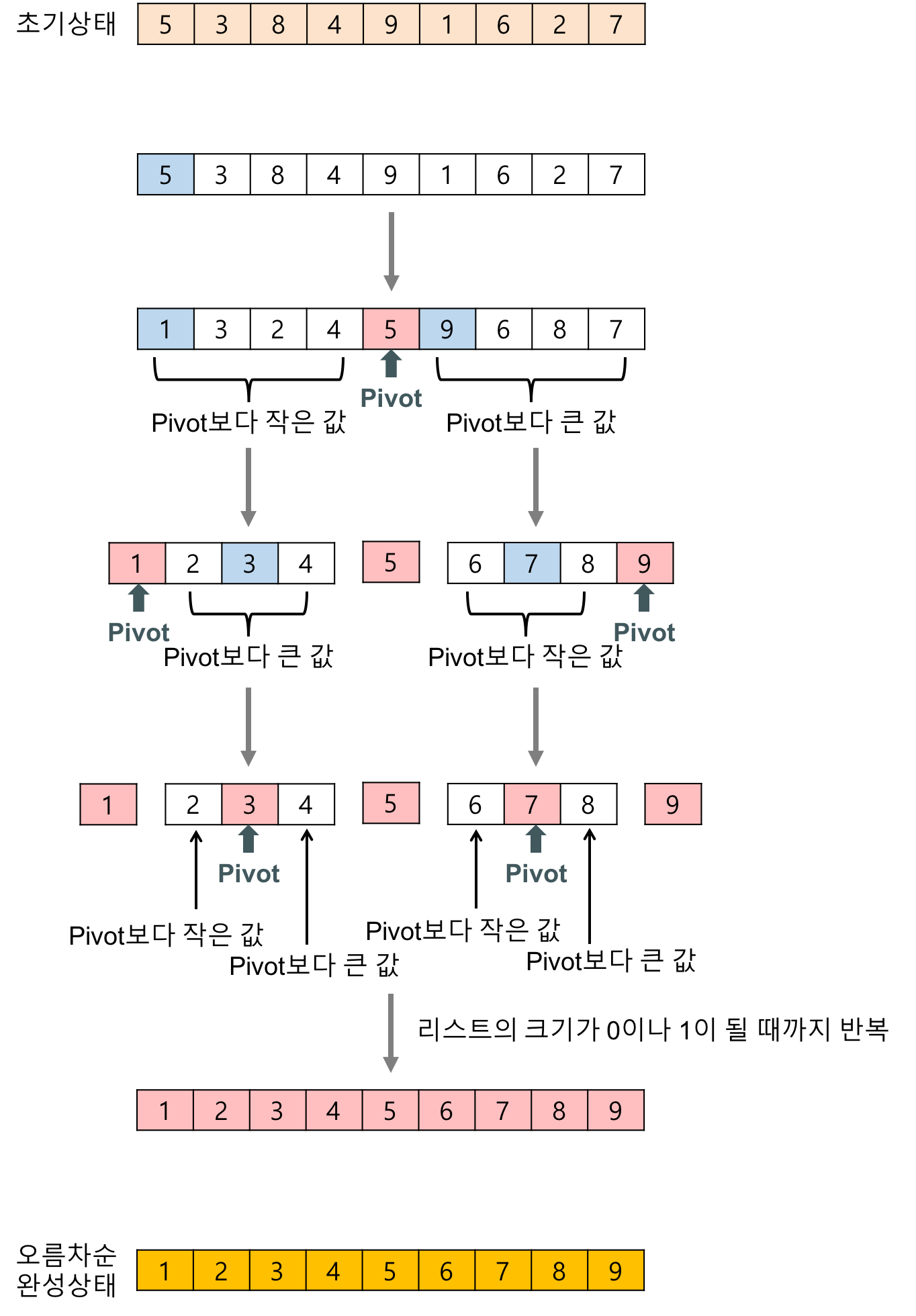
- 퀵 정렬
피벗 기준 작으면 왼쪽, 크면 오른 쪽으로
분할과 정복
평균: O(n log n) / 최악: O(n^2)
- 힙 정렬
완전 이진 트리(Complete Binary Tree) 사용
구성된 전이진 트리를 Heap Tree로 변환 후 정렬
O(n log n)
cf) 완전 이진 트리
부모 자식 간 특정 조건 만족, 자식 노드 최대2, 모든 레벨 노드 full
- 합병 정렬
이미 정렬된 두 개의 파일을 하나로 합병하는 정렬
O(n log n)
6) 이진 검색
전체 파일을 두 개의 서브 파일로 분리하며 key 레코드 검색하는 방식
- 순서화된 파일만 가능
- 대상 key 값을 중간 레코드 key 값과 비교하며 검색
- 비교 거듭 할때마다 검색 대상이 절반으로 줄어듦
- 중간 레코드 번호 = (first + last ) / 2
7) 해싱 함수
1) 제산법(Division)
- 홈 주소: 해시테이블의 크기보다 큰 수 중 가장 작은 소수(Prime, Q)로 나눈 나머지
- h(K) = K mod Q
2) 제곱법(Mid-Square)
- 홈 주소: K^2의 중간 부분 값
3) 폴딩법(Folding)
- 홈 주소: K를 여러 부분으로 나눈 후 각 부분의 합이나 XOR(배타적 논리합)한 값
4) 기수 변환법(Radix)
- 키 숫자를 다른 진수로 변환 후 주소 범위에 맞게 조정
5) 대수적 코딩법
- 홈 주소: 키 값 각 자리의 비트수를 다항식의 계수로 간주, 이를 해시표의 크기로 정의된 다항식으로 나누어 얻은 나머지 다항식의 계수
6) 숫자 분석법
- 키 값 숫자의 분포 분석 → 비교적 고른 자리를 택해서 홈주소
7) 무작위법: 난수
8) DB
- DBMS
DB 관리, 요구에 따른 정보 생성 SW
필수 기능
- 정의 기능: 데이터 타입, 구조, 제약 조건 등을 명시 가능
- 조작 기능: CRUD 인터페이스 제공
- 제어 기능: CUD의 정확한 수행으로 데이터의 무결성 유지
장점
- 데이터의 논리적, 물리적 독립성 보장
- 중복 피해서 기억 공간 절약
- 저장된 데이터 공동 이용, 데이터 표준화, 통합 관리, 최신성, 실시간 처리 가능
- 데이터의 일관성/무결성, 보안 유지
단점
- DB 전문가 부족
- 전산화 비용 증가
- 과부하(오버헤드) 발생 가능
- 백업, 리커버리 어려움
- 시스템 복잡
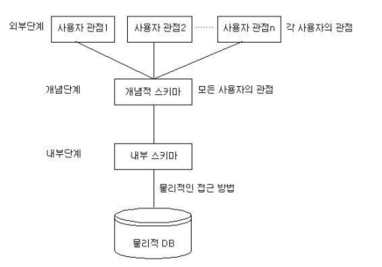
- 스키마
DB 구조, 제약 조건에 관한 명세를 기술한 메타데이터의 집합
속성, 개체, 관계, 제약조건 등
분류
- 외부 스키마
- 사용자, 개발자가 필요로하는 DB 구조
- 개념 스키마
- DB 전체적인 논리적 구조
- 모든 응용 프로그램 등이 필요로 하는 데이터를 종합한 조직 전체의 DB → 하나만 존재
- 내부 스키마
- 물리적 저장장치 입장에서 본 DB 구조
- 실제로 DB에 저장될 레코드의 형식 정의, 저장 데이터의 표현 방법, 내부 레코드의 물리적 순서 등
- 절차형 SQL의 테스트와 디버깅
- 디버깅으로 기능의 적합성 여부를 검증, 실행을 통해 결과를 확인하는 테스트 과정
- 목적: 테스트를 통해 오류를 발견한 후 디버깅을 통해 오류 발생 소스 코드를 추적하며 수정
2. 통합 구현
1) 단위 모듈(Unit Module)
SW 구현에 필요한 여러 동작 중 한 가지 동작을 수행하는 기능을 모듈로 구현한 것
- 단위 기능: 단위 모듈로 구현되는 하나의 기능
- 사용자, 다른 모듈로부터 값을 전달받아 시작되는 작은 프로그램을 의미하기도 함
- 두 개의 단위모듈을 합쳐서 두 개의 기능 구현 가능
- 구성요소: 처리문, 명령문, 데이터 구조 등
- 독립적인 컴파일, 다른 모듈에 호출/삽입 가능
- 단위기능 명세서 작성 후 입출력 기능과 알고리즘 구현
2) IPC
Inter-Process Communication
모듈 간 통신 방식을 구현하기 위해 사용되는 대표적인 프로그래밍 인터페이스 집합
복수의 프로세스를 수행하며 이뤄지는 프로세스 간 통신까지 구현 가능
- 대표 메소드
- Shared Memory
- 다수 프로세스가 공유 메모리로 통신
- Socket
- 네트워크 소켓
- Semaphores
- 공유 자원에 대한 접근 제어를 통해 통신
- Pipes & Named Pipes
- 파이프(선입선출)라는 메모리를 공유하며 통신, 프로세스 간 파이프 동시 접근 불가
- Message Queueing
- 메시지가 발생하면 이를 전달하며 통신
3) 단위 모듈 테스트
단위 기능을 구현하는 모듈이 정해진 기능을 정확히 수행하는지
Unit Test
- 화이트박스 테스트, 블랙박스 테스트 기법 사용
- 모듈 단독 실행 환경과 데이터가 필요
- 기능 단위 디버깅 용이 / 시스템 수준의 오류는 못 잡음
4) 테스트 케이스
입력값, 실행조건, 기대결과 등의 항목에 대한 명세서
- 구성요소 (ISO/IEC/IEEE 29119-3 표준)
- 식별자
- 테스트 항목: 테스트 대상(모듈, 기능)
- 입력 명세: 입력값, 조건
- 출력 명세
- 환경 설정: 필요한 HW, SW
- 특수 절차 요구
- 의존성 기술
5) 통합 개발 환경(IDE)
코딩, 디버그, 컴파일, 배포 등을 제공하는 SW 개발환경
6) 빌드 도구
-
소스 코드 → 제품 소프트웨어
-
전처리, 컴파일 등
-
Ant: 아파치, 자바 공식 빌드 도구
-
Maven: 아파치, ant 대안
-
Gradle: ant, maven 보완
3. 소프트웨어 패키징
1) 소프트웨어 패키징
모듈별로 생성한 실행 파일을 묶어 배포용 설치 파일 만들기
- 사용자 중심 진행
- 소스코드는 모듈화하여 패키징
- 고려사항
- 사용자 시스템 환경 정의 (OS, CPU, 메모리 등)
- UI는 시각적인 자료와 함께 제공
- 하드웨어와 함께 관리되도록 Managed Service 형태로 제공
- 내부 콘텐츠 암호화 및 보안
- 다른 콘텐츠 및 단말기간 DRM 연동 고려
- 사용자 편의성을 위한 복잡성 및 비효율성 문제 고려
- 소프트웨어 종류에 적합한 암호화 알고리즘 적용
2) 릴리즈 노트
개발 과정의 릴리즈 정보를 최종 사용자와 공유하는 문서
- 테스트 진행 방법, 결과, 소프트웨어 사양 확인 가능
- 전체 기능, 서비스 내용, 개선 사항 공유
- 버전 관리, 릴리즈 정보 관리 가능
- 초기 배포 및 출시 후 추가 배포 시에 제공
- 초기 버전 작성 시 고려사항
- 현재 시제로 작성
- 신규 소스, 빌드, 변경/개선된 이력 작성
- 머릿말, 개요, 목적, 문제 요약, 재현 항목, 수정/개선 내용, 사용자 영향도, SW 지원 영향도, 노트, 면책 조항, 연락처
3) 디지털 저작권 관리(DRM)
- 원본 콘텐츠가 아날로그인 경우, 디지털로 변환 후 패키저로 DRM 패키징
- 콘텐츠 크기가 작은 경우(음원, 문서) 요청 시점에 실시간 패키징, 큰 경우 패키징 후 배포
- 패키징 수행 시 암호화된 저작권자의 전자서명 포함, 라이선스 정보가 클리어링 하우스에 등록됨
- 콘텐츠 사용 시 클리어링 하우스에 등록된 라이선스 정보로 사용자 인증, 권한 여부 확인 필요
- 종량제 방식, 클리어링 하우스로 실제 사용량 측정 후 요금 부과
- DRM 구성 요소
- 클리어링 하우스
- 저작권 사용 권한, 라이선스, 암호화된 키, 사용량에 따른 결제 관리 수행
- 콘텐츠 제공자: 저작권자
- 패키저
- 콘텐츠를 메타데이터와 함께 배포 가능한 형태로 묶어 암호화하는 프로그램
- 콘텐츠 분배자
- 암호화된 콘텐츠를 유통하는
- 콘텐츠 소비자
- DRM 컨트롤러
- 배포된 콘텐츠의 이용권한 통제 프로그램
- 보안 컨테이너
- 콘텐츠 원본을 안전하게 유통하기 위한 전자적 보안 장치
- DRM 기술 요소
- 암호화 (+전자 서명)
- 키 관리
- 암호화 파일 생성(Packager)
- 식별 기술
- 저작권 표현
- 정책 관리
- 크랙 방지
- 인증
4) 소프트웨어 매뉴얼
- 설치 매뉴얼
- 사용자 기준 작성
- 설치 a-z 빠짐없이 순서대로 작성
- 오류 메시지, 예외 상황 별도 분류 설명
- 목차/개요, 서문, 기본 사항 포함
- 기능 식별 → UI 분류 → 설치/백업 파일 → Uninstall 절차 확인 → 이상 케이스 확인 → 최종 매뉴얼 적용
> 기본 사항
- 소프트웨어 개요
- 주요 기능 및 UI, 그림으로 설명
- 설치 관련 파일
- 설치에 필요한 파일, exe, ini, log 등 파일 설명
- 설치 아이콘
- 프로그램 삭제
- 관련 추가 정보
- 사용자 매뉴얼
사용 과정에서 필요한 내용에 대한 문서
- 오류 패치, 기능 업그레이드 등을 위해 매뉴얼 버전 관리
- 개별 동작 가능한 컴포넌트 단위로작성
- 컴포넌트 명세서, 구현 설계서 토대로 작성
- 목차/개요, 서문, 기본사항 등 포함
- 작성 지침 정의 → 사용자 매뉴얼 구성 요소 정의 → 구성 요소별 내용 작성 → 사용자 매뉴얼 검토
5) 형상 관리
Git, CVS, Subversion 등
- 중요성
- SW 변경사항 추적, 통제
- 무절제한 변경 방지
- 버그, 수정사항 추적
- 진행 정도 확인 기준으로 사용 가능
- 배포본 관리 효율
- 여러 개발자 동시 개발 가능
- 기능
- 형상 식별
- 형상관리 대상에 이름, 관리번호를 부여하고 계층(Tree) 구조로 구분 → 수정, 추적 용이하도록
- 버전 제어
- 다른 버전의 형상 항목 관리
- 형상 통제(변경 관리)
- 변경 요구 검토
- 형상 감사
- 형상 기록(상태 보고)
- 소프트웨어 버전 등록 관련 주요 기능
- 저장소(Repository): 최신 버전 파일, 변경 정보 저장소
- 가져오기: 빈 저장소에 파일 복사
- 체크아웃: 저장소에서 파일 받아옴
- 체크인: 소스 수정 후 저장소 갱신
- 커밋: 충돌을 알리고 수정 후 갱신 완료
- 동기화
- 방식에 따른 분류
> 공유 폴더 방식
버전 관리 자료를 로컬 컴퓨터의 공유폴더에 저장
SCSS, RCS, PVCS, QVCS
> 클라이언트/서버 방식
중앙시스템(서버)에 저장
CVS, SVN(Subversion), CVSNT, Clear Case, CMVC, Perforce
> 분산 저장소 방식
하나의 원격 저장소와 분산된 개발자 PC의 로컬 저장소에 함께 저장
- 개발자가 로컬 저장소에서 우선 반영(버전 관리)한 뒤, 이걸 다시 원격 저장소에 반영
- 원격 저장소에 문제가 생겨도 로컬 저장소 자료로 작업 가능
Git, GNU arch, DCVS, Bazaar, Mecurial, TeamWare, BitKepper, Plastic SCM
- 대표적 기술
> Subversion(SVN)
CVS 개선, 아파치
- 클라이언트/서버 구조, 서버에는 최신 파일
- 서버 자료를 클라이언트로 복사해서 작업 후 변경 내용을 서버에 반영
- 모든 개발 작업은 trunk 디렉토리에서 수행
- 추가 개발 작업은 branches 디렉토리 안에 별도의 디렉토리를 만들어 작업을 완료 후 trunk에 머지
- 커밋 시 리비전 1씩 증가
- 서버는 주로 유닉스, 클라이언트는 상관 없음
- 오픈 소스, 무료
- CVS의 단점이었던 파일, 디렉토리명 변경, 이동 등이 가능
> Git
리누스 토발즈
- 분산 버전 관리 시스템. 로컬/원격 저장소
- 지역 저장소: 개발자들이 실제 개발을 진행, 버전관리 수행
- 원격 저장소: 협업을 위해 버전 공동 관리, 내 작업 반영하거나 다른 개발자의 작업 가져오기
- 버전 관리가 로컬에서 진행되므로 버전관리 신속, 원격/네트워크 문제 시 작업 가능
- 브랜치를 이용하면 기존 코드에 영향 없이 다양한 테스팅 가능
- 스냅샷: 파일의 변화 → 이전 스냅샷의 포인터를 가지므로 버전 흐름 파악 가능
6) 빌드 자동화 도구
소스 코드를 컴파일한 후 여러개의 모듈을 묶어 실행 파일로 만드는 과정
→ 빌드, 테스트, 배포를 자동화 하는 도구
- 지속적인 통합 개발환경
- 한 작업 마무리 시 모듈 단위로 개발된 코드를 지속적으로 통합
- 빌드 자동화 도구 유용
Ant, Make, Maven, Gradle, Jenkins
- Jenkins
자바 기반 오픈소스
- 서블릿 컨테이너에서 실행되는 서버 기반 도구
- 형상관리 도구와 연동 가능, Web UI 제공
- 분산 빌드, 테스트 가능
- Gradle
Groovy 기반 오픈소스
- Groovy로 만든 DSL(Domain Specific Language)를 스크립트 언어로 사용
- 실행 명령을 모아 태스크로 만든 후, 태스크 단위로 실행
- 빌드 캐시: 태스크 재사용 / 다른 시스템의 태스크 공유
4. 애플리케이션 테스트
1) 애플리케이션 테스트
잠재 결함을 찾아내는 일련의 행위
→ 요구사항 만족 여부 확인, 기능 수행 검증 (명세서에 맞는지)
2) 테스트 관련 용어
- 결함 집중(Defect Clustering): 대부분의 결함이 소수의 특정 모듈에 집중해서 발생
- 파레토 법칙: 80%의 오류는 20% 모듈에서 발견 → 20% 모듈을 집중적으로 테스트하자
- 살충제 패러독스: 살충제 내성
- 오류 부재의 궤변: 결함이 없어도 요구사항 불만족 시 품질이 낮은 것
3) 실행 여부에 따른 분류
- 정적 테스트
- 프로그램 실행 없이 명세서, 소스 코드를 대상으로
- 개발 초기 결함 발견 가능 → 비용 ↓
- ex) 워크스루, 인스펙션, 코드 검사
- 동적 테스트
- 실행해서 하는 테스트
- 소프트웨어 개발 모든 단계에서 수행 가능
- ex) 블랙박스, 화이트박스
4) 테스트 기반에 따른 분류
- 명세 기반 테스트: 명세 빠진 것 없는지
- ex) 동등 분할, 경계 값 분석
- 구조 기반 테스트: SW 내부 논리 흐름에 따라 테스트 케이스 작성 후 확인
- ex) 구문/결정/조건 기반
- 경험 기반 테스트: 테스터의 경험 기반, 명세/시간이 충분하지 않을 때
- ex) 에러 추정, 체크리스트, 탐색적 테스팅
5) 시각에 따른 분류
- 검증 테스트
- 개발자의 시각에서, 명세서 일치 여부
- 확인 테스트
- 사용자의 시각에서, 요구한대로 완성됐는지
6) 목적에 따른 분류
- 회복 테스트: 시스템에 결함을 주어 실패 유도 → 올바르게 복구되는지
- 안전 테스트: 시스템 보호 도구가 침입에 대응을 잘 하는지
- 강도 테스트: 과부하 확인
- 성능 테스트
- 구조 테스트: SW 내부 논리, 소스 코드의 복잡도
- 회귀 테스트: 변경/수정 사항의 결함
- 병행 테스트: 변경된 SW와 기존 SW에 동일한 인풋 → 결과 비교
7) 화이트박스 테스트
원시 코드의 논리적인 경로로 테스트 케이스 설계
- 모듈 내부 작동 관찰
- 원시 코드(모듈)의 모든 문장을 한 번 이상 실행
- 프로그램 제어 구조에 따라 선택, 반복 등 분기점 부분을 수행 → 논리적 경로 제어
- 종류
- 기초 경로 검사
- 가장 대표적
- 설계자가 논리적 복잡성 측정할 수 있게 해줌
- 결과는 실행 경로의 기초를 정의하는 지침으로 사용
- 제어 구조 검사
- 조건 검사: 논리적 조건
- 루프 검사: 반복 구조
- 데이터 흐름 검사: 변수
- 검증 기준
- 문장 검증 기준: 모든 구문이 한 번 이상 수행되도록
- 분기 검증 기준: 결정 검증 기준, 모든 조건문 true/false
- 조건 검증 기준: 조건문에 포함된 개별 조건식의 결과 true/false
- 분기/조건 기준: 분기 + 조건
8) 블랙박스 테스트
각 기능의 완전한 작동을 입증, 기능 테스트
- 프로그램 구조 고려 X → 테스트 케이스는 모듈 요구나 명세를 기초로 결정
- 소프트웨어 인터페이스에서 실시
- 부정확/누락된 기능, 인터페이스 오류, 자료 구조나 외부 DB 접근에 따른 오류, 행위/성능 오류, 초기화 종료 오류 등을 발견하기 위해 사용
- 테스트 과정의 후반부
- 종류
- 동치 분할 검사
- 동치 클래스 분해, 동등 분할 기법
- 입력 자료에 초점을 맞춰 테스트 케이스를 만들어 검사
- 타당한 입력, 타당하지 않은 입력 자료의 개수를 균등하게 배분
- 경계값 분석
- 입력자료에만 치중한 동치 분할 기법을 보완
- 입력 조건의 중간값보다 경계값에서 오류가 발생할 확률이 높음 → 경계값을 테스트 케이스로 선정
- 원인-효과 그래프 검사
- 입출력 상황 분석 → 효용성이 높은 테스트케이스를 선정하여 검사
- 오류 예측 검사
- 과거의 경험이나 확인자의 감각으로 테스트
- 보충적 검사 기법
- 데이터 확인 검사
- 비교 검사
- 여러 버전의 프로그램에 동일한 테스트 자료를 제공 → 동일 결과 출력되는지
9) 개발 단계에 따른 애플리케이션 테스트
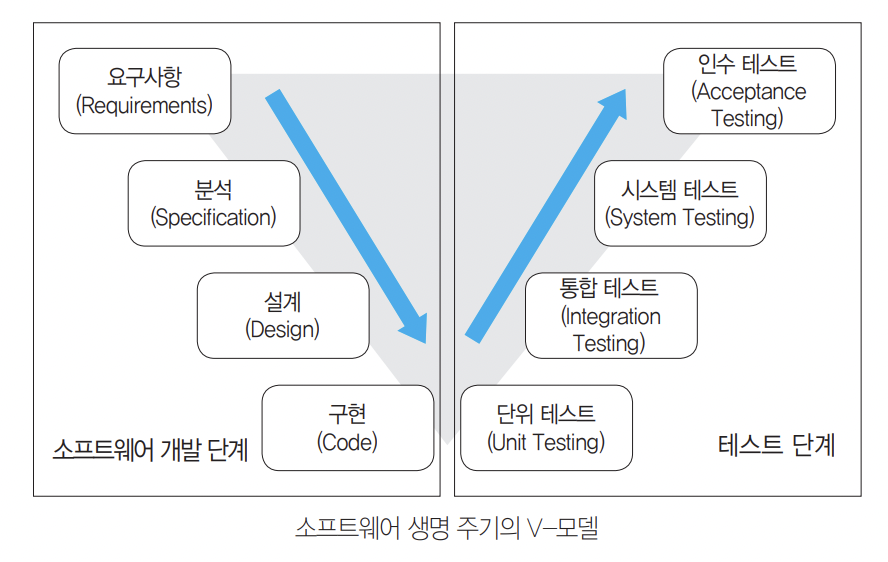
- 단위 테스트(Unit Test)
코딩 직후 모듈, 컴포넌트 초점 테스트
- 인터페이스, 외부적 I/O, 자료 구조, 독립적 기초 경로, 오류 처리 경로, 경계 조건 검사
- 사용자의 요구사항을 기반으로 한 기능성 테스트를 우선적으로
- (주로)구조 기반 테스트 cf) 명세 기반 테스트
- 발견 가능한 오류: 알고리즘 오류, 탈출구 없는 반복문, 틀린 수식
- 통합 테스트(Integration Test)
단위 테스트가 완료된 모듈을 결합, 하나의 시스템으로 완성시키는 테스트
- 비점진적 통합 방식
- 단계적 통합 절차 없이 모두 결합된 프로그램 전체를 테스트
- 빅뱅 통합 테스트 방식
- 소규모 SW, 단시간
- 오류 발견 및 장애 위치 파악, 수정이 어려움
- 점진적 통합 방식
- 모듈 단위로 단계적으로 통합하면서 테스트
- 하향식, 상향식, 혼합식
- 오류 수정 용이, 인터페이스 연관 오류 테스트 가능성 높음
> 하향식 통합 테스트
상위 모듈에서 하위 모듈로 통합
- 깊이 우선 통합법, 넓이 우선 통합법
- 테스트 초기부터 사용자에게 시스템 구조를 보여줄 수 있다
- 상위 모듈에서 테스트 케이스 사용하기 어려움
> 상향식 통합 테스트
하위 → 상위 모듈
- 스텁은 필요하지 않지만, 한 주요 제어모듈과 관련된 종속 모듈의 그룹인 클러스터가 필요
> 테스트 드라이버와 테스트 스텁
- 드라이버
- 하위 모듈 호출 도구 / 매개 변수를 전달하고 테스트 결과 도출
- 상위 모듈 없이 하위 모듈이 있는 경우
- 상향식 테스트
- 스텁
- 제어 모듈이 호출하는 타 모듈의 기능을 단순히 수행 / 일시적 조건만 가지는 테스트용 모듈
- 상위 모듈은 있는데 하위 모듈이 없는 경우
- 하향식 테스트
- 공통점과 차이점
- 공통점: 소프트웨어 개발, 테스트 병행 시 이용
- 차이점
- 드라이버
- 존재하는 하위 모듈과 존재하지 않는 상위 모듈 간의 인터페이스 역할
- 개발 완료 시 드라이버는 본래 모듈로 교체
- 스텁
- 가짜 모듈, 임시 모듈
- 시험용 모듈이기 때문에 드라이버보다 작성 쉬움
- 드라이버
- 시스템 테스트
개발된 SW가 해당 컴퓨터에서 완벽히 수행되는가
- 실제 사용 환경과 유사한 환경 만들어야 함
- 기능적/비기능적 요구사항을 모두 만족하는지
- 인수 테스트
사용자의 요구사항 충족 여부
-
사용자가 직접 테스트
-
문제가 없으면 사용자는 SW를 인수 → 프로젝트 종료
-
알파 테스트: 개발자 앞에서, 통제된 환경, 오류/문제점을 사용자와 개발자가 함께 확인
-
베타 테스트: 선정된 유저가 여러 사용자 앞에서. 필드 테스팅. 제어되지 않은 환경
10) 회귀 테스팅
테스트된 프로그램의 테스팅을 반복
통합 테스트로 인해 변경된 모듈이나 컴포넌트의 새로운 오류를 확인
- 수정 부분 때문에 새로운 오류를 발생하지 않음을 보증하기 위해
- 변경 부분을 테스트할 수 있는 케이스만 선정하여 수행
11) 애플리케이션 테스트 프로세스
순서
- 테스트 계획: 명세서 등을 기반으로 테스트 목표, 대상, 범위 결정
- 테스트 분석 및 디자인
- 테스트 케이스 및 시나리오 작성
- 테스트 수행
- 테스트 결과 평가 및 리포팅
- 결함 추적 관리
12) 테스트 케이스
요구사항 준수 여부 확인을 위해 설계된 테스트 항목 명세서
입력값, 실행 조건, 기대 결과
→ 명세 기반 테스트의 설계 산출물
- 테스트 오류 방지, 인력/시간 ↓
- 테스트 목표, 방법 설정 후 작성
- 시스템 설계 단계에서 작성하는 것이 이상적
- 테스트 시나리오
테스트 케이스 적용 순서에 따라 묶음 집합
테스트 케이스를 적용하는 구체적인 절차 명세
→ 절차, 조건, 입력 데이터 등
- 테스트 오라클
테스트 결과가 올바른지 판단하기 위해 정의된 참 값을 대입하여 비교
> 종류
- 참 오라클: 모든 테스트 케이스의 기대값 제공, 발생된 모든 오류 검출 가능
- 샘플링 오라클: 특정한 몇몇 케이스만
- 추정 오라클: 샘플링 오라클 개선, 몇 개는 결과 제공, 나머지는 추정
- 일관성 검사 오라클: 앱 변동 시 전후 결과값 동일한지 확인
13) 테스트 자동화 도구
사람이 하던 걸 스크립트 형태의 자동화 도구 시킴
- 유형
- 정적 분석 도구: 프로그램 실행 X, 소스 코드의 코딩 표준, 스타일, 복잡도 등을 발견
- 테스트 케이스 생성 도구
- 자료 흐름도: 자료 원시 프로그램 입력 → 파싱 → 자료 흐름도 작성
- 기능 테스트: 기능 구동의 모든 가능한 상태를 파악하여 입력 작성
- 입력 도메인 분석: 코드 내부 말고 입력 변수 도메인 분석해서 테스트 데이터 만듦
- 랜덤 테스트: 입력 값 무작위 추출
- 테스트 실행 도구: 데이터/수행방법 등이 포함된 스크립트
- 데이터 주도 접근 방식: 스프레드 시트에 데이터 저장
- 키워드 주도 접근 방식: 스프레드 시트에 동작 키워드와 테스트 데이터 저장
- 성능 테스트 도구
- 테스트 통제 도구
- 테스트 계획, 관리, 수행, 결함 관리 도구
- ex) 형상 관리 도구, 결함/추적 관리 도구
- 테스트 하네스 도구
- 컴포넌트, 모듈 테스트 환경의 한 부분 → 테스트를 위한 코드, 데이터
- 테스트 실행 환경 시뮬레이션 후 테스트
- 테스트 하네스의 구성 요소
- 테스트 드라이버: 하위 모듈 호출, 매개변수 전달, 결과 도출
- 테스트 스텁: 제어 모듈이 호출하는 타 모듈의 기능만 단순히 수행, 일시적으로 필요한 조건만 충족
- 테스트 슈트: 테스트 케이스의 집합
- 테스트 케이스: 입력값, 조건, 기대값
- 테스트 스크립트: 자동화된 테스트 실행 절차에 대한 명세서
- 목 오브젝트: 조건 입력하면 그 상황에 맞는 행위 수행
14) 결함
오류, 작동 실패 등 이상 동작
→ 기대값/결과 간 차이나 업무 내용과의 불일치도 모두 결함에 해당
15) 애플리케이션 성능 분석
요구한 기능을 최소한의 자원으로 최대한 많이, 신속하게 처리하는 정도
- 성능 측정 지표
- 처리량
- 응답 시간: 요청~응답
- 경과 시간: 작업 의뢰~처리 완료
- 자원 사용률
- 빅 오 표기법(Big-O Notation)
알고리즘 실행시간 최악일 때를 표기하는 방법
cf) 오메가 표기법(신뢰성 ↓), 세타 표기법(평가 까다로움)
- O(1)
- 입력값(n)에 독립적으로 문제 해결에 하나의 단계만 거침
- 스택의 삽입(push), 삭제(pop)
- O(log n)
- 필요 단계가 입력값, 조건에 의해 감소
- 이진트리, 이진 검색
- O(n)
- 입력값과 1:1 관계
- for문
- O(n log n)
- nlogn번만큼 수행
- 힙정렬, 합병 정렬
- O(n^2)
- 삽입 정렬, 쉘 정렬, 선택 정렬, 버블 정렬, 퀵 정렬
- O(2^n)
- 피보나치 수열
- 순환 복잡도
한 프로그램의 논리적 복잡도 측정
맥케이브 순환도, 맥케이브 복잡도 메트릭
- 프로그램의 경로의 수 정의 → 모든 경로가 한 번 이상 수행됨을 보장하기 위해 테스트 횟수 상한선
> 순환 복잡도 계산
제어 흐름도 G에서 순환 복잡도 V(G) 계산
- 순환 복잡도는 제어흐름도의 영역 수와 일치하므로 영역 수를 계산
- V(G) = E - N + 2
- E == 화살표 수
- N == 노드 수
16) 소스 코드 최적화
- 클린 코드
- 단순 명료한 코드, 잘 작성된 코드
- 나쁜 코드(Bad Code)
- 로직이 복잡하고 이해하기 어려운 코드
- 스파게티 코드: 코드 로직이 서로 복잡하게 얽혀있는 코드
- 외계인 코드: 너무 오래되거나 참고할 게 없어서 유지보수 어려운 코드
- 클린 코드 작성 원칙
- 가독성
- 단순성: 한 번에 한 가지 처리하도록, 클래스/메소드 등을 최소 단위로 분리
- 의존성 배제: 코드가 다른 모듈에 미치는 영향을 최소화, 변경 시 다른 부분에 영향이 없도록 작성
- 중복성 최소화
- 추상화: 상위 클래스/메소드/함수에서는 간략히 애플리케이션의 특성을 나타내고, 상세 내용은 하위에서 구현
17) 소스 코드 품질 분석 도구
- 정적 분석 도구
- 실행 X. 코딩 표준이나 스타일, 결함 확인
- 애플리케이션 초기 결함 찾기 → 완료 시점에서는 품질 검증 차원
- 자료 흐름, 논리 흐름을 분석 → 비정상적 패턴 찾기
- 코딩의 복잡도, 모델 의존성, 불일치성 분석
- pmd, cppcheck, SonarQube, checkstyle, ccm, cobertura
- 동적 분석 도구
- 실행하여 메모리 누수, 스레드 결함 분석
- Avalanche, Valgrind
4. 인터페이스
1) EAI
Enterprise Application Integration
기업 내 앱/플랫폼 간 정보 연동 솔루션
비즈니스 간 통합, 연계성 증대 → 효율성, 확정성 ↑
- 구축 유형
- Point-to-point: 애플리케이션 1:1 연결 / 변경, 재사용 어려움
- Hub & Spoke: 중앙 집중형(허브 시스템) / 확장, 유지보수 용이 / 허브 시스템 장애 시 시스템 전체에 영향
- Message Bus(ESB 방식): 앱 사이에 미들웨어 / 확장성 ↑, 대용량 처리 가능
- Hybrid: Hub&Spoke + Message Bus
- 그룹 내에서는 허브 시스템, 그룹 간에는 메시지 버스
- 필요한 경우 한 가지 방식으로 EAI 구현 가능
- 데이터 병목 최소화
- ESB
Enterprise Service Bus
애플리케이션 간 연계, 데이터 변환, 웹 서비스 지원 등 표준 기반의 인터페이스를 제공하는 솔루션
- 애플리케이션 통합 측면에선 EAI와 유사, 그러나 서비스 중심 통합 지향
- 애플리케이션과 Loose Coupling 유지 → 범용성을 위해
- 관리, 보안 유지 쉬움, 높은 품질 지원 가능
2) JSON
JavaScript Object Notation
속성-값 쌍, ajax에서 xml 대체
3) XML
eXtensible Markup Language
다목적 마크업 언어
HTML이 웹 브라우저에서 상호 호환적이지 못함
SGML의 복잡성 해결
4) AJAX
Asynchronous JavaScript and XML
비동기 통신 기술
클라이언트-서버 간 XML 데이터를 교환 → 웹 페이지와 자유롭게 상호작용
5) 인터페이스 보안 기능 적용
일반적으로 네트워크, 애플리케이션, 데이터베이스 영역에 적용
- 네트워크 영역
- 인터페이스 송/수신 간 스니핑으로 데이터 탈취 및 변조 위협 때문에 네트워크 트래픽 암호화
- IPSec, SSL, S-HTTP 등
- IPSec: IP Security. IP 패킷 단위의 데이터 보안 프로토콜, 양방향 암호화 지원
- 애플리케이션 영역
- 코드 상 보안 취약점 보완
- 데이터 베이스 영역
- DB, 스키마, 엔티티 접근 권한 및 프로시저, 트리거 등
6) 데이터 무결성 검사 도구
시스템 파일 변경 시 관리자에게 알려줌
인터페이스 보안 취약점 분석에 사용
백도어 만들거나 시스템 파일에서 발자국 지우는 행위 감지
해시 함수로 현재 파일/디렉토리 상태 DB 저장 후 상태 변경 시 알려줌
Tripwire, AIDE, Samhain, Claymore, Slipwire, Fcheck
7) 인터페이스 구현 검증 도구
- xUnit
- 테스트 코드 반복 줄여주고, 자동화된 예상 결과 제공 → 단위 테스트 프레임워크
- JUnit, CppUnit, NUnit, HttpUnit 등
- STAF
- 서비스 호출, 컴포넌트 재사용 등 다양한 환경 지원
- 크로스 플랫폼, 분산 소프트웨어 테스트 환경 지원
- 분산의 경우, 데몬이 테스트 응답 대신, 테스트 완료 시 통합/자동화하여 프로그램 완성
- FitNesse
- 웹 기반 테스트 케이스 설계, 실행, 결과 확인 지원
- NTAF
- FitNesse의 협업 기능 + STAF의 재사용성, 확장성
- 네이버의 테스트 자동화 프레임워크
- Selenium
- 다양한 브라우저, 개발 언어 지원 → 웹 앱 테스트 프레임워크
- watir: Ruby
8) APM
Application Performance Management/Monitoring
성능 관리를 위해 접속자, 자원 현황, 트랜잭션 수행 내역, 장애 진단 등 다양한 모니터링 도구
- 리소스 방식: Nagios, Zabbix, Cacti
- 엔드투엔드 방식: VisualVM, 제니퍼, 스카우터
