
1. 오늘의 스토리
이전에 식당 얘기를 할때
직원들이 각자의 업을 맡아서
식당 운영이 어느정도 되어서
어느 괘도에 잘 올라섰다고 함보자 손님들도 많아지고 잘 돈을 벌고 있었다고 해보자.
그런데 손님이 많아 지다 보니까 이것들을 어떻게 처리를 할지 고민이 생기기 시작했다.
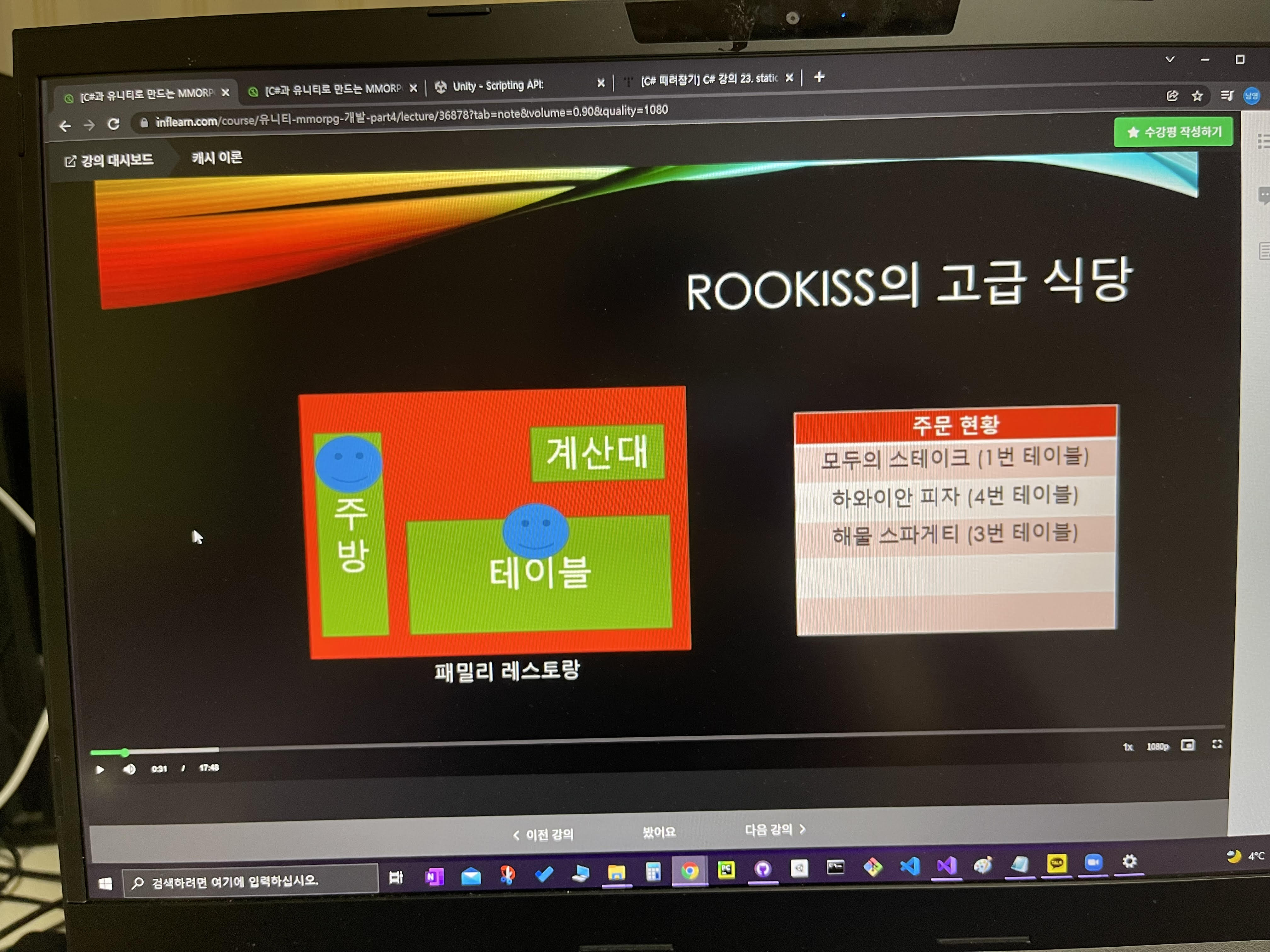
이렇게 테이블을 돌아 다니면서 주문을 받는 직원이 한명이 있다.
아무튼 주문 받은 것을 어떤 방식으로든지 주방에다가 전달을 해야지만 주문이 들어 갈 것이다.
머리속에 알바가 주문을 기억했다고해서 자동적으로 주문이 들어가지는 않을 것이다.
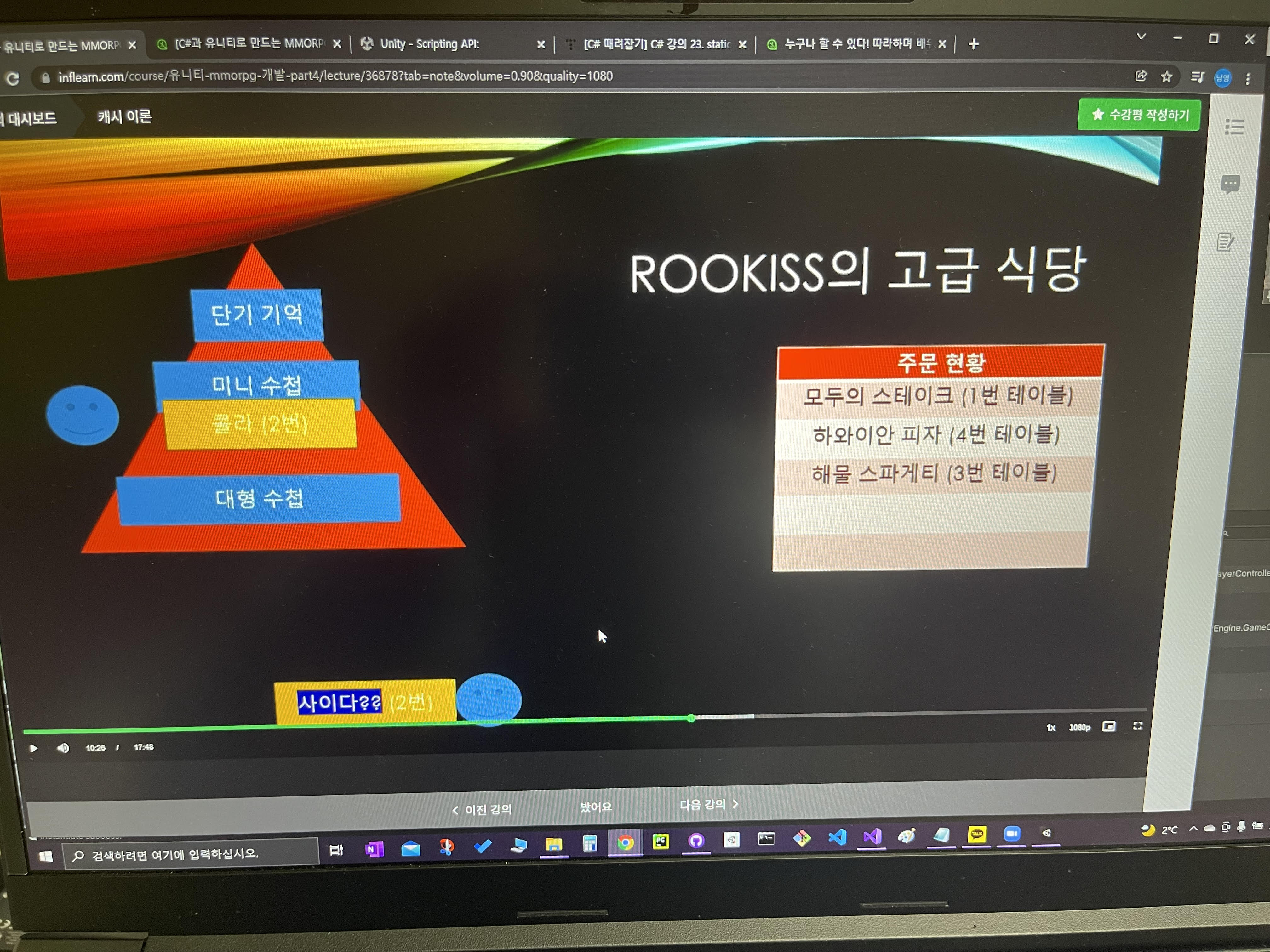
이 식당에서는 특이하게 주문 현황이라는 "기계"가 있는데
그래서 주문을 받은 것을 이 주문현황 기계에다가 기입을 하면 원격으로 주방에서도 확인을 할 수 있어가지고
그제서야 요리를 시작하는 그런 구조로 되어있다고 가정을 해보도록 하자.
그런데 주문 현황판까지 직원이 가기 너무 멀어서 시간이 아깝다라는 문제가 있다.
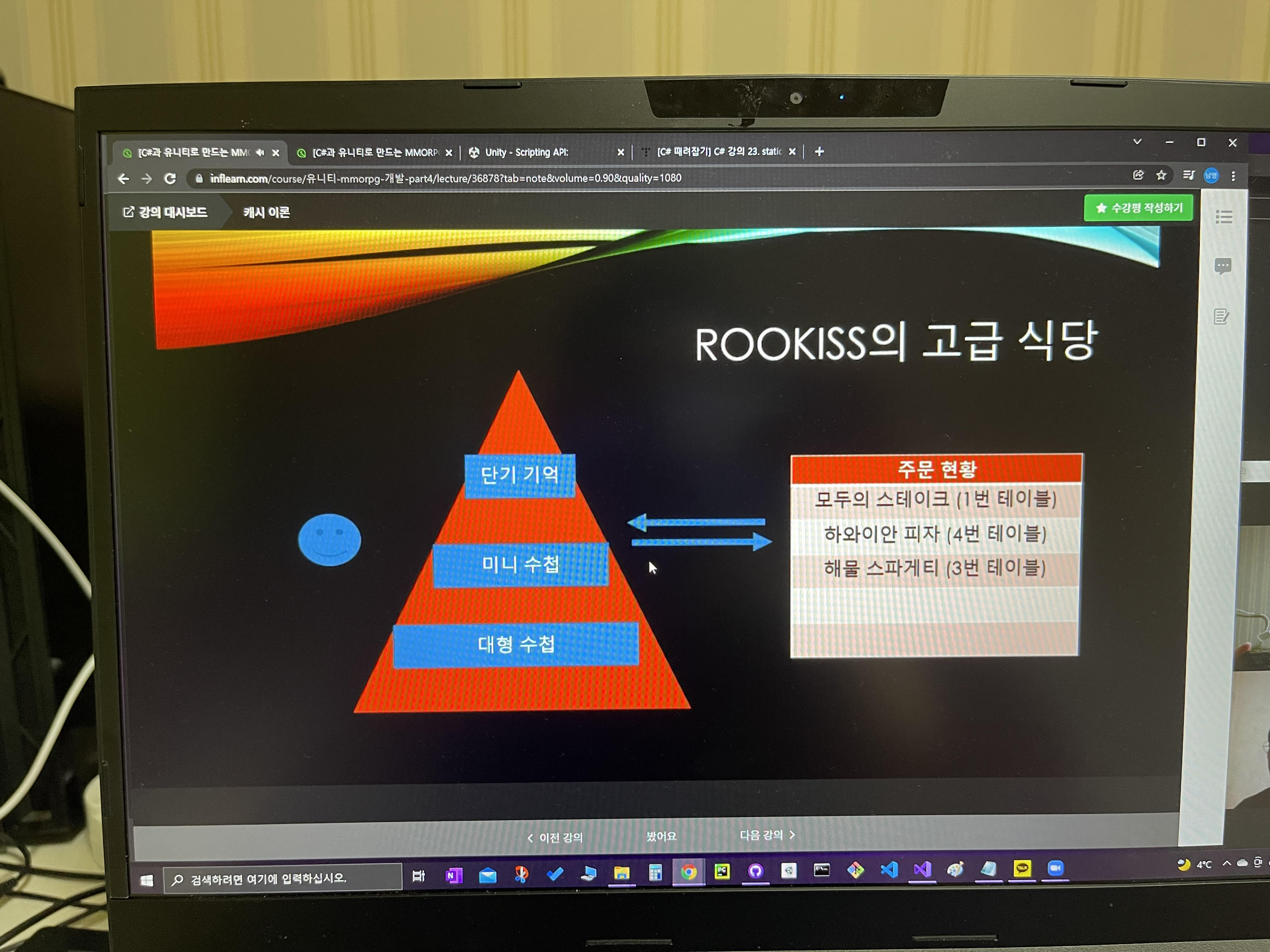
그래서 똑똑한 직원은 주문을 받자마자 바로 기계에 가서 기입을 하는 것이 아니라
조금 꼼수를 써서
최대한 꾹꾹 눌러가지고 기억을 해가지고 모아가지고
한번에 주문현황 판에가서 기입을 하면 어떻까라는 생각을 해본 것이다.
테이블을 돌아다니면서
최대한 단기 기억으로 주문을 기억을 하고
그래도 조금 벅차다 싶으면 준비한 수첩에다가 적어가지고
주문을 모아서 한번에 들어 갈 수 있도록 하는 것이다.
실제로도 식당에 가면 스파게티 주문받고 주방에 전달하지 않고
스파게티, 콜라, 피자 이런식으로 주문들을 다 받은 다음에 한번에 한다.
이것과 비슷하다고 보면 될 것이다.

이렇게 2번 테이블에서 콜라를 수첩에다가 받아 적고 나중에 주문현황에 기입을 하면
"장점" 이 있는데
2번 테이블에서 갑자기 콜라를 취소를 하고 사이다로 변경을 하면 아직 주문현황판에 기입은 안하고 직원 수첩에다가만 적어놨으니
콜라 x 표치고 사이다만 기입을 해서 나중에
주문현황판에 기입을 하면 아무 문제 없이 잘 될 것이다.
그런데 만약에 직원수가 많아지면 생기는 문제가 있는데
최종적인 주문현황판에 기입을 하기 전에는
"수첩"이나 그런 단기 기억을 하는데에다가만 적으니까
그 "수첩"은 개개인마다 들고있지 공유를 하지 않기 때문에
1번직원이 콜라를 주문을 받아서 자기 수첩에다가 적어 놨는데
다른 볼일을 보러 간다고 2번 직원이 콜라를 주문 테이블에서 주문을 번복을해서 콜라 -> 사이다 변경 주문을 2번 직원이 받았다고 가정을 해보도록 하자.
그런데 두번째 알바는 약간 벙 찌는게 2번직원은 애초에 "콜라"라는 주문을 받은 적이 없었다.
콜라주문을 번복을 왜 해야되는지 모르는 사태가 발생을 한다.
그러니까 최종적인 주문이 실시간으로 갱신되지 않다 보니까
이렇게 알바가 다른 정보를 들고 있으니까 여기서 혼선이 생긴다는 이야기가 된다.
그래서 이것이 오늘까지의 스토리이이고
이것이 우리의 컴퓨터에서도 똑같이 일어나고 있다.
2. 오늘의 스토리 -> 컴퓨터
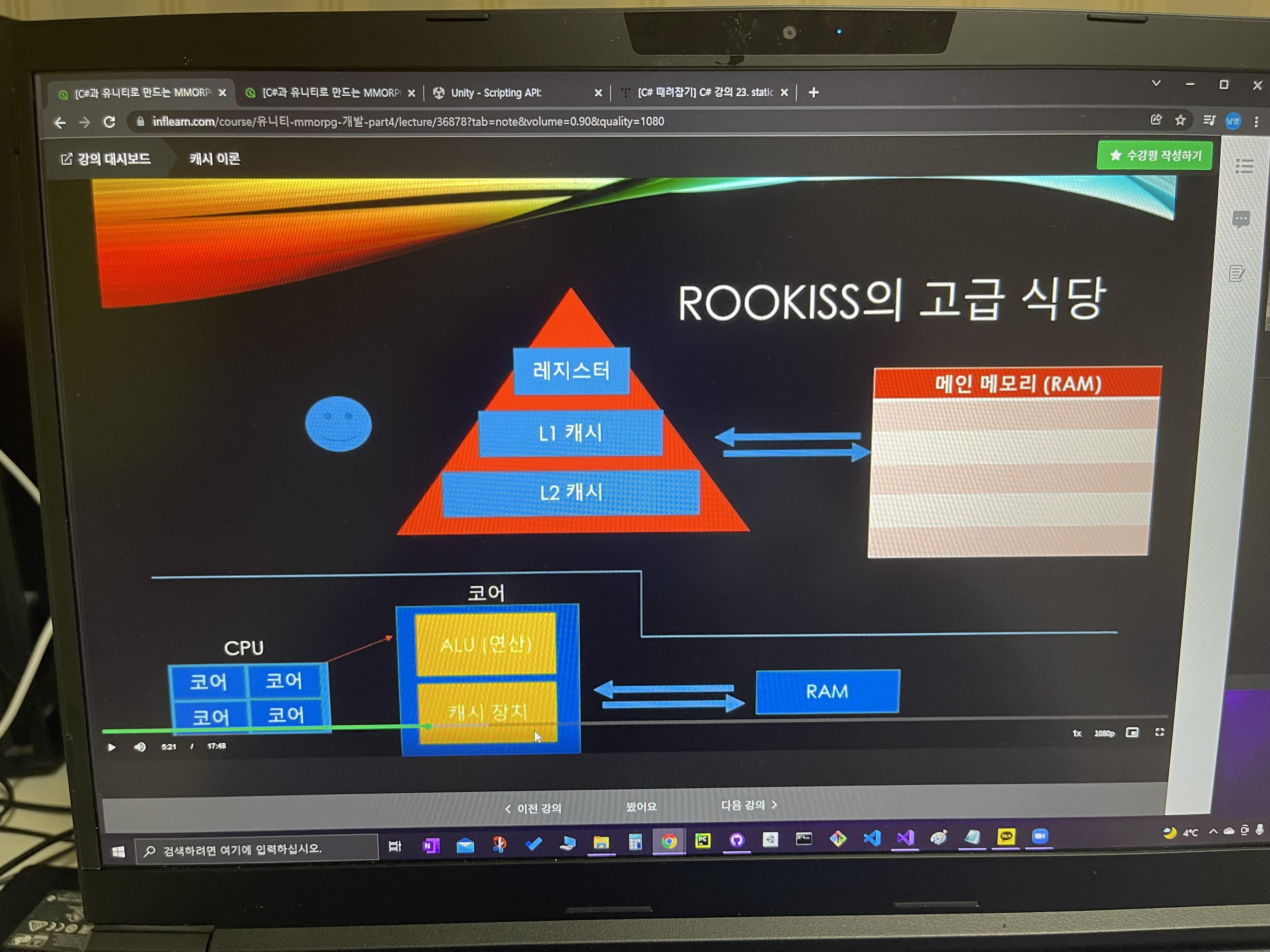
우리가 이전에 CPU와 Core에 대해서 이야기를 했었었는데
요즘은 멀티코어로 많이 나와가지고 듀얼코어 멀티코어 이런 용어들을 많이 쓴다.
즉, CPU안에 코어가 여러개가 존재 할 수 있는데
이 "코어"를 다시 확대를 해서 까보면은
-
"ALU" 라고 하는는 "연산"을 하는 장치
-
"캐시" 라고 하는 "기억"을 하는 장치
이렇게 두가지가 있다.
그래서 "코어"는 이런식으로 연산하는 것과 기억을 하는 것으로 세트로 보면 되고
마찬가지로 최종적으로 메모리에다가 기입을 하는것은
메모리랑 CPU가 워낙 멀리 떨어져 있기 떄문에(물리적으로 너무 멀리 있기 때문에)
매번마다 "메모리 갱신"이 일어 난다고 해서
이렇게 매번 "RAM"에 가가지고 매번바다 갱신을 하는 것은
너무나도 힘든일이 될 것이다.
그래서 피라미드에서 보이는 것 처럼
-
레지스터(좀 가벼운 것들을 기억하는 것)
-
L1 캐시
-
L2 캐시
이런식으로 다양한 캐시 기억을 하는 기억장치들이 준비가 되어있다.(가벼운것 -> 무거운것)을 하기 위한 캐시 장치들이 준비되어 있다.
그래서 어떤 변수나 메모리에 있는 값을 조작한다고 했을 때
그것을 실제로 바로 메모리에 바꿔치기(갱신)하는 것이 아니라
일단은 "캐시장치"에다가 기입을 해가지고
나중에 시간이 좀 지나면 한번에 메모리에 올리는 그런 작업을 하는 것이다.
그런데 캐시가 사용되는 것은 사실
우리가 딱히 뭘 하지 않더라도 내부적으로 알아서 작동을 하고있는 것이다.
우리도 코드를 작성을 할때 이 "캐시"의 덕을 계속 보고 있었던 것이다.
그런데 이것을 딱히 체감은 할 수 없었을 것이다.
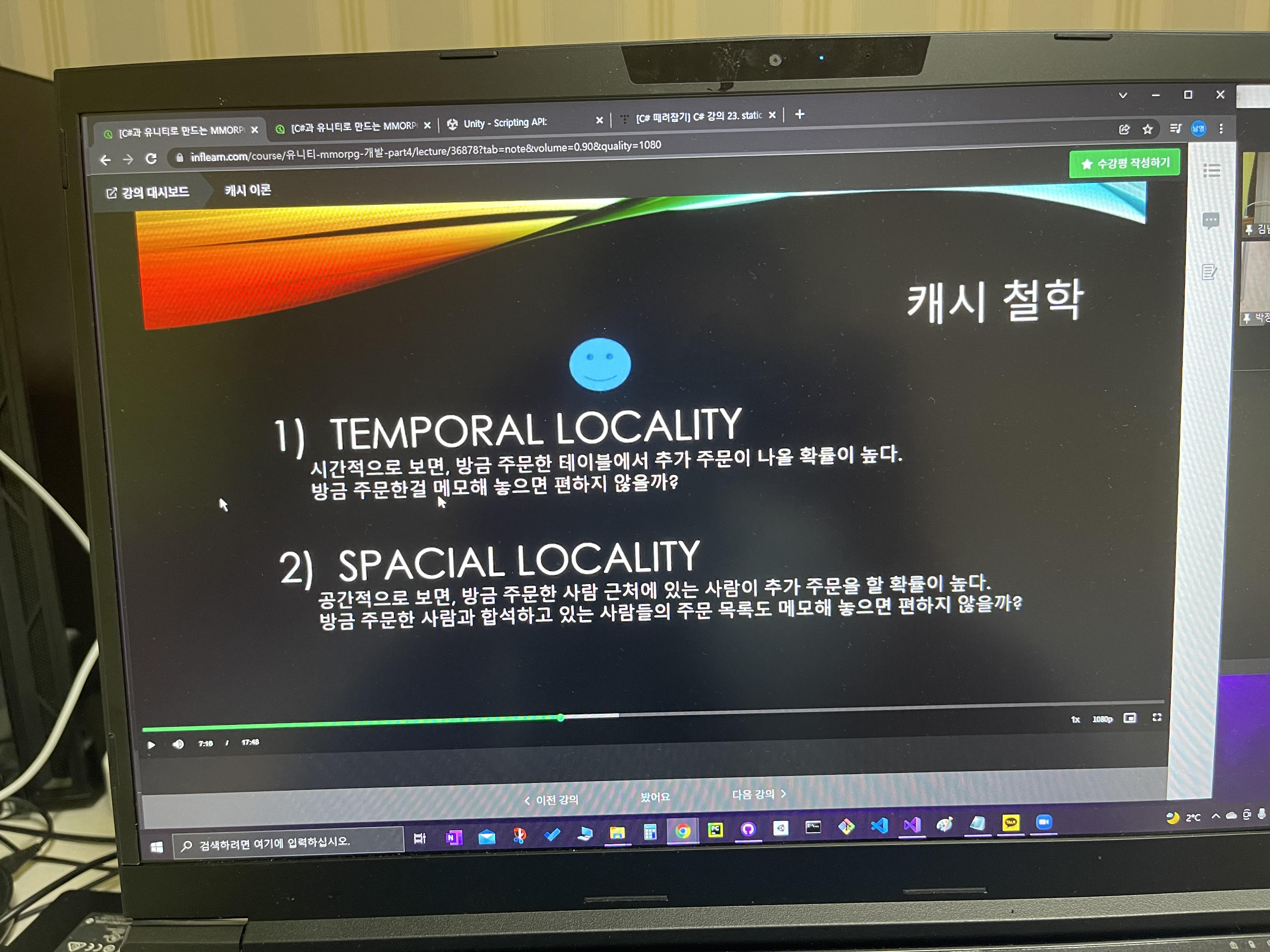
그런데 사실 "캐시" 자체는 철학이 두가지가 있는데
"무엇을" "캐싱"할 것인가에 대답하기 위해서
두가지로 분류를 하는 것이다.
- 1) TEMPORAL LOCALITY
시간적으로 보면, 방금 주문한 테이블에서 추가 주문이 나올 확률이 높다.
방금 주문한것을 메모해 놓으면 편하지 않을까?
- 2) SPECIAL LOCALITY
공간적으로 보면,
방금 주문한 사람 근처에 있는 사람이 추가 주문을 할 확률이 높다. 방금 주문한 사람과 합석하고 있는 사람들의 주문 목록도 메모해 놓으면 편하지 않을까?
첫번째는 temporal이 있으니까 시간과 관련이 있다는 것을 알 수 있겠죠.
시간 관점에서보면 가장 최근에 사용한 그 변수가
또 다시 재사용될 확률이 높다는 철학에서 온것이다.
그래서 방금 주문을 한 테이블에서 다시 주문을 할거같다라고 가정을 하고
캐싱을 하면은 왠지 더 좋을 거 같다라는게 첫번째 이고
두번째 철학은
"시간"과는 딱히 관련이 없지만
"공간"적으로 보면은
방금 접근한 변수와 인접한 주소에있는 그런 주소들이 또 방문될거같다라는 예감이 드는 것이 두번째 철학이다.
다시, 식당으로 비유를 하면은
방금 처음으로 주문한 사람 근처에있는 사람들이 주문을 할 확률이 높다는 이야기가 된다.
이렇게해서 캐시에 대한 내용을 쭉봤는데
이것이 실생활에서도 유용하지만
컴퓨터 프로그래밍을 할떄도 이부분이 굉장히 유용하게 또 알게 모르게
잘 사용되고 있었다.
그런데!, 이제또
싱글쓰레드라고 했으면은 우리가 모르는 사이에 잘 일어나고 있었으니까
그냥 편한게 doc만 보면 되었는데
이게 또 멀티 쓰레드 환경이 되면은
이런것도 하나하나씩 우리의 발목을 붙잡게 된다는 의미이다.
그러니까
아까 이전에 했던 내용을 잠깐 다시 살펴보면은
이렇게 혼자서는 잘 진행하고 아무런 문제가 없었는데
이런식으로 직원이 여러명이 되면은
서로 가지고있는 data가 안 맞으니까 문제가 된다고 했었다.
그런데 이것이 컴퓨터도 똑같이 문제가 될 것이다.
우리가 이제 "멀티쓰레드"환경에서는
"쓰레드"마다 각각의 "코어"로 실행이 되고있고
그다음에 "코어"마다 자신만의 "캐시"가 따로 있을텐데
만약에 우리가 어떤 변수를 어떤 값으로 고쳤다고 했을 때,
그게 100%확률로 메모리에 바로 올라가는 것이 아니니까
다른 "쓰레드"입장에서 볼 떄는
분명히 첫번째 아이가 데이터를 건드렸음에도
두번째 아이가 볼때는 방금 "수정"된 따끈따끈한 애로 보는 것이 아니라
그 이전 data 즉, 두번째 아이가 기억하고있던
그 "캐시"에 있던 data를 사용하게 된다는 문제가 있다.
이게 굉장히 끔찍하다.
우리가 이떄까지는 로직을 보면은
data를 고쳤으면 data가 고쳐진것이라고 가정을 했었는데
그거는 어디까지나 "싱글 쓰레드" 였으니까 그렇게 됬던 것이였고
"멀티 쓰레드" 환경에서는 그 "가정"이 깨지게 된다.
즉, 어떤 식으로든
만약 그게 정말 중요한 정보라고 하면은
여기 주문 현황판에다가 업데이트를 한 다음에
이 두번째 아이가 사용하지 않으면은 "문제"가 일어나는 상황이 된다는 것이다.
그래서 마치기 전에 짧은 실습을 해보도록 하자.
여기다가 간단한 테스트를 하고 마치도록 하자.
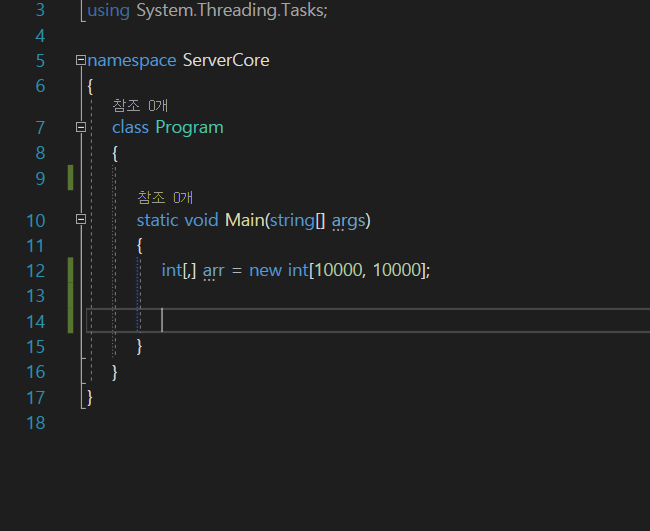
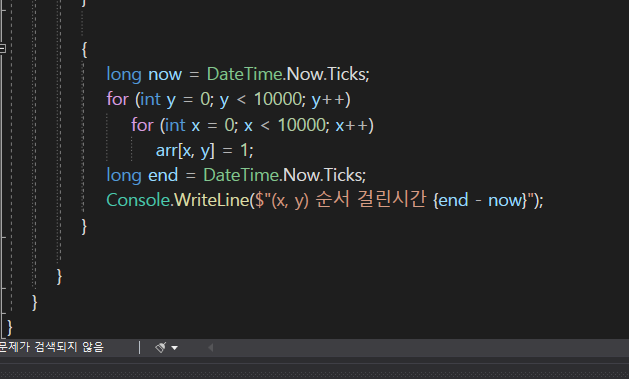
이렇게 어마어마하게 큰 10000개짜리 2차 배열을 만들어 보도록 하자.
그래서 캐시가 잘 동작하는 지 알아보기 위해서

이렇게 코드를 2차 배열을 만들어서 코드를 실행을 해볼 것이다.
그런데 수학적으로보면 둘다 똑같은 시간이 걸릴거같은게 상식적인데
같은 시간이 걸리지 않을 것이다.
실행을 해보면은
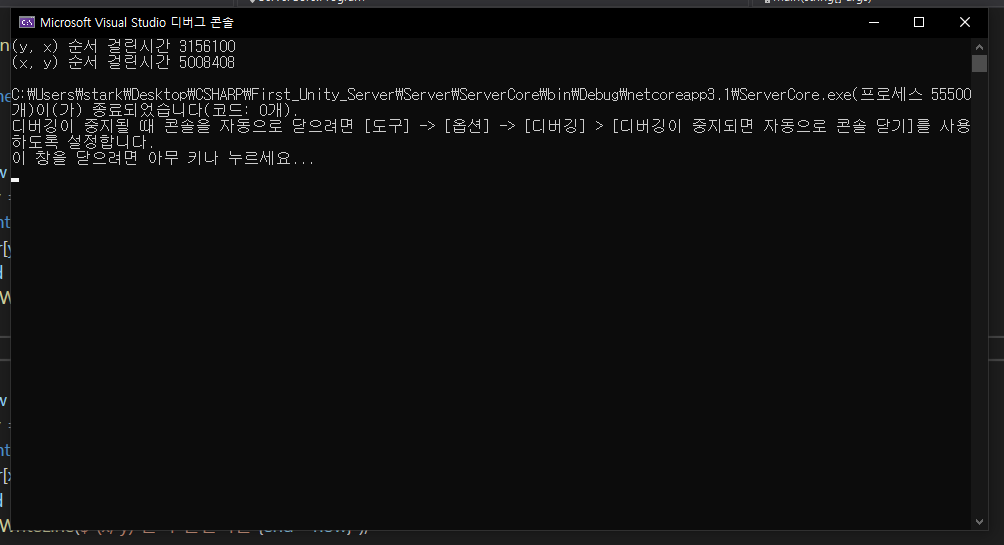
이렇게 실행결과 시간이 차이가 나는데
이게 지금 아까전에 말한
SPECIAL LOCALITY라는 것이다.
그림으로 설명을 하면은
이렇게
5 * 5 배열이 있다고 하면은

첫번째 for의 경우 첫번째 인자에 접근을함과 동시에
캐시에서 두번째 철학을 사용을해서 근접한 주소(두번째 배열에) 갈 것이라고 예상을 해서 준비? 같은 상태를 취해서 바로 바로 다음다음
두번째에 접근을 하고 세번째에 바로 접근을 하는 것이다.
그래서 캐시에 있는 값에 바로 접근을해서 업데이트를 하는 것이다.
(메모리까지 가서 값을 가져와서 연산을 하는 것이 아니라)
그러니까 상대적으로 빠르다는 얘기가 되는 것이고
근데 두번째 경우에는
이 상황일 경우에는
여기 첫번째에 먼저 접근을 하고
두번째칸? 에 접근을 하고
세번쨰 칸에 이런식으로 접근을 하는 꼴이니까
캐싱의 두번째 철학인
방금 접근한 변수와 인접한 주소에있는 그런 주소들이 또 방문될거같다라는 예감이 드는 것이 두번째 철학이다.
라는 철학이 먹히지 않아
띄엄띄엄 접근을 계속 하다가 한바퀴를 돌고 나면은
여기에 접근을 해서 이어가게 될 것이다.
이렇게 되면 아까 말한 공간적 이점을 살릴 수 없게된다.
왜나하면은
이녀석에 접근을 하면 그다음 인접한 녀석에게 접근을 할 것이라 생각을 하고
캐시에 넣어 둔 상태인데
우리는 쿨하게 다음 테이블 쫙 멀리가서
이런 아이를 사용을 하고 잇으니까
캐시를 활용할 수 없는 그런 코드가 될 것이다.
그래가지고 아까 시간을 측정을 해보아도 차이가 난다는 것을 볼 수 있었다.
그래서 실제로 꼭
"멀티 쓰레드"가 아니라고 하더라도
이런식으로 "캐시"가 잘 잘동하고 있다라는 것을 실험적으로 확인을 해보았다.
그리고 이게 멀티쓰레드로 가기 시작하면은
더 끔찍한 일들이 벌어진다는 것까지 예고를 하고 이번시간은 마치도록 하겠다.
