환경 setting
$ conda create -n yolov7 python=3.8
$ conda activate yolov7
$ pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
$ pip install -r requirements.txt
$ sudo apt-get install libgl1-mesa-glxor
environment_setting.sh 파일 생성 (in Kubeflow)
#!/bin/sh
echo "################################# Creating conda environment #################################"
conda create -y -n test python=3.8
echo "################################# Activating conda environment #################################"
source /opt/conda/etc/profile.d/conda.sh
source /opt/conda/bin/activate test
echo "################################# Installing pytorch #################################"
pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
echo "################################# Installing dependencies #################################"
pip install -r requirements.txt
echo "################################# Installing libgl1-mesa-glx #################################"
sudo apt-get install libgl1-mesa-glx
echo "################################# Finished #################################"environment_setting.sh 파일 실행 (in Kubeflow)
$ . ./environment_setting.shInference
Single Image
$ python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source inference/images/myimage.jpgDataset
$ python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source /path/to/my/datasetVideo
# Merge frames to make video
$ python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source /path/to/myvideo.mp4Realsense D435i
detect_RS.py
import argparse
import time
from pathlib import Path
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
from models.experimental import attempt_load
from utils.datasets import LoadStreams, LoadImages
from utils.general import check_img_size, check_requirements, check_imshow, non_max_suppression, apply_classifier, \
scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path
from utils.plots import plot_one_box
from utils.torch_utils import select_device, load_classifier, time_synchronized, TracedModel
import pyrealsense2 as rs
import numpy as np
def detect(save_img=False):
source, weights, view_img, save_txt, imgsz, trace = opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_size, not opt.no_trace
# Directories
save_dir = Path(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok)) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Initialize
set_logging()
device = select_device(opt.device)
half = device.type != 'cpu' # half precision only supported on CUDA
# Load model
model = attempt_load(weights, map_location=device) # load FP32 model
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(imgsz, s=stride) # check img_size
if trace:
model = TracedModel(model, device, opt.img_size)
if half:
model.half() # to FP16
# Second-stage classifier
classify = False
if classify:
modelc = load_classifier(name='resnet101', n=2) # initialize
modelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']).to(device).eval()
# Get names and colors
names = model.module.names if hasattr(model, 'module') else model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in names]
# Run inference
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
old_img_w = old_img_h = imgsz
old_img_b = 1
config = rs.config()
config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30)
config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30)
pipeline = rs.pipeline()
profile = pipeline.start(config)
align_to = rs.stream.color
align = rs.align(align_to)
while(True):
#t0 = time.time()
frames = pipeline.wait_for_frames()
aligned_frames = align.process(frames)
color_frame = aligned_frames.get_color_frame()
depth_frame = aligned_frames.get_depth_frame()
if not depth_frame or not color_frame:
continue
img = np.asanyarray(color_frame.get_data())
depth_image = np.asanyarray(depth_frame.get_data())
depth_colormap = cv2.applyColorMap(cv2.convertScaleAbs(depth_image, alpha=0.08), cv2.COLORMAP_JET)
# Letterbox
im0 = img.copy()
img = img[np.newaxis, :, :, :]
# Stack
img = np.stack(img, 0)
# Convert
img = img[..., ::-1].transpose((0, 3, 1, 2)) # BGR to RGB, BHWC to BCHW
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Warmup
if device.type != 'cpu' and (old_img_b != img.shape[0] or old_img_h != img.shape[2] or old_img_w != img.shape[3]):
old_img_b = img.shape[0]
old_img_h = img.shape[2]
old_img_w = img.shape[3]
for i in range(3):
model(img, augment=opt.augment)[0]
# Inference
t1 = time_synchronized()
with torch.no_grad(): # Calculating gradients would cause a GPU memory leak
pred = model(img, augment=opt.augment)[0]
t2 = time_synchronized()
# Apply NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t3 = time_synchronized()
# Process detections
for i, det in enumerate(pred): # detections per image
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
#s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
c = int(cls) # integer class
label = f'{names[c]} {conf:.2f}'
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=2)
plot_one_box(xyxy, depth_colormap, label=label, color=colors[int(cls)], line_thickness=2)
# Print time (inference + NMS)
#print(f'{s}Done. ({(1E3 * (t2 - t1)):.1f}ms) Inference, ({(1E3 * (t3 - t2)):.1f}ms) NMS')
# Stream results
cv2.imshow("Recognition result", im0)
cv2.imshow("Recognition result depth",depth_colormap)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='yolov7-tiny.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='inference/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--no-trace', action='store_true', help='don`t trace model')
opt = parser.parse_args()
print(opt)
#check_requirements(exclude=('pycocotools', 'thop'))
with torch.no_grad():
if opt.update: # update all models (to fix SourceChangeWarning)
for opt.weights in ['yolov7.pt']:
detect()
strip_optimizer(opt.weights)
else:
detect()$ pip install pyrealsense
$ python3 detect_RS.py
# 사람만 검출하고 싶다면
$ python3 detect_RS.py --classes 0
# 지정한 class에 대한 object만 검출 가능Training with MS COCO Dataset
Data Preparation
# yolov7 경로에서 실행
$ bash scripts/get_coco.shSingle GPU Training
# train p5 models
python train.py --workers 8 --device 0 --batch-size 32 --data data/coco.yaml --img 640 640 --cfg cfg/training/yolov7.yaml --weights '' --name yolov7 --hyp data/hyp.scratch.p5.yaml
# train p6 models
python train_aux.py --workers 8 --device 0 --batch-size 16 --data data/coco.yaml --img 1280 1280 --cfg cfg/training/yolov7-w6.yaml --weights '' --name yolov7-w6 --hyp data/hyp.scratch.p6.yaml만약 학습이 도중에 끊겼을 때 끊긴 epoch부터 다시 학습시키고 싶다면 --resume 인자를 붙여주면 runs/train/yolov7(가장 최근에 저장된 학습 폴더)/weights/last.pt 로부터 끊기기 전에 저장된 최근의 weight부터 학습을 시작할 수 있다. 또한 --resume 뒤에 특정 weight 파일 경로를 입력해주면 특정 epoch부터 학습을 재개할 수 있다.
Test
Github에 나와있는 성능과 MSCOCO dataset으로 직접 학습한 모델의 성능과의 비교 작업을 위해 학습을 시킨 후 학습한 weight로 test 진행
python test.py --data data/coco.yaml --img 640 --batch 32 --conf 0.001 --iou 0.65 --device 0 --weights runs/train/yolov71/weights/best.pt --name yolov7_640_val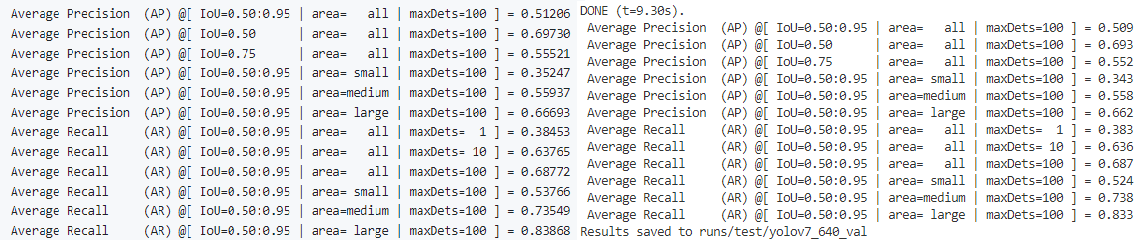
왼쪽이 github에 나와있는 성능표이고, 오른쪽이 직접 학습한 모델을 평가한 성능표이다. 결과적으로 거의 유사한 성능이 도출되었다는 것을 알 수 있다.
Error message
Traceback (most recent call last):
File "train.py", line 616, in <module>
train(hyp, opt, device, tb_writer)
File "train.py", line 245, in train
dataloader, dataset = create_dataloader(train_path, imgsz, batch_size, gs, opt,
File "/home/***/***/yolov7/utils/datasets.py", line 69, in create_dataloader
dataset = LoadImagesAndLabels(path, imgsz, batch_size,
File "/home/***/***/yolov7/utils/datasets.py", line 396, in __init__
cache, exists = self.cache_labels(cache_path, prefix), False # cache
File "/home/***/***/yolov7/utils/datasets.py", line 521, in cache_labels
torch.save(x, path) # save for next time
File "/opt/conda/envs/yolov7/lib/python3.8/site-packages/torch/serialization.py", line 369, in save
with _open_file_like(f, 'wb') as opened_file:
File "/opt/conda/envs/yolov7/lib/python3.8/site-packages/torch/serialization.py", line 230, in _open_file_like
return _open_file(name_or_buffer, mode)
File "/opt/conda/envs/yolov7/lib/python3.8/site-packages/torch/serialization.py", line 211, in __init__
super(_open_file, self).__init__(open(name, mode))
PermissionError: [Errno 13] Permission denied: 'coco/train2017.cache'Solution
coco 폴더에 root 권한을 주면 해결됨
$ sudo chmod 777 coco
[References]

ssw