
Adversarial attacks
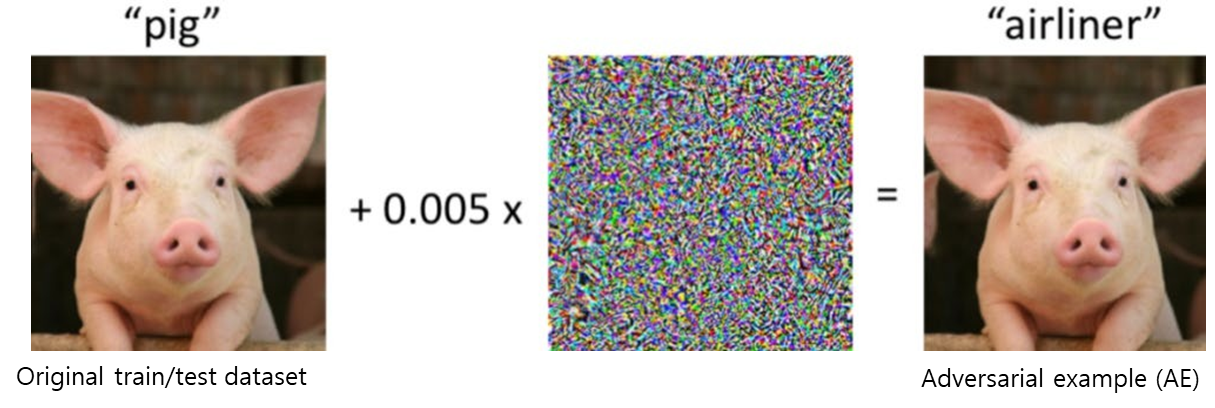
- 컴퓨터는 input 이미지에 약간의 noise라도 추가된다면 오동작한다.
- "airliner"로 분류되게 만드는 이미지를 AE(Adversarial Example)이라고 한다.
- AE를 통해 Deep Neural Net이 높은 확률로 misclassified할 수 있다는 것을 증명할 수 있다.
- Real image의 일부 픽셀 변화로 생성한다.
Perturbation
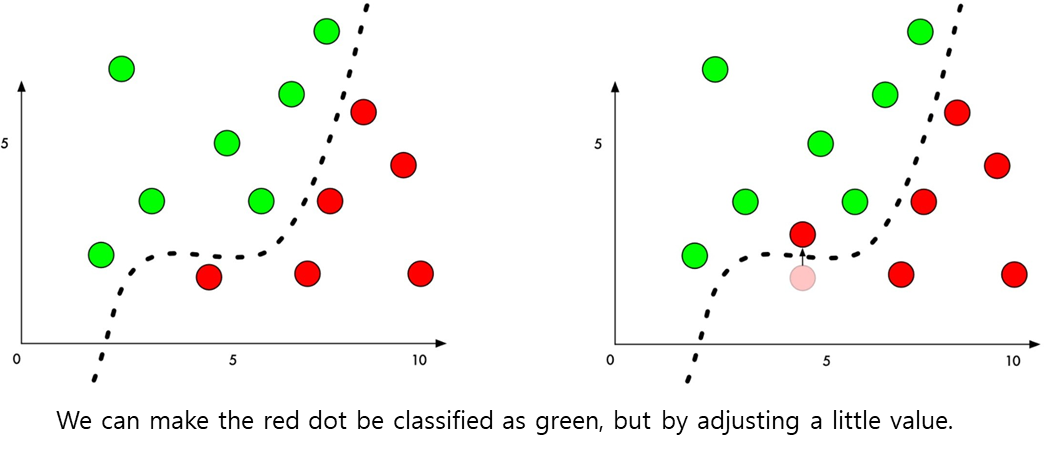
- 점선을 넘어서 오동작한다.
Adversarial example generation
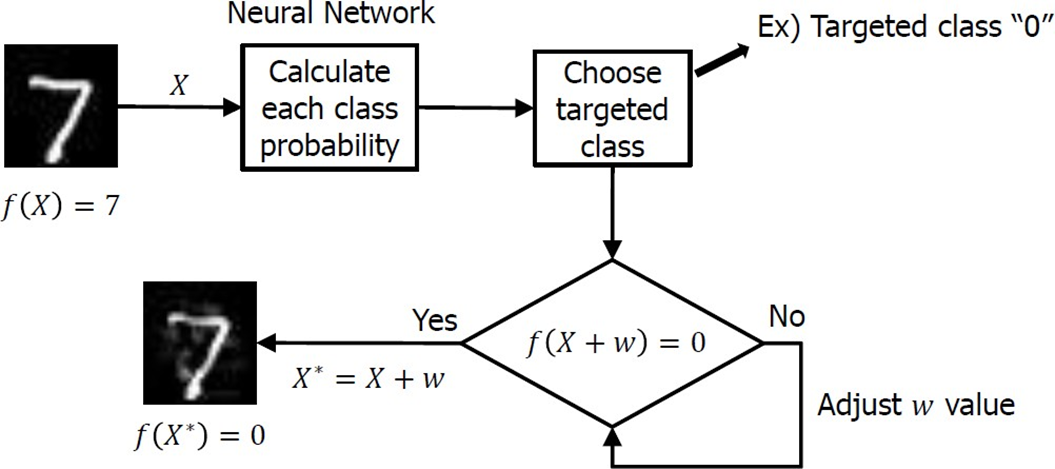
- 7로 분류되도록 학습시켰는데, 0으로 출력하도록 오작동 시킬 것임
- 0으로 출력되면, AE가 생성됨
- 0이 아니라면, 다른 random w를 더한다.
- 이 과정을 반복한다.
Adversarial goals
- 공격자의 의도에 따라서 목표를 다음과 같이 분류
1. Confidence reduction
AI의 신뢰도를 낮추는 방향. 90%의 신뢰도를 가지는 사과 예측을 55%로 낮추는 공격
2. Non-targeted misclassification
오답을 유발하는 공격. 확률을 떨어뜨리는 것뿐만 아니라 아예 다른 예측을 하도록.
3. Targeted misclassification
의도한 오답을 유발하는 공격. 특정 input에 대해 특정 output을 출력하도록
4. Source-Target misclassification
입력에 따라서 오답을 유발하는 공격

- 공격 능력과 공격 목표에 따라서 공격 난이도가 달라진다.
Y축: 공격 대상의 모델을 안다 > train data를 안다 > input, output을 안다 > input, output의 sample을 안다- 내려갈수록 complexity가 높다.
Adversarial capabilities
Training phase capabilities
- Train 단계에서 할 수 있는 공격
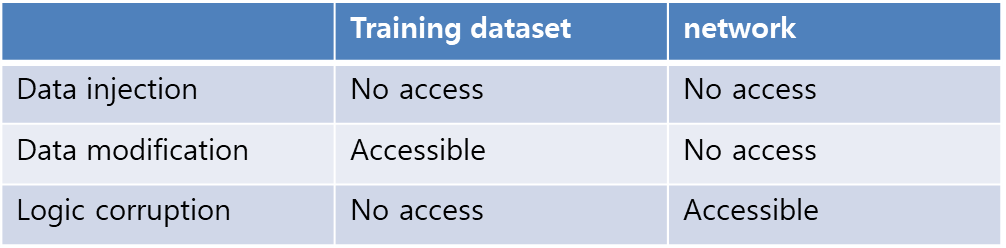
Data injection
Training dataset에 새로운 dataset 추가
Data modification
현재 dataset에 perturbations를 추가해서 수정
Logic corruption
네트워크의 parameters or hyper parameters 수정
Testing phase capabilities
- Test 단계에서 공격
White box attack - Target model에 대한 정보는 알고 있으나, 접근은 못함
Black box attack - 정보는 모르나, image를 input으로 넣어서 나오는 output을 보고 패턴을 분석한다.
Methods of defense
Goals of defense
- Do not change the model structure significantly.
- Do not affect speed and accuracy
Two types
1. Reactive: detect adversarial example
2. Proactive: make deep neural network more robust
Reactive defense
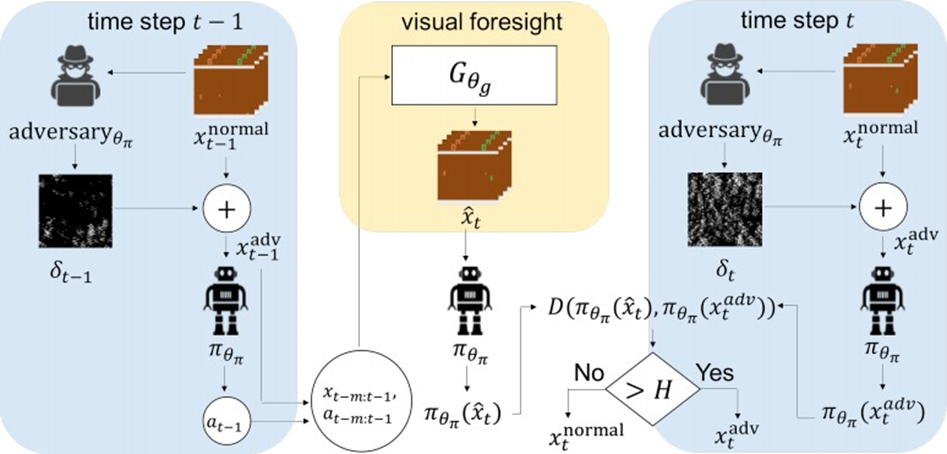
- Distinguish distribution differences
- 이전 타임의 output을 visual foresight에 넣어서 변형한다. -> 예측한 거
- 예측한 거랑 현재 input이랑 차이가 크면 -> attack이라고 결론
- 차이가 적으면, 오염되지 않은 input이다.
Proactive method
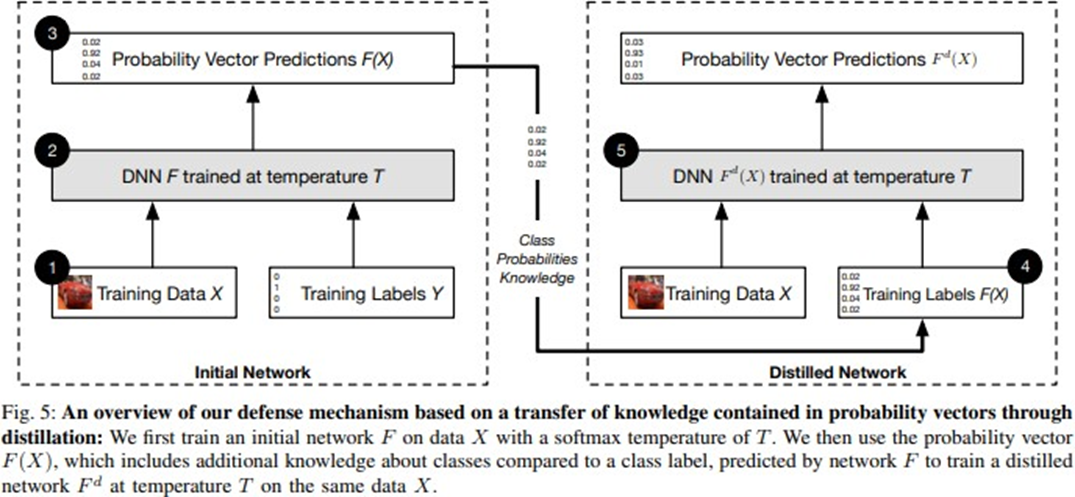
Using Distilled Neural Network
- The label of the second network is softmax of the first network
- 3번을 가져와서 똑같은 network에 넣는다.
- 이건 onehot이 아니라 확률(softmax)로 표현됨
- 이걸 가지고 학습을 한 번 더한다.
-> Distilled network - 네트워크 자체를 robust하게 만든다.
- 한번 학습된 output을 input으로 사용했더니, 새로운 knowledge를 얻을 수 있다.
Adversarial training
Original exmaple+adversarial example넣어서 학습- 정확도가 떨어지지 않도록 한다.
Filtering method

- Adversarial example의 perturbation을 제거한다.
- 필터링 가능
- 이런 방법으로 원래 목적을 달성할 수 있다.
- 원래 dataset과 model을 수정할 필요가 없다.
// 무슨말이지
References

Übermensch