🔎 Python의 selenium을 이용해 동적 페이지에서 원하는 요소를 스크래핑 해 보자.
1. selenium 설치와 webdriver 설치
selenium은Python을 이용해서 웹 브라우저를 조작할 수 있는자동화 프레임워크이고,WebDriver는 웹 브라우저를 제어할 수 있는자동화 프레임워크이다.WebDriver는웹 브라우저와 연동을 하기 위해 필요하다.- 동적인 페이지를 스크래핑 하기 위해서는
selenium과webdriver의 설치가 필요하다.
%pip install selenium
%pip install webdriver-manager2. 추출할 데이터 위치를 분석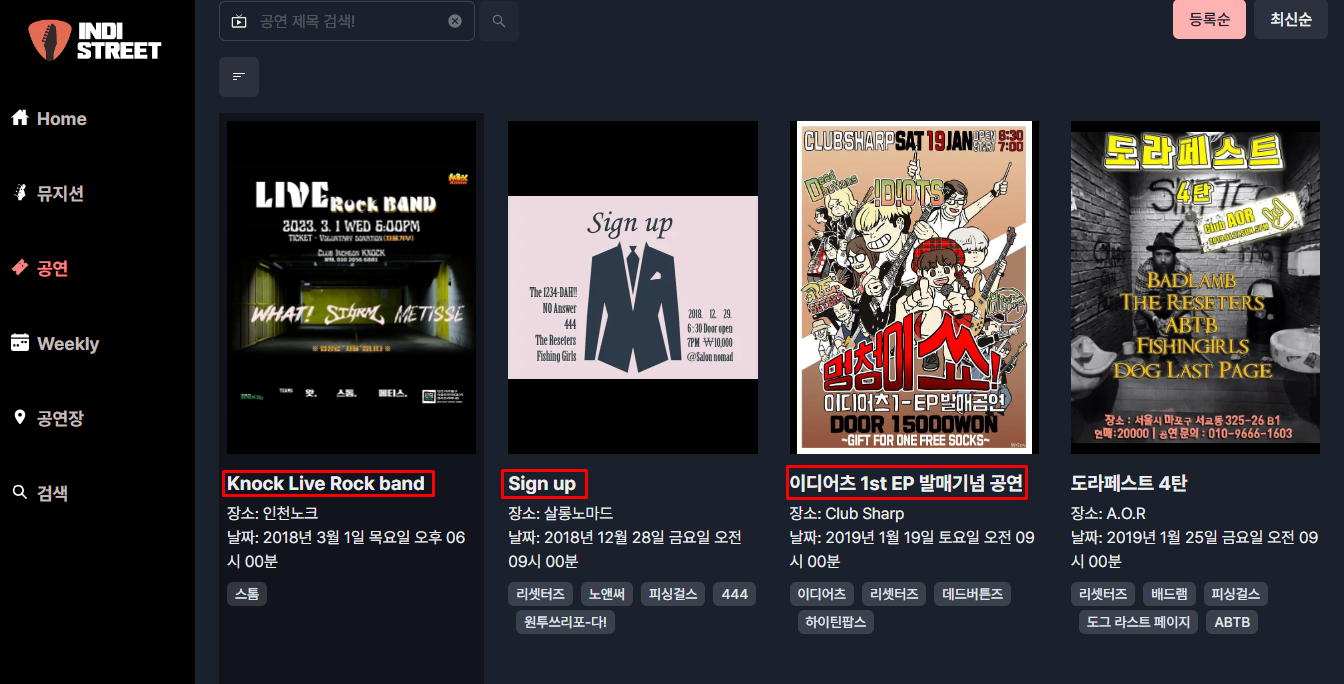
- 인디스트릿이라는 사이트는
동적인 웹 사이트이다. - 우리는 여기서
공연의 이름을 스크래핑 할 것이기 때문에이름에 우 클릭 후검사를 누르거나 직접개발자 도구를 통해공연 제목이 들어가는 위치를HTML 코드에서 찾아 준다.
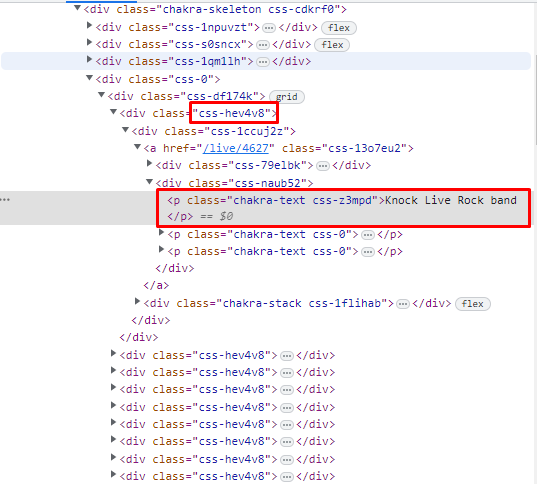
- 공연의 제목은
css-hev4v8이라는class에p태그 안의context임을 알 수 있다. - 이때
class name이임의의 랜덤한 값이 붙는다는 것을 알 수 있는데 이는 스크래핑이 쉬운 환경이 되는 것을 막기 위해class name을 랜덤하게 정의한 것이다. - 이럴 때는 어떤 것을 이용해서
원하는 요소를 추출할 수 있을까?
- 여러 가지 방법이 존재하지만XPath를 통해추출할 것이다.
3. selenium과 webdriver 호출
- 먼저
selenium과webdriver을 사용하기 위해 그에 필요한 라이브러리를import해 준다.
#스크래핑에 필요한 라이브러리를 호출한다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager4. 스크래핑 할 웹 브라우저에 요청을 보내고 드라이버 객체 생성
webdriver.Chrome은 현재 우리가 사용하고 있는Chrome과 동일한 버전을 사용해싱크를 맞추기 위해 사용한다.- Chrome 드라이버 객체를 만들고 이를
driver라는 객체에 넣어 주는 과정이다. - 이 과정을 통해 Chrome 브라우저가 실행된다.
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get("https://indistreet.com/live?sortOption=startDate%3AASC") 5. Xpath를 이용하여 원하는 요소 찾기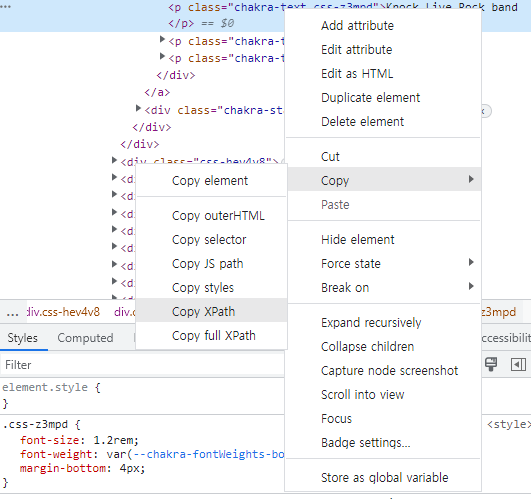
원하는 요소를 찾기 위해서는.find_element(By.대상을 찾는 기준, "대상 속성")혹은.find_elements(By.대상을 찾는 기준, "대상 속성")를 이용할 수 있다.- 다음과 같이 찾기 원하는 소스 코드의 위치를 우 클릭 한 후 복사를 선택하고,
Copy XPath를 선택하면XPath가 복사가 된다. XPath란XML,HTML문서의 요소의 위치를 경로로 표현한 것으로 변하지 않는다.- 첫 번째 공연의 제목의
XPath는//*[@id="__next"]/div/main/div[2]/div/div[4]/div[1]/div[1]/div/a/div[2]/p[1]다음과 같다.
driver.find_element(By.XPATH, '//*[@id="__next"]/div/main/div[2]/div/div[4]/div[1]/div[1]/div/a/div[2]/p[1]')- 하지만
.find_element를 이용해서XPath요소의context를 찾으면NoSuchElementException오류가 발생한다. - 이 오류는 값이 없다는 오류인데 왜 이런 오류가 발생할까?
- 이 웹 페이지가 동적인 웹 페이지이기 때문이다.
- 동적인 웹 페이지를 스크래핑 하기 위해서는
Wait를 해 주어야 한다. Wait의 방법으로는Implicit Wait(암시적 기다림)과Explicit Wait(명시적 기다림)이 존재한다.
6-1. Implicit Wait(암시적 기다림)을 사용하여 원하는 요소 추출
Implicit Wait는.implicit_wait(초단위시간)을 이용해서 적용할 수 있다.- 다만
Implicit Wait는default를 완전하게 로딩이 될 때까지의 시간으로 가지며 만약파라미터를 통해시간(초)를 넣어 주었다면 그 시간 안에 로딩이 되지 않았을 경우그 시간까지의 렌더링된 정보만 가지고 오는 것이다.
# 10초 동안 Implicit Wait를 진행하도록 한 후 스크래핑
#with-as절을 통해 명령어가 끝나면 자체적으로 driver 객체를 소멸시켜 준다.
with webdriver.Chrome(service=Service(ChromeDriverManager().install())) as driver:
driver.get("https://indistreet.com/live?sortOption=startDate%3AASC")
#요청이 완벽하게 응답이 되면 다음을 실행하거나 10초를 기다린다. -> 10초까지를 기다리는데 렌더링이 끝나면 그때 종료
driver.implicitly_wait(10)
print(driver.find_element(By.XPATH, '//*[@id="__next"]/div/main/div[2]/div/div[4]/div[1]/div[1]/div/a/div[2]/p[1]').text)- 해당 코드를 실행하면 우리가 찾고자 했던 첫 번째 공연 제목이
output으로 나오게 된다.# output Knock Live Rock band
6-2. Explicit Wait(명시적 기다림)을 사용하여 원하는 요소 추출
WebDriverWait(드라이버 객체, 지연시킬 초 단위의 시간)과until(조건)혹은until_not(조건)을 통해Explicit Wait를 줄 수 있다.until(조건)은 인자의 조건이 만족될 때까지라는 뜻이고,until_not(조건)은 인자의 조건이 만족되지 않을 때까지 진행한다라는 뜻이다.WebDriverWait는 사용하기 전from selenium.webdriver.support.ui import WebDriverWait를 통해 라이브러리를import해 주어야 한다.- 또한
expected_conditions라는selenium에서 정의된 조건들을 사용하기 위해from selenium.webdriver.support import expected_conditions as EC라이브러리를 추가해 주는 것도 잊어서는 안 된다.
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
with webdriver.Chrome(service=Service(ChromeDriverManager().install())) as driver:
driver.get("https://indistreet.com/live?sortOption=startDate%3AASC")
element = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, '//*[@id="__next"]/div/main/div[2]/div/div[4]/div[1]/div[1]/div/a/div[2]/p[1]')))
print(element.text) - 해당 코드를 실행하면 우리가 찾고자 했던 첫 번째 공연 제목이
output으로 나오게 된다.# output Knock Live Rock band
7. 하나가 아닌 여러 요소를 추출
- 하지만 우리는 하나가 아닌
여러 개의 공연 이름을 스크래핑 하는 것이 목표이기 때문에for문을 생각해 봐야 한다. - 이때
XPath에서의 공통점을 찾는다.
//*[@id="__next"]/div/main/div[2]/div/div[4]/div[1]/div[1]/div/a/div[2]/p[1]
//*[@id="__next"]/div/main/div[2]/div/div[4]/div[1]/div[2]/div/a/div[2]/p[1]
//*[@id="__next"]/div/main/div[2]/div/div[4]/div[1]/div[3]/div/a/div[2]/p[1]- 각 공연 제목의
XPath는 그리드 형태로 있기 때문에 view 하나 안에 있는 구조는 똑같다.그리드의 몇 번째 요소냐만 달라진다.
with webdriver.Chrome(service=Service(ChromeDriverManager().install())) as driver:
driver.get("https://indistreet.com/live?sortOption=startDate%3AASC")
driver.implicitly_wait(10)
#그리드 형태에서는 view 하나 안에 있는 구조는 똑같음. 그리드의 몇 번째 요소냐만 달라진다.
for i in range(1, 11): #총 10 개의 공연 제목을 스크래핑 하기 위한 반복문
element = driver.find_element(By.XPATH, '//*[@id="__next"]/div/main/div[2]/div/div[4]/div[1]/div[{}]/div/a/div[2]/p[1]'.format(i))
print(element.text)- 해당 코드를 실행하면 우리가 찾고자 했던 인디스트릿이라는 웹 페이지에 게시된
공연 이름 10 개가output으로 나오게 된다.# output Knock Live Rock band Sign up 이디어츠 1st EP 발매기념 공연 도라페스트 4탄 NO PASARAN! Vol.1 LIVE in NOV 2019 LIVE in DEC 2019 오롯한 라이브와 함께 LIVE in FEB 2020 PUNK Marathon

송의 개발 LOG