🔎 Python을 이용하여 페이지네이션 되어 있는 웹 페이지의 원하는 요소를 class 호출을 이용해서 추출해 보자.
페이지네이션(Pagination)이란?
- 많은 정보를
인덱스로 구분하는 기법.- 우리가 흔히 아는
웹 페이지의 페이지 번호를 말한다.- 대부분의 웹 페이지들이
URL?page={i}로 URL 뒤에Query String으로페이지 번호를 보낸다.

1. 추출할 데이터의 위치를 분석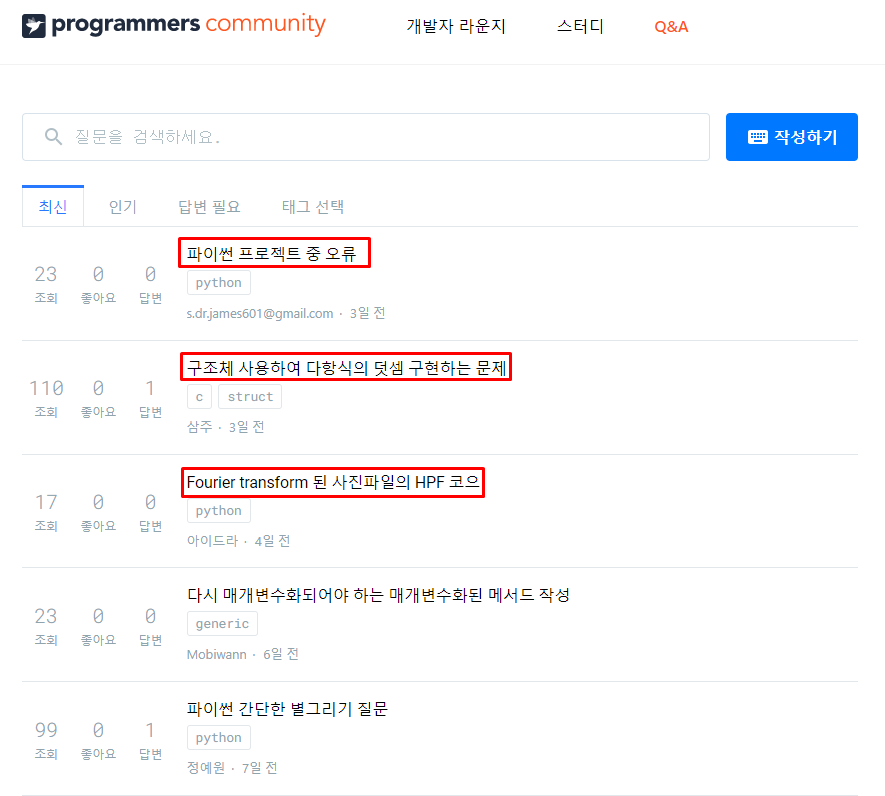
- 해당 사이트의
질문 제목들을 추출한다고 가정하였을 때검사혹은개발자 도구(F12)를 통해질문 제목의 위치를 파악한다.

- 질문들의 제목은 반복되는
li태그 중question-list-item이라는class에 포함되어 있는 것을 알 수 있으며h4의context임을 파악할 수 있다. - 또한
단 하나의 데이터가 아닌question-list-item이라는class로여러 개의 데이터가 묶여 있음을 알 수 있다. - 그렇다면 우리는
find_all을 통해class를 호출해 주고 그 안의h4.text추출해야 한다.
2. 라이브러리를 호출 후 응답을 파싱해 객체 생성
- 이전 특정 웹 페이지 원하는 요소 추출 포스트와 동일한 방식으로 진행한다.
- 이때
user_agent를 우리가 설정해서 보내 줄 수 있다. get에 두 번째 인자로user_agent의 값을 보내 주면 된다.
user_agent = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36"}
import requests
from bs4 import BeautifulSoup
# 두 번째 인자로 들어가는 것은 header
res = requests.get("https://qna.programmers.co.kr/", user_agent)
context = BeautifulSoup(res.text, "html.parser")3. 원하는 요소 class를 통해 찾기
태그 이름으로만 데이터를 추출할 경우 웹 페이지에는 같은 태그 이름이 많기 때문에 잘못된 데이터가 추출될 수도 있다.- 그래서 우리는
class나 id명을 사용하여 좀 더정확한 데이터를 추출할 수 있다. - 현재 추출하고자 하는
질문 제목 리스트의 경우li태그의question-list-item이라는class에 존재한다. - 또한
question-list-item이라는class는 하나가 아니라 여러 질문이 존재하기 때문에 여러 개이고, 이때는find_all을 사용해야 한다.
questions = context.find_all("li", "question-list-item") #먼저 find_all을 통해서 question-list-item의 리스트를 만들어 준다
for question in questions:
print(question.find("div", "question").find("div", "top").h4.text) #질문 목록의 제목만 추출해 줄 수 있도록 h4.text로 조회해 준다.-
이 코드를 통해 우리는
.find("태그 이름", "클래스명")을 내부를 타고, 타고 중첩적으로 가능하다는 것을 알 수 있다. 다만.find_all은 중첩적인 사용이 불가하다..find_all을 중첩적으로 사용할 경우,AttributeError가 발생한다.#output
4. 특정 페이지의 원하는 요소 찾기
- 각 페이지의
질문 제목을 호출하기 위해서는특정 페이지를 지정해 주어도 되고,1페이지부터 5페이지까지의 질문 제목을 추출하고 싶다면for문을 사용해 주면 된다. - 대부분의 페이지는
url안에?page=i라는Query String으로 페이지를 이동할 수 있다는 점을 이용한다.
import time #인터벌 시간을 두기 위한 호출
for i in range(1, 6): # 1페이지부터 5페이지까지의 정보만
res = requests.get("https://qna.programmers.co.kr/?page={}".format(i), user_agent) #query string의 값을 for문을 통해 1부터 5까지 보내 준다.
soup = BeautifulSoup(res.text, "html.parser")
questions = soup.find_all("li", "question-list-item")
for question in questions:
print(question.find("div", "question").find("div", "top").h4.text)
time.sleep(0.5) #0.5초의 인터벌을 준다.- 다음과 같은 코드를 실행하면
1페이지부터 5페이지까지의 질문 제목이 추출된다.

송의 개발 LOG