❄️ Snowflake에 데이터 웨어하우스 환경을 구축해 보고, 벌크 업데이트를 통해 업로드한 csv 파일을 분석해 새로운 테이블을 생성해 보자.
-
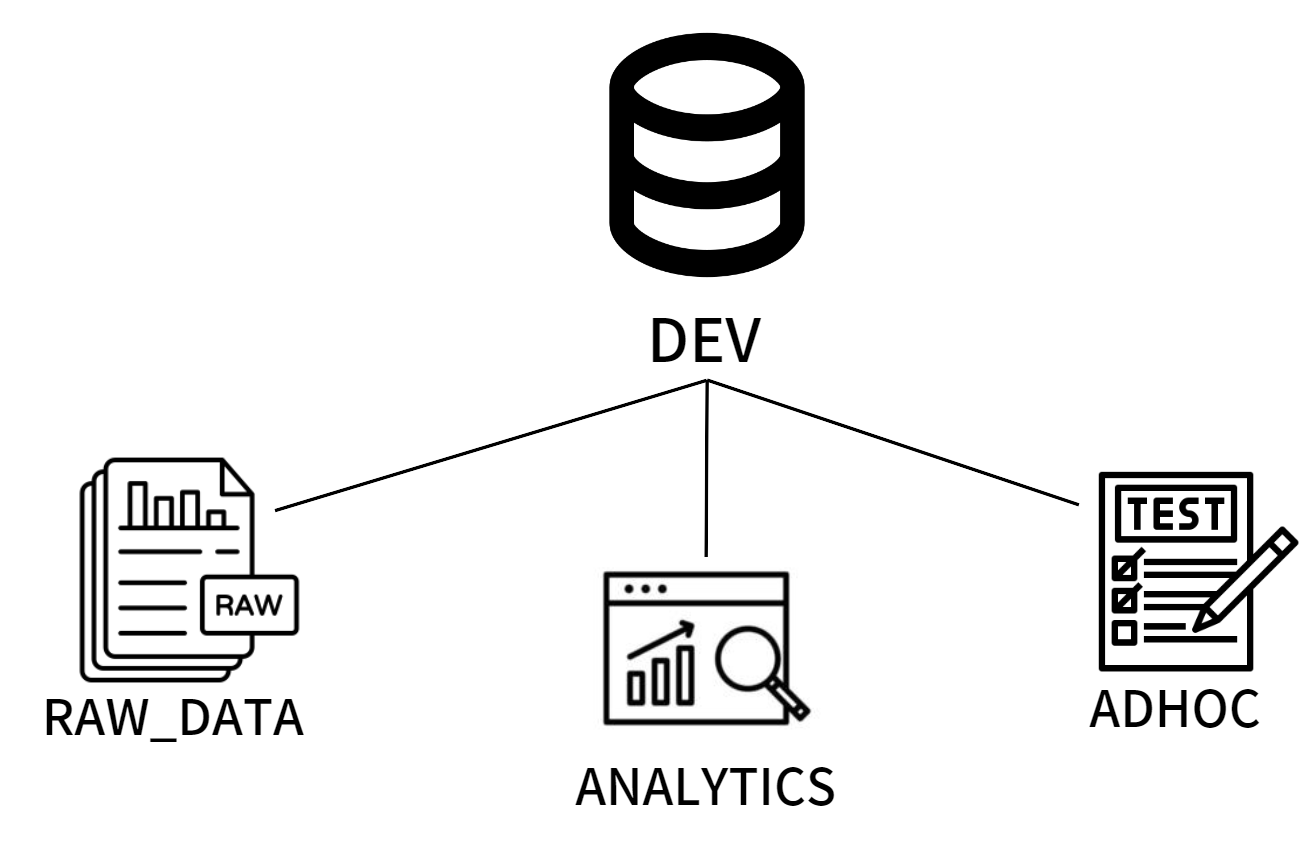
DEV라는데이터베이스안에 세 개의 스키마를 생성해 본다.RAW_DATA는ETL의 결과가 들어가는 스키마ANALYTICS는ELT의 결과가 들어가는 스키마ADHOC은 테스트용 테이블이 들어가는 스키마
-
이후 생성된
RAW_DATA스키마에S3의 csv 파일을 통해 벌크 업데이트해 테이블에 값을 추가해 본다. -
생성한
RAW_DATA스키마 테이블을 토대로ANALYTICS스키마에MAU_SUMMARY라는 월별 통계 테이블을 생성해 준다.
1. Worksheet 생성
-
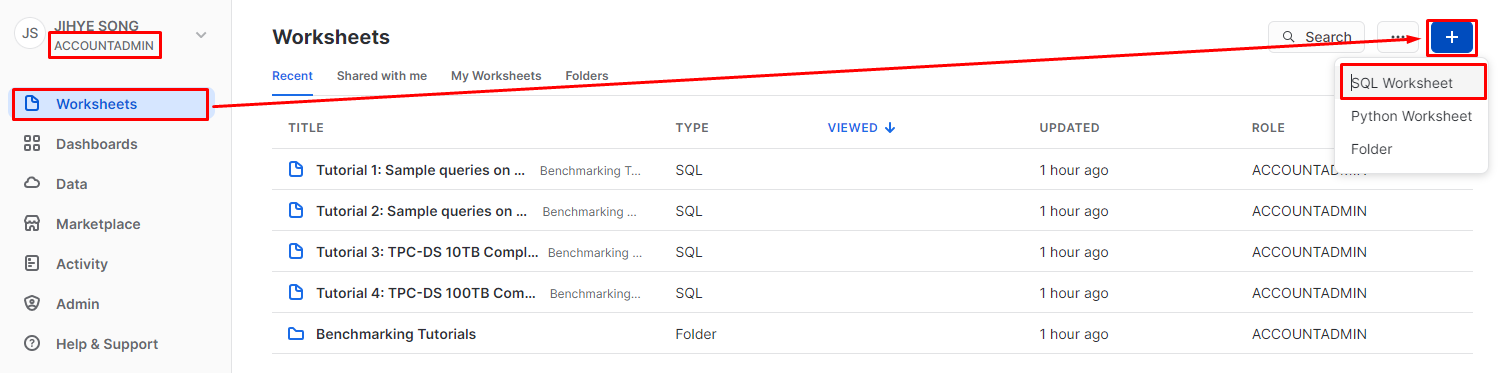
먼저
계정 권한을 확인해 준다.ACCOUNTADMIN계정이어야 모든 권한에 접근 가능하기 때문에 다음과 같이ACCOUNTADMIN으로 설정해 준다. -
이후
Worksheets의 플러스 버튼을 누르면SQL과Python기반의Worksheet를 생성할 수 있는데SQL을 통해 환경 설정을 해 줄 것이기 때문에SQL Worksheet를 선택해 준다.

-
생성된
Worksheet의 이름을 우 클릭Rename을 눌러 이름을 바꿔 준다.

-
우측 상단에 있는
Share버튼은 작성한SQL 구문을 공유할 수 있도록 해 준다. -
재생 표시 버튼은 아이콘이 있는 곳을 누르면커서위치의SQL 쿼리만 실행되며 다음과 같이 드롭 다운 버튼을 눌러Run All을 선택할 경우 전체Worksheet의SQL 쿼리를 실행할 수 있다.
2. 스키마 생성
- 먼저
스키마 (schema)생성을 위해데이터베이스(Database)를 생성해 주어야 한다.
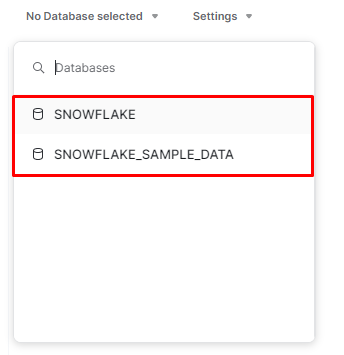
- 현재는 두 개의 default
데이터베이스(Database)만 존재한다. DEV라는데이터베이스(Database)를 생성해 준다.
CREATE DATABASE DEV;-
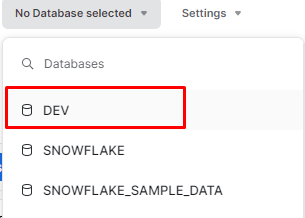
새로고침을 해 주어야 다음과 같이 목록에 생성된 데이터베이스(Database) 볼 수 있다.
-
이후 생성된
DEV를 선택해 준다. -
만약 이를 선택하지 않는다면 스키마를 생성할 때나 스키마를 조회할 때 모두
데이터베이스명.스키마명을 해 주어야 하고, 만일데이터베이스(Database)를 선택한다면 그데이터베이스(Database)안에서만 돌아가는 것임으로 따로데이터베이스명을 호출해 줄 필요 없이스키마명만 호출해 주면 된다. -
DEV라는데이터베이스안에 세 개의 스키마를 생성한다.RAW_DATAANALYTICSADHOC
-- 만일 DEV를 선택해 주지 않았다면 DEV.RAW_DATA, DEV.ANALYTICS, DEV.ADHOC으로 해 주어야 함
CREATE SCHEMA RAW_DATA;
CREATE SCHEMA ANALYTICS;
CREATE SCHEMA ADHOC;- 이후
DEV데이터베이스를 보면 다음과 같이 세 개의 스키마가 생성된 것을 확인할 수 있다.

3. RAW_DATA 세 개의 테이블 생성
-
SQL구문의CREATE를 통해 RAW_DATA 스키마 밑에 세 개의 테이블을 생성해 준다. -
Snowflake의 경우CREATE OR REPLACE TABLE구문이 있다. 해당 SQL문은 테이블을 생성하고 만약 그 테이블이 존재한다면 그 테이블을 삭제하고 새로 테이블을 생성하는 것이다. 테이블이 사용하는 테이블인지 아닌지를 확인 후에 해당 SQL문을 써 주어야 한다.
-
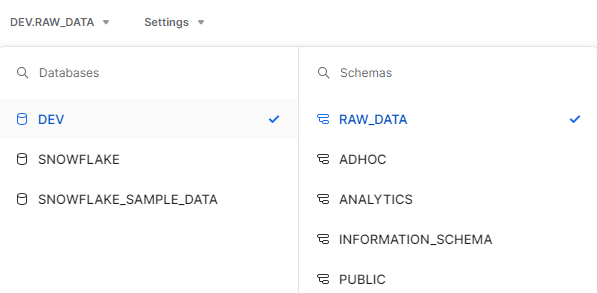
다음과 같이
DEV,RAW_DATA를 선택해 준다. 해당 단계에 선택해 주지 않아도 된다. 선택하지 않았다면DEV.RAW_DATA라고 호출해 주면 된다.
CREATE OR REPLACE TABLE USER_SESSION_CHANNEL(
USERID INTEGER
, SESSIONID VARCHAR(32) PRIMARY KEY
, CHANNEL VARCHAR(32)
);
CREATE OR REPLACE TABLE SESSION_TIMESTAMP(
SESSIONID VARCHAR(32) PRIMARY KEY
, TS TIMESTAMP
);
CREATE OR REPLACE TABLE SESSION_TRANSACTION(
SESSIONID VARCHAR(32) PRIMARY KEY
, REFUNDED BOOLEAN
, AMOUNT INT
);- 실행하게 되면 다음과 같이 좌측의
DATABASE를 통해 테이블이 생성된 것을 확인할 수 있다.

4. AWS IAM 사용자 생성
-
COPY명령문으로 벌크 업데이트를 진행하기에 앞서Snowflake가S3위치에 접근하기 위해서는AWS_KEY_ID와AWS_SECRET_KEY가 있어야 한다. -
하지만 이때
루트 사용자계정으로 노출해서는 안 된다. S3 Bucket을 읽을 수 있는 권한만을 부여한IAM 사용자를 하나 만들어 준 후 사용해야 한다.
-
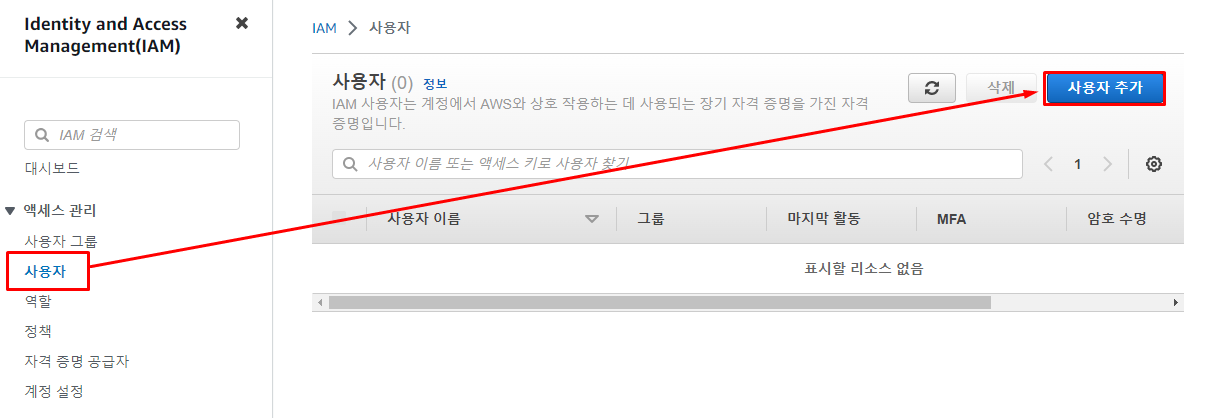
AWS IAM콘솔로 이동한 후사용자->사용자 생성을 선택해 준다.
-
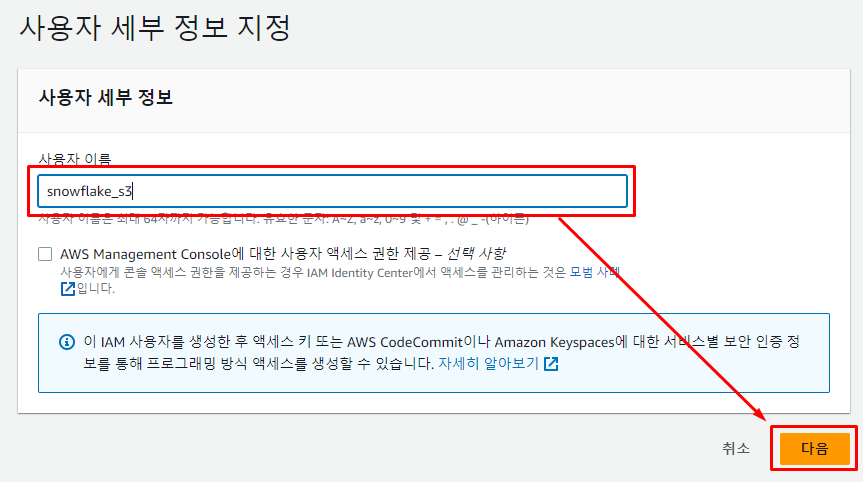
사용자의 이름을 설정해 주고
다음을 눌러 넘어가 준다.
-
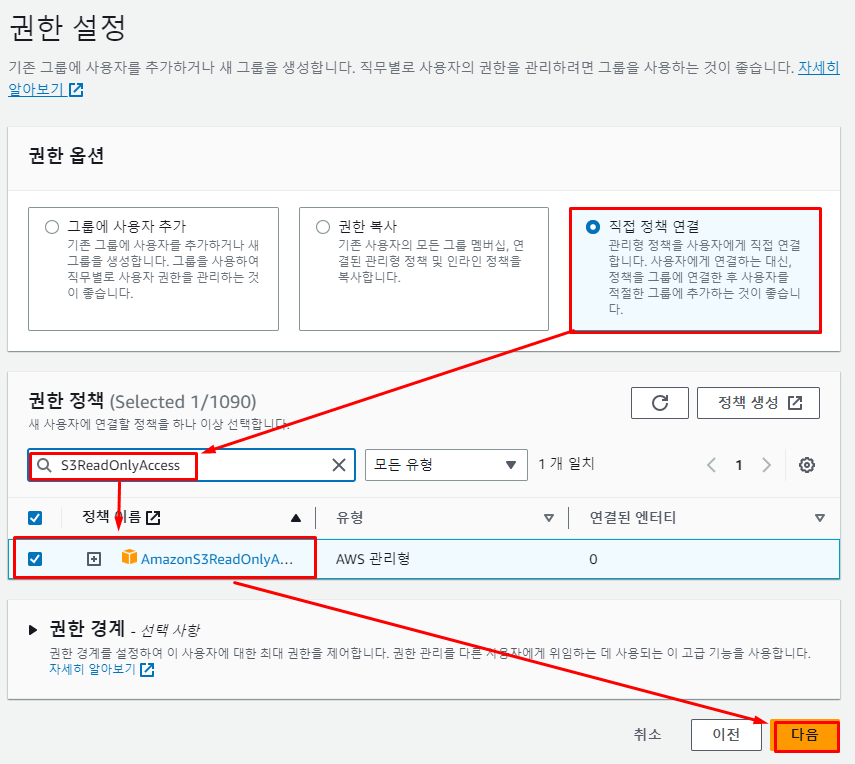
이후
S3에 대한 읽기 권한만 부여해 줄 것이기 때문에직접 정책 연결을 선택해 준 후AmazonS3ReadOnlyAccess정책을 선택해 생성해 준다.AmazonS3ReadOnlyAccess정책은S3읽기 권한만을 부여한 정책이다. -
사용자가 다음과 같이 생성이 되었다면 이제
snowflake에서 해당 사용자의AWS_KEY_ID와AWS_SECRET_KEY를 확인해야 한다.
-
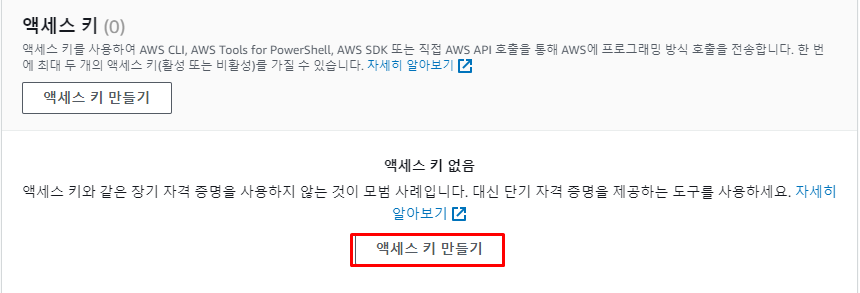
먼저 해당 사용자를 선택 후
보안 자격 증명에서Access Key를 확인한다.
-
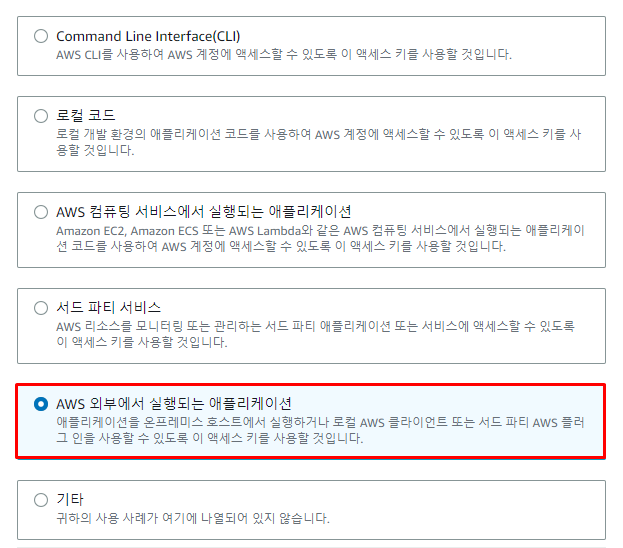
Access Key가 존재하지 않는다면 새로 생성해 준다.
-
snowflake환경에서 사용할 것이기 때문에액세스 키 모범 사례 및 대안을AWS 외부에서 실행되는 애플리케이션으로 선택해 준다. -
이후
액세스 키 생성을 누르면Access Key와Secret Access Key가 부여되며Access Key가AWS_KEY_ID가 되고,Secret Access Key가AWs_SECRET_KEY가 된다.
4. COPY를 통해 벌크 업데이트 수행
- 흡사하지만
Redshift와SQL문의 차이가 존재한다. FILE_FORMAT의 TYPE에서 input이 되는 TYPE을 작성해 주고 만약 헤더를 제외하고 싶을 때는skip_header=1을 추가해 준다.IGNOREHEADER 1과 동일한 역할을 한다.FIELD_OPTIONAALY_ENCLOSED_BY="":""로 둘러싸인 경우""는 제외하고 추출해 주는 명령어로REMOVEQUOTES와 동일한 역할을 한다.CREDENTIALS는Snowflake가FROM절에 있는 파일에 접근 권한이 있는지를 증명해 주는 부분으로AWS_KEY_ID와AWS_SECRET_KEY를 주어야 한다. 해당 부분에서는 3의 단계에서 생성해 준IAM 사용자의Access Key와Secret Access Key를 부여해 주면 된다.
COPY INTO USER_SESSION_CHANNEL
FROM 's3://songji-test-bucket/test_data_20230523/user_session_channel.csv'
credentials=(AWS_KEY_ID='Access Key' AWS_SECRET_KEY='Secret Access Key')
FILE_FORMAT = (type='CSV' skip_header=1 FIELD_OPTIONALLY_ENCLOSED_BY='"');
COPY INTO SESSION_TIMESTAMP
FROM 's3://songji-test-bucket/test_data_20230523/session_timestamp.csv'
credentials=(AWS_KEY_ID='Access Key' AWS_SECRET_KEY='Secret Access Key')
FILE_FORMAT = (type='CSV' skip_header=1 FIELD_OPTIONALLY_ENCLOSED_BY='"');
COPY INTO SESSION_TRANSACTION
FROM 's3://songji-test-bucket/test_data_20230523/session_transaction.csv'
credentials=(AWS_KEY_ID='Access Key' AWS_SECRET_KEY='Secret Access Key')
FILE_FORMAT = (type='CSV' skip_header=1 FIELD_OPTIONALLY_ENCLOSED_BY='"');
- 벌크 업데이트를 수행하면 다음과 같이 상태(status)가 LOADED임을 볼 수 있고, 모두 완료가 된 것을 볼 수 있다.
SELECT *
FROM SESSION_TRANSACTION
LIMIT 10;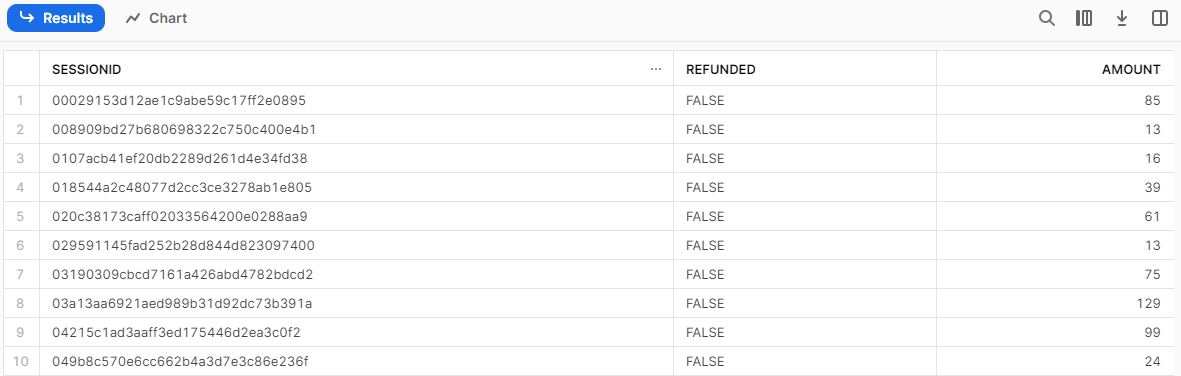
SELECT을 통해 조회해 제대로 데이터가 적재되었는지를 확인하면 다음과 같이 데이터가 들어온 것을 볼 수 있다.
5. ANALYTICS 스키마 밑에 테이블을 CTAS로 생성
RAW_DATA의SESSION_TIMESTAMP와USER_SESSION_CHANNEL을JOIN하여 월별 사용자 수를 분석한SQL문을 작성한다.- 이
SQL문을CTAS를 통해ANALYTICS스키마에MAU_SUMMARY라는 테이블을 생성해 적재해 준다.
- 상단의
데이터베이스와스키마설정을 변경해 준다. - 앞서 말했듯 해당
데이터베이스를 선택하지 않고DEV.ANALYTICS로 호출해 주어도 무관하다.
CREATE TABLE MAU_SUMMARY AS
SELECT TO_CHAR(A.TS, 'YYYY-MM') AS "MONTH"
, COUNT(DISTINCT B.USERID) AS MAU
FROM RAW_DATA.SESSION_TIMESTAMP A
JOIN RAW_DATA.USER_SESSION_CHANNEL B
ON A.SESSIONID = B.SESSIONID
GROUP BY 1
ORDER BY 1 DESC;
- 다음과 같이
DEV데이터베이스의ANALYTICS라는 스키마 밑에MAU_SUMMARY가 생성된 것을 확인할 수 있다. - 데이터가 제대로 들어갔는지를 조회해 주기 위해서는
SELECT문을 작성해 준다.
SELECT *
FROM MAU_SUMMARY
LIMIT 10;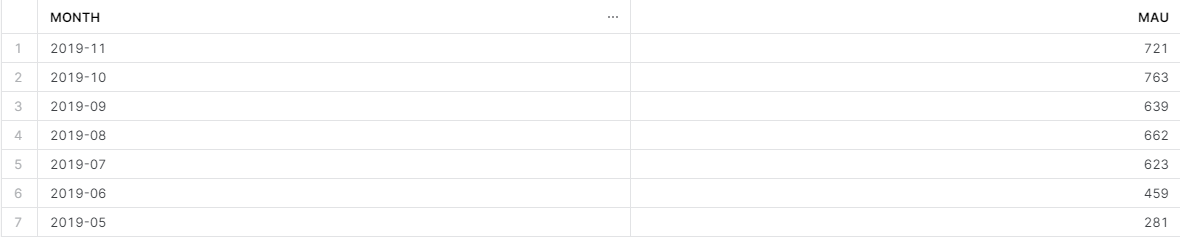
- 값이 잘 조회되는 것을 볼 수 있다.
