
본 포스트는 이수안컴퓨터연구소님의 파이토치 한번에 끝내기 PyTorch Full Tutorial Course 강의를 듣고 작성되었습니다.
파이토치(Pytorch)
- 페이스북이 초기 루아(Lua) 언어로 개발된 토치(Torch)를 파이썬 버전으로 개발하여 2017년도에 공개
- 초기에 토치(Torch)는 넘파이(NumPy) 라이브러리처럼 과학 연산을 위한 라이브러리로 공개
- 이후 GPU를 이용한 텐서 조작 및 동적 신경망 구축이 가능하도록 딥러닝 프레임워크로 발전시킴
파이토치 모듈 구조
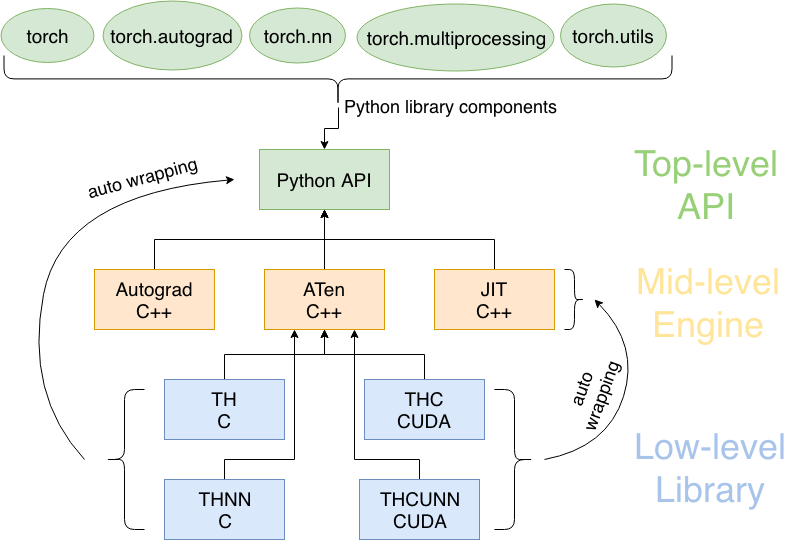
파이토치 구성요소
torch: 메인 네임스페이스, 텐서 등의 다양한 수학 함수가 포함torch.autograd: 자동 미분 기능을 제공하는 라이브러리torch.nn: 신경망 구축을 위한 데이터 구조나 레이어 등의 라이브러리torch.multiprocessing: 병럴처리 기능을 제공하는 라이브러리torch.optim: SGD(Stochastic Gradient Descent)를 중심으로 한 파라미터 최적화 알고리즘 제공torch.utils: 데이터 조작 등 유틸리티 기능 제공torch.onnx: ONNX(Open Neural Network Exchange), 서로 다른 프레임워크 간의 모델을 공유할 때 사용
1. 텐서(Tensors)
- 데이터 표현을 위한 기본 구조로 텐서(tensor)를 사용
- 텐서는 데이터를 담기위한 컨테이너(container)로서 일반적으로 수치형 데이터를 저장
- 넘파이(NumPy)의 ndarray와 유사
- GPU를 사용한 연산 가속 가능
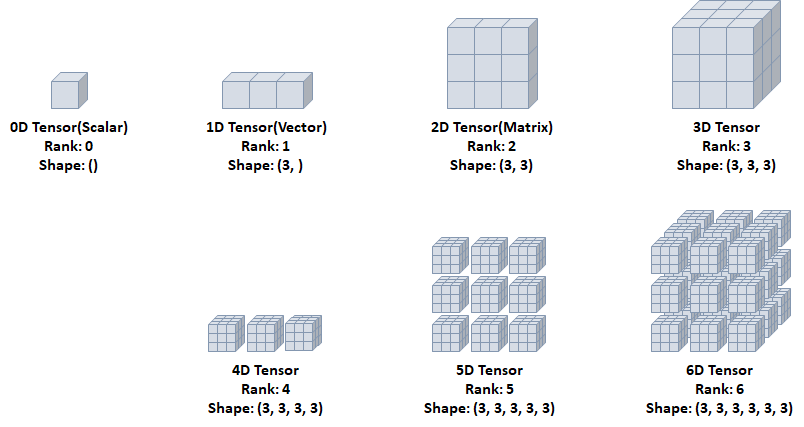
1.1 텐서 초기화와 데이터 타입
[1] 텐서 초기화
(1) 초기화 되지 않은 텐서 : torch.empty()
- 랜덤한 기존 형태 값으로 출력
x = torch.empty(4,2)tensor([[-6.1985e+32, 4.5848e-41],
[ 1.6558e+01, 0.0000e+00],
[ 4.4842e-44, 0.0000e+00],
[ 1.7937e-43, 0.0000e+00]])
(2) 무작위 초기화된 텐서 : torch.rand()
x = torch.rand(4,2)tensor([[0.1663, 0.9950],
[0.8520, 0.5015],
[0.7387, 0.0313],
[0.8601, 0.9957]])
(3) 데이터 타입이 long(정수)이며 0으로 채워진 텐서 : torch.zeros(4,2, dtype=torch.long)
- 0으로 초기화
- long type : 정수형
x = torch.zeros(4,2, dtype = long)tensor([[0, 0],
[0, 0],
[0, 0],
[0, 0]])
(4) 사용자가 입력한 값으로 텐서 초기화 : torch.tensor([3,2,3])
x = torch.tensor([3,2,3])tensor([3.0000, 2.3000])
(5) 1로 채워진 텐서 + double 타입 : x.new_ones(2,4, dtype=torch.double)
- new_ones : 1로 채워진 텐서
- double : 실수형
x = x.new_ones(2,4, dtype = torch.double)tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.]], dtype=torch.float64)
(6) 지정된 범위로 tensor 생성 : torch.arange(start, end, step)
# end만 지정
a = torch.arange(5)
# start, end 지정
a = torch.arange(2, 6)
# start, end, step 모두 지정
a = torch.arange(1, 10, 2)
tensor([0, 1, 2, 3, 4])
tensor([2, 3, 4, 5])
tensor([1, 3, 5, 7, 9])
(7) x와 같은 크기, float 타입, 무작위 텐서 : torch.randn_like()
- randn : 무작위
- like : 기존 텐서 모양과 같게
x = torch.randn_like(x, dtype = torch.float)tensor([[-0.1523, -0.0642, -0.3455, -0.2723],
[ 1.3314, 1.1569, -0.0211, 0.8774]])
(8) 텐서 크기 확인 : x.size()
print(x.size())torch.Size([2, 4])
[2] 데이터 타입
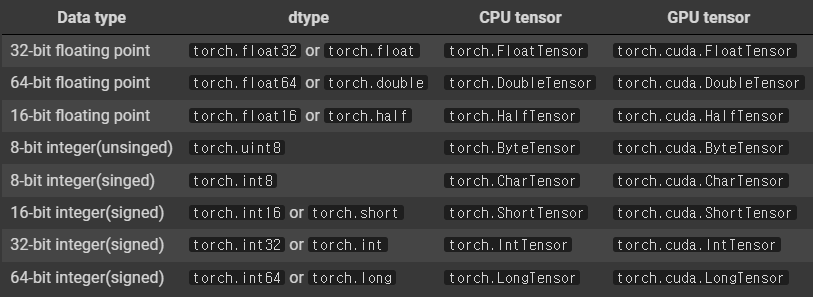
# float type
ft = torch.FloatTensor([1,2,3])
print(ft)
# type 변환
print(ft.short())
print(ft.int()) # dtype=torch.int16
print(ft.long()) # dtype=torch.int32tensor([1., 2., 3.])
tensor([1, 2, 3], dtype=torch.int16)
tensor([1, 2, 3], dtype=torch.int32)
tensor([1, 2, 3])
# int type
it = torch.IntTensor([1,2,3])
print(it)
# type 변환
print(it.float())
print(it.double()) # dtype=torch.float64
print(it.half()) # dtype=torch.float16tensor([1, 2, 3], dtype=torch.int32)
tensor([1., 2., 3.])
tensor([1., 2., 3.], dtype=torch.float64)
tensor([1., 2., 3.], dtype=torch.float16)
1.2 CUDA Tensors : device
- 텐서를 cpu, gpu 장치로 옮기기
x = torch.randn(1)
# cuda가 가능하면(is_available()) gpu, 안되면 cpu로 자동 연결
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)cuda
.to이용해서 device 보냄
# 기존 x 모양으로 1로 전부 차있는 것에 device 정의
y = torch.ones_like(x, device = device)
print(y)
# 랜덤으로 선언했던 x 텐서를 device로 보냄
x = x.to(device)
# z를 cpu로 옮기고 type은 double(float64)로 지정
z = x+y
print(z)
print(z.to('cpu', dtype = tensor.double))tensor([1.], device='cuda:0')
tensor([2.0479], device='cuda:0')
tensor([3.0479], device='cuda:0')
tensor([3.0479], dtype=torch.float64)
1.3 다차원 텐서 생성
(1) 0D Tensor (=Scalar)
- 하나의 숫자를 담고 있는 텐서
- 축과 형상 없음
t0 = torch.tensor(0)
print(t0.ndim) # 차원
print(t0.shape) # 크기
print(t0) # 실제값0
torch.Size([])
tensor(0)
(2) 1D Tensor (=Vector)
- 리스트와 유사
- 하나의 축
t1 = torch.tensor([1,2,3])
print(t1.ndim)
print(t1.shape)
print(t1)1
torch.Size([3])
tensor([1, 2, 3])
(3) 2D Tensor (=Matrix)
- 행렬 모양
- 두개의 축
- 구조 : 특성(feature) + 샘플(smaples)
- ex) 수치, 통계 데이터 셋
t2 = torch.tensor([[1,2,3],
[4,5,6],
[7,8,9]])
print(t2.ndim)
print(t2.shape)
print(t2)2
torch.Size([3, 3])
tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
(4) 3D Tensor
- 큐브(cube) 모양, 3개의 축
- 구조 : 특성(features) + 샘플(samples) + 타입스텝(timesteps)
- 연속된 시퀀스 데이터, (시간 축이 포함된)시계열 데이터에 해당
- ex) 주식 가격 데이터셋, 시간에 따른 질병 발병 데이터 등
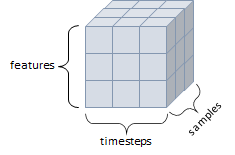
t3 = torch.tensor([[[1,2,3],
[4,5,6],
[7,8,9]],
[[1,2,3],
[4,5,6],
[7,8,9]],
[[1,2,3],
[4,5,6],
[7,8,9]]])
print(t3.ndim)
print(t3.shape)
print(t3)3
torch.Size([3, 3, 3])
tensor([[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]],
[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]],
[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]])
(5) 4D Tensor
- 4개의 축
- 컬러 이미지 데이터 (흑백은 3D Tensor로 가능)
- 구조 : 샘플(smaples) + 높이(height) + 너비(width) + 컬러 채널(channel)
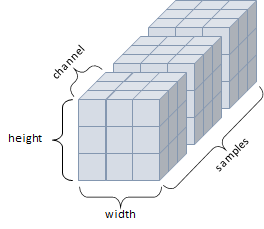
(6) 5D Tensor
- 5개의 축
- 비디오 데이터 (이미지가 연달아 있는 데이터)
- 구조 : 샘플(samples) + 프레임(frames) + 높이(height) + 너비(width) + 컬러 채널(channel)
1.4 텐서의 연산 (Operations)
- 텐서에 대한 수학 연산, 삼각함수, 비트 연산, 비교 연산, 집계 등 제공
(1) math
import math
a = torch.rand(1,2) * 2 - 1torch.abs(a): 절댓값torch.ceil(a): 반올림torch.floor(a): 반내림torch.clamp(a, -0.5,0.5): 최대최소를 찝어버린다 (clamp)
=> tensor([[0.5000, 0.5000]])torch.min(a): 최소torch.max(a): 최대torch.mean(a): 평균torch.std(a): 분산torch.prod(a): 곱torch.unique(torch.tensor([1,2,3,1,2,2])): 종류
=> tensor([1, 2, 3])
(1.1) dim 인자(max,min) : argmax,argmin 리턴
- argmax : 최대값을 가진 인덱스
- argmin : 최소값을 가진 인덱스
x = torch.rand(2,2)
print(x)
print(x.max(dim = 0)) # dim=0 : 열 기준 , max() : 더 큰 인덱스
print(x.min(dim = 1)) # dim=1 : 행 기준 , max() : 더 큰 인덱스 tensor([[0.7574, 0.0808],
[0.0846, 0.1804]])
torch.return_types.max(
values=tensor([0.7574, 0.1804]),
indices=tensor([0, 1]))
torch.return_types.max(
values=tensor([0.7574, 0.1804]),
indices=tensor([0, 1]))
(2) torch.연산
x = torch.rand(2,2)
y = torch.rand(2,2)-
torch.add(x,y): 덧셈 -
torch.sub(x,y): 뺄셈 -
torch.mul(x,y): 곱셈 -
torch.div(x,y): 나눗셈 -
torch.mm(x,y): 내적
## 내적 예시
print(x)
print(y)
print(torch.matmul(x,y))
z = torch.mm(x,y)
print(z)
print(torch.svd(z)) # U,S,V 로 기존의 행렬 값을 분해tensor([[0.7431, 0.2229],
[0.9548, 0.4806]])
tensor([[0.8347, 0.3137],
[1.3998, 0.7706]])
tensor([[0.9323, 0.4049],
[1.4698, 0.6699]])
tensor([[0.9323, 0.4049],
[1.4698, 0.6699]])
torch.return_types.svd(
U=tensor([[-0.5326, -0.8464],
[-0.8464, 0.5326]]),
S=tensor([1.9084, 0.0154]),
V=tensor([[-0.9120, -0.4101],
[-0.4101, 0.9120]]))(3) 결과 텐서 인자로 제공하는 법
result = torch.empty(2,4)
torch.add(x,y, out = result)
print(result)
(4) in-place : 텐서 값 변경
- 연산 뒤에 "_" 붙이기
- `x.copy_(y)
x.t_()
print(x)
print(y)
y.add_(x) # _ : inplace => 'x 더한 값'을 y로 다시 지정
print(y)tensor([[0.7431, 0.2229],
[0.9548, 0.4806]])
tensor([[0.0917, 0.0908],
[0.4450, 0.2899]])
tensor([[0.8347, 0.3137],
[1.3998, 0.7706]])1.5 텐서의 조작 (Manipulations)
(1) 인덱싱(Indexing)
- numpy 형태로 사용 가능
## 텐서의 특정 위치 값 가져오는 법
x = torch.Tensor([[1,2],
[3,4]])
print(x)
# 행렬 위치로 값 추출
print(x[0,0])
print(x[0,1])
print(x[1,0])
print(x[1,1])
# 슬라이싱
print(x[:,0]) # 행은 다 선택하면서 0번째 컬럼 선택
print(x[:,1])
print(x[0,:]) # 열을 슬라이싱하고 행을 선정
print(x[1,:])tensor([[1., 2.],
[3., 4.]])
tensor(1.)
tensor(2.)
tensor(3.)
tensor(4.)
tensor([1., 3.])
tensor([2., 4.])
tensor([1., 2.])
tensor([3., 4.])
(2) 텐서의 크기(size)나 모양(shape) 변경 : view
view
- 변경 전,후 텐서 안 원소 개수 유지되어야함
- -1 설정 시, 계산 통해 해당 크기 값 유추
x = torch.randn(4,5)
y = x.view(20) # 20개가 나열된 형태로 변경되어 출력
z = x.view(5,-1) # 행 5개, -1 : 나머지는 알아서 계산해서 넣어 # 5,4로 출력됨tensor([[ 0.1870, 0.6372, 0.2561, -1.3911, 0.8974],
[ 0.8734, 0.5315, -0.4903, -0.4616, -0.3950],
[ 0.4581, -0.1911, -1.6286, 0.5659, -1.8072],
[-1.9535, 0.2897, -0.4601, 0.5018, 1.1456]])
tensor([ 0.1870, 0.6372, 0.2561, -1.3911, 0.8974, 0.8734, 0.5315, -0.4903,
-0.4616, -0.3950, 0.4581, -0.1911, -1.6286, 0.5659, -1.8072, -1.9535,
0.2897, -0.4601, 0.5018, 1.1456])
tensor([[ 0.1870, 0.6372, 0.2561, -1.3911],
[ 0.8974, 0.8734, 0.5315, -0.4903],
[-0.4616, -0.3950, 0.4581, -0.1911],
[-1.6286, 0.5659, -1.8072, -1.9535],
[ 0.2897, -0.4601, 0.5018, 1.1456]])(3) 실제값 출력 : item
- 단, 스칼라 값이 하나만 존재해야 사용 가능 (2개 이상부터 에러)
item
x = torch.randn(1)
print(x)
print(x.item())
print(x.dtype)tensor([-1.7272])
-1.7272114753723145
torch.float32
(4) 차원 축소(제거) : squeeze
tensor = torch.rand(1,3,3)
print(tensor.shape)
t = tensor.squeeze()
print(t.shape) torch.Size([1, 3, 3])
torch.Size([3, 3]) ## 차원이 축소됨
(5) 차원 증가(생성) : unsqueeze
- dim 인자
- unsqueeze(dim=0) : 첫번째 차원을 기준으로 차원 증가
- unsqueeze(dim=1) : 뒤에 추가해서 차원 증가
tensor = torch.rand(3,3)
print(tensor.shape)
t = tensor.unsqueeze(dim=0)
print(t.shape)torch.Size([3, 3])
torch.Size([1, 3, 3]) #첫번째 차원을 기준으로 차원이 증가됨
(6) 텐서 결합 : stack, cat
stack
x = torch.FloatTensor([1,4])
y = torch.FloatTensor([2,5])
z = torch.FloatTensor([3,6])
# 텐서 결합
print(torch.stack([x,y,z]))tensor([[1., 4.],
[2., 5.],
[3., 6.]])
cat
- 텐서를 결합하는 메소드(concat)
- 넘파이의
stack과 유사하지만 쌓을dim존재 - 해당 차원을 늘려준 후 결합
- 차원 기준 텐서 결합 (첫번째 차원)
a = torch.randn([1,3,3])
b = torch.randn([1,3,3])
## 차원 기준 텐서 결합 (첫번째 차원)
c = torch.cat((a,b), dim = 0) # dim=0 : 첫번째 차원을 기준으로 결합
print(c)
print(c.size()) # 결과 : torch.Size([2, 3, 3])tensor([[[ 1.7086, 1.7309, 1.4096],
[ 0.0378, -0.8366, 1.3575],
[ 0.7722, -0.5331, -0.2113]],
[[-0.3134, 1.9430, 1.1301],
[ 0.3056, 1.4749, 1.5296],
[ 0.7489, 0.9423, 0.2366]]])
torch.Size([2, 3, 3])- 차원 기준 텐서 결합 (두번째 차원)
c = torch.cat((a,b), dim=1) # dim=1 : 두번째 차원을 기준으로 결합
print(c)
print(c.size()) # 결과 : torch.Size([1, 6, 3])tensor([[[ 1.7086, 1.7309, 1.4096],
[ 0.0378, -0.8366, 1.3575],
[ 0.7722, -0.5331, -0.2113],
[-0.3134, 1.9430, 1.1301],
[ 0.3056, 1.4749, 1.5296],
[ 0.7489, 0.9423, 0.2366]]])
torch.Size([1, 6, 3])- 차원 기준 텐서 결합 (세번째 차원)
c = torch.cat((a,b), dim=2) # dim=2 : 세번째 차원을 기준으로 결합
print(c)
print(c.size()) # 결과 : torch.Size([1, 3, 6])tensor([[[ 1.7086, 1.7309, 1.4096, -0.3134, 1.9430, 1.1301],
[ 0.0378, -0.8366, 1.3575, 0.3056, 1.4749, 1.5296],
[ 0.7722, -0.5331, -0.2113, 0.7489, 0.9423, 0.2366]]])
torch.Size([1, 3, 6])(7) 텐서를 여러 개로 나누기 : chunk, split
chunk
- 몇개로 나눌 것인가? 정의
tensor = torch.rand(3,6)
print(tensor)
t1,t2,t3 = torch.chunk(tensor, 3, dim=1)
# 첫번쨰 차원을 기준으로 3개로 나눔
print(t1)
print(t2)
print(t3)tensor([[0.5286, 0.2108, 0.0335, 0.2943, 0.8410, 0.4693],
[0.3923, 0.1196, 0.1436, 0.3561, 0.2415, 0.0414],
[0.9088, 0.4601, 0.1271, 0.7551, 0.6036, 0.3934]])
tensor([[0.5286, 0.2108],
[0.3923, 0.1196],
[0.9088, 0.4601]])
tensor([[0.0335, 0.2943],
[0.1436, 0.3561],
[0.1271, 0.7551]])
tensor([[0.8410, 0.4693],
[0.2415, 0.0414],
[0.6036, 0.3934]])split
- 텐서의 크기는 몇인지 물어본 후, 그에 맞춰 나눔
tensor = torch.rand(3,6)
t1, t2 = torch.split(tensor, 3, dim=1)
print(tensor)
print(t1)
print(t2)tensor([[0.0883, 0.4678, 0.1435, 0.6052, 0.9097, 0.4505],
[0.3931, 0.1826, 0.0384, 0.2358, 0.7419, 0.0266],
[0.3956, 0.3721, 0.3204, 0.4135, 0.3338, 0.3091]])
tensor([[0.0883, 0.4678, 0.1435],
[0.3931, 0.1826, 0.0384],
[0.3956, 0.3721, 0.3204]])
tensor([[0.6052, 0.9097, 0.4505],
[0.2358, 0.7419, 0.0266],
[0.4135, 0.3338, 0.3091]])