
본 포스트는 이수안컴퓨터연구소님의 파이토치 한번에 끝내기 PyTorch Full Tutorial Course 강의를 듣고 작성되었습니다.
Autograd(자동미분)
torch.autograd패키지는 Tensor의 모든 연산에 대해 자동 미분 제공- 이는 코드를 어떻게 작성하여 실행하느냐에 따라 역전파가 정의된다는 뜻
backprop를 위해 미분값을 자동으로 계산
1. 연산 추적(기록) : requires_grad
requires_grad
-
속성을
True로 설정하면, 해당 텐서에서 이루어지는 모든 연산들을 추적 시작 -
기본 텐서의 gradient값은
False
a = torch.randn(3,3)
a = a * 3
print(a)
print(a.requires_grad)tensor([[-3.4160, -4.7597, 1.9489],
[ 0.4322, 0.9619, 1.0409],
[ 3.0706, -1.8473, 2.5310]])
Falserequires_grad_(True)
- gradient 값을 True로 변경해야 추적 시작
- requiresgrad()
- 기존 텐서의 requires_grad값을 바꿔치기(in-place)하여 변경
a.requires_grad_(True)grad_fn
- 미분값을 계산한 함수에 대한 정보 저장
- backpropagation 할 때 어떤 연산을 했는지, 어떤 함수에 대해 진행했는지 기록을 저장
b = (a * a).sum() # 결과 : a*a 결과 값 모두 합친 값 한 개
print(b)
print(b.grad_fn)tensor(59.5639, grad_fn=<SumBackward0>) # sum 이라는 연산을 했음을 기록
<SumBackward0 object at 0x7fce31cd6190>2. 기울기(Gradient)
(1) gradient 추적하는 과정 살펴보기
- 연산 정보 추적할 수 있도록 requires_grad = True 지정
x = torch.ones(3,3, requires_grad = True) # 연산 정보 추적할 수 있게 True로 지정
print(x)tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]], requires_grad=True)- 연산 추가
- add 연산 추가
y = x + 5 # grad_fn=<AddBackward0>
print(y)tensor([[6., 6., 6.],
[6., 6., 6.],
[6., 6., 6.]], grad_fn=<AddBackward0>)- Mul, mean 연산 추가
z = y * y # grad_fn=<MulBackward0>
out = z.mean() # grad_fn=<MeanBackward0>
print(z, out)tensor([[36., 36., 36.],
[36., 36., 36.],
[36., 36., 36.]], grad_fn=<MulBackward0>)
tensor(36., grad_fn=<MeanBackward0>)- 역전파 계산 :
.backward()
.backward(): 역전파 계산
print(out)
out.backward()tensor(36., grad_fn=<MeanBackward0>)
- 미분값 저장 :
.grad
- data가 거쳐온 layer에 대한 미분값 저장
print(x) # x의 원래 값
print(x.grad) # x의 미분 값 출력tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]], requires_grad=True)
tensor([[1.3333, 1.3333, 1.3333],
[1.3333, 1.3333, 1.3333],
[1.3333, 1.3333, 1.3333]])다른 예시
x = torch.randn(3, requires_grad=True)
y = x * 2
while y.data.norm() < 1000:
y = y * 2
print(y)tensor([-393.4280, 1086.7229, 68.0228], grad_fn=<MulBackward0>)
v = torch.tensor([0.1, 1.0, 0.0001], dtype = torch.float)
y.backward(v) # v를 기준으로 backward
print(x.grad) # v 텐서를 기준으로 변경해줌tensor([2.0480e+02, 2.0480e+03, 2.0480e-01])
(2) 기울기 업데이트 중지 : with torch.no_grad()
- 기록을 추적하는 것을 방지하기 위해 코드 블럭을 with torch.no_grad()로 감싸면 기울기 계산은 필요없지만
- requires_grad=True로 설정되어 학습 가능한 매개변수를 갖는 모델을 평가(evaluate)할 때 유용
print(x.requires_grad) # true/false 출력 (현재는 True 상태)
print((x**2).requires_grad) # 제곱에 대해 출력
with torch.no_grad(): # with로 감싼 코드에서는 기울기 계산 하지 않음
print((x**2).requires_grad) # Flase가 출력됨True
True
False
(3) 기록을 추적하는 것을 중단 : .detach()
- 연산기록으로부터 분리
require_grad가 다른 새로운 Tensor를 가져올 때
print(x.requires_grad) # True 상태
y = x.detach() # x를 detach한 것을 y로 지정
print(y.requires_grad) # False 출력됨
print(x.eq(y).all()) # x.eq(y) : x=y?True
False
tensor(True)
3. 자동 미분 흐름 예제
- 계산 흐름
a→b→c→out
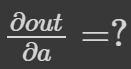
backward()를 통해 a←b←c←out 을 계산하면 ∂out/∂a 값이a.grad에 채워짐

[Data Science] 차근차근 쌓아나가는