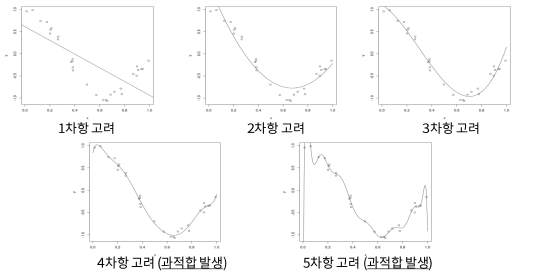
1. 과적합이란
-모델이 train 데이터에 지나치게 적응되어 그 외 데이터에는 대응하지 못하는 상태.
EX) 아래와 같은 회귀 문제에서, 두번째 모델이 최적의 모델이다
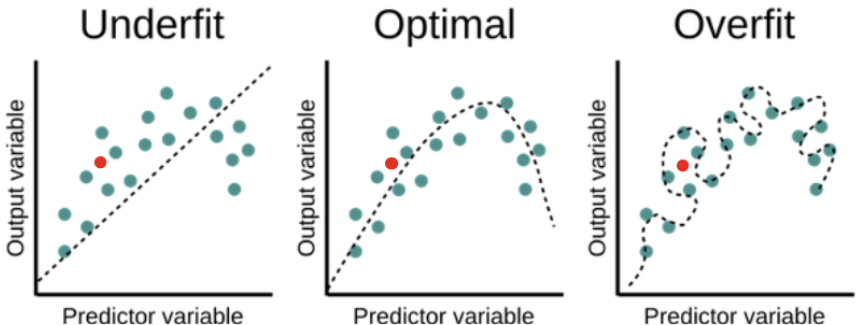
1. 첫번쨰 모델 : 과소적합(Underfitting), 주어진 데이터를 아직 제대로 반영하지 못함.
2. 두번쨰 모델 : 우리가 원하는 모델!
3. 세번째 모델 : 과대적합(Overfitting), 새로운 데이터에는 적용할 수 없는 일반화하기 어려운 경우.
- 여기서 빨간 점(data)과 점선(모델이 예측한 결과)의 거리가 가장 가까운 모델은 두번째 모델이다.
- 모든 input 데이터에 대해 오차가 존재하지만, 두번째가 가장 데이터 분포와 경향 잘 나타내고 있음.
- 과적합된 세번째 모델은, 기존 데이터들은 오차 없이 잘 표현했지만, 새로운 데이터(빨간점)가 주어지자 오히려 예측한 값의 오차가 더 크게 나타남.
- 모델의 성능은 곧 일반화 성능을 말한다고도 볼 수 있음.
2. 과적합이 일어나는 이유
아주 다양하지만, 주로 두가지 경우에 발생한다.
1. 상대적으로 데이터 수가 적은데 비해 feature(-> parameter)가 많고 표현력이 높은 모델의 경우
2. train 데이터가 적은 경우 (상대적으로 feature -> parameter가 많은 데 비해)
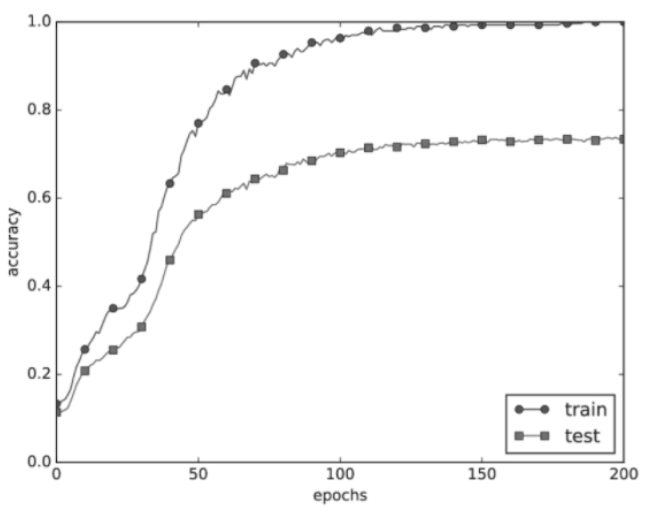
- train에 과적합된 eccuracy 그래프
- train에 비해 test 성능이 낮고 그 차이가 크면 과적합 발생한 것.
3. 과적합을 방지하는 법
Overfitting 해결법
- input 데이터 늘리기
- feature의 개수를 줄이기
- 주요 feature를 직접 선택하고 버림
- model selection algorithm을 사용
- 규제(Regularization)
- 각 feature마다 페널티(규제)를 부여해 그 영향력을 조정하는 것
- 모든 feature를 사용하되, parameter(θ)의 값을 줄인다.
정규화, 표준화, 정칙화(규제) 차이
1. 정규화(Nomalization)
: 데이터의 분포가 정규분포에 가깝게 만드는 것.
: 범위(scale)를 0~1 사이 값으로 바꿈
2. 표준화(Standardization)
: 데이터가 표준 정규분포에 가깝게 만드는 것.
: 평균이 0, 분산이 1 되도록 scaling
3. 정칙화/규제 (Regularization)
: 오버피팅 방지를 위해 weight에 penalty 부여하는것.
4. 규제 (Regularization)
: 모델이 가질 수 있는 파라미터 값에 제약을 부여해 과적합을 방지하는 방법론
1. 가중치 감소
- 모델의 학습 과정에서 가중치에 페널티(규제) 부여함으로써 과적합 방지하는 방법
- 가중치 W가 클수록 더 큰 페널티를 부과 -> 해당 input x에 대해 지나치게 fit하지 않도록 조절
- 이때 페널티를 얼마나 부과할 것인지 계산 하는 방법 L1 or L2 규제
-
L1 규제 (Lasso)
: 가중치의절댓값에 비례하는 비용 추가
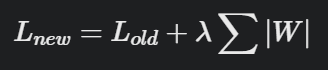
-
L2 규제 (Ridge)
: 가중치제곱에 비례하는 비용 추가
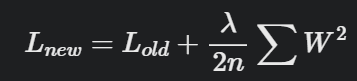
- L : 손실함수(loss function), ㅅ는 규제 강도(Regularization Strength)
- 즉, 규제 정도를 결정하는 하이퍼파라미터 의미
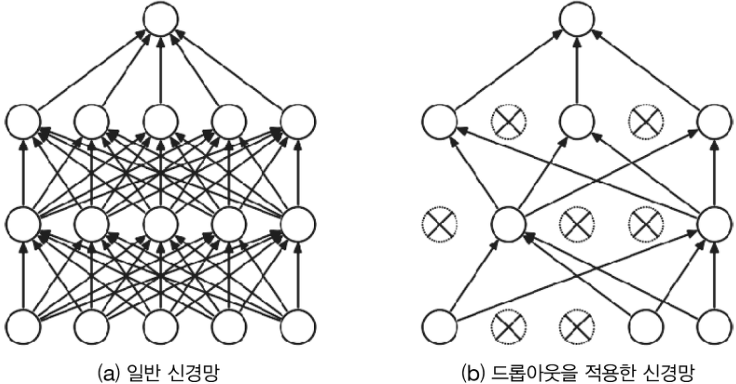
2. 드롭아웃 (Dropout)
- 뉴런을 임의로 삭제하며 학습하는 방법
- train 하면서 무작위로 은닉층(Hidden layer)의 뉴런을 골라 배제하고, 다음 layer로 신호를 전달하지 못하도록 하는 것.
Reference

[Data Science] 차근차근 쌓아나가는