1. K-NN 알고리즘이란?
-
K-최근접 이웃 (K-NN, K-Nearest Neighbot) 알고리즘
-
분류 (Classification)
-
지도학습
-
비슷한 특성을 가진 데이터는 비슷한 범주에 속하는 경향이 있다는 가정
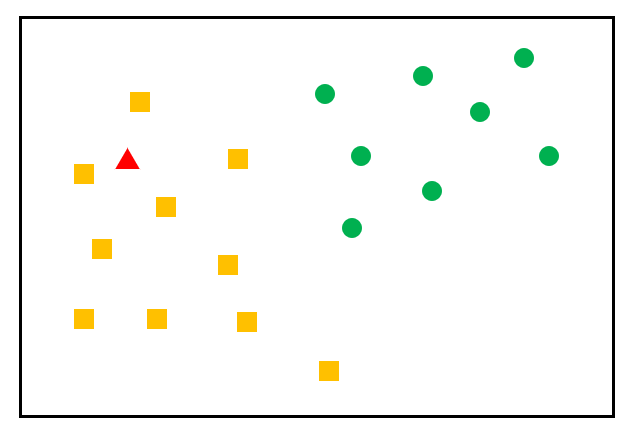
-
주변의 가장 가까운 K개의 데이터를 보고 데이터가 속할 그룹을 판단하는 알고리즘
-
가장 가까운 속성에 따라 분류하여 레이블링을 하는 알고리즘
[장점]
- 단순, 구현 쉬움, 빠름
[단점]
- 모델을 생성하지 않기 때문에
- 특징과 클래스 간 관계 이해에 제한적
- 모델 결과로 해석하는게 아닌, 미리 변수와 클래스 간 관계 파악해 알고리즘에 적용해야 원하는 경과 얻으 수 있음
- 적절한 k의 선택이 필요
- 데이터가 많아지면 분류 단계가 느림
2. 거리 기반 분류분석 모델
- K-NN 알고리즘은 새로운 데이터로부터 거리가 가까운 K개의 다른 데이터의 레이블(속성)을 참고하여 K개의 데이터 중 가장 빈도 수가 높게 나온 데이터의 레이블로 분류
거리 측정 방법
1) 유클리드 거리 (Euclidean Distance) : L2 Distance
- 2차원 평면에 서로 다른 두 점 A(x1, y1)와 B(x2, y2)가 있을 때
- 이 둘의 거리 d는 유클리드 거리 계산법에 의해 다음과 같이 나온다.
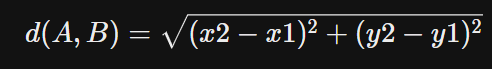
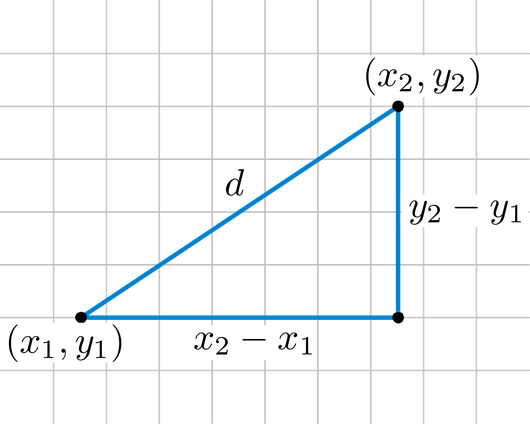
2) 맨해튼 거리 (Mangattan Distance) : L1 Distance
- 유클리드 공식처럼 직선으로 이동할 수 없는 건물들이 많은 지역의 거리 재기 위해 탄생한 공식
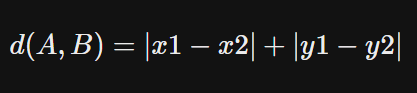
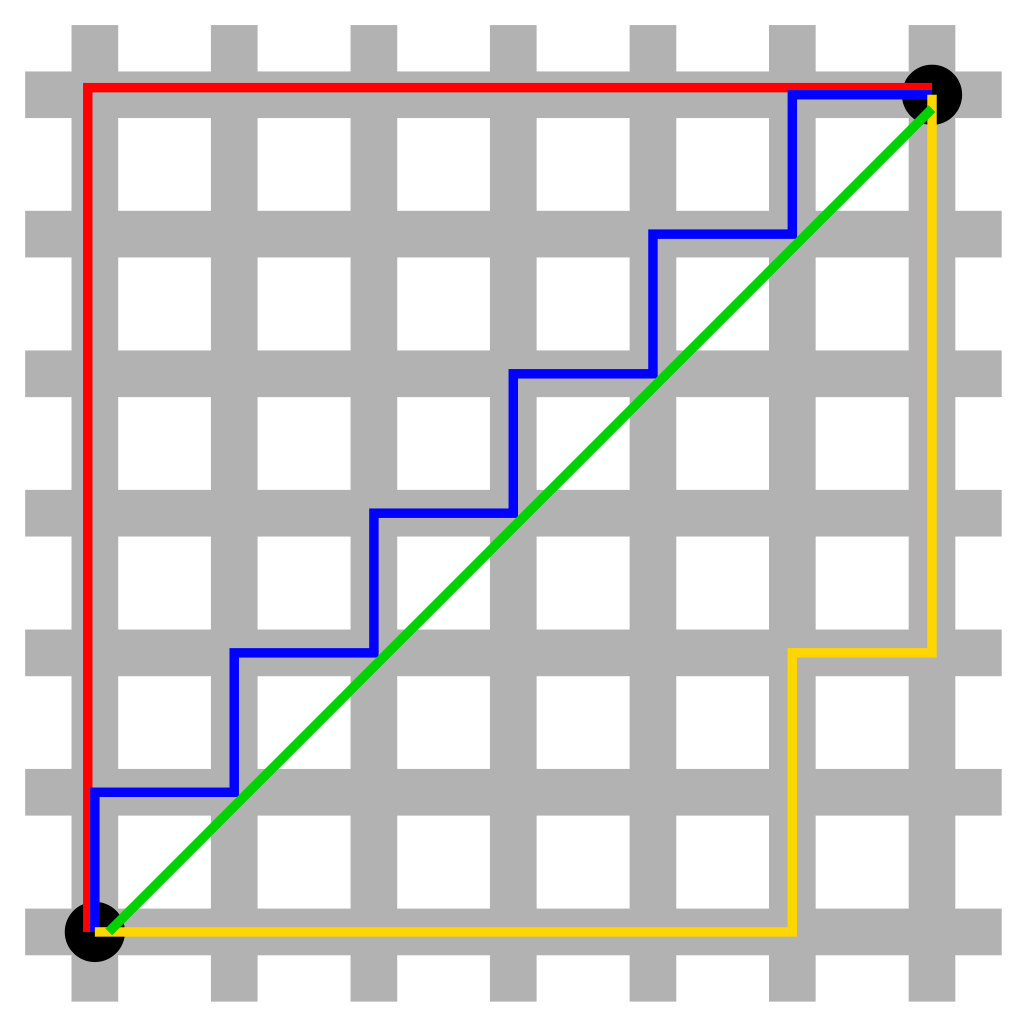
초록색직선 : 유클리드 거리- 나머지 색 선 : 맨해튼 거리 => 모두 총 거리가 동일
3. K-NN 알고리즘 원리
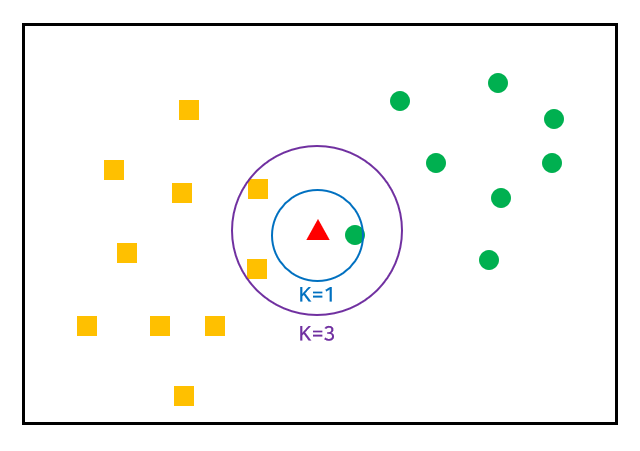
- K 값에 따라 분류가 달라짐
- K는 홀수 설정이 좋으며, 최선의 K 선택하는데 일반적으로 총 데이터 수의 제곱근 값 사용

[Data Science] 차근차근 쌓아나가는