이 글은 딥러닝 호형님의 딥러닝 전체 흐름보기 강의를 바탕으로 작성되었습니다.
1. 머신러닝 학습 방법
- 지도 학습 (supervised learning)
- 비지도 학습 (Unsupervised learning)
- 강화학습 (Reinforcement learning)
2. 딥러닝
[ 딥러닝 전체 흐름 ]
- 문제 이해/Data 처리
- 학습 데이터 생성
- 모델 결정
- 모델 구축
- 예측값 산출
- Loss 계산
- parameter 업데이트
- 최적화
1. 문제 이해 : 무엇을 생각해야 하나?
- 원하는
타겟이 무엇인가?- ex) 주가 예측, 불량 검출, 패션 디자인 등
- 데이터는 어떻게 생겼는가?
- ex) 데이터 구조, 타입, 실시간, 크기 등
딥러닝이 꼭 필요한가?- 딥러닝은 만능이 아니다.
- 왜 예측이 잘되는지 설명이 어려움
- 성능 위주로 정확도로만은 받아들일 수 없음
- 오버헤드가 아닌지?
1.2 데이터 처리 : 어떻게 가공?(Feature Engineering)
- 예측
방해 요소 확인- 결측값, 중복값, 오류, 오차, 다변수 등
- background knowledge가 필요 (+ 도메인 지식)
데이터 구조 및 분포분석- ex) 통계분석 - 상관관계, 히스토그램, 가설검증 등
데이터 가공- ex) Outlier 제거
- feature selection, 변수 생성
- scaling(Nomalization, minmax scaler, low sclaing...) 등
데이터 형태 변환- ex) labeling, one-hot-encoding(0,1로만 이루어짐) 등
- ex) 년도,나이대를 0,1,2 등 그룹으로 묶기
- 특정 class 잡아주기
2. 학습 데이터 생성 : 샘플링
편향 방지- 특정 데이터로 편중되어선 안됌.
- Cheating 금지
test 데이터와 중복금지
충분한데이터 양샘플링 종류선택- ex) 기본 random / under / stratified sampling 등
- under sampling : calss 중 가장 적은 데이터를 기준으로 똑같은 개수로 뽑아 학습 데이터로 만듬
- stratified sampling(추가 추출법) : 가지고 있는 데이터가 모집단이라 할때, 모집단의 class 비율과 똑같이 학습 데이터 만듬
- 데이터 분할
- Train vs Test
- Train. vs Validation. vs Test
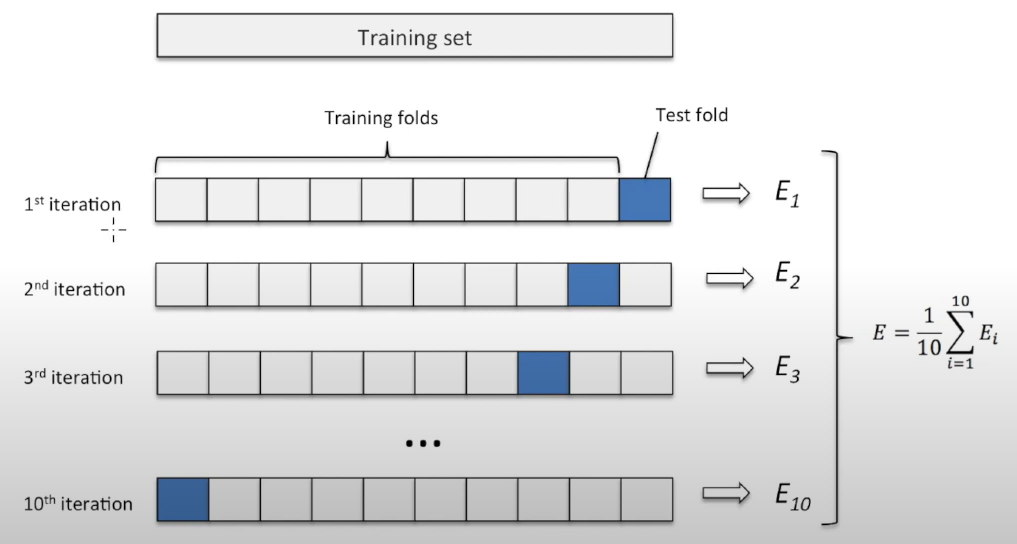
- Cross Validation
3. 모델 결정 : (NN, CNN, RNN, GAN...)
-
어떤 종류의 문제인가?- regression, Classification, Clustering(비지도) 등...
-
무엇을 최적화할 것인가?- ex) 예측 시간 단축, 정확도 등 최적화의 목적 확인
-
데이터가
얼마나 큰가?- GPU 연산 유무, 하드웨어 성능 확인
-
모델 종류
- CNN
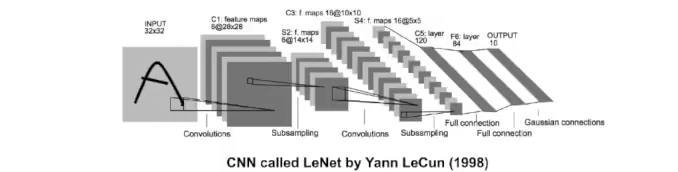
- 이미지, 자연어 처리 등
- RNN
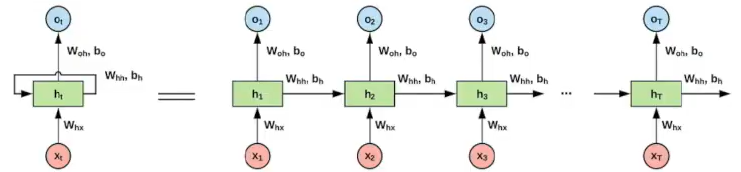
- 시계열 데이터
- GAN
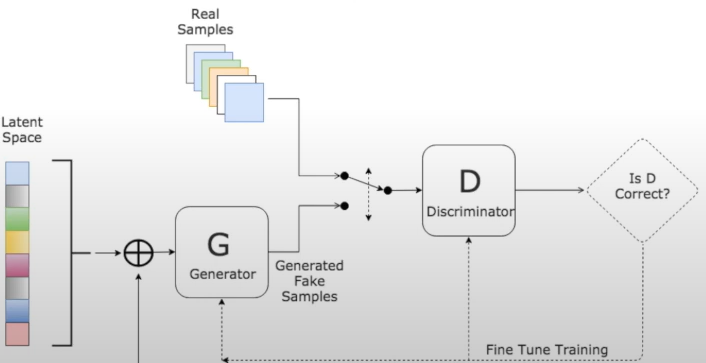
- latent space로 가짜 데이터를 만들어 가짜/진짜 구별 안되게 학습
- AutoEncoder
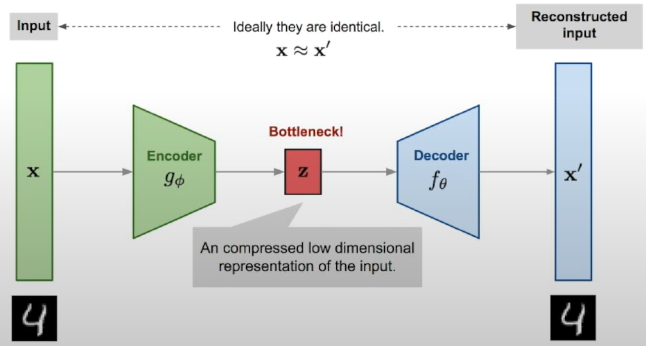
- 비지도 학습
- 레이블링이 없고 데이터를 넣으면 레이어를 거쳐 원본과 유사하게 데이터를 생성하는 모델
- CNN
4. 모델 구축
epoch,mini batch- batch : data 1조각, train 데이터를 n 조각으로 쪼개 한조각씩 넣어줌.
- epoch : 학습 횟수
layer,Node,filter등 (수,크기 지정)
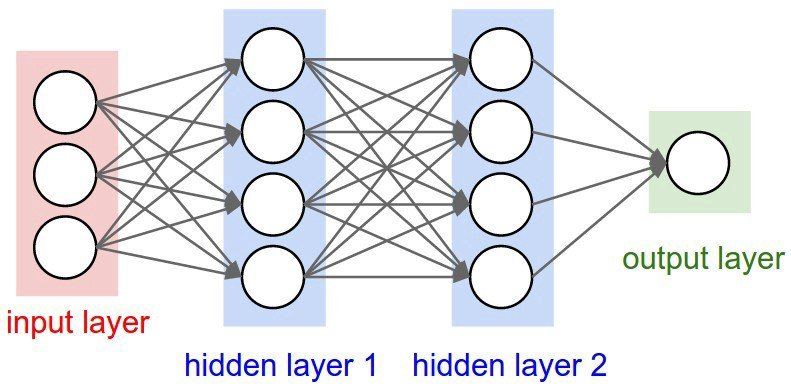
- input layer, hidden later, output layer
- filter : layer 연결 선들이 metric 형태로 들어가 있는 것. filter의 크기,값 지정해야함, 초기값은 random
loss function- output 결과가 잘 되었는지 확인
optimizer- loss funnction을 계산하여 얼만큼 예측? 어떻게 업데이트? 하며 최적화 과정
5. 예측 : output
- 모델 구축해놓고 input만 넣으면 예측
- 중요한건 예측을 잘 했는가
6. Loss 계산
y실제값,ŷ예측값- ŷ 이 얼마나 예측을 잘했는가의
기준이 loss function - 예측값이 어떠한 기준에 의해 loss를 계산
- loss값이
작아지게 하는 것이 목표 - 학습 흐름
(loss 작아지게 하는게 목표)
=> input 값을 넣어 아웃풋 나오면 실제 값과 비교(loss(오차) 계산)해서
=> loss(오차)가 작아지게 하는 가중치값을 업데이트하여
=> 다시 input 넣고 다시 loss 계산해서 가중치 업데이트...반복
7. Parameter Weight Update
- 업데이트 할 parameter
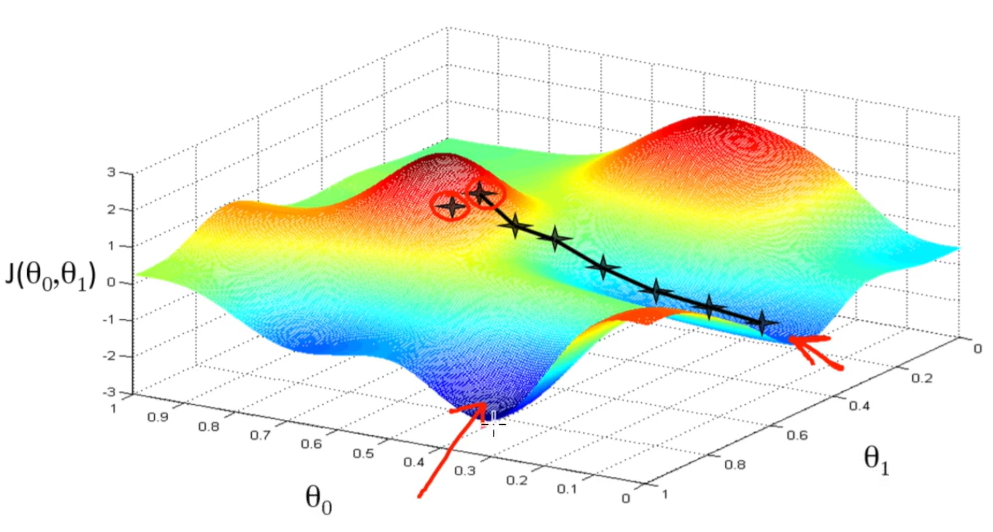
weight값을 구하는 것이 목표 역전파 (Backpropagation)- loss function의 예시 그림

- loss function이
가장 작은 지점의 (θ0 , θ1) 값을 구하고자 함. - 역전파를 통해 loss가 작아지는 weight값을 찾아가게 하는 것이 역전파 알고리즘.
- 모델을 backward pass 거꾸로 올라가며 node의 기여도를 확인하여 더 나은 weight 값 찾기
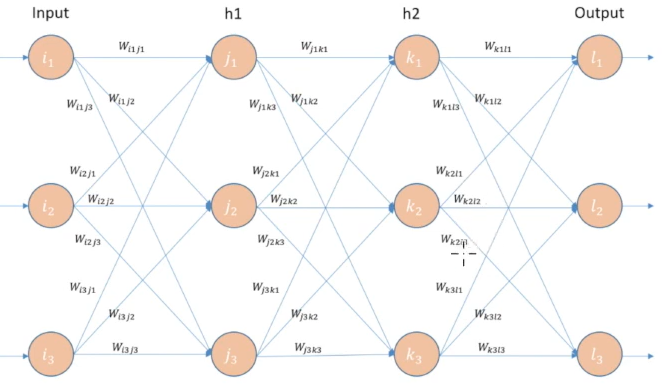
- 모델을 backward pass 거꾸로 올라가며 node의 기여도를 확인하여 더 나은 weight 값 찾기
- W 값들을 전부 역전파를 통해 업데이트 해줌
- loss function의 예시 그림
8. Optimizer
[파라미터를 업데이트 하는 방법]
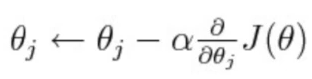
경사하강법 (gradient descent)- 기본적인 형태
- (미분) 기울기 값을 통해 작아지는 방향으로 찾아가게끔 만들어주는 것.
- α : learning rate, 기울기 방향으로 갈때 걸음 수 (좁게,넓게)

- 기본 형태를 기준으로 다양한 optimizer가 나옴
9. 최적화 (진단) : 모델 튜닝
loss/정확도안좋을 경우 조절learning rate
: 너무 작은 경우 조금씩 가다가 글로벌 미니멈까지 가기 전에 끝날 수도
: 너무 큰 경우 큼직큼직 걷다가 글로벌 미니멈을 지나쳐버릴 수도..optimizer: 다양한 optimizer 방법 사용batch: 몇개씩 data 넣을지filter: 크기,수layer: 수node: 얼마나 가져갈지activation function
: 한 라인이 1차 결합(W*X+bias등)으로 들어감.
: 실제 데이터가 전부 linear 한 관계가 아니기 때문에
: layer에서 layer로 넘어갈때 linear함을 non linear함으로 바꿔줌- etc..
overfitting방지early stoppingregularization: loss function이 완전히 작아지지 않게끔dropout: node의 일부를 죽여서 과적합 방지- etc..

[Data Science] 차근차근 쌓아나가는