과적합(Overfitting)
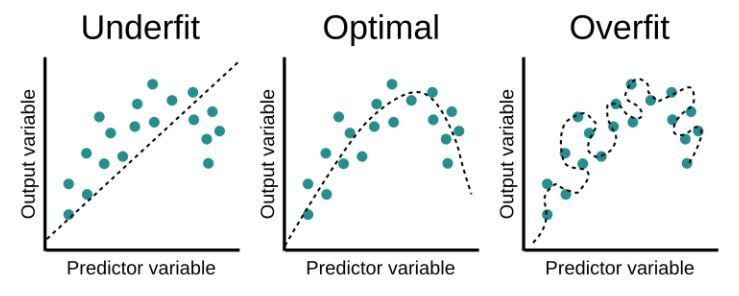
- 신경망이 훈련 데이터에만 지나치게 적응되어, 그 외 데이터에는 제대로 대응하지 못하는 상태.
- 이는 모델이 훈련 데이터의 노이즈까지 학습하여 발생한다.
과적합을 막는 방법들
1. 데이터 증식 (Data augmentation)
- 모델은 데이터의 양이 적을 경우, 데이터의 특정 패턴, 노이즈까지 쉽게 암기하기 때문에 과적합이 발생할 확률이 높다.
- 데이터의 양을 늘려 학습 데이터의 다양성을 높이는 방법이 있다.
- 하지만 실제 데이터의 양을 늘리는 것엔 한계가 있다.
- 의도적으로 기존의 데이터를 변형,추가 하는 data augmentation 방법을 이용한다.
- 이미지를 돌리거나, 노이즈 추가, 일부 수정 등
2. 모델 복잡도 줄이기
- 인공 신경망의 복잡도는 은닉층(hidden layer)의 수, 매개변수 수 등으로 결정된다.
- 따라서 네트워크의 층 수, 뉴런 수를 줄여 모델의 복잡도를 낮춘다.
인공 신경망에서는 모델의 매개변수의 수를 모델의 수용력(capacity)라고도 한다.
3. 가중치 규제 (Regularization)
- 가중치에 규제를 적용하여 네트워크의 복잡도를 줄인다.
- L1 규제와 L2 규제가 대표적
- L1 규제 : 가중치 w들의 절대값 합계를 cost function에 추가
- L2 규제 : 모든 가중치 w들의 제곱합을 cost function에 추가
4. 드롭아웃 (Dropout)
- 학습 과정에서 일부 뉴런을 무작위로 비활성화하여 네트워크의 복잡도를 줄인다.
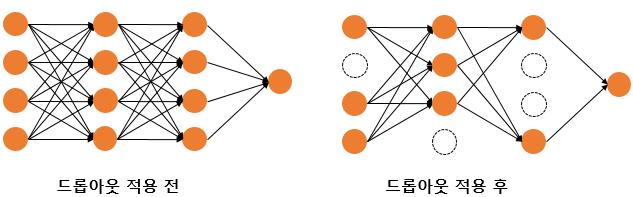
- 예를 들어, 드롭아웃 비율을 0.5로 설정하면, 학습마다 랜덤으로 절반의 뉴런을 사용하지 않는다.
- 드롭아웃은 신경망 학습 시에만 사용하고, 예측 시에는 사용하지 않는다.
- 학습 시에는 인공 신경망이 특정 뉴런, 조합에 너무 의존적이게 되는 것을 방지해줌.
- 매번 랜덤으로 뉴런을 사용하지 않으므로 -> 서로 다른 신경망들을 앙상블해 사용하는 것과 같은 효과를 내어 과적합을 방지한다.
- 드롭아웃 코드 예제
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dropout, Dense
max_words = 10000
num_classes = 46
model = Sequential()
model.add(Dense(256, input_shape=(max_words,), activation='relu'))
model.add(Dropout(0.5)) # 드롭아웃 추가. 비율은 50%
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5)) # 드롭아웃 추가. 비율은 50%
model.add(Dense(num_classes, activation='softmax'))출처
https://wikidocs.net/61374
책 <밑바닥부터 시작하는 딥러닝>, <딥러닝을 이용한 자연어 처리 입문>
https://deep-learning-study.tistory.com/167

[Data Science] 차근차근 쌓아나가는