모델 경량화 도구들
- ONNX
- TensorRT
- PyTorch Mobile
- TensorFlow Lite
- NCNN
모델 경량화 도구들 - 상세
1. ONNX
-
다양한 machine learning framework의 산출물들을 ONNX 형식으로 변환함

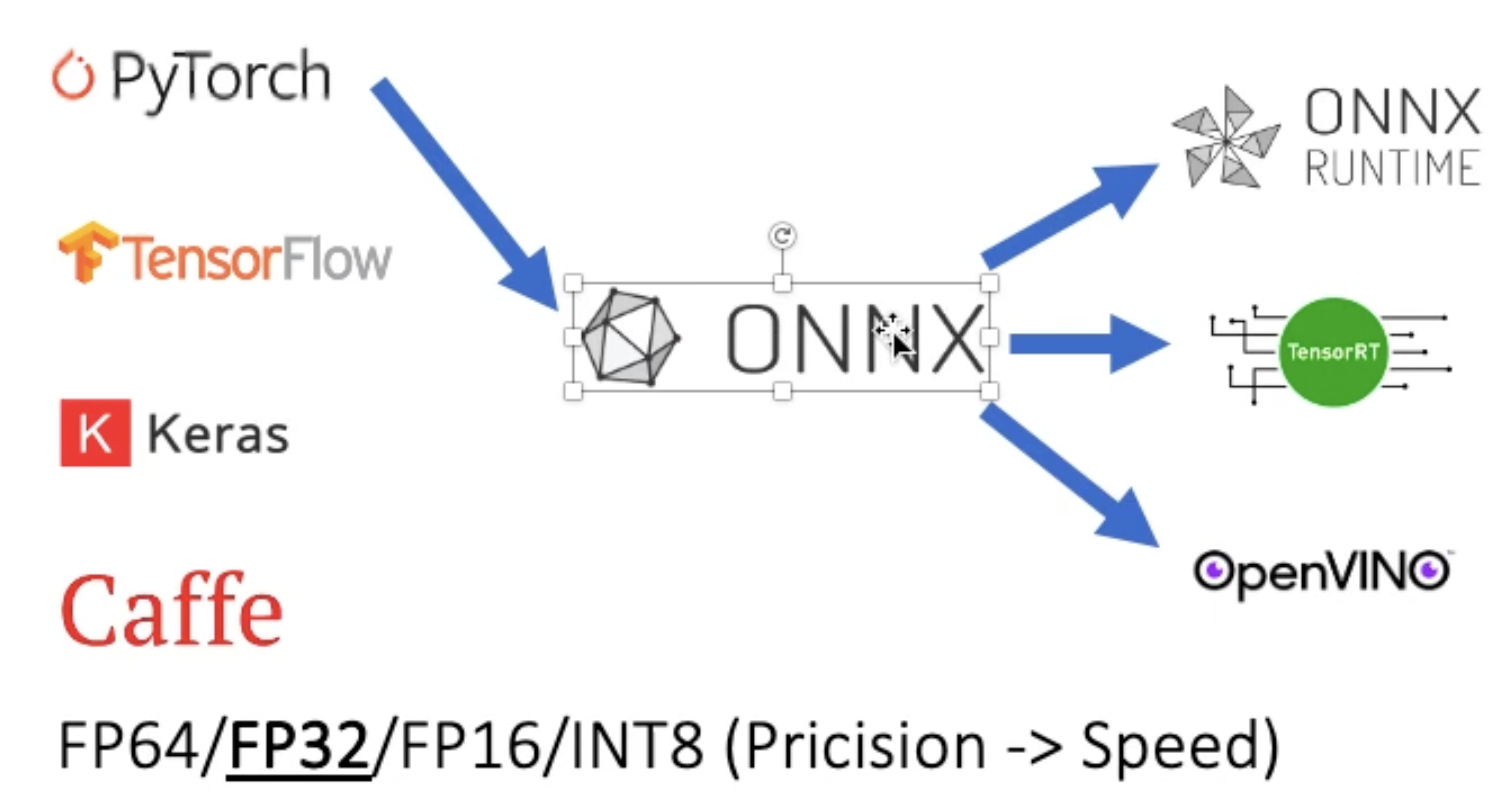
-
ONNX Design Principles
- traditional ML, DNN 지원
- 빨리 개선할 수 있도록 충분히 유연하게
- serialization을 위한 cross-platform
- 잘 정의된 연산자로 이루어지도록 표준화
-
ONNX File Format
- Model
- Version info
- Metadata
- Acyclic computation dataflow graph
- Graph
- Inputs and outputs
- List of computation nodes
- Graph name
- Computation Node
- Zero or more inputs of defined types
- One or more outputs of defined types
- Operator
- Operator parameters
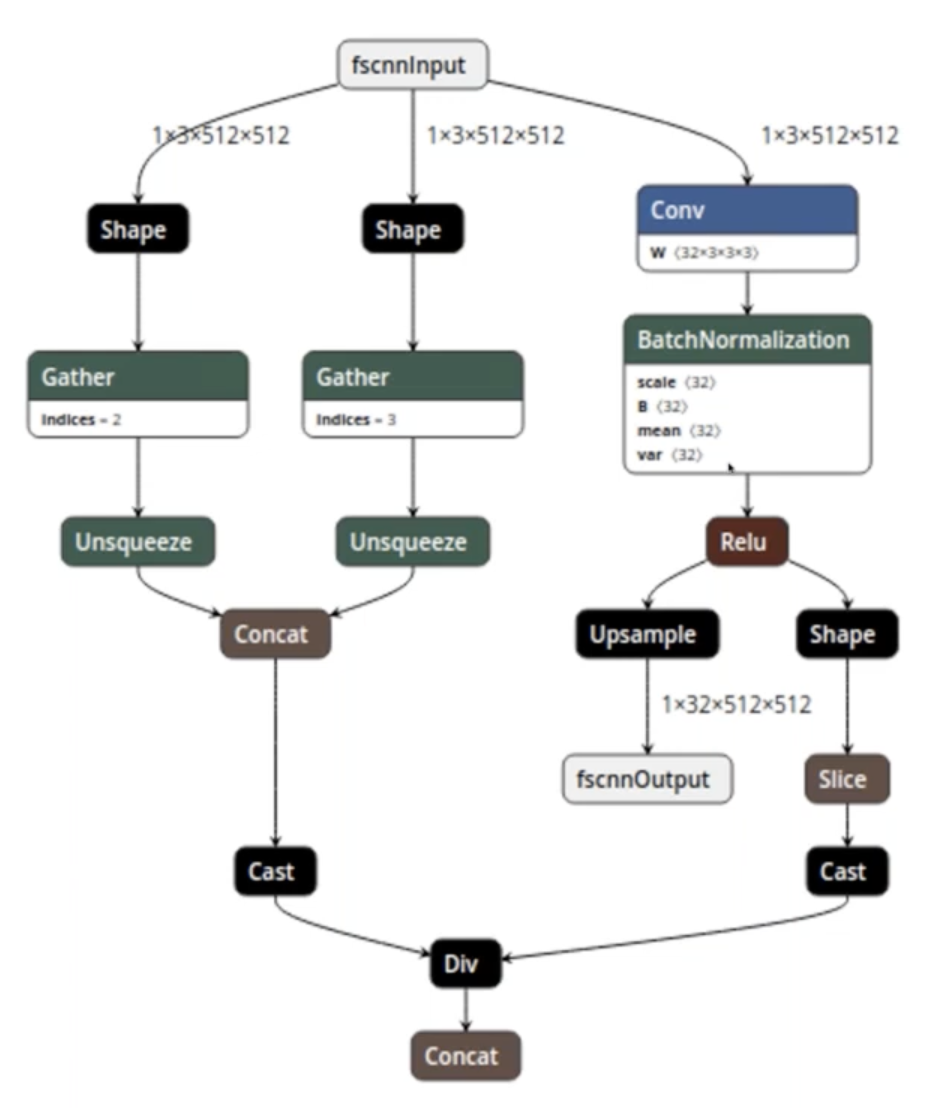
- Model
-
ONNX Data Types
- Tensor type
- Element types
- int8, int16, int32, int 64
- uint8, uint16, uint32, uint64
- float16, float, double
- bool
- string
- complex64, complex128
- Element types
- Non-tensor types in ONNX-ML
- Sequence
- Map
- Tensor type
-
ONNX Operators
- An operator is identified by <name, domain, version>
- Core ops (ONNX and ONNX-ML)
- ONNX 호환 가능한 product에 의해 지원 받아야함
- ai.onnx 도메인에서 124 ops가 있고, ai.onnx.ml 도메인에서 18 ops가 있음.
- 많은 scenarios/problem 영역을 지원함
- image classification, recommendation, natural language processing 등
- Custom ops
- framework 혹은 runtime에 specific한 ops
- custom domain name에 의해 표시됨
- Primarily meant to be a safety-value
-
ONNX Runtime
- High performance inference engine for ONNX
- Founded and open sourced by Microsoft under MIT license
- Full ONNX spec support (v1.2+)
- Extensible and modular framework
- Ships with Windows 10 as WinML
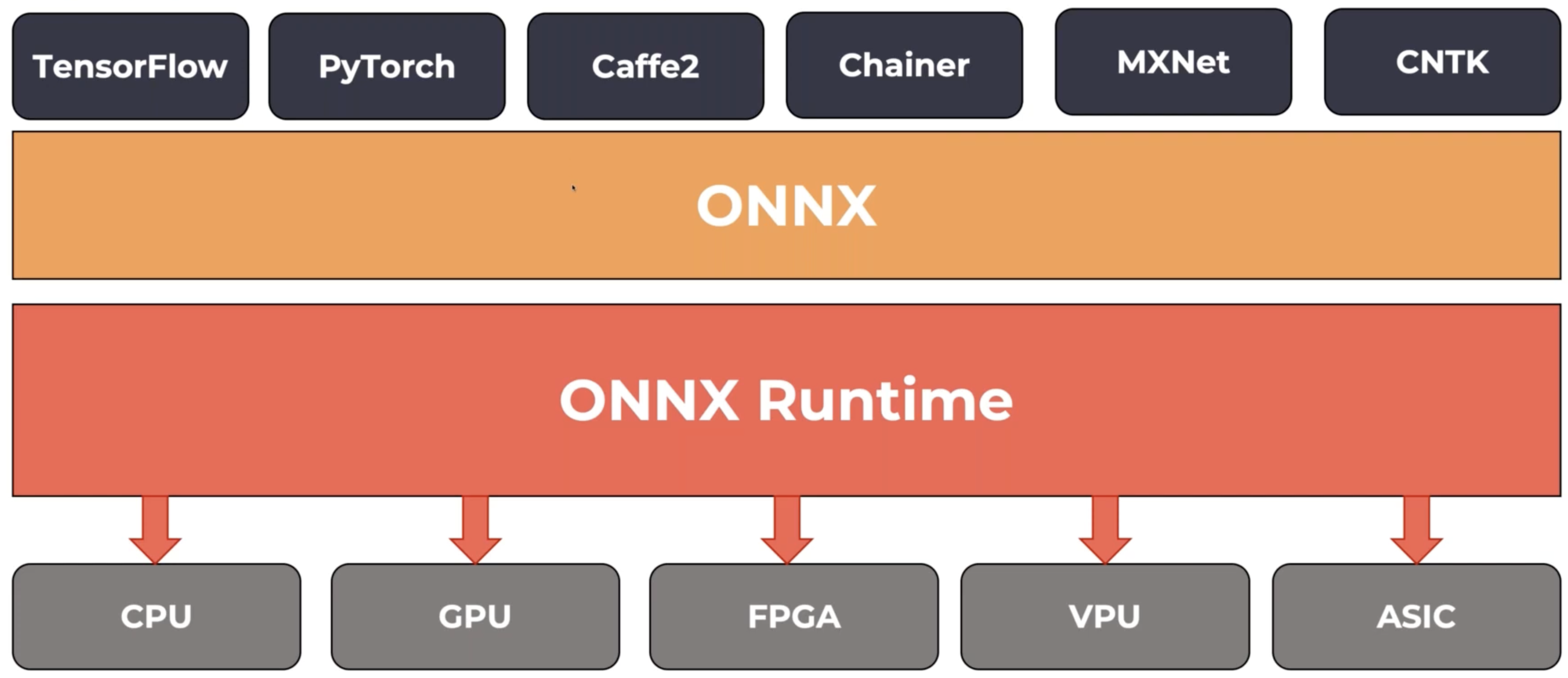
-
Deploying ONNX Models - Azure ML
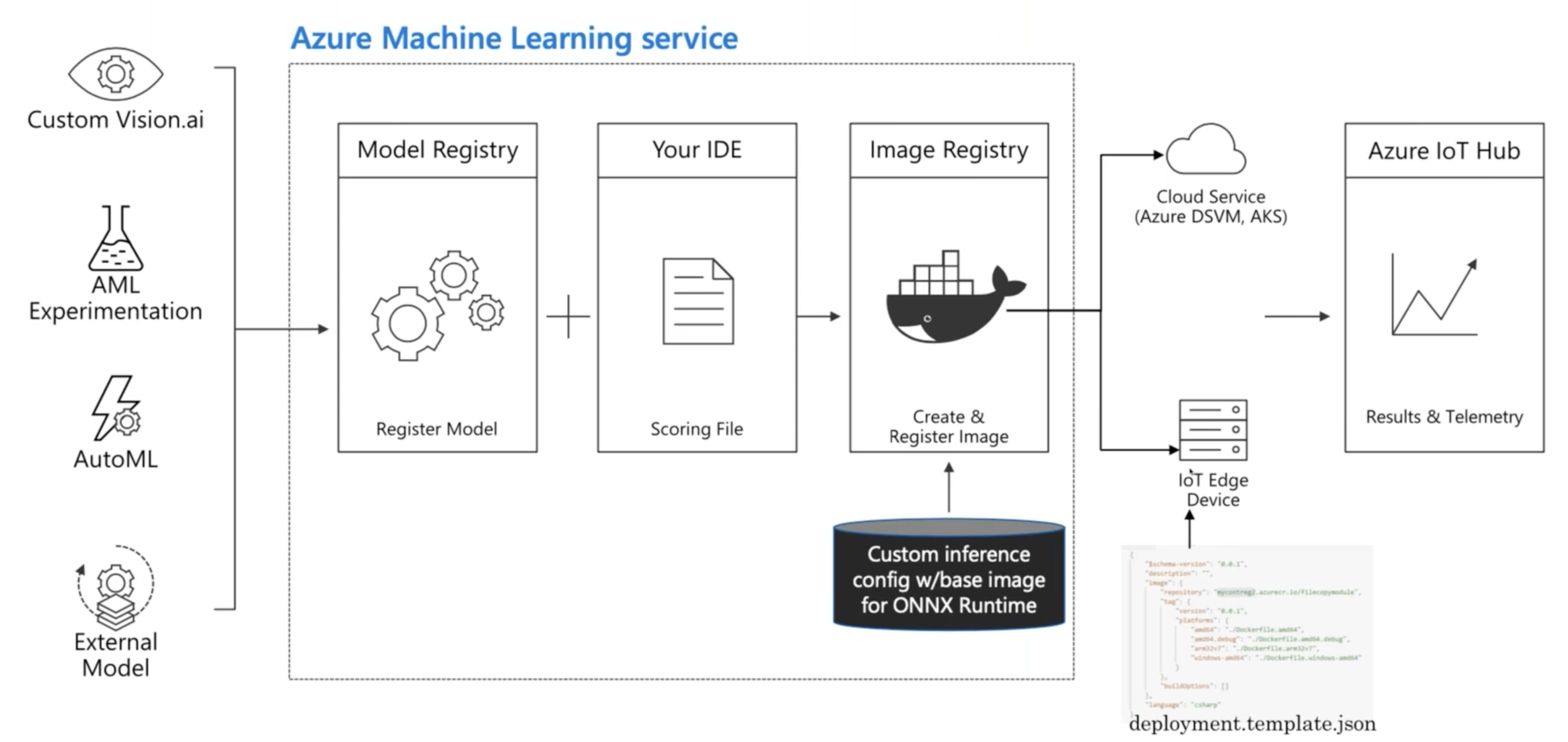
2. TensorRT
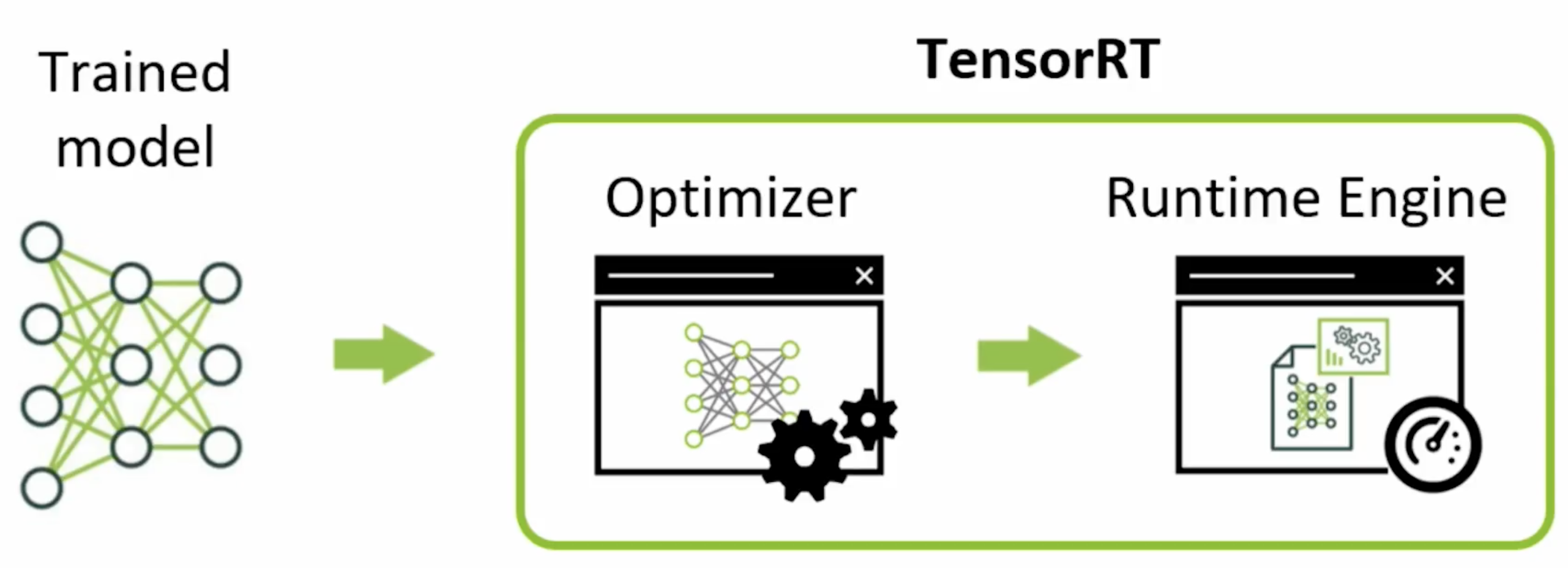
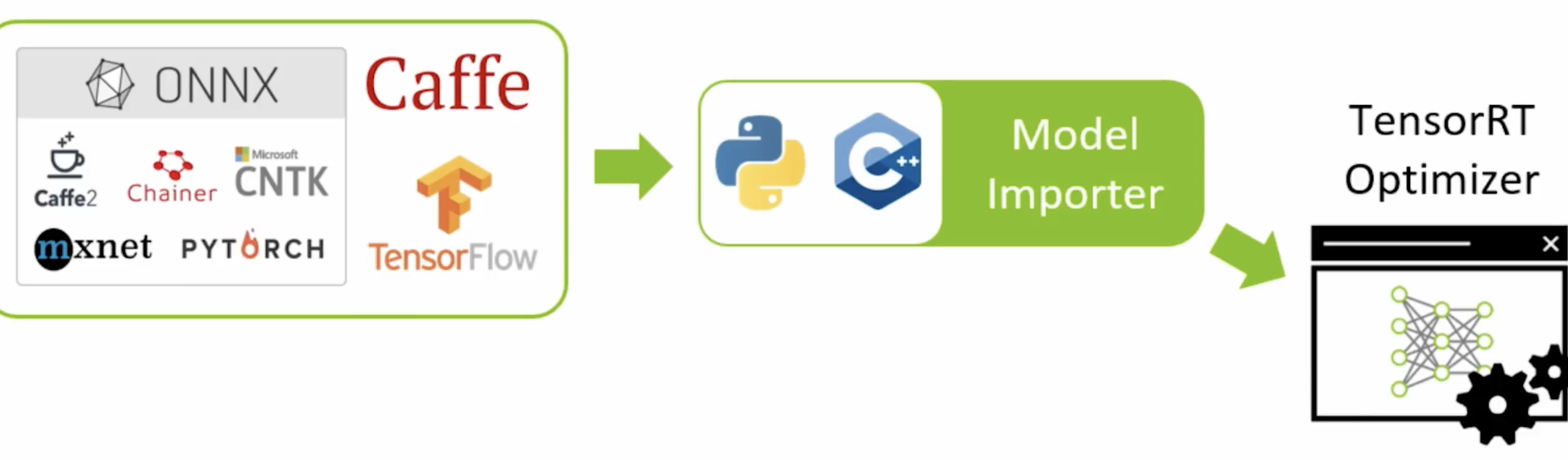
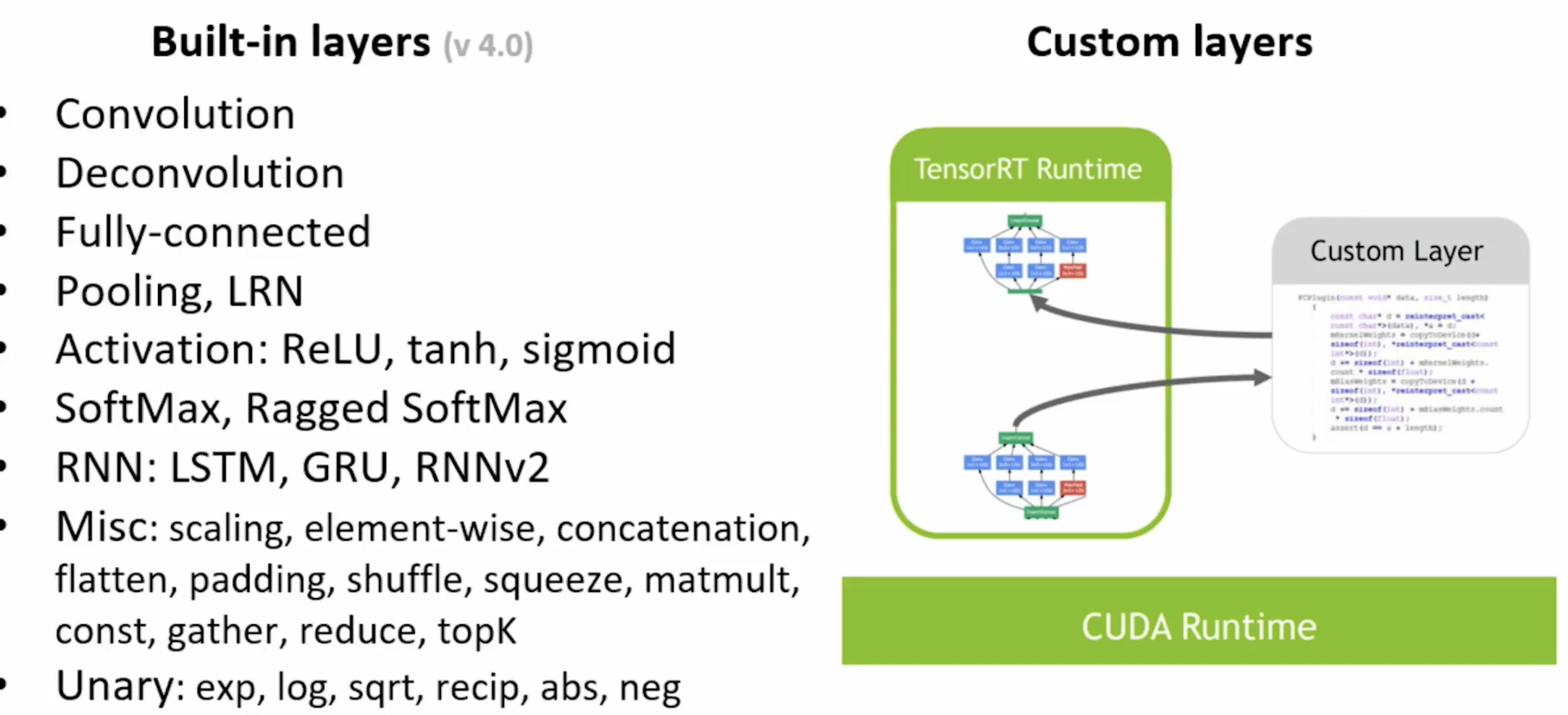
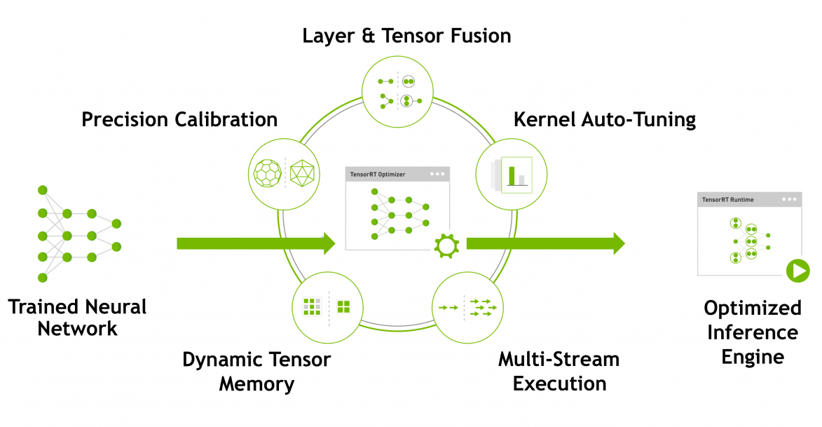
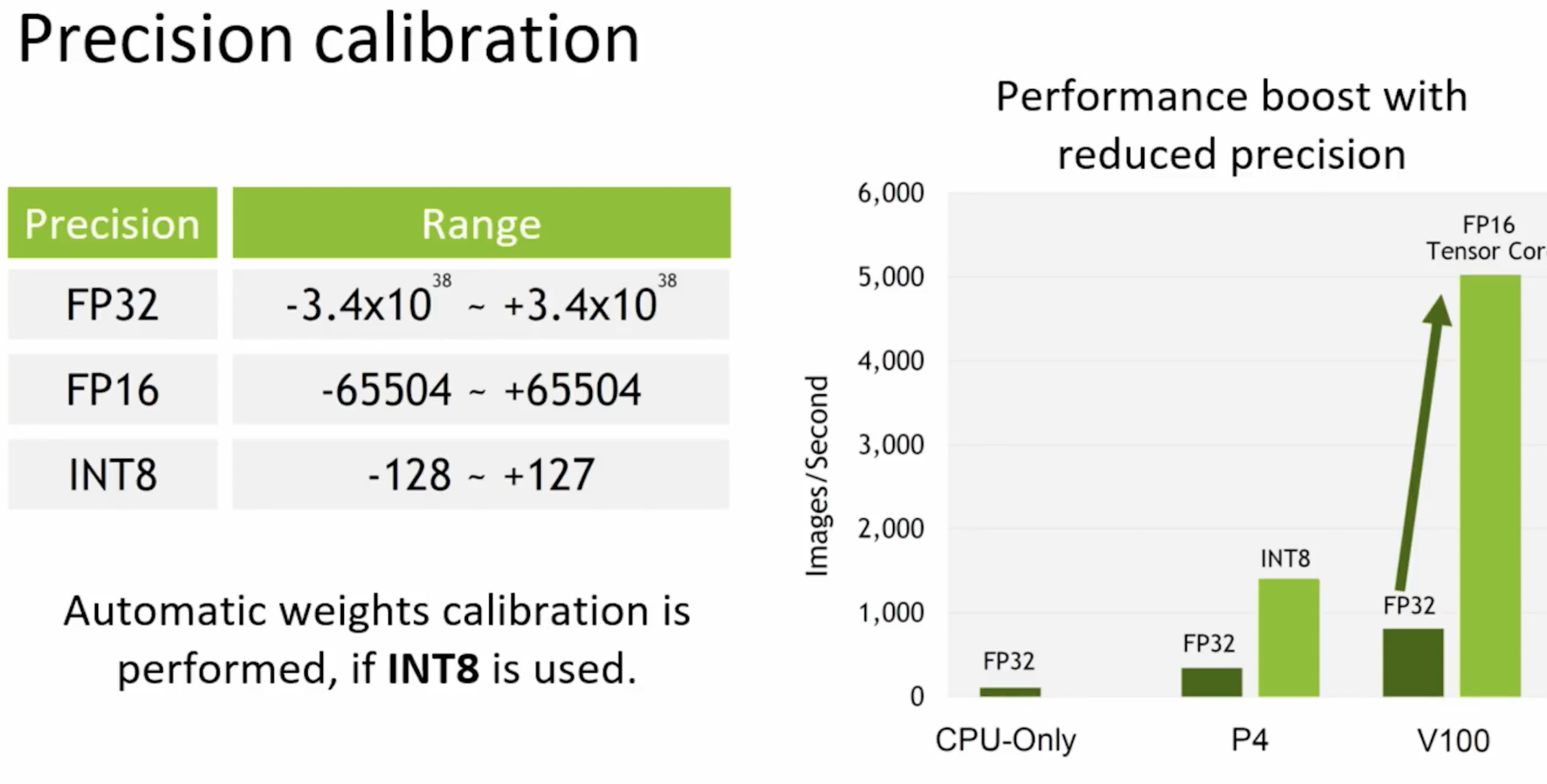
TensorRT optimization에서 사용되는 기법
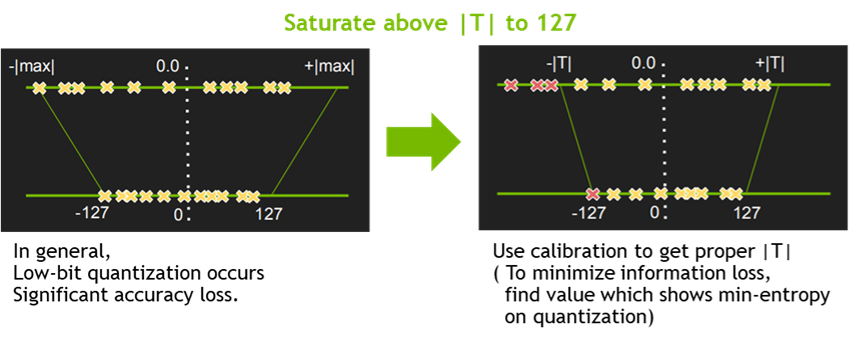
- Quantization & Precision Calibration
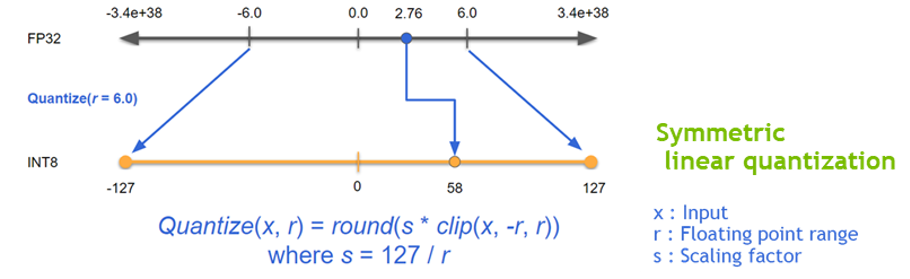
- Summetric linear quantization
- FP32 -> FP16 and INT8
- EntropyCalibrator, MinMaxCalibrator 지원
- Graph Optimization
- Layer Fusion, Tensor Fusion 방식 동시에 적용
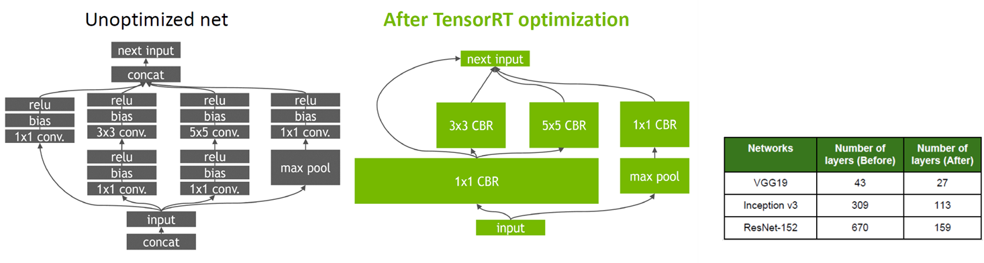
- Layer Fusion, Tensor Fusion 방식 동시에 적용
- Kernel Auto-tuning
- NVIDIA의 platform, architecture에 맞는 Runtime 생성을 도와줌.

- NVIDIA의 platform, architecture에 맞는 Runtime 생성을 도와줌.
- Dynamic Tensor Memory & Multi-stream execution
- momory management를 통해 footprint를 줄여 재사용할 수 있게 도와주는 dynamic tensor memory.
- multi-stream execution은 CUDA stream 기술을 이용하여 multiple input stream의 scheduling을 통해 병렬 효율을 극대화함.
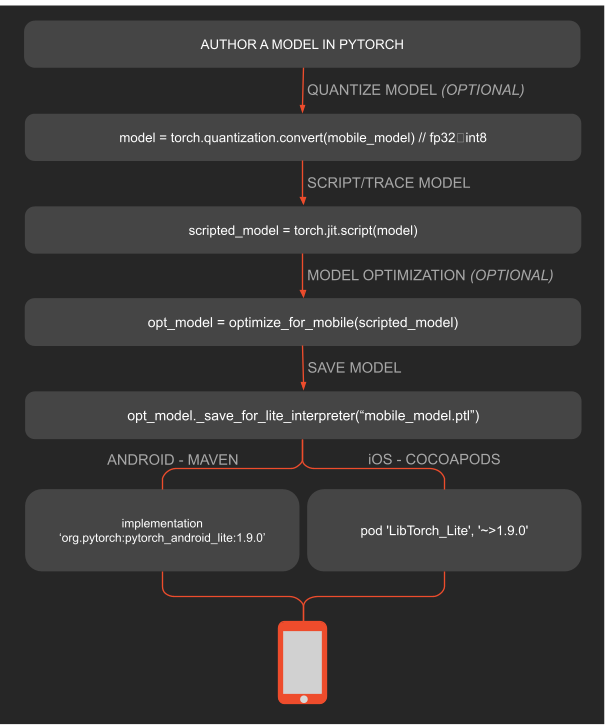
3. PyTorch Mobile
4. TensorFlow Lite
-
TensorFlow Lite는 개발자가 모바일, 내장형 기기, IoT 기기에서 모델을 실행할 수 있도록 지원하여 기기 내 머신러닝을 사용할 수 있도록 하는 도구 모음
-
주요 특징
- 기기 내 머신러닝에 최적화됨, 5가지 핵심 제약사항 해결: 지연 시간(서버까지의 왕복 없음), 개인 정보 보호(기기에 개인 정보를 남기지 않음), 연결성(인터넷 연결이 필요하지 않음), 크기(모델 및 바이너리 크기 축소), 전력 소비(효율적인 추론 및 네트워크 연결 불필요)
- 여러 플랫폼 지원: Android, iOS, 내장형 Linux, 마이크로 컨트롤러
- 다양한 언어: 자바, Swift, Objective-C, C++, Python 등
- 고성능: 하드웨어 가속 및 모델 최적화 사용
- 포괄적인 task: 다양한 플랫폼에서의 일반적인 머신러닝 작업(예: 이미지 분류, 객체 감지, 자세 추정, 질문 답변, 텍스트 분류 등)
-
개발 워크플로
- TensorFlow Lite 모델 생성
- 기존 TensorFlow Lite 모델 사용
- TensorFlow Lite 모델 생성
- TensorFlow 모델을 TensorFlow Lite 모델로 변환
- 추론 실행
- 메타데이터가 없는 모델
- 메타데이터가 있는 모델
5. NCNN
- mobile platform을 위해 neural network inference를 최적화하는 framework.
- ncnn은 third party 의존성이 없다.
- cross-platform이다.
- mobile phone cpu에서는 알려진 어떤 framework보다 빠름.
References

sshinohs