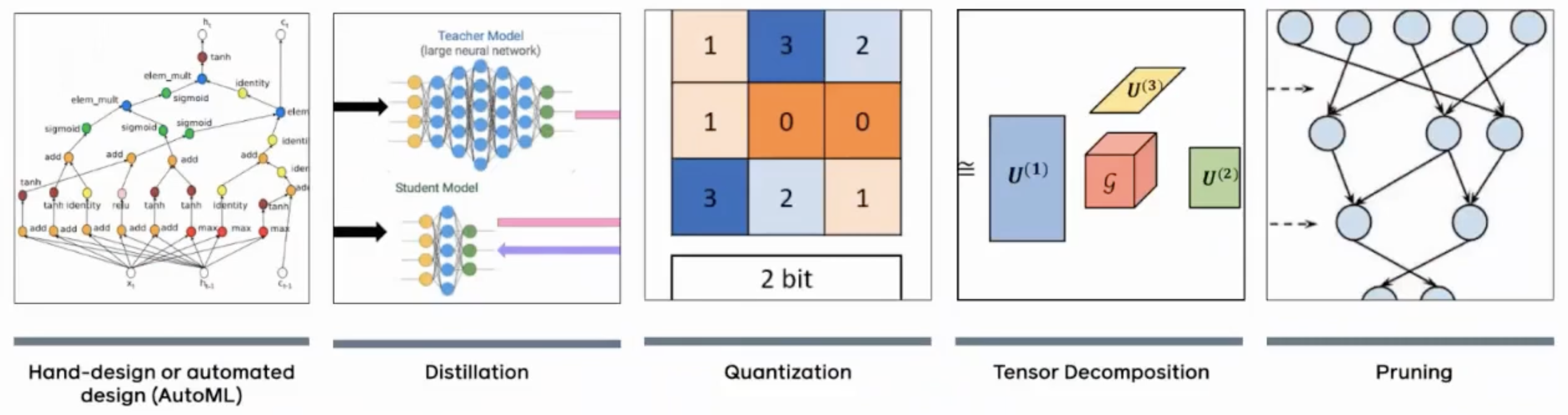
모델 경량화 기법 분류
Model Compression Methods List
- Quantization
- Pruning
- Knowledge Distillation
- Low-Rank Approximation
- Weight Sharing
- Compact Network Architecture Design
- Others
- model compression의 이점들
- inference, training 속도
- 저장 공간 요구사항 감소
- in-memory 계산량 감소
- on-device 계산 감소
- power 절약
- 발열량 감소
- 환경문제 경감
- 해석 가능성에 도움
- model compression의 단점들
- pre-trained version이 거의 없음
- custom hardware 없이는 속도 개선이 잠재적으로 미미함
- 목표 hardware architecture의 정확한 지식 없이는 compression method를 선택하기가 어려움
- task에 의존함
Model Compression Methods List - Detail
- Quantization
: neural network의 weights, biases, activations의 값을 저장하는 bit 수를 감소시킨다. 예를 들면, 32-bit floating point를 8-bit integer로 대체한다. - Pruning
: neural network에서 중요하지 않은 것 처럼 보이는 일부 weights 혹은 connections를 제거하여 전체 네트워크의 크기를 감소시킨다. - Knowledge Distillation
: 큰 network의 출력을 이용해서 보다 작은 network를 훈련시키는 방법이다. - Low-Rank Approximation
: low-rank matrix factorization을 이용해서 neural network의 weights를 근사하는 방법이다. - Weight Sharing
: weights를 그룹으로 묶어서 공유하는 방법이다. - Compact Network Architecture Design
: network architecture를 parameter 수 혹은 operation이 적은 architecture로 재설계하는 방법이다. MobileNet, ShuffleNet, SqueezeNet 등이 있다. - Others
: 특별히 설계된 hardware(GPU, FPGA 등)를 사용하는 방법, 다양한 compression 기법을 조합하여 사용하는 방법이 있다.
Model Compression Methods List - More Detail
1. Quantization
- 장점은 다음과 같다.
- memory 사용량 감소
- power comsumption 감소
- latency 감소
- silicon area 감소

- quantization은 대칭, 비대칭으로 분류할 수 있다.
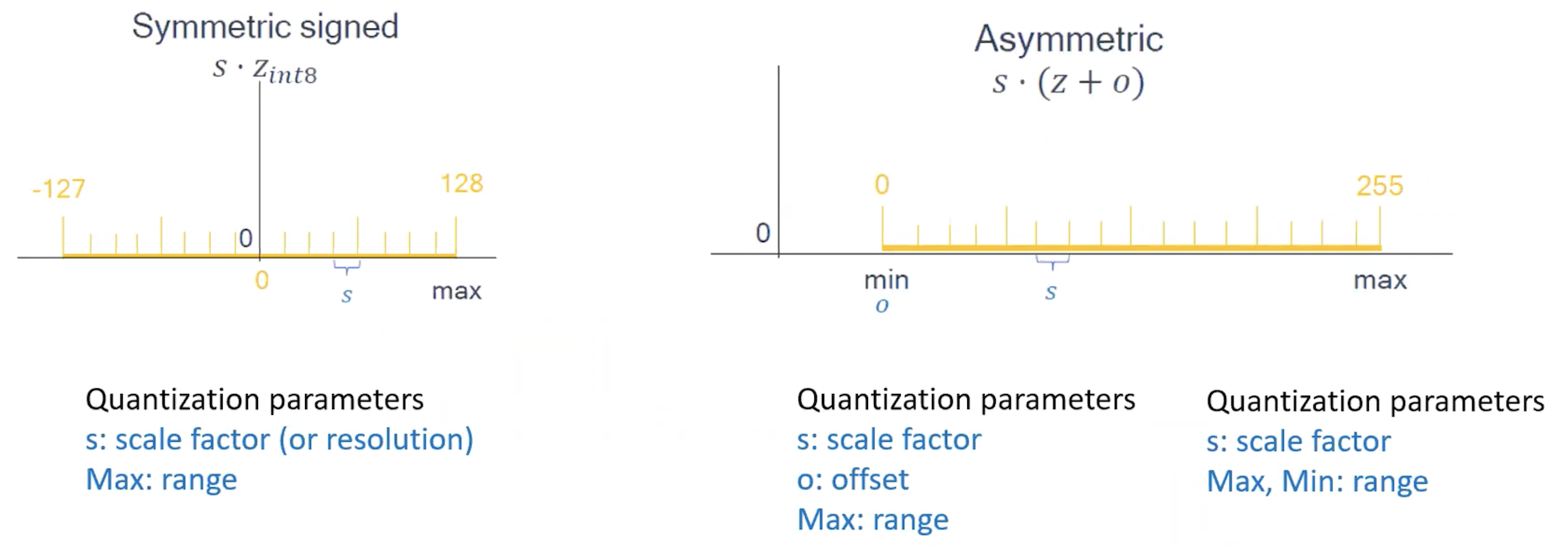
- 대칭: quantization 이전 값에서 quantization 이후 값으로 mapping할 때, 0을 기준으로 좌우가 대칭
- parameter set
- s: scale factor (or resolution)
- Max: range
- parameter set
- 비대칭: quantization 이전 값에서 quantization 이후 값으로 mapping할 때, 0을 기준으로 좌우가 비대칭
- parameter set #1
- s: scale factor
- o: offset
- Max: range
- parameter set #2
- s: scale factor
- Max, Min: range
- parameter set #1
- 대칭: quantization 이전 값에서 quantization 이후 값으로 mapping할 때, 0을 기준으로 좌우가 대칭

-
보통 값들이 대칭적으로 분포되지 않기 때문에, asymmetric으로 양자화 했을 때 정확도가 높다. 하지만 계산할 때 overhead가 많아지게 된다.

-
asymmetric으로 quantization 할 때 10-15% 추가로 연산이 필요하다.
-
weights는 보통 symmetric이 적절하고, activations, inputs는 asymmetric이 적절하다고 한다.
-
Fake quantization
- weights 및 모든 operation 뒤에 quantization operation을 삽입한다.
- 출력이 여전히 floating point이므로 fake quantization이라고 한다.
- GPU, CPU는 fp32로 설정되어 있기 때문에 fake quantization이라고 한다.
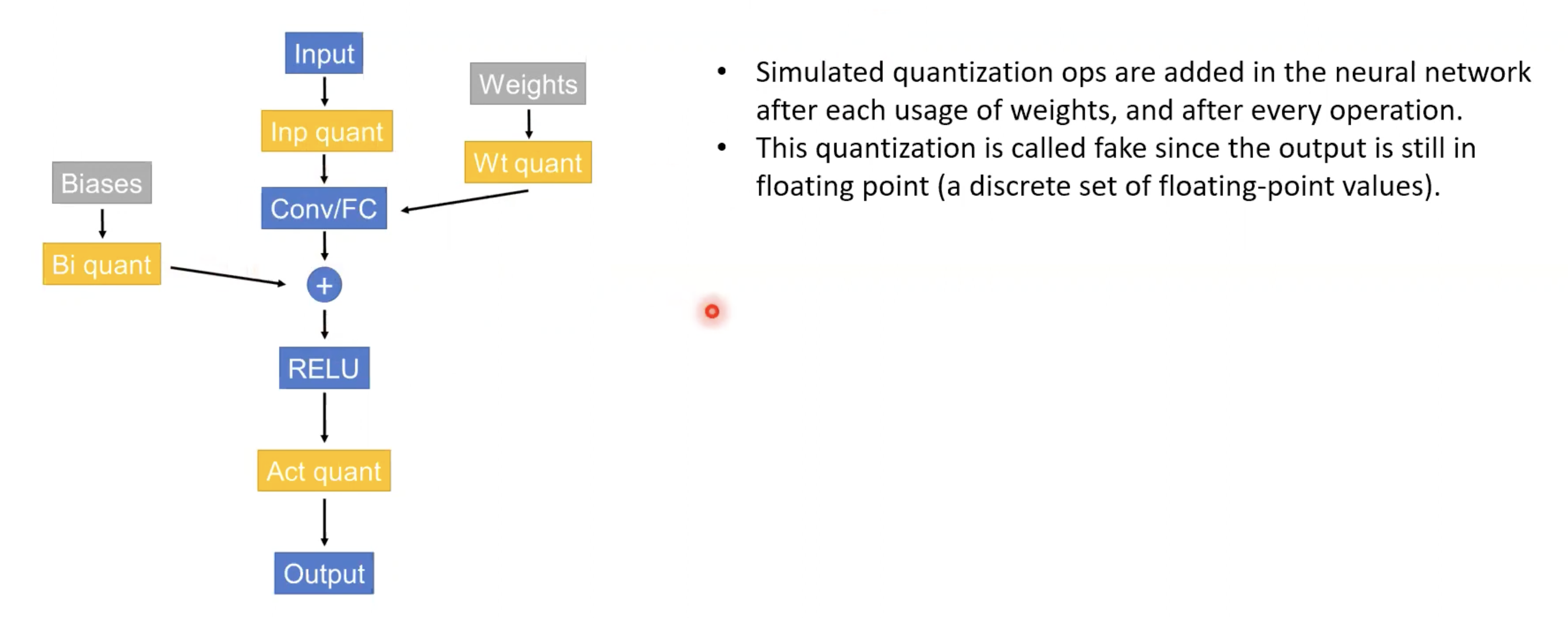
-
Per-channel quantization vs Per-tensor quantization
- per-channel은 모든 convolution kernel이 다른 clipping range를 가짐
- per-tensor는 모든 convolution kernel이 같은 clipping range를 가짐
- per-channel이 정확도 우수, per-tensor가 연산량 적음
-
clipping range는 어떻게 결정할까?
- inference 시에 weights의 경우 값을 알고 있으니, 통계값을 이용함
- activations의 경우, static과 dynamic이 있다
-
static vs dynamic quantization
- static은 사전에 range를 미리 결정
- dynamic은 runtime에서 min/max 등을 계산하여 결정
- static이 속도 우수, dynamic이 정확도 우수
-
Post Training Quantization(PTQ) vs Quantization Aware Training(QAT)
- PTQ: finetuning 없이 훈련된 모델의 weights/activations를 분석하여 quantization 하는 것
- final accuracy를 control 하지 않음
- data가 없어도 수행할 수 있음
- back propagation이 필요하지 않음
- QAT: finetuning 하는 것 -> final accuracy를 control 함
- PTQ: finetuning 없이 훈련된 모델의 weights/activations를 분석하여 quantization 하는 것
-
Uniform vs Mixed-precision quantization
- 일부 layer가 민감할 경우, 특정 layer만 quantization하는 mixed-precision quantization 적용함
2. Pruning
-
DRAM에 접근하는 것은 에너지 비용이 많이 든다.
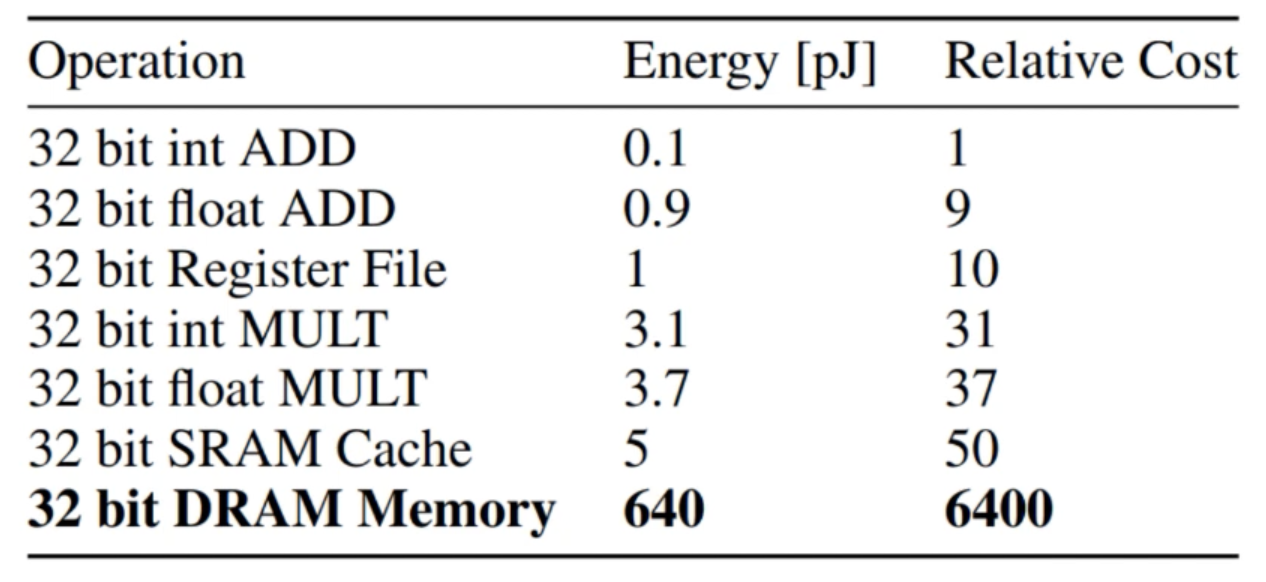
-
pruning은 over-parametrization일 때 효과가 있다.
-
pruning은 불필요한 구조를 제거하는 것이다.
- 어떤 구조가 불필요한가?
- 어떤 종류의 구조?
-
pruning은 훈련 전, 훈련 중, 훈련 후에 적용 가능하다.
-
Pruning methods differ across many dimensions
- based on weight magnitude, activations, gradients, Hessian, interpretability measures, credit assignment, random, etc.
- Layer-wise vs global, unstrutured vs structured, etc.
- Rule-based, bayesian, differentiable, soft approaches, etc.
- One-shot vs iterative pruning
- Followed by: fine tuning, reinitialization, rewinding
-
structured vs unstructured
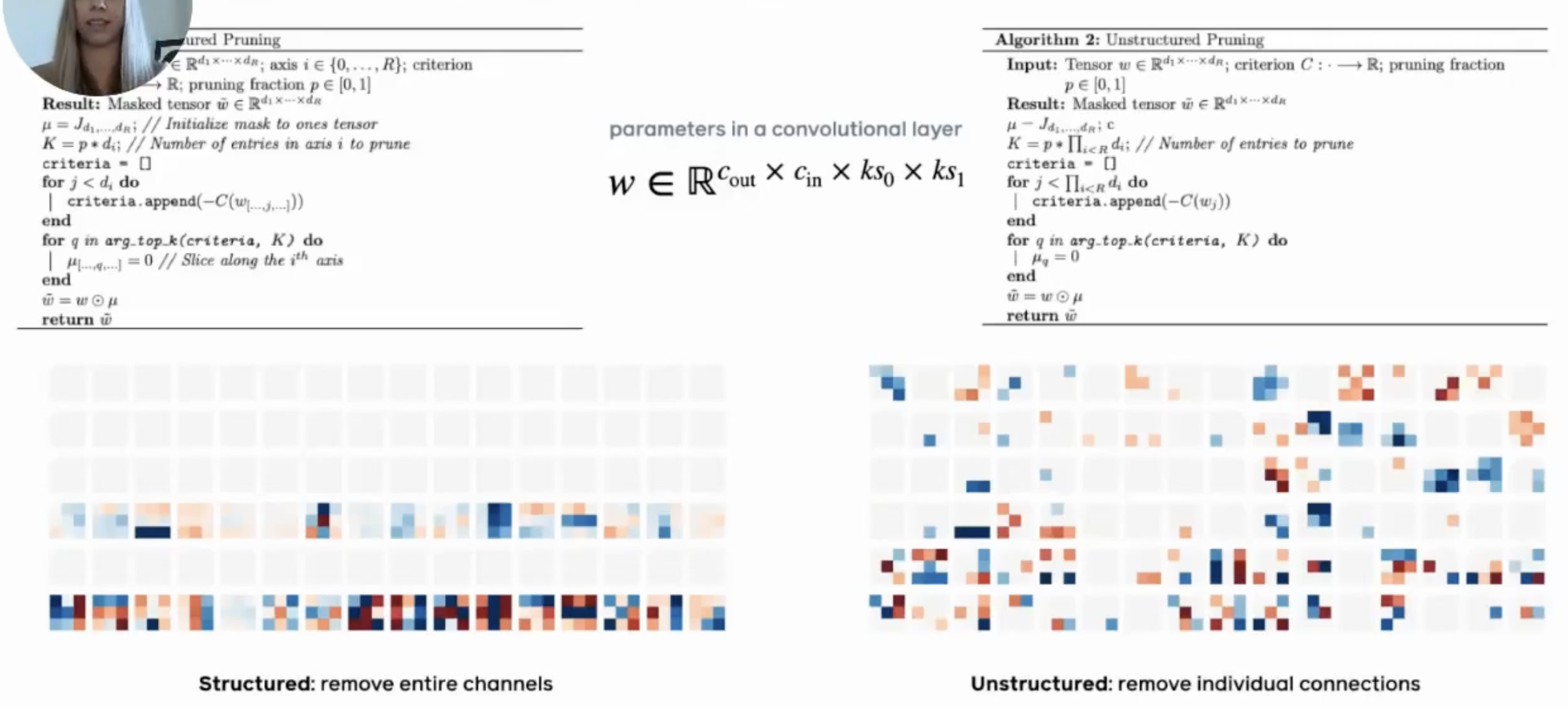
-
pruning 기준의 예
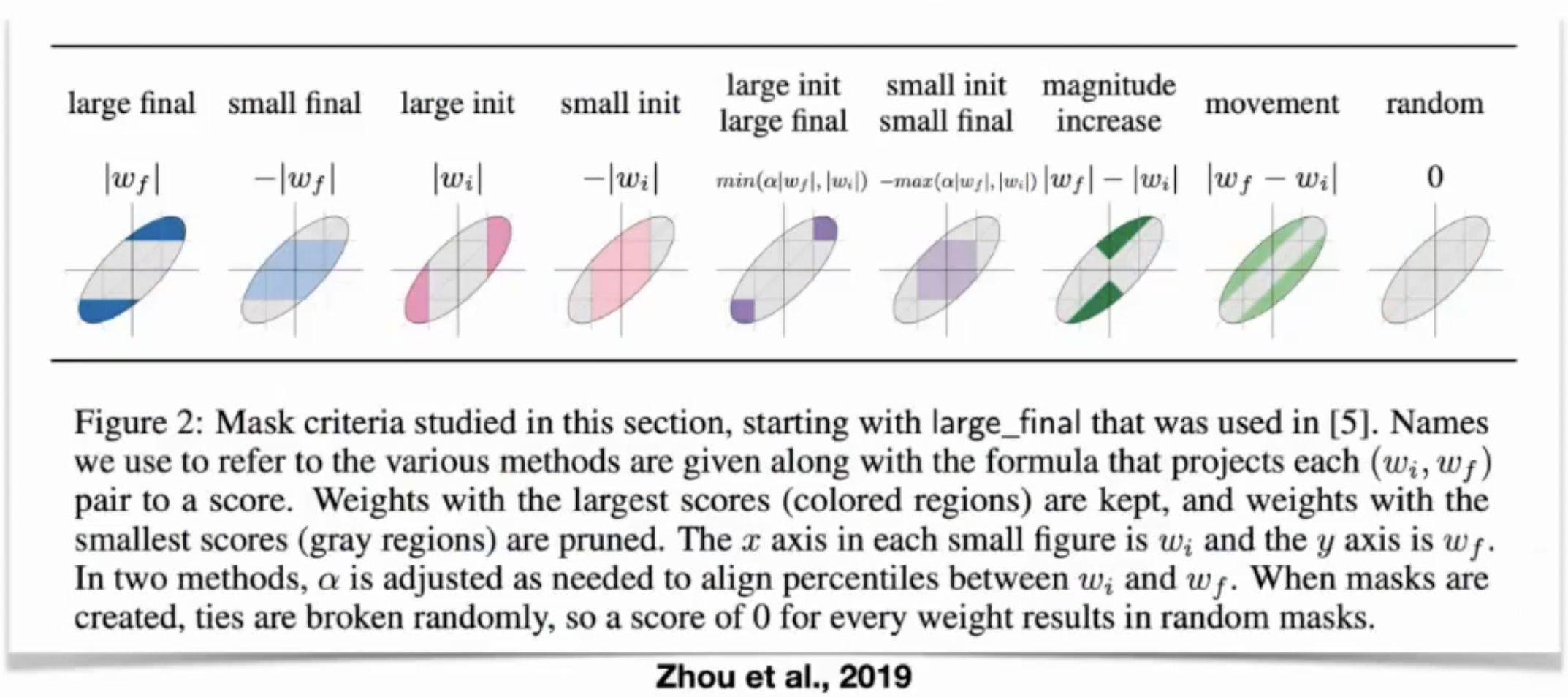
-
pruning에서 불필요한 구조를 확인하는 방법
- pruning 되지 않은 모델을 학습하여, 가중치의 크기가 적은 뉴런을 불필요하다고 본다.
-
Lottery ticket hypothesis
- 무작위로 초기화된 밀집된 딥뉴럴넷에서 어떤 부분을 가져왔을 때, 따로 트레이닝 하더라도, 기존의 네트워크와 같은 성능을 같은 학습 횟수 내에 달성할 수 있을 것이다.
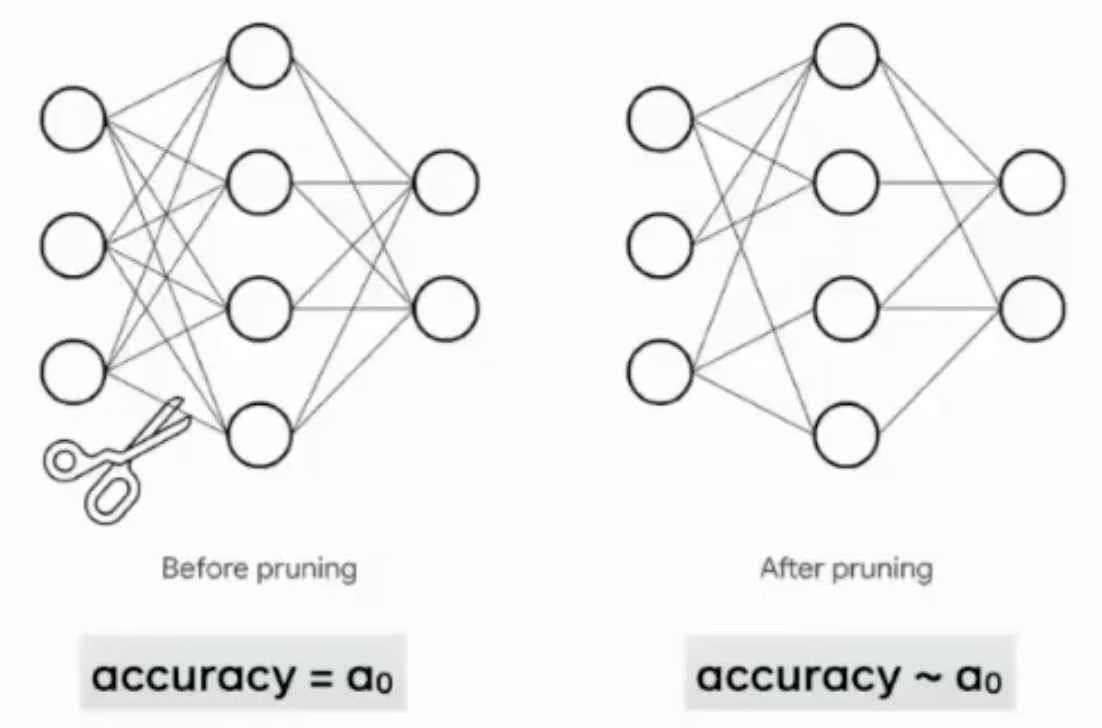
- 무작위로 초기화된 밀집된 딥뉴럴넷에서 어떤 부분을 가져왔을 때, 따로 트레이닝 하더라도, 기존의 네트워크와 같은 성능을 같은 학습 횟수 내에 달성할 수 있을 것이다.
-
Iterative magnitude pruning
- 일반적으로 학습된 네트워크에서 가중치의 크기(magnitude)가 작은 뉴런을 제거하고 가지치기된 네트워크를 가지고 다시 학습시키는 방식
- 계산 비용이 많이 든다.
-
그래서 사람들은 학습을 덜 하거나 안하고 pruning을 할 수 있는 방법을 찾는다.
- 데이터를 안보고도 pruning을 할 수 있는 방법을 찾음
- Pruning neural networks without any data by iteratively conserving synaptic flow
- https://arxiv.org/pdf/2006.05467.pdf
- 데이터를 안보고도 pruning을 할 수 있는 방법을 찾음
-
fine-tuning vs rewinding
- rewinding은 pruning 후 재학습할 때, initialization 값으로 돌리는 것이 아니라, training 초기의 특정 단계로 돌리는 것
fine-tuning 보다 빨리 수렴한다고 함 - COMPARING REWINDING AND FINE-TUNING IN NEURAL NETWORK PRUNING
- https://openreview.net/pdf?id=S1gSj0NKvB
- rewinding은 pruning 후 재학습할 때, initialization 값으로 돌리는 것이 아니라, training 초기의 특정 단계로 돌리는 것
3. Knowledge Distillation
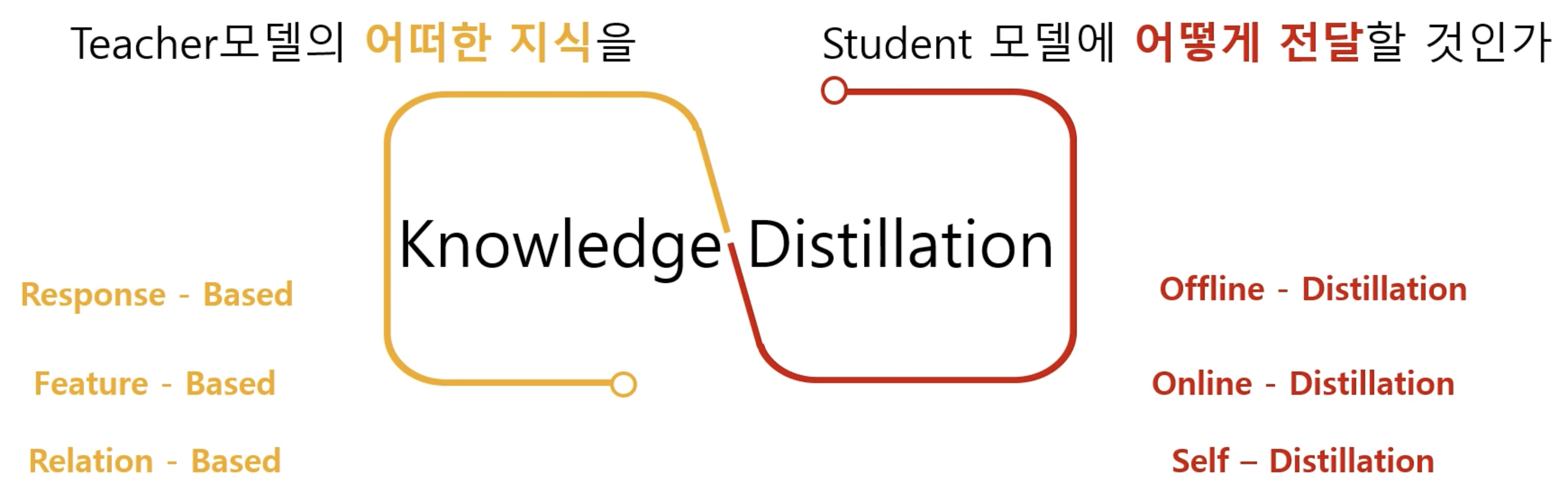
4. Low-Rank Approximation
-
Matrix와 Tensor의 분해 방법
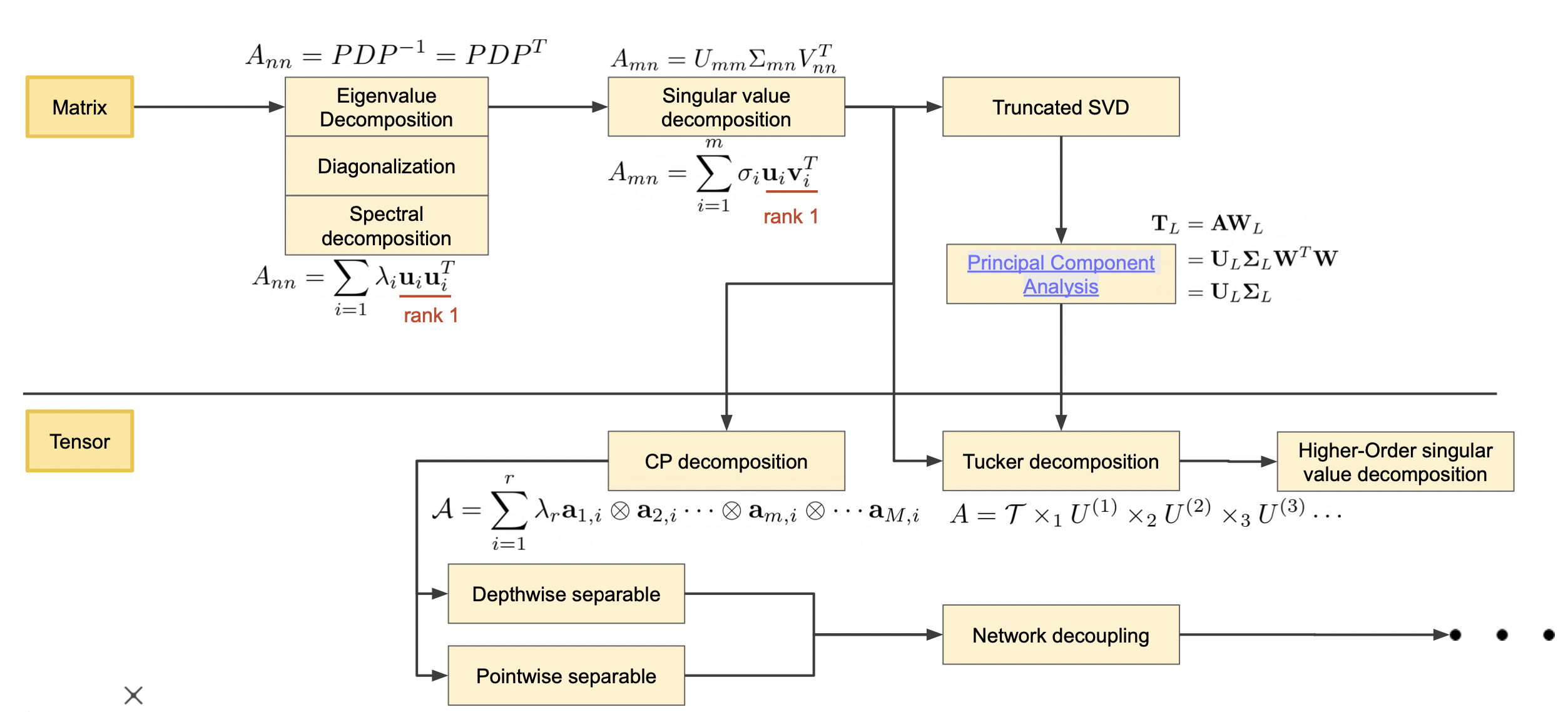
-
Matrix는 선형 변환
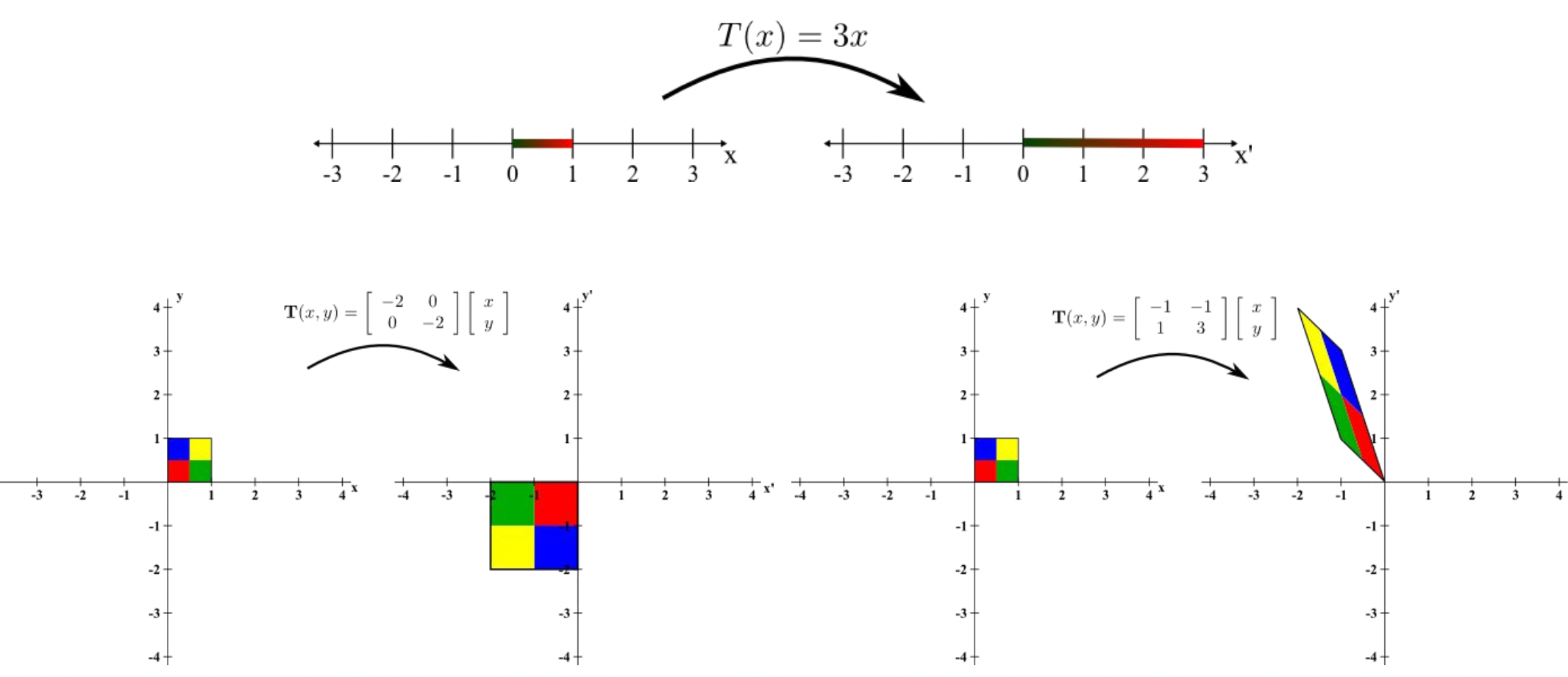
-
Matrix에 적용할 수 있는 기법들
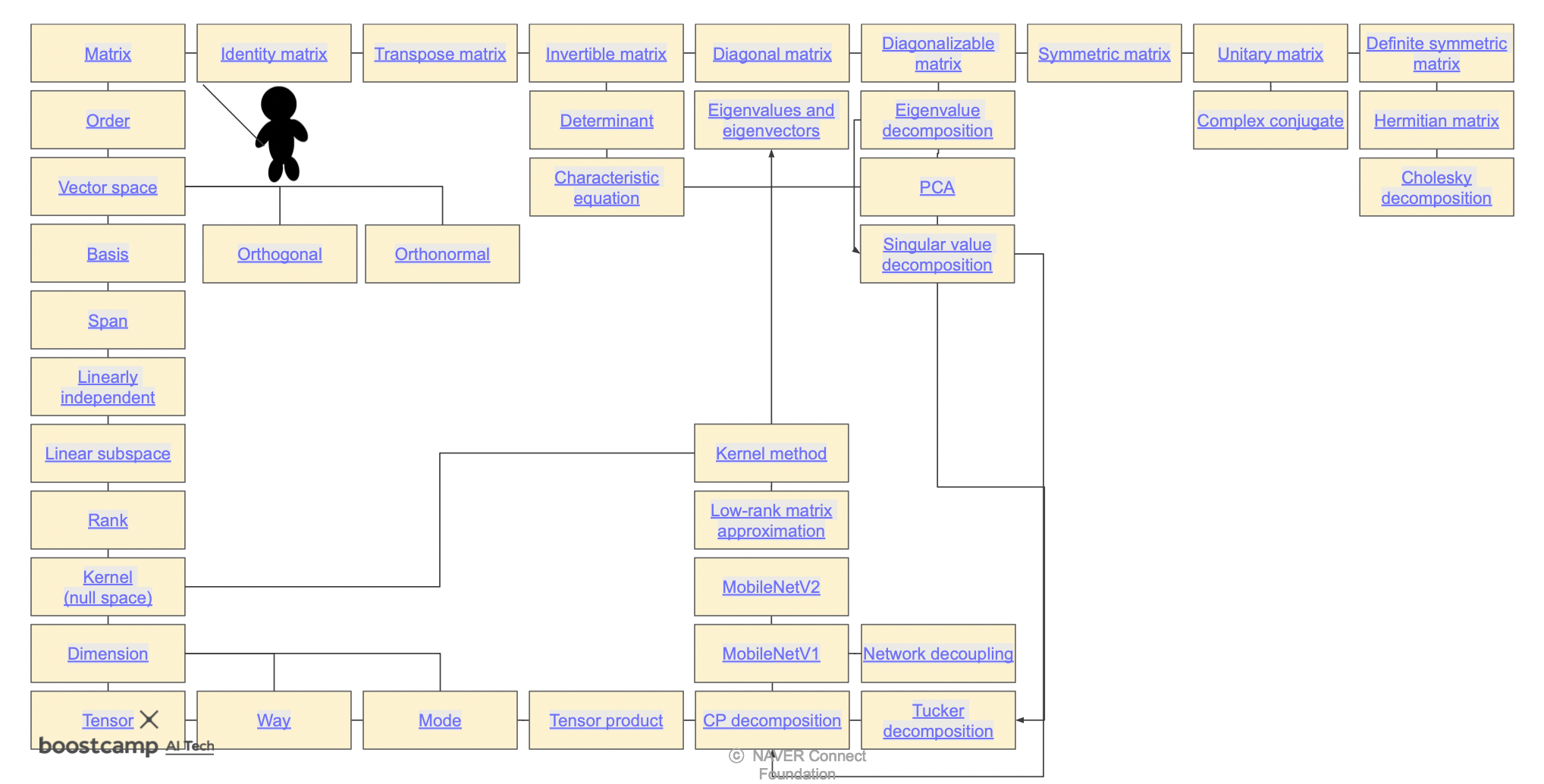
-
decomposition 종류
- Filter decomposition
- Matrix factorization
- Tensor factorization
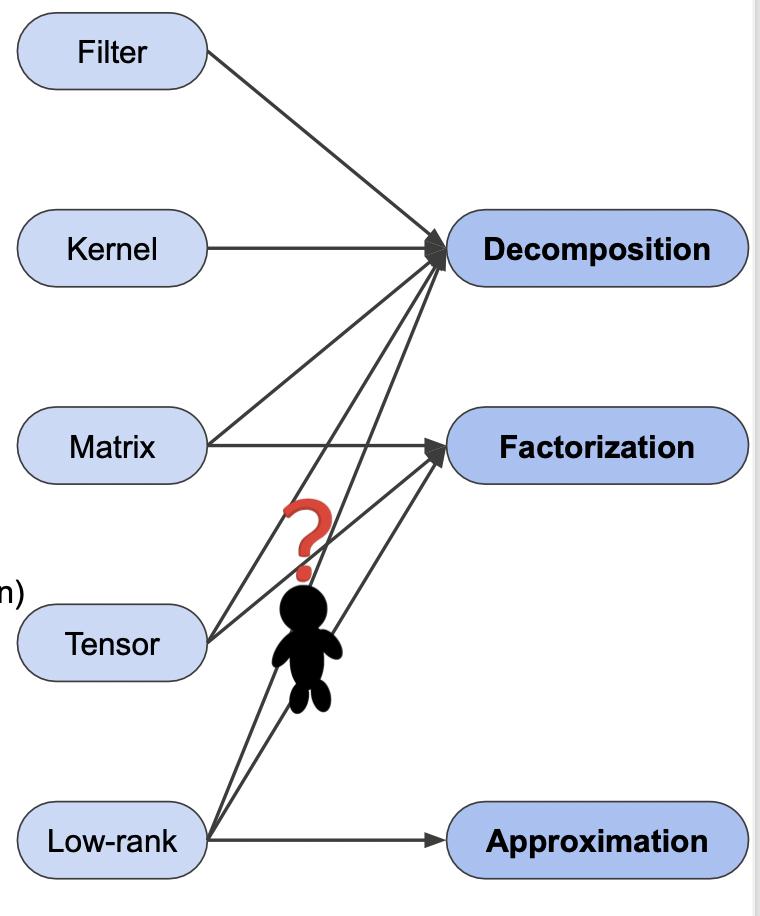
-
Tensor decomposition
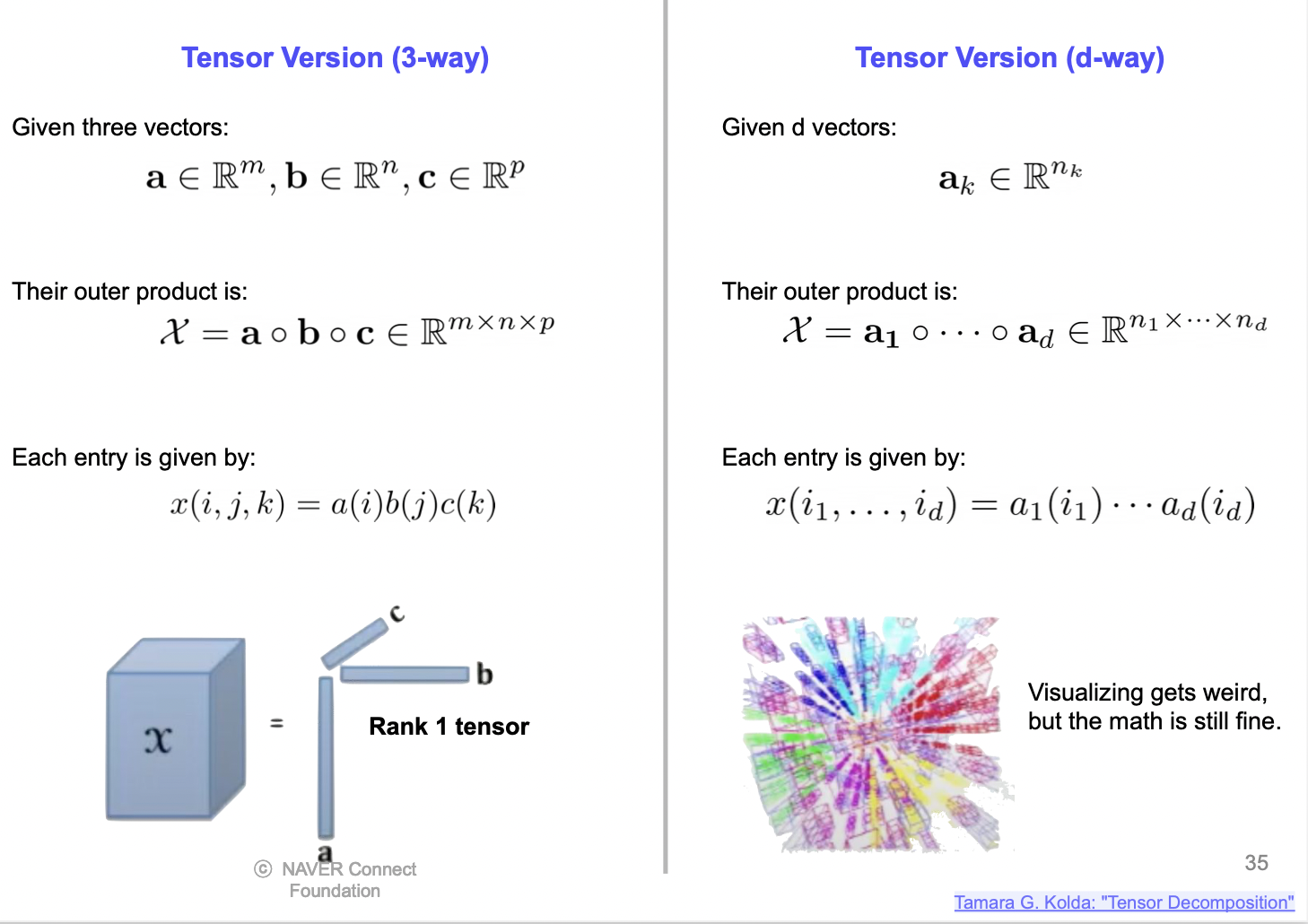
-
Tucker decomposition
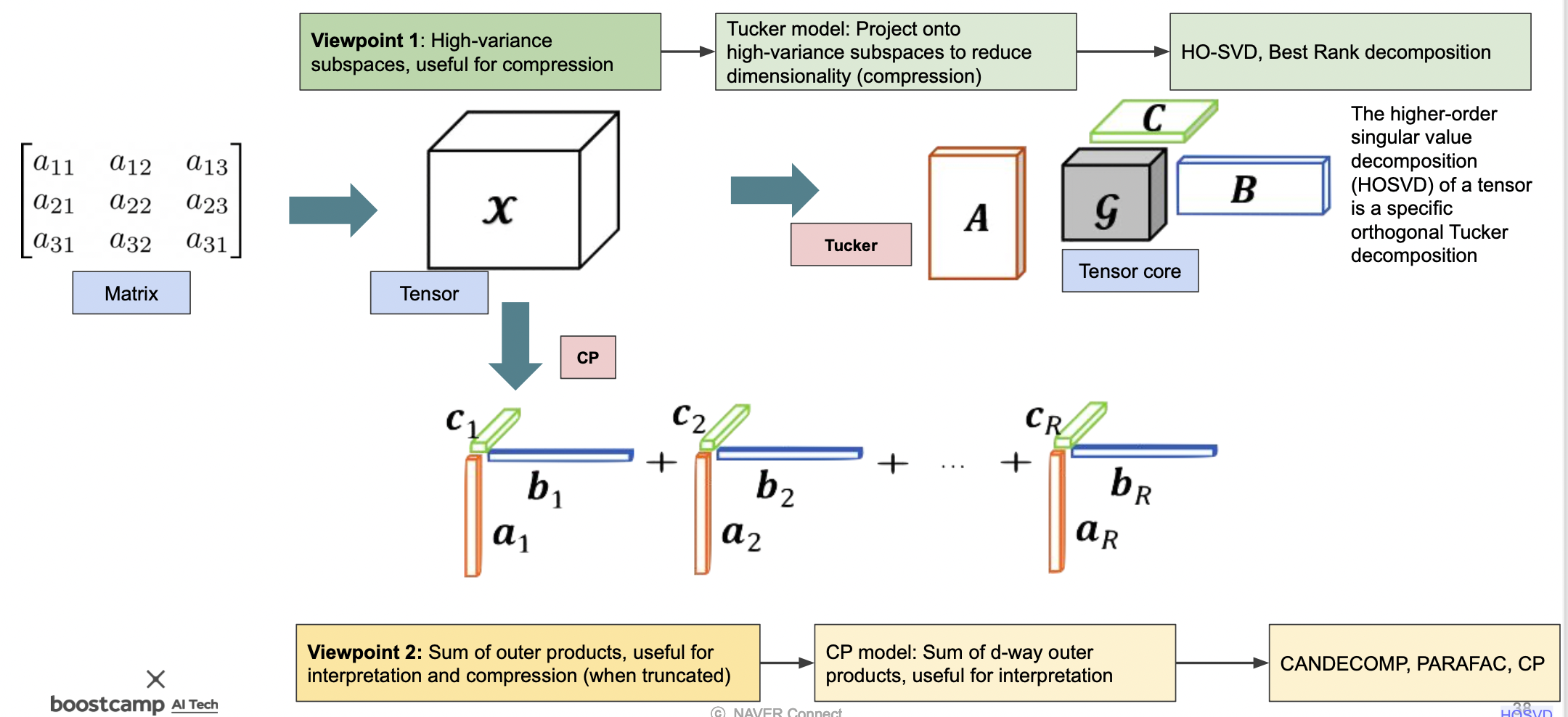
References
- http://chat.openai.com
- https://www.youtube.com/watch?v=91_hhex0CmU
- https://www.youtube.com/watch?v=AgezOkBTV90
- https://www.youtube.com/watch?v=f86hkOGoX54
- https://velog.io/@bismute/The-Lottery-Ticket-Hypothesis와-그-후속-연구들-리뷰
- https://www.youtube.com/watch?v=pgfsxe8sROQ
- https://velog.io/@dldydldy75/행렬-분해-Low-rank-Approximation
