그런데 너무 어려워서 계속 포기중이었다.. 그렇지만 응원을 받고 진짜 정복하겠다는 다짐...
만약에 이걸 보시는 다른 분들이있다면 포기하지마세유ㅜㅜ먼저 들어가기전에, DFS는 스택이나 재귀로, BFS는 큐로 구현하는것을 알고가자.
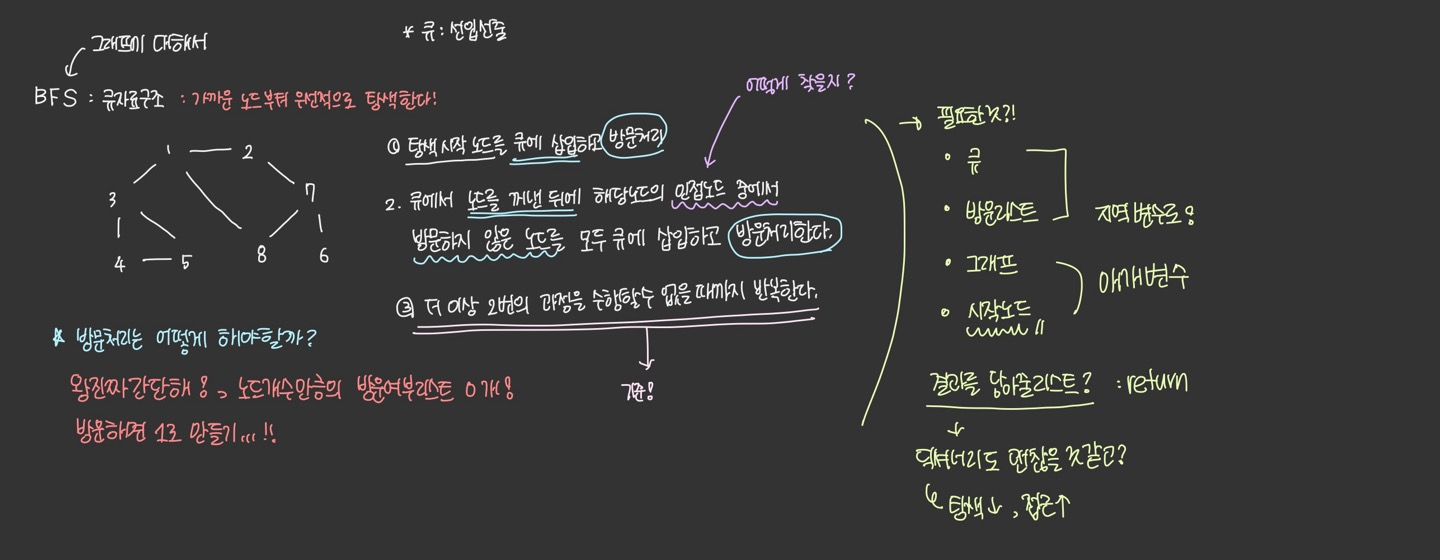
BFS
그래프를 전체 탐색하는 방법 중 하나로, 가까운 노드부터 탐색해 모든 노드에 딱 한번씩만 들리는 방법이다.
- 트리구조가 아니여도 탐색할 수 있다.
- 그래프와 탐색시작노드, 큐만 있다면!!
큐를 왜쓸까? : 다음에 탐색해야할 노드를 넣어놓는 바구니로!
BFS 과정
- 탐색 시작 노드를 큐에 삽입하고 방문처리
- 큐에서 노드를 꺼낸 뒤에 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문처리한다.
- 큐에 아무것도 남아있지 않을때까지 반복한다.
왜 BFS가 빠를까??
모든 노드를 순회하는 것이 아니라, 이미 간 노드는 순회하지 않기 떄문이다.
→ 방문처리를 통해서
방문 처리를 하는 방법
노드의 개수만큼 방문리스트를 만들어서 노드의 값을 인덱스로 가지는 요소에 표시, 딕셔너리 이용등등…
구현 코드
# BFS
from collections import deque
def bfs(graph, start):
queue = deque()
visited_list = [0] * len(graph)
BFS = deque()
queue.append(start)
visited_list[start - 1] = 1
while queue:
targetNode = queue.popleft()
BFS.append(targetNode)
for i in graph[targetNode - 1]:
if visited_list[i - 1] != 1:
visited_list[i - 1] = 1
queue.append(i)
return BFS
grap = [
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
BFS = bfs(grap,1)
print(str(BFS))DFS(깊이 우선 이동)
DFS는 스택이나 재귀를 사용하고, 노드의 경로 끝까지 간 후에 되돌아와서 다음 경로를 가는 알고리즘이다.
DFS 과정
- 스택에서 방문 노드를 꺼내고,
- 방문 노드가 방문처리가 안되어있다면, 방문 처리를 해주고
- 인접 노드들을 방문 예정 리스트에 추가
🤔 왜 중간에 방문처리를 하는가? 앞에 담긴 스택에는 담지 않기 위해서!
따라서 방문처리 표시 순서는 DFS랑 다를 수 있다!

코드
# BFS
from collections import deque
def dfs(graph, start):
stack = deque()
visited_list = [0] * len(graph)
DFS = deque()
stack.append(start)
j = 0
while stack:
targetNode = stack.pop()
visited_list[targetNode - 1] = 1
DFS.append(targetNode)
for i in graph[targetNode - 1]:
if visited_list[i-1] == 0:
visited_list[i - 1] = 1
stack.append(i)
return DFS
grap = [
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
BFS = dfs(grap, 1)
print(str(BFS))출력 결과
deque([1, 8, 7, 6, 3, 5, 4, 2])재귀로 풀어보기
def recursive_dfs(graph, start, visitList):
visitList.append(start)
for node in graph[start-1]:
if node not in visitList:
recursive_dfs(graph, node, visitList)
return visitList
grap = [
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
# BFS = dfs(grap, 1)
#
# print(str(BFS))
DFS = []
DFS = recursive_dfs(grap,1,DFS)
print(DFS)출력결과
[1, 2, 7, 6, 8, 3, 4, 5]마무리 하면서
그래프 탐색 알고리즘을 배워봤다.
잘 배워서 써먹었으면 좋겟다..

포기만 하지 않는다면 언젠간 도달한다!