알고리즘과 자료구조
1.[알고리즘 입문] 1. 알고리즘이란?

😑들어가면서😑
2.재귀 알고리즘
🤔들어가면서🤔
3.탐색 알고리즘 - 선형탐색과 이진 탐색
⭐ 정렬되지 않은 data set에도 사용할 수 있다.따라서 정렬되어 있지 않을 때 사용한다.순차적으로 모든 요소를 탐색하기 때문에 순차 탐색이라고 부른다. 평균의 경우 : O(n/2)최악의 경우 : O(n)👉 실행화면👉 실행화면정렬된 데이터 세트의 중간값을 기준으
4.정렬 - 버블정렬, 삽입정렬, 병렬 정렬
⭐들어가면서⭐ 🎯 목표 📌 버블 정렬 버블 정렬이란 숫자 리스트를 순회하면서 각 숫자를 다음 숫자와 비교하고, 순서가 틀렸으면 다음 숫자와 바꾸는 정렬 방법이다. 버블 정렬의 첫번째 순회 결과 : 가장 큰 숫자가 리스트의 마지막으로 온다. 즉, 가장 큰 숫자를
5.문자열 알고리즘 - 애너그램과 팰린드롬
📌 제거한 문자열의 결과를 저장해야한다.
6.시저의 암호 (ps. % 연산자 써먹기)
하나의 숫자를 선택하고 메시지의 모든 문자를 그 숫자만큼 이동시켜 새로운 메시지를 만드는 것이다.
7.수학 알고리즘 - 이진수 (ps.파이썬)
b2 = format(value, 'o2 = format(value, 'h2 = format(value, '\`\`\`
8.수학 알고리즘: 비트 연산자
비트 연산자
9.수학 알고리즘 - 최대 공약수
최대 공약수
10.수학 알고리즘 - 유클리드_(아직 완벽히 이해 X)

유클리도 알고리즘
11.수학 알고리즘: 소수
소수
12.자료구조란?
자료구조란, 개발자가 데이터를 저장하는 방법을 말한다.추상데이터 타입자료구조를 설명하는 데이터 타입이고 추상적인 개념이다.자료구조추상 데이터 타이을 실제로 구현한 결과를 말한다. 선형 자료구조데이터 요소를 순서대로 정렬한다.따라서, 순회에 재귀나, 백트래킹이 필요없다.
13.배열
배열과 리스트 모두 순서가 있으며, 연속적으로 값을 저장한다. 따라서 값이 저장된 상대적 위치인 인덱스를 가진다.순차적으로 접근이 가능하기 때문에, 빠르게 접근할 수 있다.일반적으로 배열은 동질적이며, 정적이다. 동일한 데이터 타입끼리만 저장이 가능하고, 자료의 크기를
14.링크드 리스트
추상 데이터 타입의 리스트를 구현한 자료구조이다.순서가 있는 값을 저장하지만 링크드리스트에는 인덱스가 없다.링크드 리스트는 순서가 있는 자료구조이지만 연속적인 메모리 블록에 저장되지 않는다.그 대신 링크드 리스트는 노드로 이루어져있다. 필드: 데이터를 보관 포인터: 다
15.스택
스택은 가장 마지막에 추가한 요소가 먼저 제거되는 선형 자료구조이다.즉, 후입 선출 자료구조이다. 추가나 제거에 제한이 있기 때문에 접근이 제한된 자료구조라고도 한다.푸시 : 스택에 요소를 뒤에 추가하는 것팝 : 스택에 마지막으로 추가된 요소를 꺼내는 것이다.➕ 픽 :
16.큐
어떤 데이터를 출력하느냐에 따라서 결졍된다.선입선출(FIFO) : 큐 가장 먼저 들어온 데이터를 출력한다.후입선출(LIFO) : 스택 마지막에 들어온 데이터를 출력한다.선입선출의 자료구조이다. 따라서 가장 먼저 들어온, 오래 기다린 데이터를 출력한다.큐도 스택처럼 접근
17.해시테이블
해시테이블 연관 배열이란? 연관 배열은 키를 사용해사 키-값의 쌍을 저장하는 데이터 타입이다. 키 : 값을 가져올 때 사용 값 : 키를 통해 가져온 데이터이다. 키-값 쌍 : 키와 값을 하나로 묶은 데이터이다. 해시 테이블이란? 연관 배열을 구현한 자료구조이다. 고
18.이진 트리
트리는 노드를 연결해 계층 구조를 만드는 비선형 추상 데이터 타입이다.트리에는 일반 트리, AVL 트리, 레드 블랙 트리, 이진 트리, 이진 탐색 트리가 있다.맨 위에 하나의 노드를 두고 시작하는 자료구조를 말한다. 루트노드 : 트리의 맨 위에 있는 노드자식 노드 :
19.이진 힙
우선순위 큐란, 각 데이터에 우선순위가 있는 자료구조를 정의하는 추상 데이터 타입이다.즉, 데이터가 우선순위를 가지고 있기 때문에 우선순위에 따라 요소를 꺼낼 수 있다.우선순위를 구현한 구체적인 데이터 타입이 힙이다.힙은 트리 기반의 자료구조로, 각 노드는 값(키)과
20.문자열 검색 알고리즘 : 브루트 포스 - 백준 1543
문자열 검색 알고리즘 문제 설명 - 1543번 문제 검색 첫째 줄에 문서가 주어진다. 문서의 길이는 최대 2500이다. 둘째 줄에 검색하고 싶은 단어가 주어진다. 이 길이는 최대 50이다. 문서와 단어는 알파벳 소문자와 공백으로 이루어져 있다. 문서에서 단어가 최대
21.DFS(깊이우선탐색), BFS(너비우선탐색)을 정복하자!!
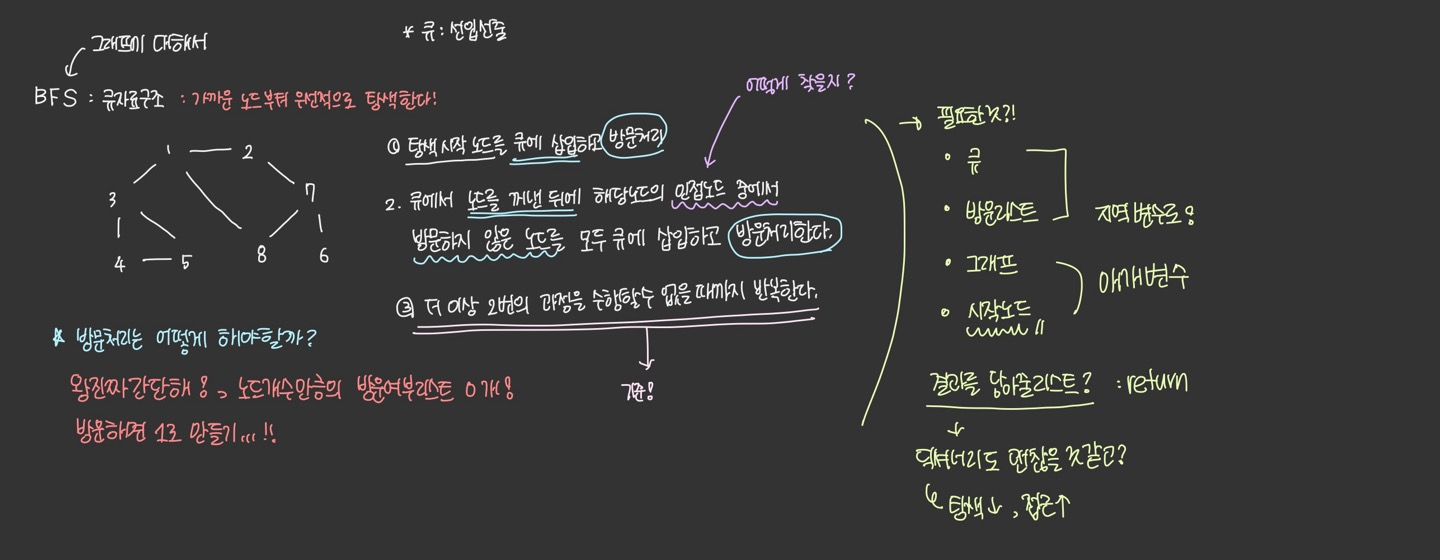
백트래킹이란, 해를 찾는 도중 해가 아니어서 막히면 되돌아가서 다시 해를 찾아가는 방법이다. 지금의 경로가 해가 될 것 같지 않다고 느껴질 때, 그 경로를 가지 않고 가지치기를 하기 때문에 효율적이다. 따라서 가지치기를 얼마나 잘 하느냐에 따라 효율성이 결정이 된다.보
22.퀵 정렬
퀵 정렬은 pivot을 사용해, pivot을 기준으로 분할하며 정렬해나간다.각 단계의 목표는 pivot 앞에는 모두 pivot 보다 작도록,pivot 뒤에는 모두 pivot 보다 크도록 만들어준다.분류가 끝난 후에는 pivot을 기준으로 앞,뒤로 분할해 다시 진행한다.