
🚨 Abstract
✅ Pre-training에서 희귀 단어에 대한 노트 사전을 생성하면 더 빠르고 안정적입니다.
✅ 노트 사전을 업데이트하고 유지하기 위한 노트 임베딩을 소개합니다.
🔑 Method
1. 노트 사전 구축
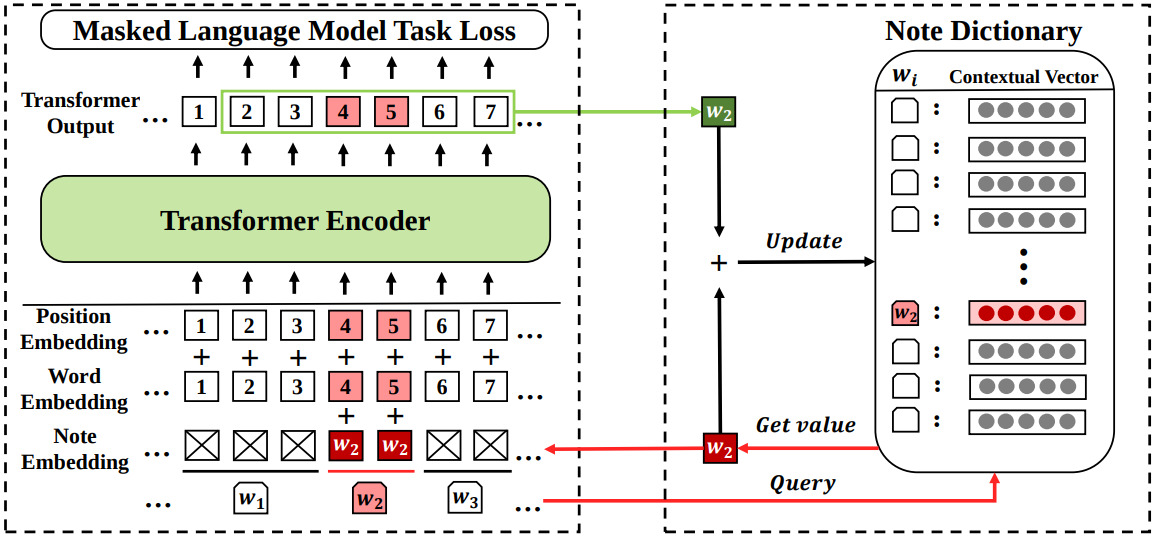
왼쪽 상자는 노트 사전의 도움을 받아 전방향 패스를 보여줍니다. 입력 단어 시퀀스에서 는 희귀한 단어입니다.
그리고 에서 비롯된 토큰 4와 5에 대해서 우리는 노트 사전에서 의 값을 조회하고 토큰/위치 임베딩과 가중 평균을 계산합니다.
오른쪽 박스는 노트 사전을 어떻게 유지하는지를 보여줍니다.
모델의 forward pass 이후, 근처 단어의 문맥적 표현을 얻을 수 있으며, 이러한 표현에 대한 평균 풀링을 사용하여 현재 문장에서 의 노트로 사용합니다.
그런 다음, 의 노트 사전 값에 현재 노트와 이전 값의 가중 평균을 통해 업데이트합니다.
2. 노트 사전 유지 관리
입력 토큰 시퀀스 및 노트 사전에 모두 나타나는 희귀한 단어 에 대해서, 내에서 의 범위 경계를 로 표시하며, 여기서 와 는 시작 위치와 끝 위치입니다.
의 에 대한 노트는 다음과 같이 정의됩니다.
여기서 는 위치 에서의 인코더 출력으로 의 문맥적 표현으로 사용되며, 는 주변 토큰을 몇 개의 노트로 취할지와 그들의 embedding을 저장할 window 크기의 절반을 나타냅니다.

안녕하세요, AI를 좋아하는 AI 엔지니어입니다