1. 안드로이드 앱 컴파일 방법
MacroBacnmark와 Baseline Profile을 사용해 성능 측정 및 개선을 위해선 안드로이드 앱의 컴파일 단계를 먼저 알 필요가 있다. 그래야 성능 측정 방법과 결과가 이해되기 때문이다. 안드로이드 앱은 총 3단계로 컴파일된다.
Step1. Kotlinc 컴파일
Java에선 소스 코드를 Javac컴파일러로 컴파일하여 .class 확장자의 바이트 코드를 생성한다.
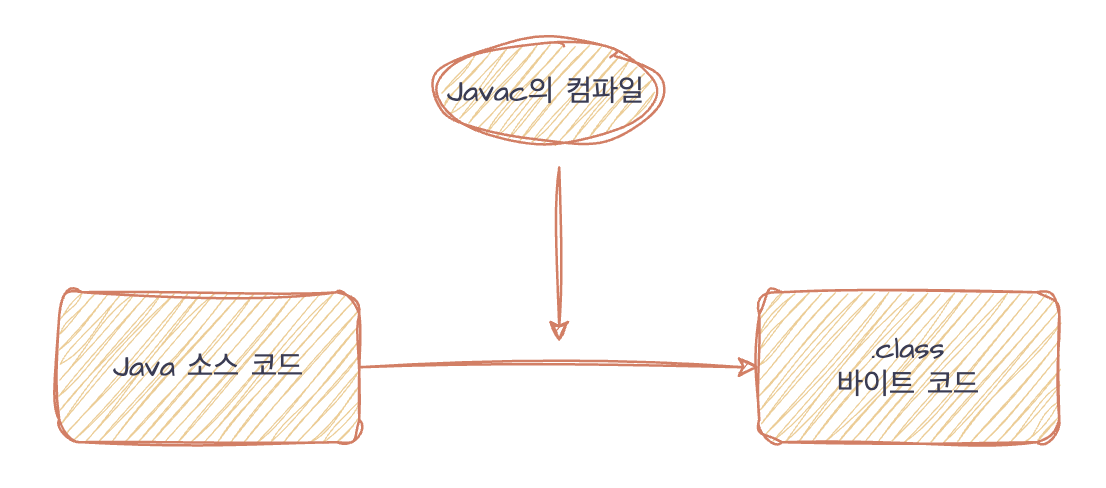
하지만 Kotlin은 kotlinc 컴파일러로 소스코드를 컴파일해 바이트 코드를 생성한다. 또한 이는 javac와 다른 한 가지 차이점이 있는데, 그것은 바로 kotlin언어는 기존 java 클래스, 함수에 부가 기능을 확장함수로 추가 제공한다는 점이다. 따라서 javac는 .class로만 바이너리 파일을 생성하지만 kotlinc는 .class파일을 포함, kotlin 전용 확장 함수를 포함한 .jar파일로 패키징을 진행한다는 점이다. 이는 마치, JRE(Java Runtime Environment)에 Java의 여럿 유틸리티 메서드들(eg. java.lang.*, java.util)을 기본으로 제공해주는 것과 같은 원리이다.
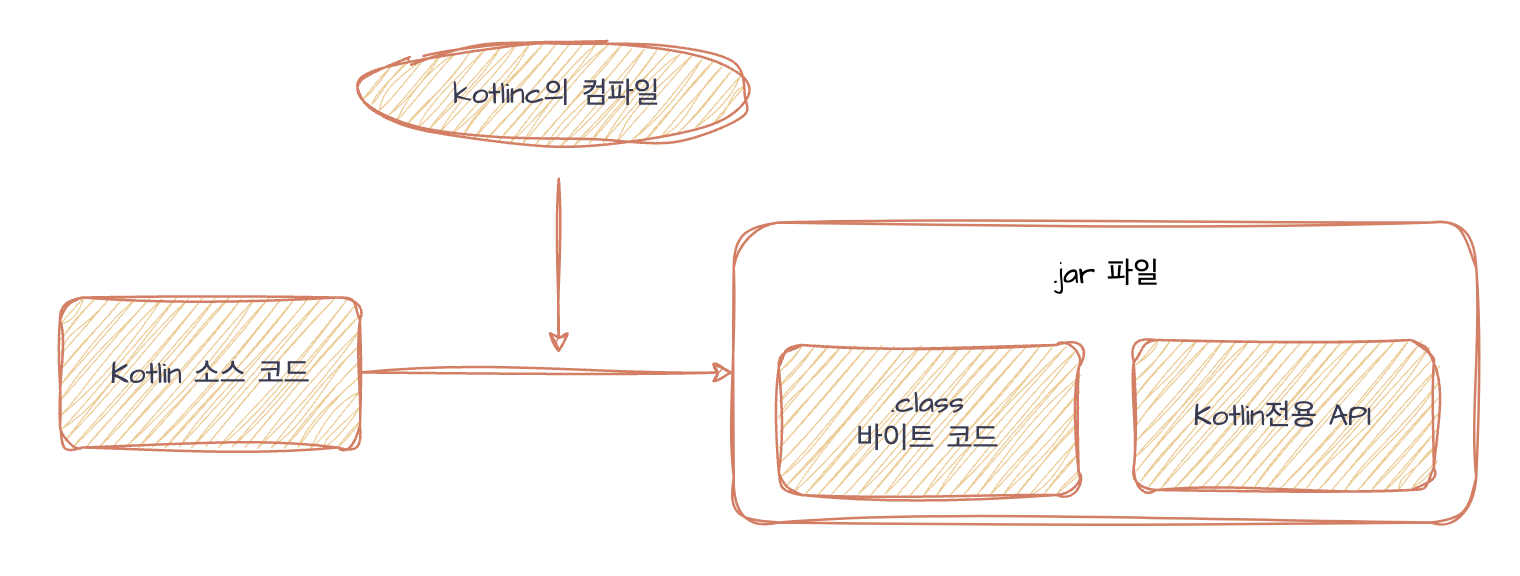
Step2. R8 컴파일
.class or .jar로 탄생된 바이트 코드는 .jks확장자의 키파일과 함께 R8에 의해 .dex확장자의 바이트 코드로 변환된다. 그리고 이러한 .dex파일들이 모여 .apk파일이 만들어 진다.
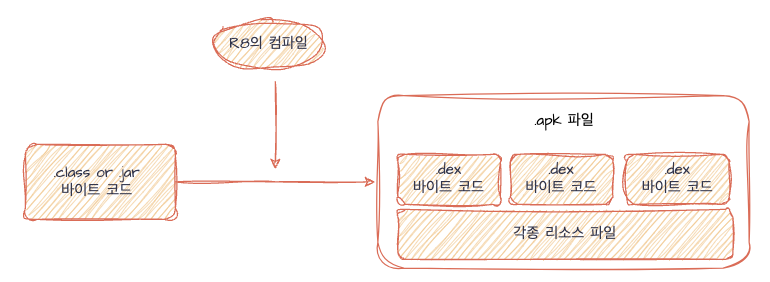
이를 쉽게 확인해볼 수 있는게, .apk파일의 확장자를 .zip으로 변경 후, 압축을 해제해보면 .dex파일들로 구성돼있는걸 볼 수 있다.
Step3. AOT or JIT 컴파일
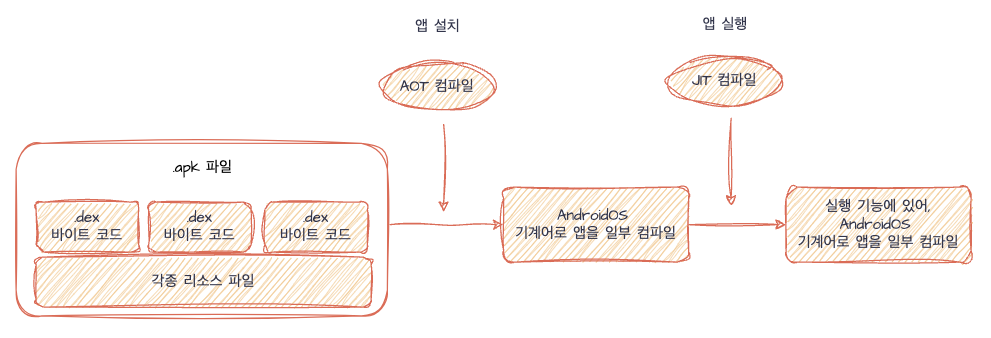
.apk파일이 플레이 스토어에 업로드 되고 사용자는 이를 다운받는다. 이때, 첫 번째로 AOT(Ahead Of Time)컴파일이 일어나는데, 이는 .dex바이트 코드를 AndroidOS가 이해 가능한 기계어로 변경되어 앱에 설치되는걸 의미한다. 하지만 모든 .dex파일이 사전 AOT 컴파일 되는건 아니기에, 일부분은 앱 실행 또는 버튼 클릭 등 런타임에 JIT컴파일이 일어나며 기계어로 변환된다.
AOT컴파일은 앱이 설치될 때, 기계어로 변환하는 만큼 설치 속도를 늦춘다는 단점이 있다. 하지만 기계어로 미리 컴파일 해놓기에, 런타임때 앱의 성능이 JIT에 비해 빠르다는 점이다. 반면, JIT컴파일은 앱을 처음 실행하거나 런타임 때, 그때그때 기계어로 컴파일한다는 점이다. 따라서 JIT컴파일 방식은 앱 설치는 빠르나, 런타임 성능이 떨어진다는 단점이 있다.
Android는 4.0 버전까진 Dalvik 가상머신의 JIT 컴파일 방식을 100%로 채택했다. 하지만 런타임 성능 저하로 인해 5.0 ~ 6.0버전엔 ART 가상머신의 AOT 컴파일 방식을 100% 채택했었다. 이를 통해 앱 실행속도는 전보다 빨라졌지만, AOT방식의 단점인 앱 설치속도 저하 및 사용성 감소 이슈가 발생했다. 이로 인해 7.0버전부턴 AOT + JIT의 하이브리드 방식이 지금까지 이어져 오고 있다. 따라서 안드로이드 가상머신의 변화와 컴파일러 변천사에 맞춰 AOT와 JIT의 장단점을 잘 이해하고, AOT컴파일을 지점을 잘 선별해 Baseline Profile을 사용을 결정해야 한다.
| OS | VM | Compile 방식 | 설명 |
|---|---|---|---|
| 2.x ~ 4.0 | Dalvik | 100% JIT | 앱 실행 때, .dex파일을 Native Code로 변경 |
| 5.0 ~ 6.0 | ART | 100% ART | 앱 설치 때, .dex파일을 Native Code로 변경 |
| 7.0 | ART | JIT + AOT(초기엔 AOT많음) | 설치 시간 감소를 위해 일부만 AOT, 나머진 JIT |
| 8.0 ~ | ART | JIT + AOT(Profile Guided Compilation) | 앱 실행 패턴 분석하여 자주 사용 코드만 AOT 컴파일. 나머진 JIT로 실행. |
이렇게 안드로이드 앱이 컴파일 되기까지 3단계를 짚어봤다. 이를 그림으로 나타내면 아래와 같다.

2. MacroBenchmark 성능 측정
Benchmark란, 네트워크와 로컬 저장소 등 각종 데이터 통신을 포함하여 실 사용자 환경을 가정해 앱의 성능을 측정하는 기술이다. 이를 통해 여러가지 성능 측정이 가능한데, UI의 프레임 렌더링, 메모리/CPU 사용량, 앱 시작 시간 등을 측정할 수 있다. 그리고 이를 metrics 라는 파라미터를 통해 지정할 수 있다. 벤치마크는 아래와 같은 코드로 측정한다.
@RunWith(AndroidJUnit4::class)
class ScrollBenchmarks {
@get:Rule
val benchmarkRule = MacrobenchmarkRule()
@Test
fun scroll() {
benchmarkRule.measureRepeated(
packageName = "com.example.macrobenchmark_codelab",
compilationMode = CompilationMode.None(),
iterations = 5,
metrics = listOf(StartupTimingMetric()),
startupMode = StartupMode.COLD,
setupBlock = {
// TODO Add not measured interactions.
}
) {
// TODO Add interactions to measure list scrolling.
}
}1. CompilationMode
위에서 다음과 같이 설명했다.
.apk파일은.dex파일들로 구성돼 있음..dex바이트 파일은AOTorJIT컴파일 방식에 따라 기계어로 변경되는 시기가 다름.AOT는 앱 설치 직후에JIT은 앱 실행/런타임에 진행.
CompilationMode는 위의 AOT or JIT컴파일 방식을 지정해주는 파리미터이다. 즉, CompilationMode의 타입에 따라 앱의 원하는 부분에 AOT 컴파일 방식 지정이 가능하단 뜻이다. 그럼 어떤 타입이 있는지 알아보자.
1. None
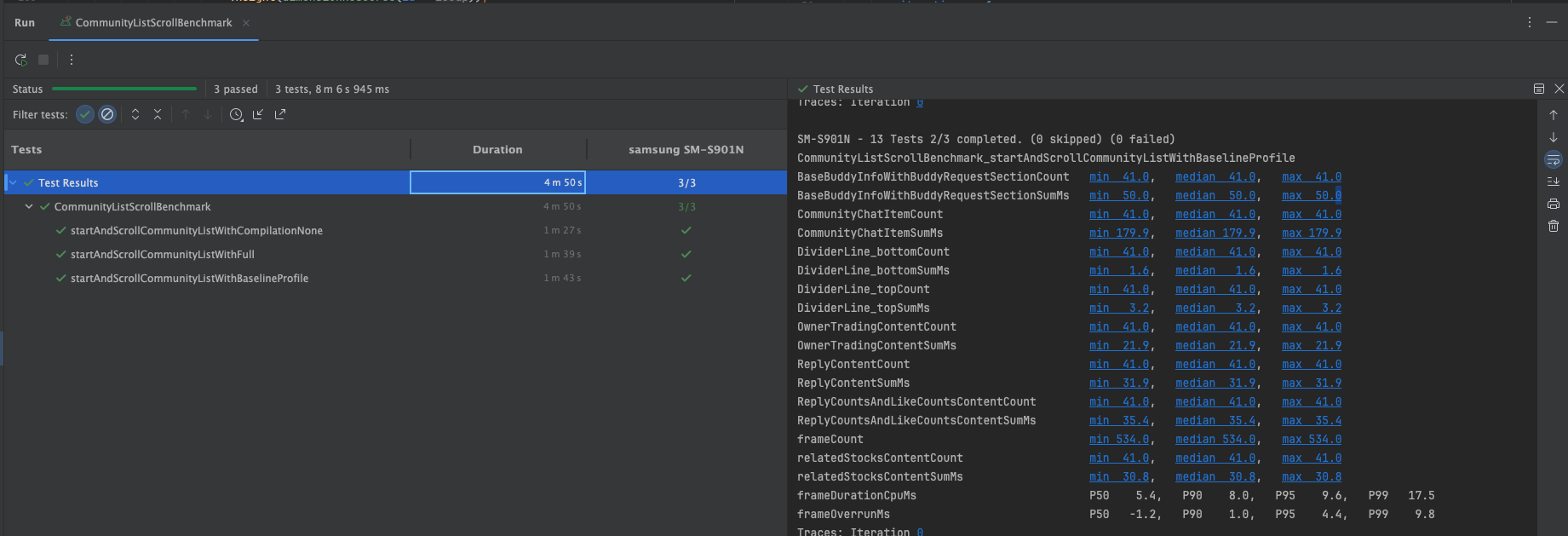
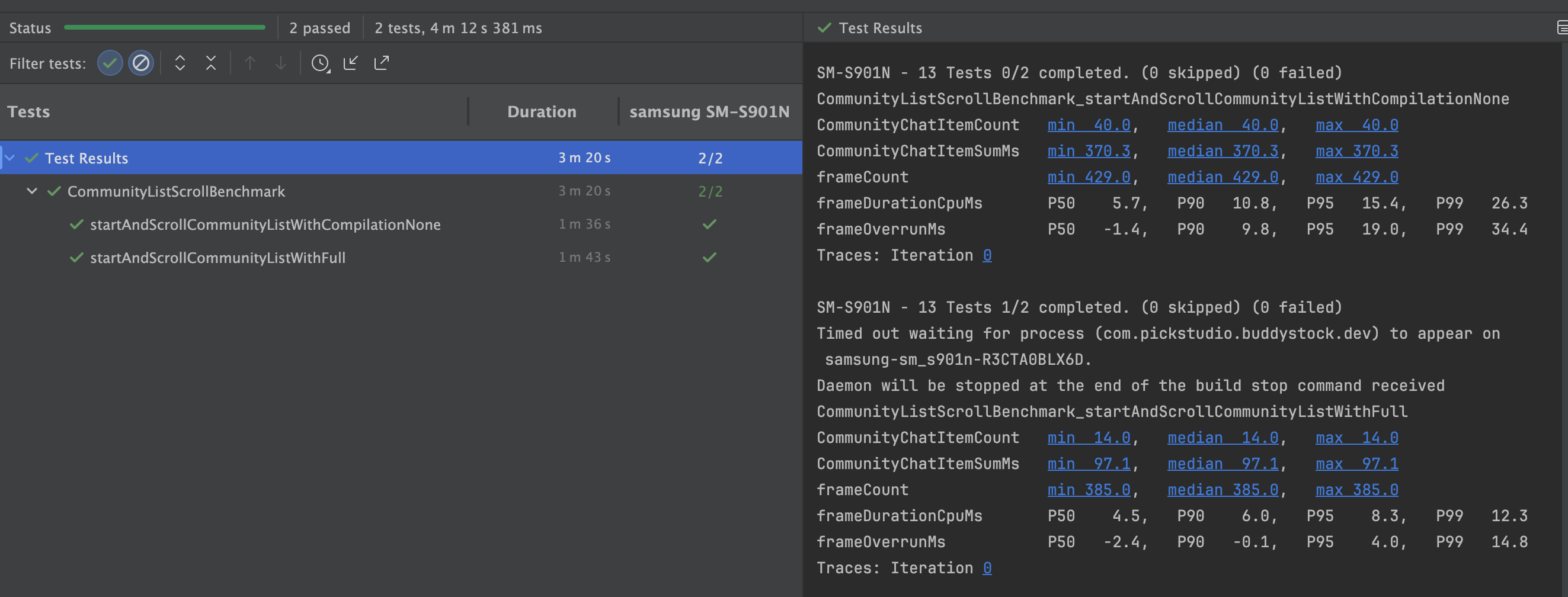
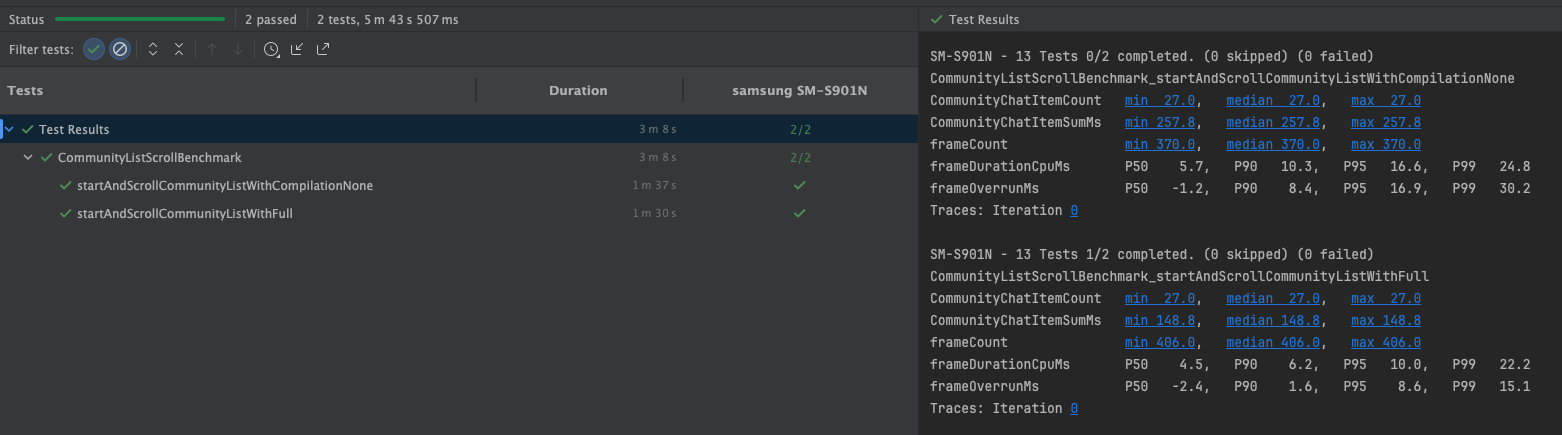
앱을 설치할 때, 어떤 컴파일도 진행하지 않겠다고 선언하는 파라미터이다. 즉, AOT가 아닌 JIT컴파일 방식을 사용하겠다는 의미이다. 따라서 이 방식을 통해 벤치마크를 측정한다면 앱의 런타임 성능이 매우 안좋게 나올 수 있다는 것을 알아야 한다.
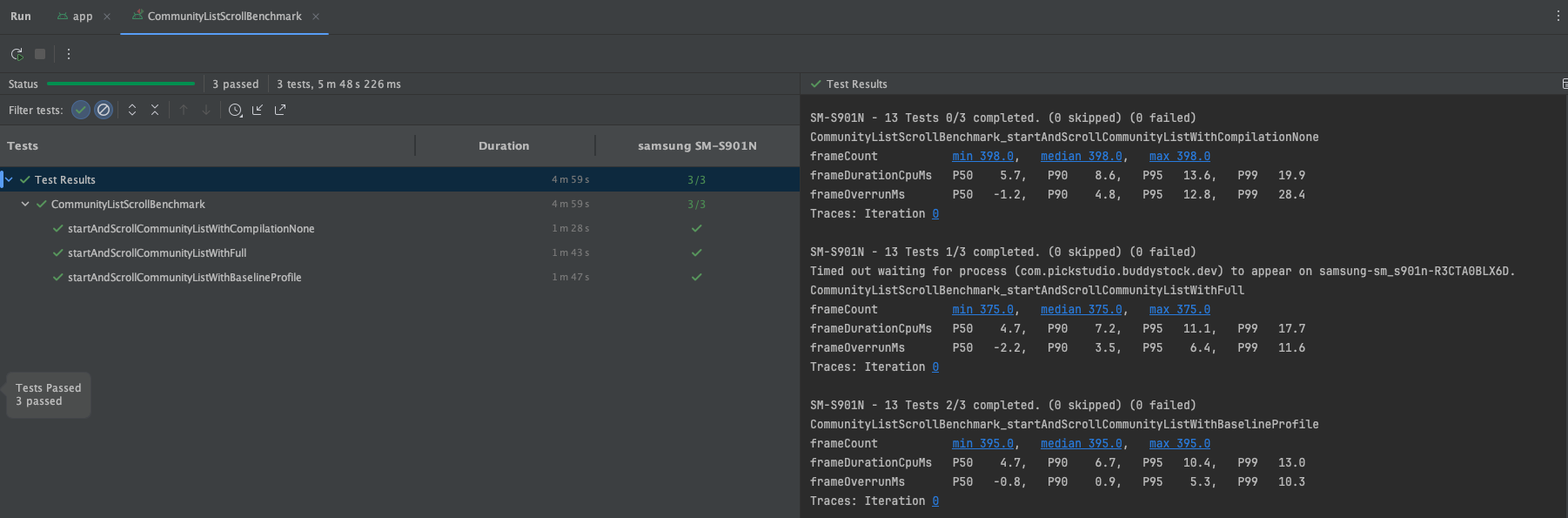
위 이미지는 필자가 유지보수중인 앱의 스크롤을 벤치마킹한 결과이다. None타입 즉, JIT 컴파일 방식의 앱 성능이 다른 컴파일 방식보다 2 ~ 3배 안좋은 것을 확인할 수 있다.(frameOverrunMs기반) 그 이유는 위에서도 말했다시피, None타입은 앱 실행과 런타입에 dex파일을 기계어로 바꿔주는 작업을 시시때때로 진행하므로 성능이 안좋은 것이다. 반면, 그 밑의 AOT컴파일 방식의 벤치마크들은 성능이 더 좋을걸 확인할 수 있다.
다만,
JIT컴파일 방식 벤치마킹 때 주의할 점이 있다. ART는 사용자가 앱에서 자주 사용하는 부분을localProfile에 적어둔다. 그 후, 앱의 유휴 시간때 해당 부분을AOT컴파일에 포함시킨다. 따라서JIT컴파일 방식에iterations파라미터를 사용해 여러번 측정했을 때 성능이 이전보다 좋게 나올 수 있다는걸 염두해야한다.
참고 : ART 작동 방식
2. Partial
개발자가 직접 설정한 BaselineProfile기반으로 AOT컴파일부분을 지정할 때 때 사용한다. 따라서 부분 지정인 만큼 앱의 다른 부분은 JIT컴파일 방식이 적용될 수 있다는 점을 알아야 한다.
Partial은 3가지 타입이 존재하는데, Required/UserIfAvailable/Disabled가 있다. 필자는 개인적으로 해당 CompilationMode는 BaselineProfile이 있다는 가정 하에 사용하므로 Required를 설정해서 진행하는게 좋아보인다.
Q. 벤치마크 미적용시, 부분적으로
AOT컴파일 된다 한다. 이때 어떤 부분이JIT이 적용되고 어떤 부분이AOT가 될까?
A. 해당 내용은 공식 홈페이지엔 나와있지 않아 GPT에게 물어봤다. 그 결과, 이는 블랙박스라 한다. 즉, 개발자가 알 수 없으며 ART에 의해 임의로 결정된다고 한다. 따라서 개발자 입장에서 렌더링 최적화가 필요한 부분은 BaselineProfile사용 및AOT컴파일 적용을 통해 해당 UI에는 확실한AOT컴파일 방식 보장으로 UI성능의 일관성을 보장할 수 있다고 생각한다.
3. Full
앱을 전체적으로 AOT컴파일 하고자할 때 사용한다. 앱 런타임 성능은 좋을 수 있으나, 설치 속도가 매우 느려질 수 있다는 단점이 존재한다.
2. Metrics
1. StartupTimingMetrics
[TTID(Time To Initially Display MS]
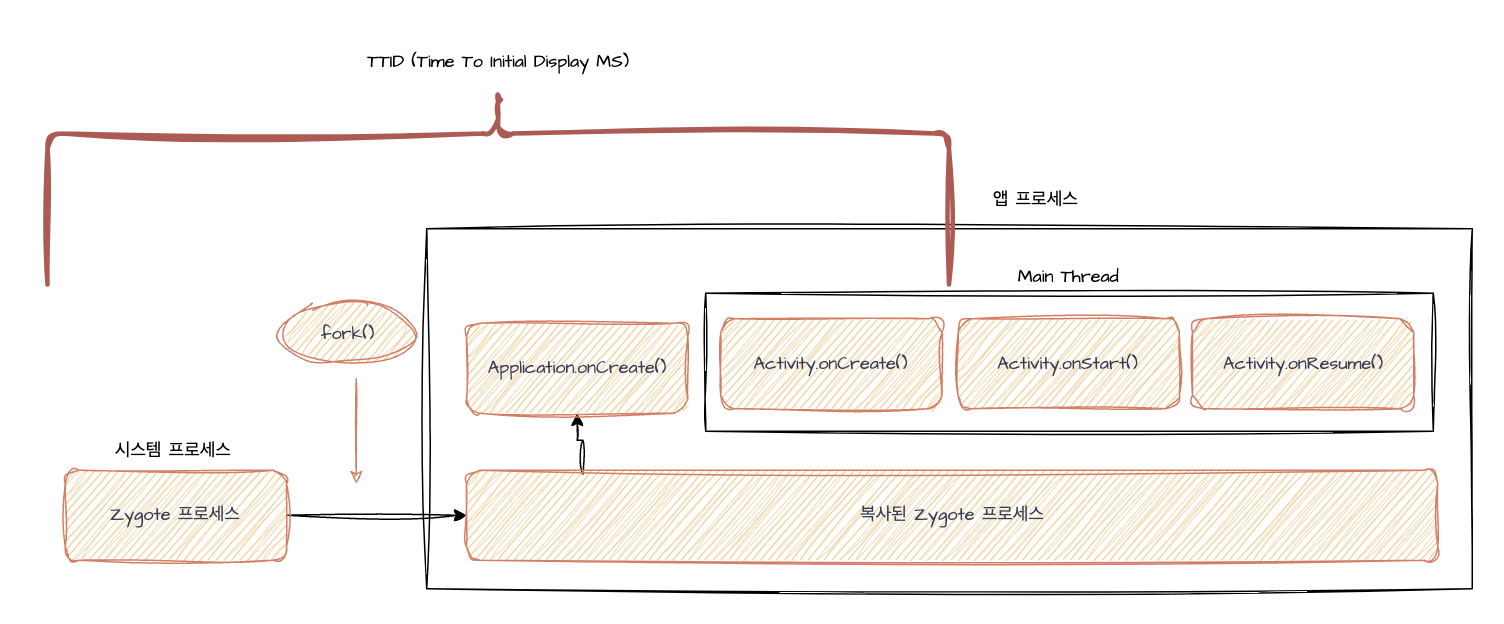
앱 시작 시간을 측정할 수 있으며, 출력 값은 TTID(Time To Initial DisplayMs)와 TTFD(Time To Fully DisplayMs)가 있다. TTID는 Intent의 LaunchMode로 지정된 Activity가 첫 번째 프레임을 그리기까지의 시간을 의미한다. 좀 더 깊게 이야기해보면, Choreographer가 UI 렌더링을 시도하며, onDraw()메서드가 첫 호출되었을 때를 의미한다. 이는 UI 렌더링 전체 그림 중, 아래 붉은색 표시 시점을 의미한다.
[TTID(Time To Fully Display MS]
TTFD는 TTID의 완료 직후 즉, 첫 번째 프레임 렌더링 완료 이후에 네트워크/로컬 등 각종 데이터가 UI에 모두 로딩되어 사용자가 앱을 온전히 사용할 수 있기 까지의 시점을 의미한다. 안드로이드 시스템은 UI 데이터가 언제 어떻게 로딩될지 알 수 없다. 따라서 로딩 완료 시점은 개발자가 안드로이드 시스템에 알려줘야 하며 이는 reportFullyDrawn()을 호출로 가능하다.
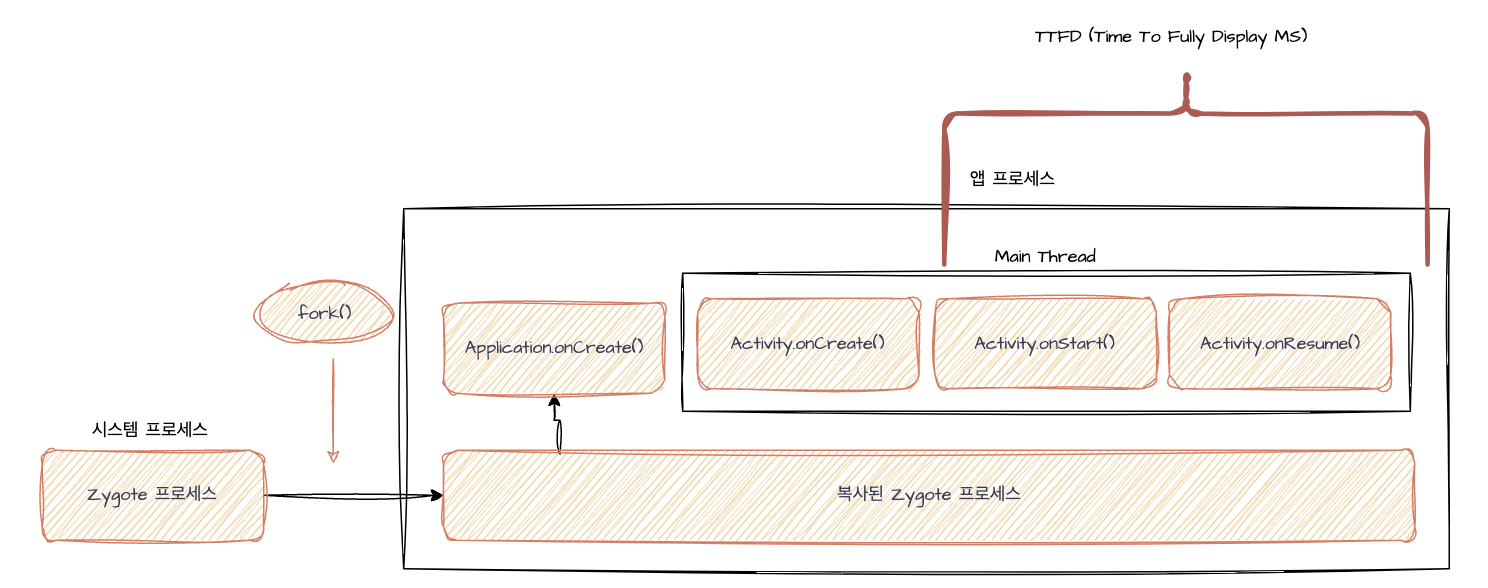
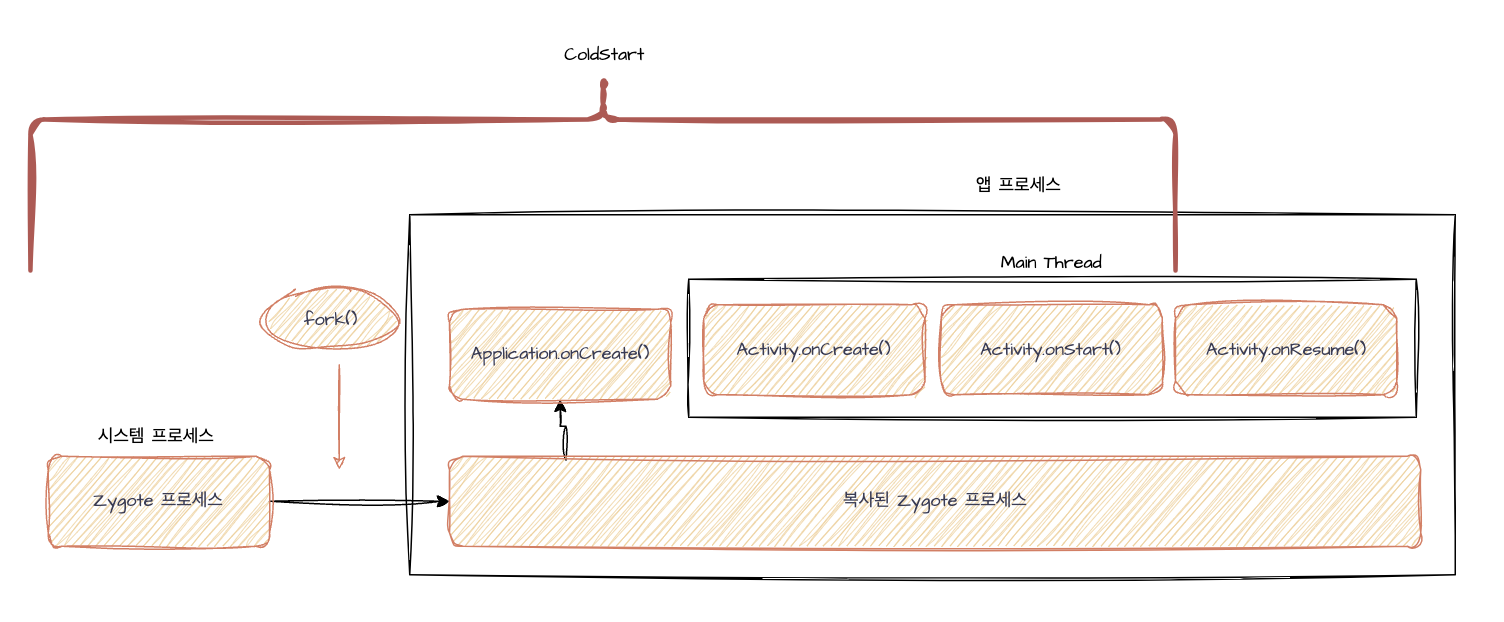
다만, 앱 시작 시간 측정 및 최적화를 위해선 앱이 어떤 방식으로 시작되는지 또한 알 필요가 있다. 이를 알아야 어떤 시작 모드에서 앱을 테스팅할지 결정할 수 있다. 앱 시작 경우의 수는 3가지가 존재하며 이는 ColdStart, WarmStart, HotStart가 있다.
[ColdStart]
시스템 프로세스 초기화부터 시작해 앱 프로세스까지 전체적으로 초기화하는 시작 방식을 의미한다.
시스템 프로세스라 하면 앱 프로세스 생성에 기반이 되는 시스템 프로세스인 Zygote프로세스가 있다. 이는 내부적으로 Android 커널 자원에 액세스할 수 있는 네이티브 API들과 안드로이드 리소스를 제어해주는 ART, 그리고 기본 Android 어플리케이션의 API들이 존재한다. 따라서 앱을 처음 시작했을 땐 이러한 Zygote프로세스를 시작시켜야만 한다.
앱 프로세스라 하면 안드로이드 어플리케이션 생성 시작을 의미하는 Application.onCreate()의 호출부터 시작해 메인 스레드 생성 후, Activity.onStart()까지의 호출을 의미한다.
따라서 위의 의미대로 Zygote프로세스 시작부터 Activity.onStart()의 초기화까지 앱이 시작되는 방식을 ColdStart 시작이라 한다. 실생활 예로, 앱을 처음 실행시켰을 때를 의미한다.
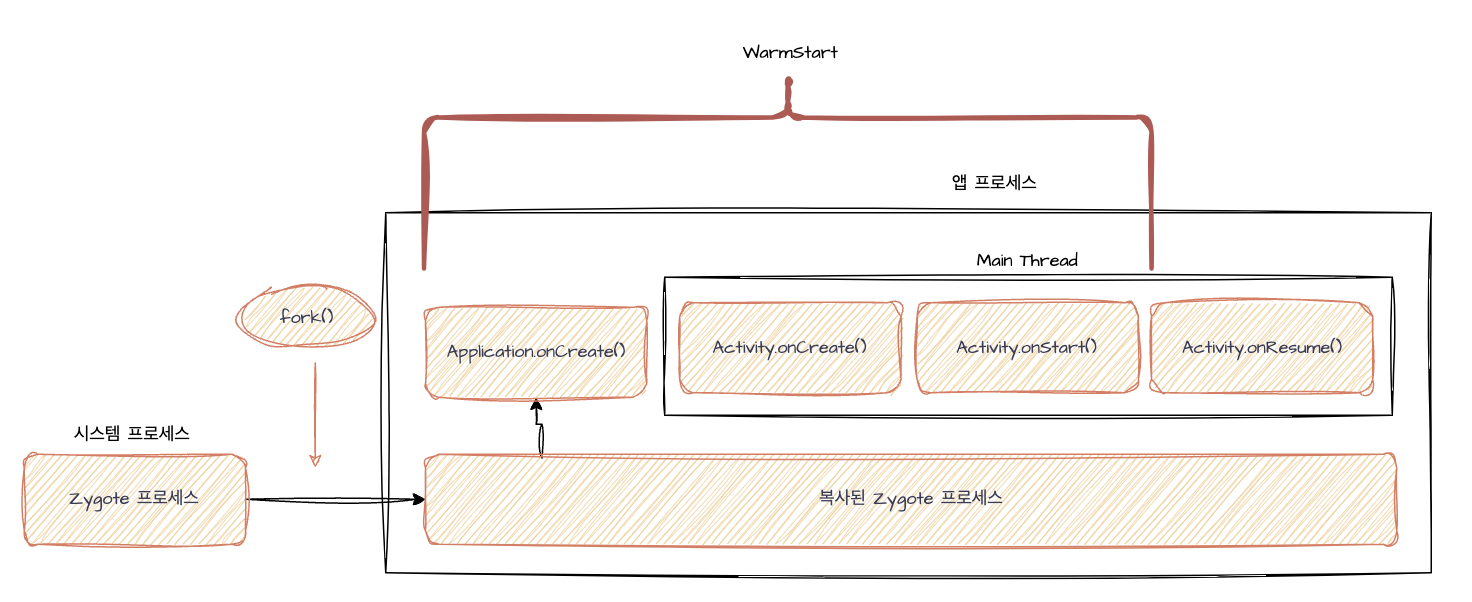
[WartStart]
ColdStart가 시스템 프로세스 초기화를 포함한 앱 실행을 의미했다. 반면, WartStart는 Zygote 프로세스의 fork작업 완료와 MainThread 생성은 이미 완료된 상태에서 Activity.onCreate()부터 시작해 앱을 실행시키는 방식을 의미한다. 대표적인 예로 홈 버튼을 눌러 앱을 백그라운드 상태로 오랜 시간을 둔다. 그 후, 다른 앱을 많이 사용하다 시스템 메모리가 부족한 상황이 발생해 AndroidOS에서 사용중이지 않은 앱의 Activity 프로세스를 정리(=onTrimMemory()호출)하고 onDestroy()가 호출된다. 이때, 앱을 실행하는 경우를 의미한다.
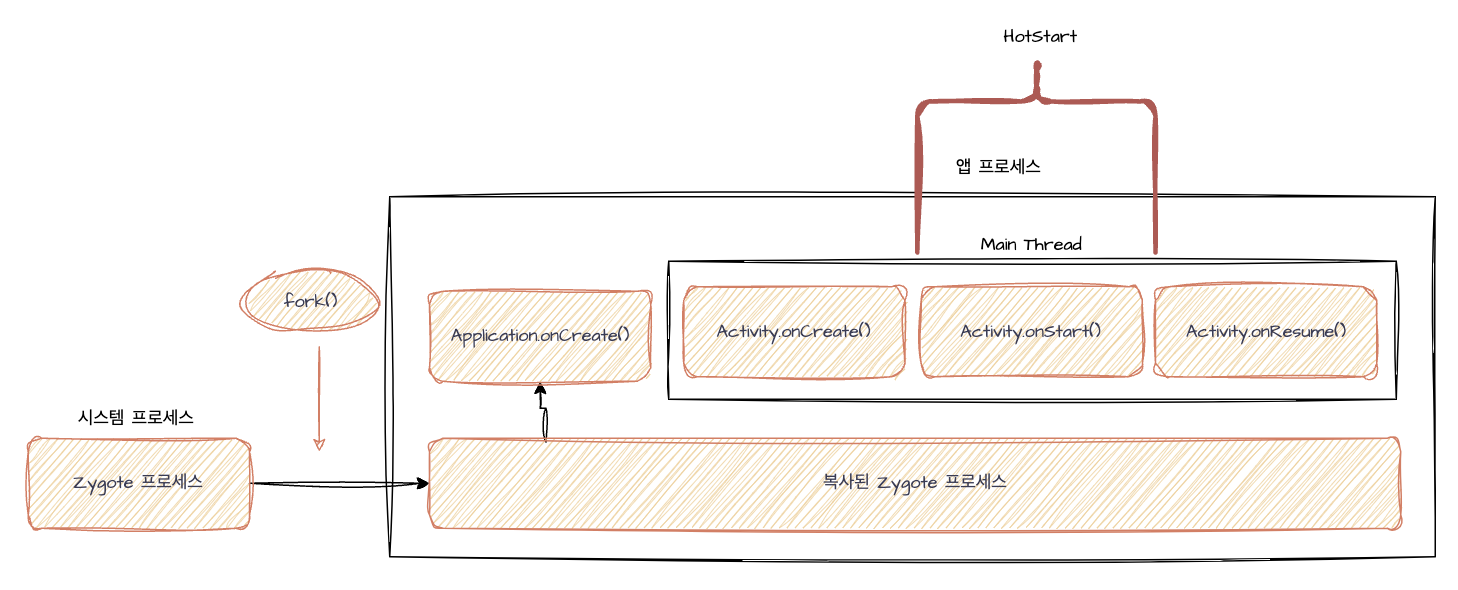
[HotStart]
HotStart는 시스템/앱 프로세스는 물론이며, Activity의 프로세스까지 살아있는 상황에서 앱을 실행해 onStart호출을 통해 앱을 실행하는 방식 의미한다. 따라서 HotStart 방식의 앱 실행은 백그라운드에 있는 앱을 거의 바로 실행시킨다 이해할 수 있다. 대표적인 예로, 핸드폰 문자메시지 인증을 위해 문자 앱으로 갔다가 다시 원래 사용중이던 앱으로 돌아오는 경우이다.
Cold/Warm/HotStart 방식을 요약해본다. ColdStart는 Zygote의 fork작업의 시작으로 시스템 프로세스를 앱 프로세스로 만드는 작업으로 시작된다. 그 후, 앱 프로세스 시작으로 Application.onCreate() 호출 이후, MainThread를 생성한다. 그 내부의 Activity는 Activity.onStart()까지 호출된다. 즉, 이렇게 프로세스 전체 초기화 방식으로 앱이 시작되는 방식을 ColdStart라 한다. WarmStart는 ColdStart보단 부하가 적은 실행방식을 의미하며 Activity.onStart()호출을 통한 앱 실행을 의미한다. HotStart는 그보다 부하가 더 적은 실행 방식으로써 Activity.onStart()를 재호출함으로써 실행된다.
- ColdStart : Zygote프로세스 fork + MainThread생성 + Activity생성 + Activity.onStart()까지 호출하여 앱을 실행하는 방식
- WarmStart : Activity.onCreate() + Activity.onStart()까지 호출하여 앱을 실행하는 방식
- HotStart : Activity.onStart()를 호출하여 앱을 실행하는 방식
이러한 앱 실행 방식은 벤치마크 코드의 startupMode를 통해 조절할 수 있으며, StartupMode.COLD/StartupMode.WARM/StartupMode.HOT이 있다.
@RunWith(AndroidJUnit4::class)
class ScrollBenchmarks {
@get:Rule
val benchmarkRule = MacrobenchmarkRule()
@Test
fun scroll() {
benchmarkRule.measureRepeated(
...
startupMode = StartupMode.COLD, // or StartupMode.WARM or StartupMode.HOT
...
)
}위의 지식에 근거해 앱 시작 시간에 대한 벤치마크 측정 시, 결과는 아래와 같이 나온다.
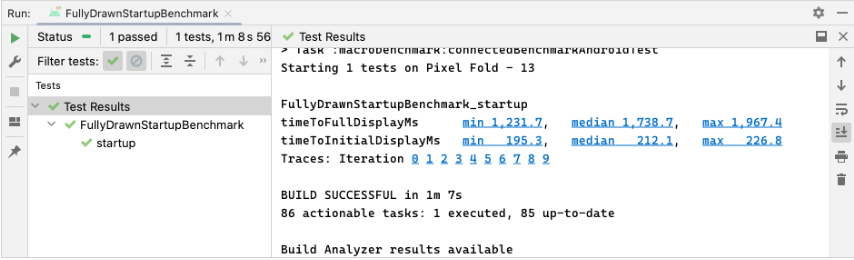
2. FrameTimingMetrics
안드로이드 앱의 UI 렌더링은 60FPS 즉, 1초에 60 Frame을 그릴 수 있어야 UI의 버벅거림이 발생하지 않는다. 만약, 1 Frame을 그리는데 있어 1ms가 더 걸린다면 즉, 17ms or 18ms가 된다면 해당 Frame이 지연되어 렌더링 되는 것이 아닌, Choreographer가 해당 Frame을 삭제해버려 버벅거림이 발생하게 된다.
FrameTimingMetrics는 UI 렌더링에 몇 Ms가 걸렸는지를 측정하는 지표로, frameDurationCpuMs와 frameOverrunMs가 있다.
[frameDurationCpuMs]
이는 CPU가 1 Frame을 그리는데 걸린 시간이다. 이 수치가 높다는 것은 UI Frame을 그리는 첫 관문에서 문제가 생겼다는 것을 의미한다.
[frameOverrunMs]
이는 GPU or Composable함수 등의 이유로 1 Frame을 그리는데 있어 초과된 시간을 의미하며, 16.67ms를 기준으로 이를 넘으면 양수가 출력되고, 넘지 않으면 음수로 출력된다. 음수로 나왔다는 것은 16.67ms시간보다 그만큼 더 빨리 렌더링 되었다는 것을 의미하며, 양수인 경우 16.67ms보다 그만큼 느리게 렌더링 되었다는 것을 의미한다.
[백분위 해석법] - BaselineProfile기준
- P50 : 전체 프레임의 50%까지가 특정 시간대 안쪽으로 렌더링. -> 전체 프레임의 절반이 0.8ms 여유있게 렌더링
- P90 : 전체 프레임의 50% ~ 90%까지가 특정 시간대 안쪽으로 렌더링 -> 전체 프레임의 50% ~ 90%까지가 0.9ms안쪽으로 렌더링(=16.67ms에서 0.9ms초과)
- P95 : 전체 프레임의 90% ~ 95%까지가 특정 시간대 안쪽으로 렌더링 -> 전체 프레임의 90% ~ 95%까지가 5.3ms안쪽으로 렌더링(=16.67ms에서 5.3ms초과)
- P99 : 전체 프레임의 95% ~ 99까지가 특정 시간대 안쪽으로 렌더링 -> 전체 프레임의 95% ~ 99%까지가 10.3ms안쪽으로 렌더링(=16.67에서 10.3ms초과)
위의 frameDurationCpuMs 백분위 99의 대부분은 16ms를 넘었거나 그에 준한 값이 나오고 있다. 1 frame을 그리는 데, 16ms가 넘지 않아야 UI가 부드러워 지는데, UI를 그리는 첫 관문인 CPU 연산 작업에서부터 이미 이를 넘어서고 있다. CPU연산 작업 후엔 GPU 연산, Composable함수 그리기 등의 작업도 추가 진행해야 하므로, frameOverrunMs 또한 당연히 양수가 나올 수밖에 없다.
이런 경우, 확인해볼 수 있는 여러 솔루션 중 한 가지로 TraceSectionMetrics를 활용하여 Composable함수의 구간 렌더링 시간을 체크하는 것이 있다.
3. TraceSectionMetrics
trace()메서드를 사용해서 선택 구간에 호출 시간을 판단할 수 있다. 이 메서드 내부를 확인하면 Trace.beginSection() + Trace.endSection()을 사용해 시작과 끝 구간 사이에서 고차함수 호출 및 체킹함을 쉽게 확인이 가능하다.
actual inline fun <T> trace(sectionName: String, block: () -> T): T {
Trace.beginSection(sectionName)
try {
return block()
} finally {
Trace.endSection()
}
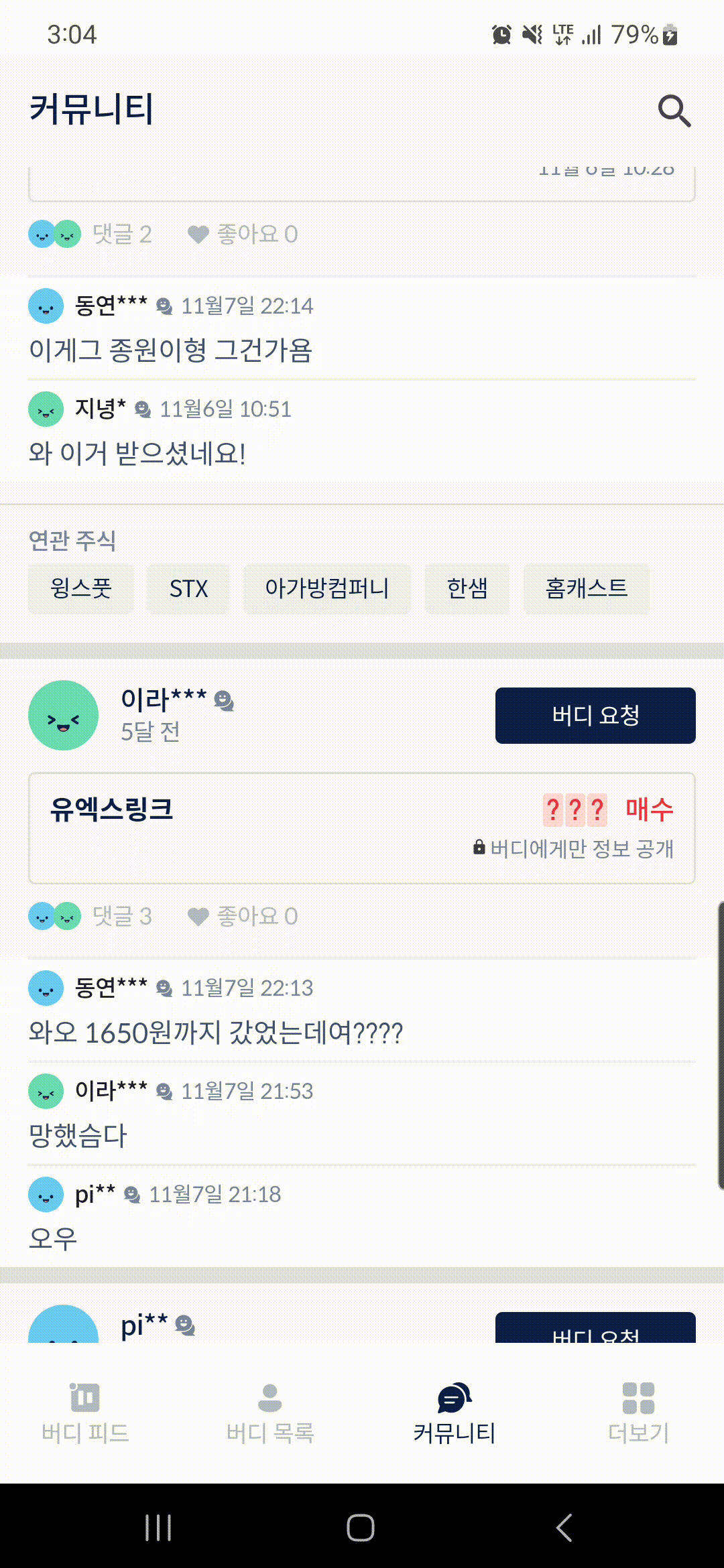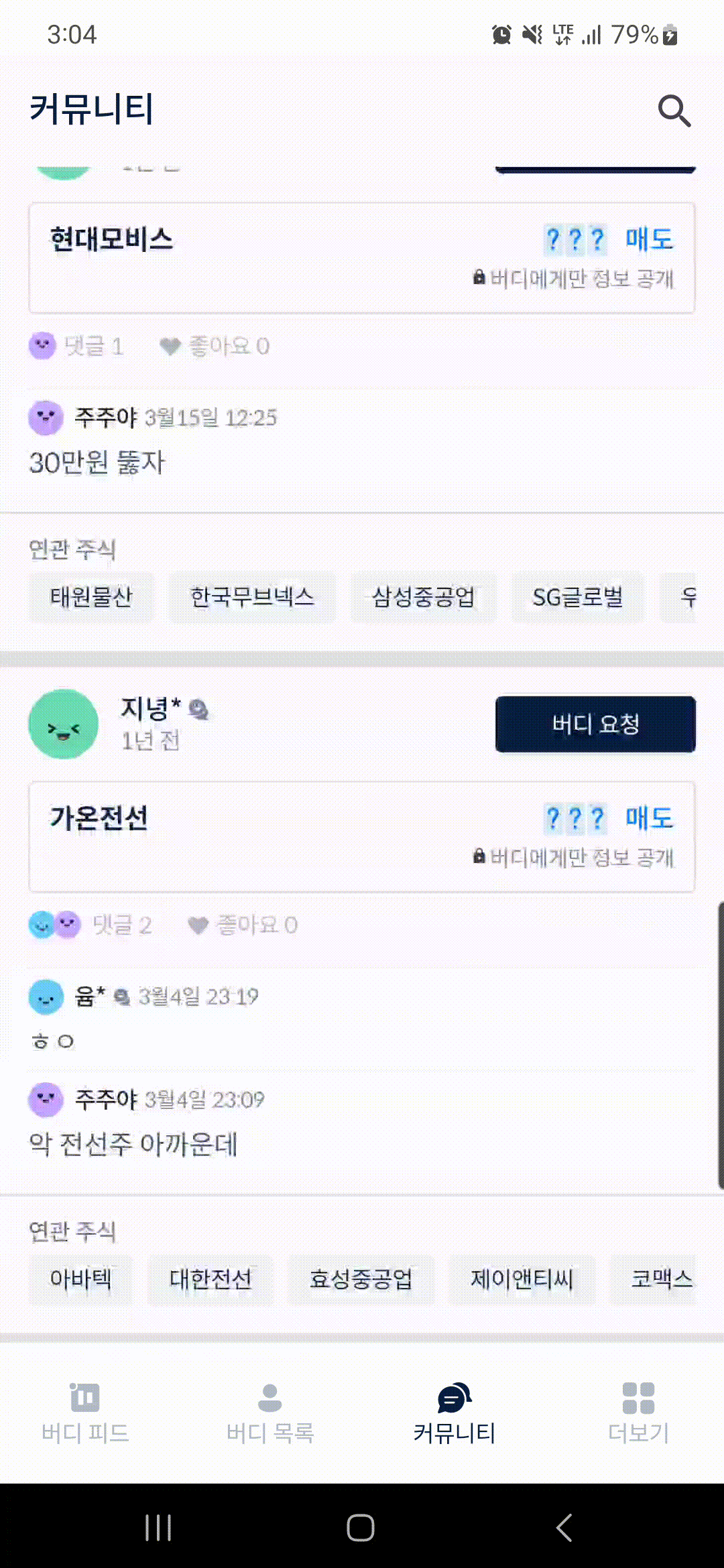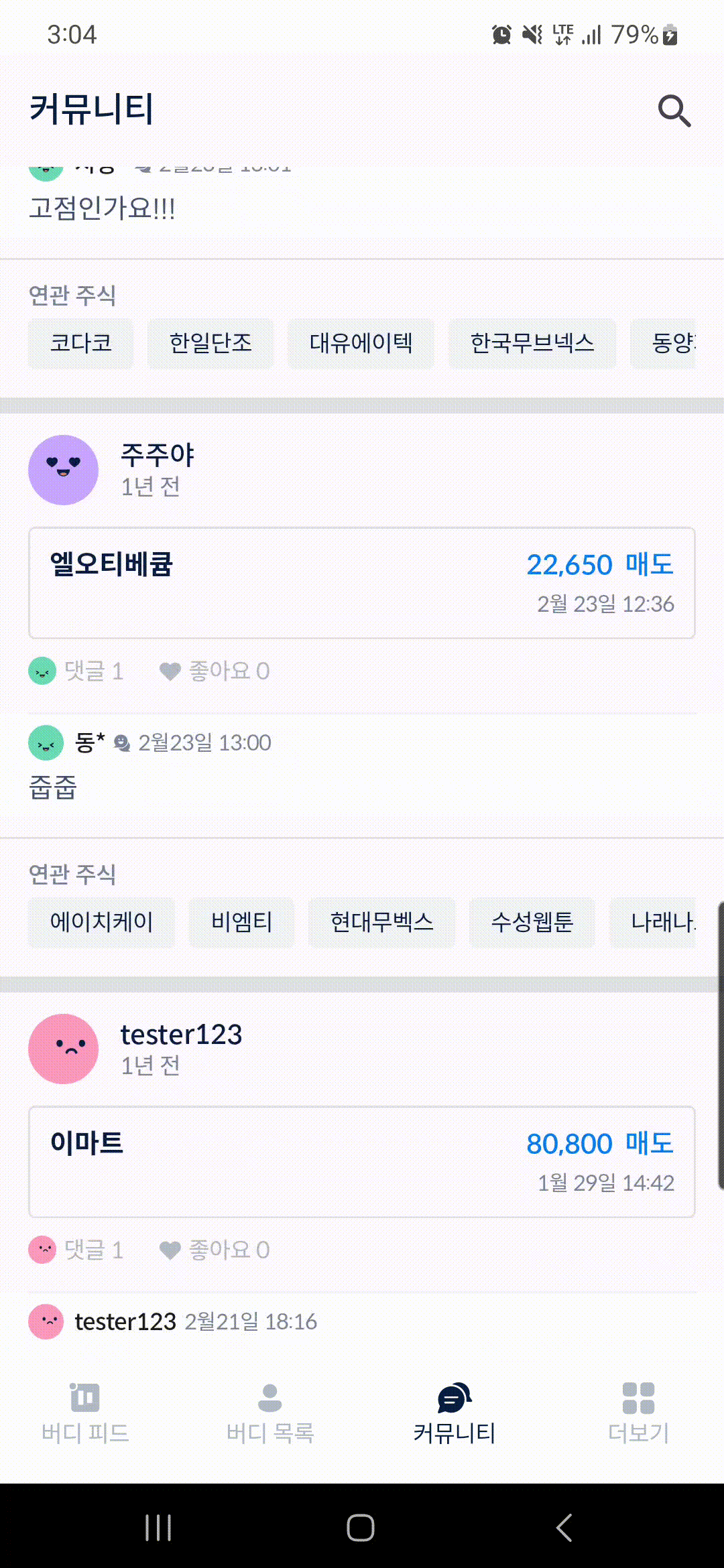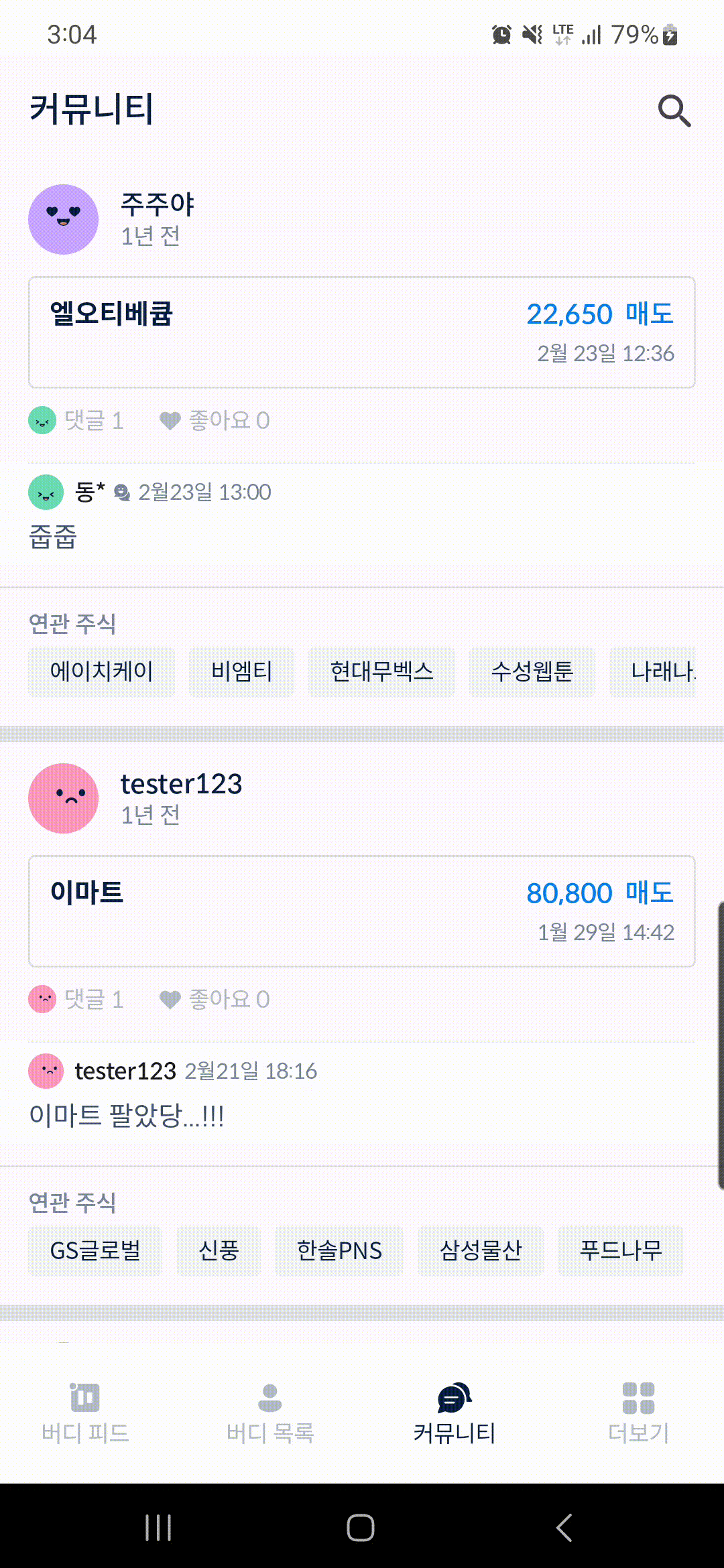
}위 구현체에 맞게 trace()메서드 사용을 위해 trace(sectionName) { ... }와 같이 사용하면 된다. 아래는 내가 진행중인 BuddyStock앱의 소스코드에서의 적용 사례이다.
[CommunityBodyContent.kt]
@Composable
@OptIn(ExperimentalMaterialApi::class)
fun CommunityBodyContent(...) {
LazyColumn(...) {
items(
items = ...,
key = { ... }
) { communityVo ->
CommunityChatItem(
communityVo = communityVo,
...
)
}
}
@Composable
private fun CommunityChatItem(
modifier: Modifier = Modifier,
communityVo: CommunityListVo.CommunityVo,
onClickedItem: (tradingId: Int) -> Unit,
onClickedSubCommentInItem: (tradingId: Int) -> Unit,
onClickedBuddyRequestButton: (CommunityListVo.CommunityVo) -> Unit,
onClickedLikeButton: (body: LikeStatusRequestDto) -> Unit,
onClickedRelatedStockItem: (RelatedStocksVo) -> Unit
) {
trace("DividerLine_top") {
DividerLine(
height = R.dimen.dimen_01dp,
color = R.color.gray_DFE1E6
)
}
Column(
modifier = modifier
.fillMaxWidth()
) {
// 유저 프로필
trace("BaseBuddyInfoWithBuddyRequestSection") {
BaseBuddyInfoWithBuddyRequestSection(
modifier = Modifier
.padding(horizontal = dimensionResource(id = R.dimen.dimen_16dp))
.padding(vertical = dimensionResource(id = R.dimen.dimen_12dp))
.noRippledClickable(onClick = { onClickedItem(communityVo.tradingId) }),
baseBuddyInfoWithBuddyRequestVo = BaseBuddyInfoWithBuddyRequestVo(
baseBuddyInfoVo = BaseBuddyInfoVo(
userId = communityVo.userId,
emojiEnum = communityVo.emojiEnum,
titleText = communityVo.nickname,
buddyType = communityVo.buddyType,
contentText = communityVo.subCommentLatestUpdatedAt,
),
buddyStatus = communityVo.buddyStatus,
),
onClickedBuddyRequest = { onClickedBuddyRequestButton(communityVo) },
)
}
// 매수/매도 상품
trace("OwnerTradingContent") {
OwnerTradingContent(
modifier = Modifier
.padding(horizontal = dimensionResource(id = R.dimen.dimen_16dp))
.noRippledClickable(onClick = { onClickedItem(communityVo.tradingId) }),
communityVo = communityVo
)
}
// 댓글/좋아요 버튼
trace("ReplyCountsAndLikeCountsContent") {
ReplyCountsAndLikeCountsContent(
modifier = Modifier
.padding(horizontal = dimensionResource(id = R.dimen.dimen_16dp))
.padding(
top = dimensionResource(id = R.dimen.dimen_10dp),
bottom = dimensionResource(id = R.dimen.dimen_15dp)
),
communityVo = communityVo,
onClickedReplyButton = { onClickedSubCommentInItem(communityVo.tradingId) },
onClickedLikeButton = onClickedLikeButton
)
}
// 3개 미리보기 댓글
trace("ReplyContent") {
ReplyContent(
modifier = Modifier
.noRippledClickable(onClick = { onClickedSubCommentInItem(communityVo.tradingId) }),
communityVo = communityVo
)
}
// 연관 주식
trace("RelatedStocksContent") {
RelatedStocksContent(
communityVo = communityVo,
onClickedRelatedStockItem = onClickedRelatedStockItem
)
}
}
trace("DividerLine_bottom") {
DividerLine(
height = R.dimen.dimen_08dp,
color = R.color.gray_DFE1E6
)
}
}위처럼 trace()메서드 호출 및 sectionName까지 적어준다. 그 후, Benchmark클래스의 metrics파라미터에 TraceSectionMectrics를 추가하고 그 내부 sectionName 파라미터엔 위 컴포저블 함수에 적었던 sectionName값을 적어준다.
[CommunityListScrollBenchmark.kt]
private fun startAndScrollCommunityList(compilationMode: CompilationMode) = benchmarkRule.measureRepeated(
packageName = PACKAGE_NAME,
metrics = listOf(
FrameTimingMetric(),
TraceSectionMetric("CommunityChatItem", TraceSectionMetric.Mode.Sum),
TraceSectionMetric("BaseBuddyInfoWithBuddyRequestSection", TraceSectionMetric.Mode.Sum),
TraceSectionMetric("OwnerTradingContent", TraceSectionMetric.Mode.Sum),
TraceSectionMetric("ReplyCountsAndLikeCountsContent", TraceSectionMetric.Mode.Sum),
TraceSectionMetric("ReplyContent", TraceSectionMetric.Mode.Sum),
TraceSectionMetric("relatedStocksContent", TraceSectionMetric.Mode.Sum),
),
compilationMode = compilationMode,
iterations = 1,
startupMode = StartupMode.WARM,
setupBlock = { ... }
) { ... }
}sectionName설정 후, Benchmark결과를 확인해보면 아래와 같은 결과 확인이 가능하다.
동일 조건에 벤치마킹 측정에도 불구, 1Frame 렌더링에 따른 오차는 약 1 ~ 4ms정돈 존재하는걸로 보인다.
4. PowerMetrics
추후 포스팅
3. 이미지 로딩 방식 변경으로 렌더링 최적화
1. 최적화 전
안드로이드에서 사용되는 이미지는 크게 Rester이미지와 Vector이미지가 있다. 여기서 Rester란 .png, .jpg, .webP등 포맷의 이미지이며, Vector란 .svg포맷의 이미지다. 또한 Vector이미지는 안드로이드 프로젝트 내에서 .xml과 .kt포맷 형태로 존재한다.
우린 해상도가 낮은 간단한 이미지들은 Vector이미지를 많이 쓴다. 하지만 Vector이미지 중, 어떤걸 사용해야할까? 나는 이미지의 해상도가 낮고, 렌더링 성능을 신경쓰고자 한다면 .kt이미지에 1표를 주고 싶다.
하지만 .xml와 .kt이미지의 렌더링 차이는 벤치마크상 구별이 거의 불가능하다. 아래는 이미지 최적화를 실행하기 전과 후에 대한 Benchmark결과이다.
| 이미지 최적화 전 |
|---|
 |
| 이미지 최적화 후 |
|---|
 |
위의 결과만으론, .kt이미지의 렌더링 성능이 우수한지 바로 알긴 힘들다. 그럼 어떻게 할까? 정답은 Perfetto를 통해 더욱 세부적인 성능 지표를 측정하는 것이다.
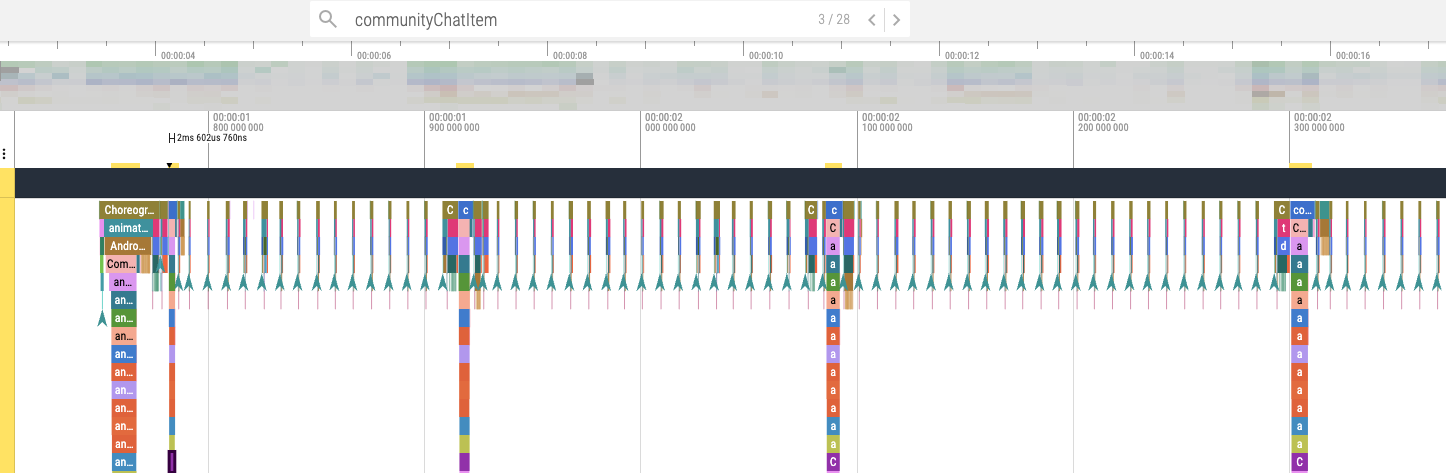
Benchmark측정 후, 위와 같이 Perfetto에 들어왔다. 하지만 LazyColumn 아이템의 요소 중, 모든 이미지에 대한 요소들을 추출하고싶다. 이들을 하나하나 검색해서 노가다하여 더해야만 할까?
이럴 땐, SQL을 사용하는게 좋은 해답이다.
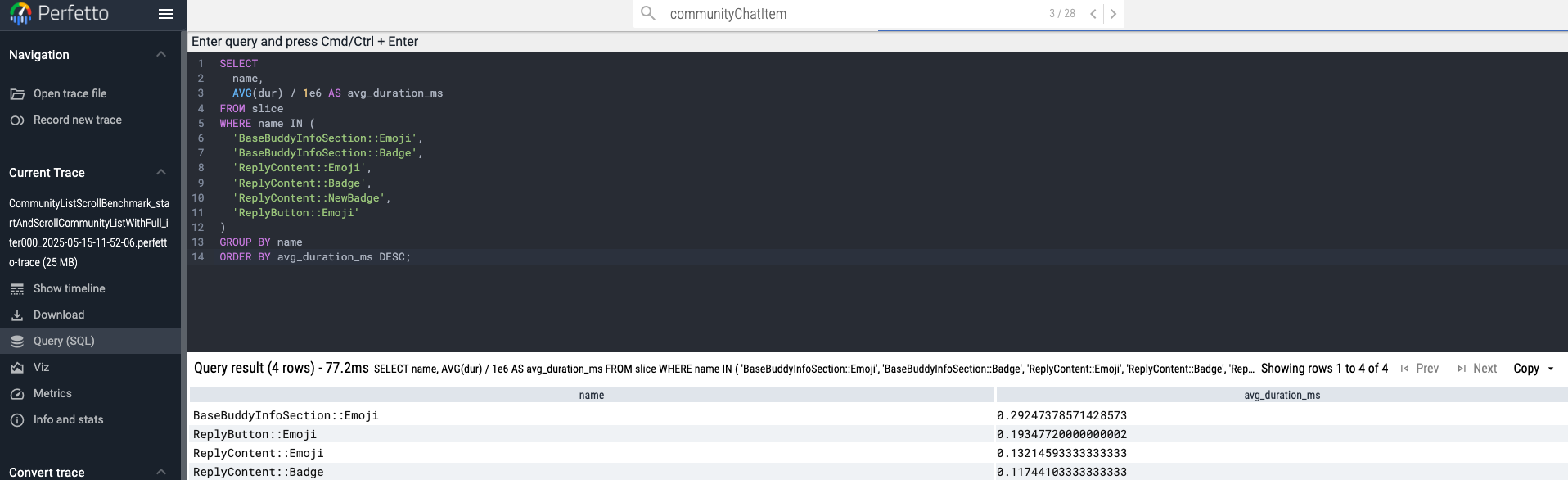
SELECT
name,
AVG(dur) / 1e6 AS avg_duration_ms
FROM slice
WHERE name IN (
'BaseBuddyInfoSection::Emoji',
'BaseBuddyInfoSection::Badge',
'ReplyContent::Emoji',
'ReplyContent::Badge',
'ReplyContent::NewBadge',
'ReplyButton::Emoji'
)
GROUP BY name
ORDER BY avg_duration_ms DESC;위 SQL처럼, 성능 측정을 위해 Composable함수를 래핑한 trace(...)메서드의 key값들을 위 SQL문에 포함시킨다. 그러면 그 밑에 Table형식의 결과를 반환한다.
따라서 이미지 최적화하기 전의 결과는 아래와 같다.
| 항목 | 변환된 μs 값 |
|---|---|
| BaseBuddyInfoSection::Emoji | 292.47 μs |
| ReplyButton::Emoji | 193.48 μs |
| ReplyContent::Emoji | 132.15 μs |
| ReplyContent::Badge | 117.44 μs |
전체 평균 : 183.88 μs
2. 최적화 후
기존 .xml포맷의 이미지를 .kt로 바꾼다. 이때 사용하기 좋은 플러그인이 있는데, svg to compose(클릭)라는 것이 있다. 이를 사용하면 기존 .xml포맷의 이미지를 .kt로 바꿀 수 있다.
무튼, 위의 trace(...)로 측정하고자하는 항목의 이미지들은 모두 .kt로 바꾼 후, 벤치마크를 찍고 Perfetto로 확인해보자.
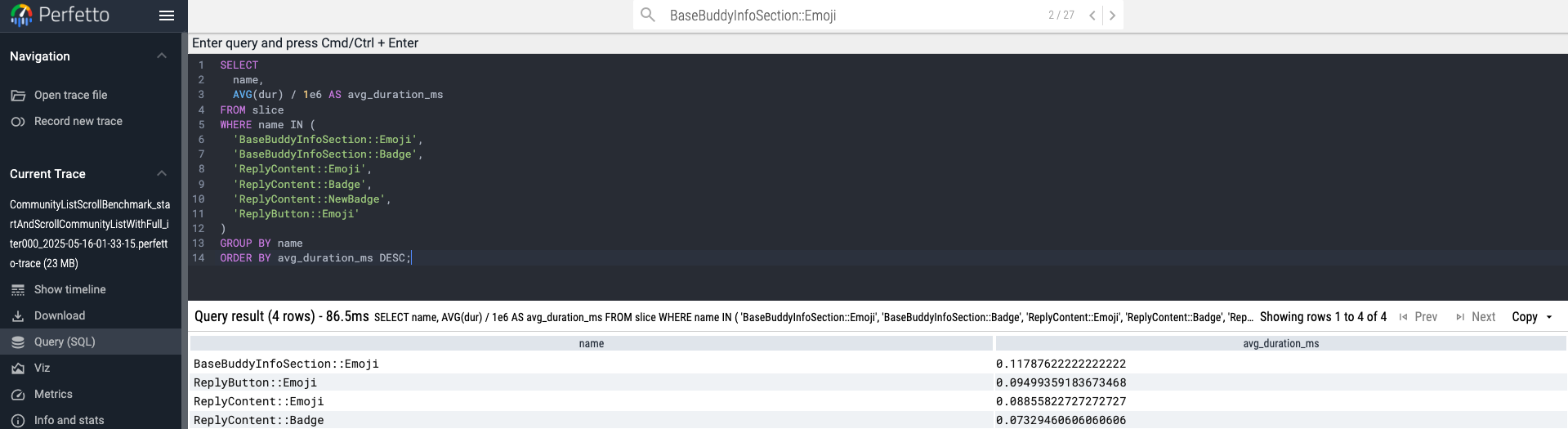
| name | avg_duration_μs |
|---|---|
| BaseBuddyInfoSection::Emoji | 117.88 μs |
| ReplyButton::Emoji | 94.99 μs |
| ReplyContent::Emoji | 88.56 μs |
| ReplyContent::Badge | 73.29 μs |
전체 평균 : 93.68 μs
Perfetto를 통해 확인한 결과, .kt타입의 벡터 이미지의 렌더링 성능이 더 좋음을 정량적으로 확인할 수 있다. 또한 이는 필자가 다른 화면에서도 테스트할 때도 동일한 결과가 나왔었다. 300 μs하던 렌더링 성능이 80 μs까지 개선되는 경우도 있었다.
4. 성능 측정하며 느낀 주저리 주저리...
문제의 발단은 내가 유지보수 중인 BuddyStock앱의 커뮤니티 스크롤의 버벅거림이었다. 다른 앱들과 비교해 보았을 때, (eg., LinkedIn, 당근마켓...) 내 앱만 버벅거렸고, 비교중인 앱들 또한 UI 데이터가 복잡한 편임에도 불구, 버벅거림이 없었다.
자고로 Native개발자란게 뭔지? 시장에서 왜 필요한지? 고찰해봐야한다고 생각한다. 그래야만 시장 경쟁력을 가질 수 있으니까. 요즘 취업시장을 보면 크로스 플랫폼 수요가 굉장히 많아졌다. 하나의 앱으로 AndroidOS와 iOS를 쉽게 만들 수 있기에 회사 입장에서 유지보수/인력/인건비의 가성비가 좋기 때문이다. 또한 일반적인 성능 또한 Native에 비해 뒤쳐지지 않기때문에 많이 택하곤 한다.
하지만 그럼에도 불구하고 Native를 쓰는 회사들이 있다. 당근, 토스(부분 React Native이긴 하지만, 인사 담당자에게 듣기로 Native로 모두 전환을 시도한다고 들음), 등이 있다. 왜 그럴까? 추상적으로 말해보면 사용성의 극대화 때문이라 생각한다. 그러한 사용성이란 위에서 포스팅 한 앱 시작시간, 스크롤 렌더링 성능 개선 등이 있을 것이다. 또한 Native언어는 OS에 1차적으로 종속적인 플랫폼이라 H/W를 다루기에도 좀 더 쉽다.(이건 좀 공부가 필요) 그러기에 돈이 많은 Mobile First기업들은 인건비를 2배 이상 늘려서라도 Native를 사용하는 것이다.
[Native는 크로스 플랫폼에 비해 비용이 3배는 더 들것이라 생각함]
AndroidOS팀과 iOS팀의 커뮤니케이션 비용때문에 그렇다. 크로스 플랫폼을 사용하는 경우, 개발자들이 모두 1가지의 언어, 플랫폼만 사용한다. 따라서 특정 기능 구현 및 API연동 용이성이 Native보단 적을 것이라 어림짐작한다.
따라서 Native개발자라면 사용성을 섬세한 부분까지 극대화할 수 있어야 한다고 생각한다. 그렇지 않으면 기업들은 크로스 플랫폼을 택하고 Native개발자들은 설 자리를 잃을것이다. 그렇기에 Native개발자로써 앱 성능 개선 방법은 꼭 알고있어야하지 않을까 생각한다.(Cross Platform이 Native에 준하는 성능 측정 프레임워크를 제공하고 있을거라 생각하기도 한다.)
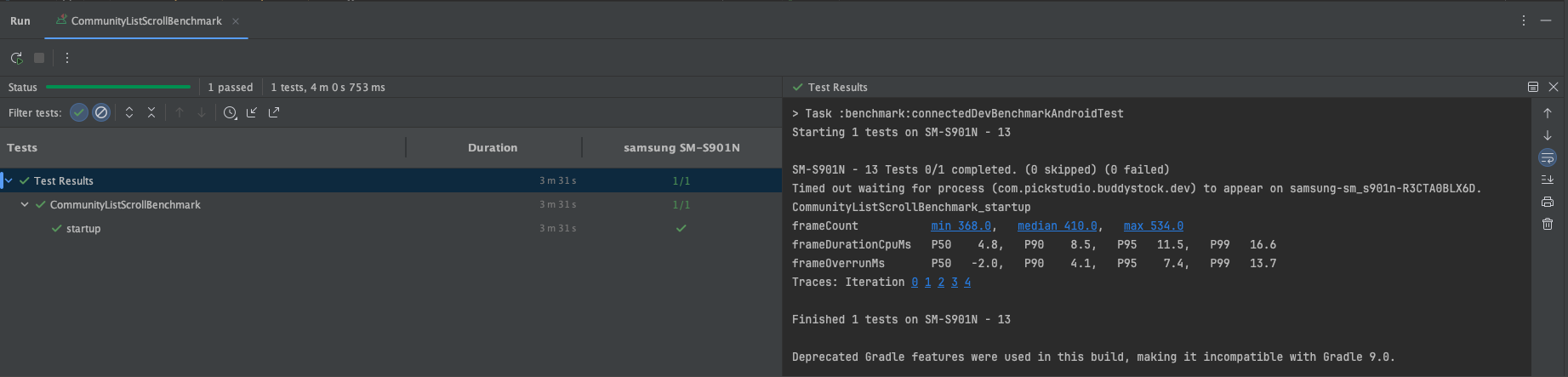
다시 원점으로 돌아와, 내가 유지보수 중인 BuddyStock에서 스크롤 버벅거림이 발생했을 때, 이를 개선하는 것은 Native개발자로써 경쟁력을 가질 수 있는 값진 경험이 될거라 생각해 진행했다. 그리고 버벅거림의 원인을 찾기 위해 아래와 같은 벤치마크를 무수히 찍으며 프레임 렌더링에 영향을 미치는 요소를 잡아가기 시작했다.
[1차 : 벤치마크만 사용]
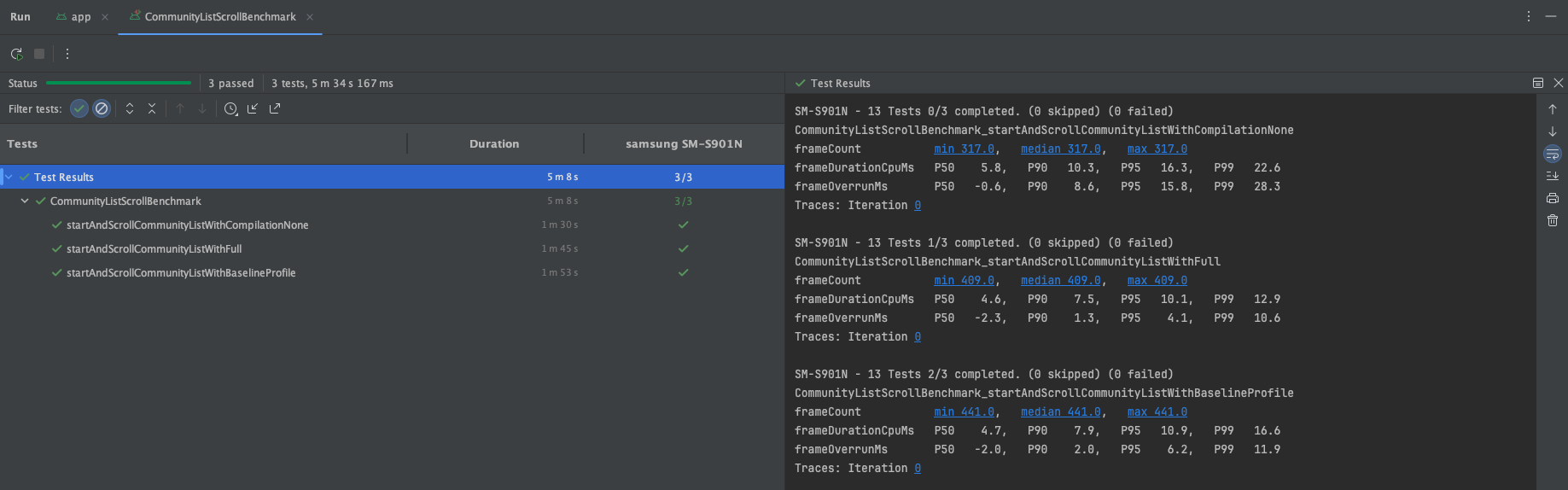
[2차 : BaselineProfile없이 벤치마크 실행]
[3차 : BaselineProfile추가 후 벤치마크 실행]
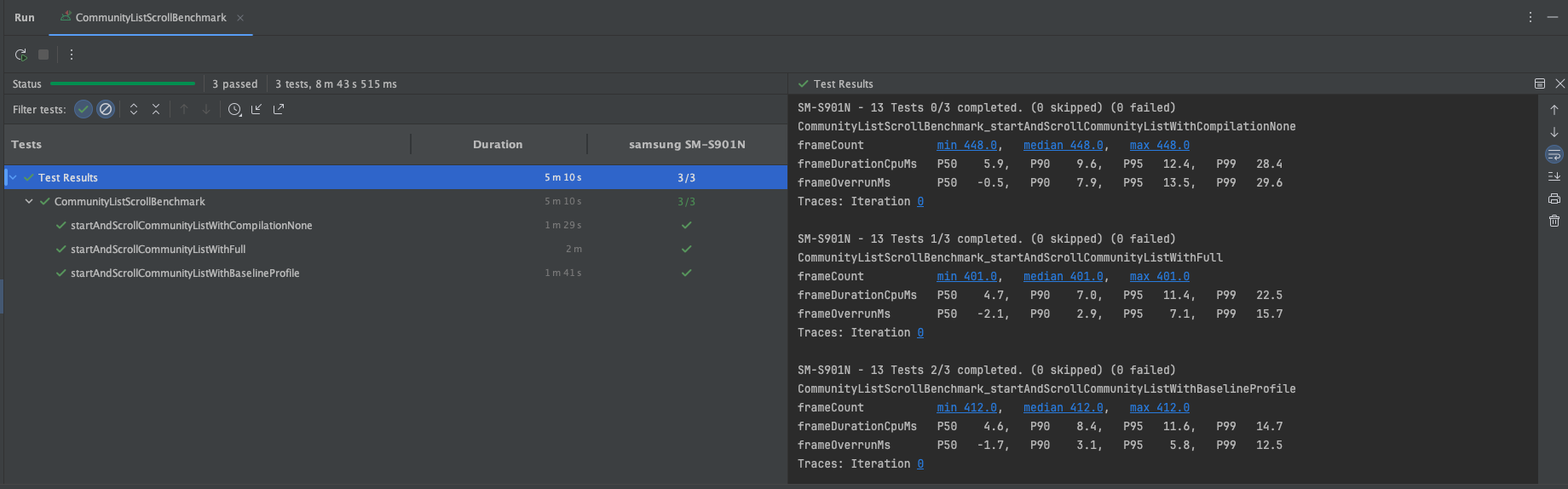
[4차 : LazyRow -> Row 전환 후 벤치마크 실행]
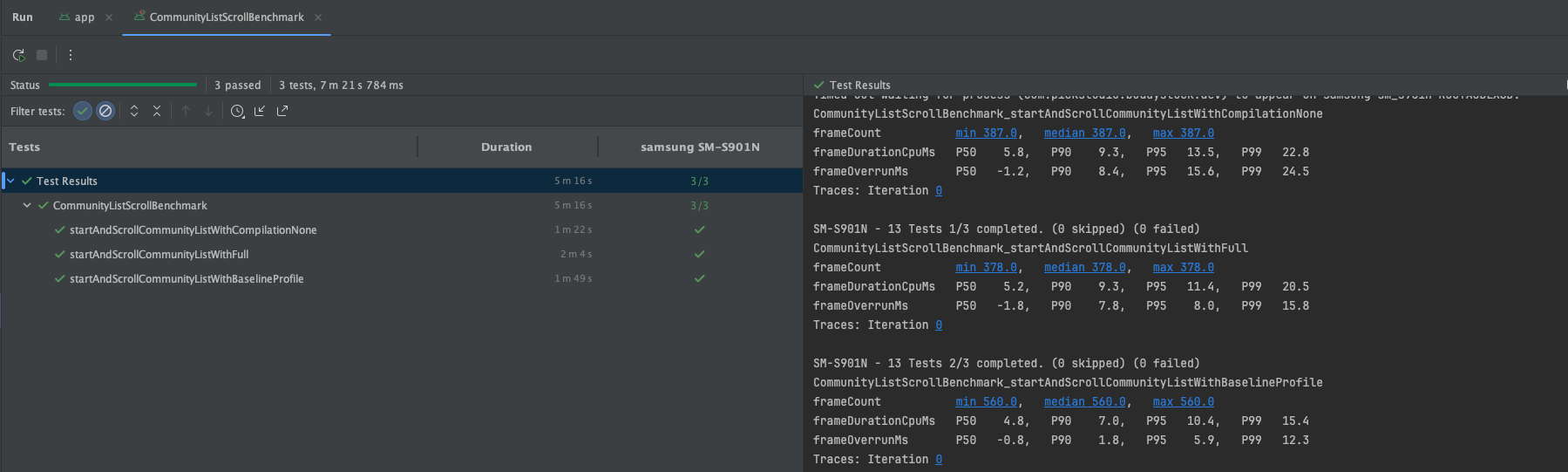
[5차 : .background -> .drawBehind 전환 후 벤치마크 실행]
[6차 : .dimensionResource제거, style의 copy제거 후 벤치마크 실행]
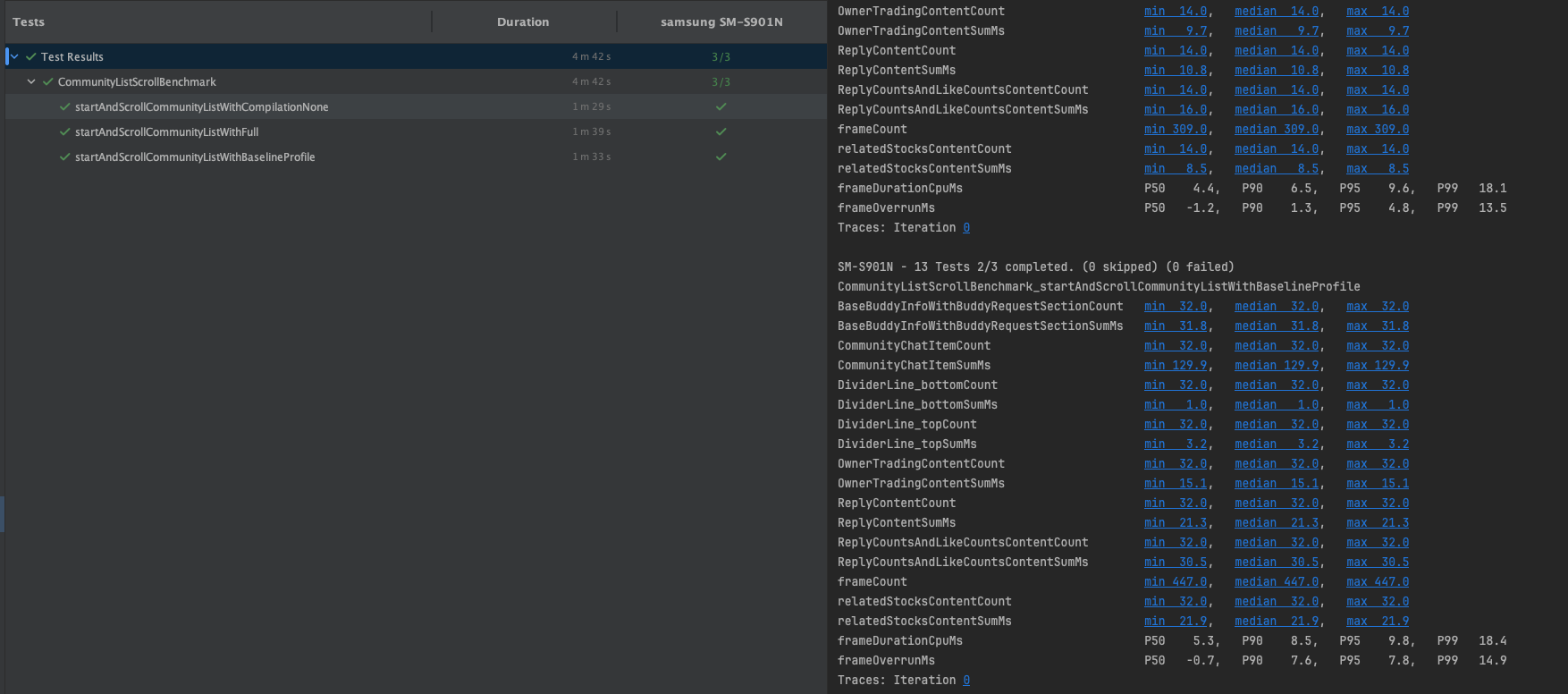
하지만 그 결과는?
이미 부분적으로 해결되어 있었음.
| JIT 컴파일 된 앱 스크롤(BuildType : Debug, 약간 버벅임) | AOT 컴파일 된 앱 스크롤(BuildType : Release, 좀 더 매끄러움) |
|---|---|
 |  |
위의 단계적으로 진행 된 벤치마크 결과에서 같은 compilationMode에선 큰 변화가 없다. 즉, Full모드끼리만 비교한다 했을 때, 이들의 수치가 드라마틱하게 변하지 않는다는 뜻이다.
하지만 None모드와 Full모드를 비교하면 어떨까? None모드는 JIT 컴파일 방식이기에 Full모드보다 런타임 성능이 느리고, 그로 인한 차이가 약 2.5배 나는걸 확인할 수 있다. 핵심은 바로 여기에 있었다.
앱의 BuildType은 기본적으로 2가지다. Debud와 Release. 전자는 개발자가 개발할 때 쓰는 BuildType이며, 후자는 스토어에 배포할 때 쓴다. 전자의 경우, 개발 코드의 빠른 확인을 위해 빠른 빌드를 요하는 만큼, 앱 설치 시 시간이 적게 걸리는 JIT컴파일 방식을 사용하는 것이다. 마찬가지로 후자의 경우는 런타임 성능이 중요한 만큼 AOT컴파일 방식을 사용하는 것이다.
즉, 내가 유지보수중인 코드는 이미 Release타입에서 AOT컴파일이 적용중이었기에 문제가 되지 않을거란 생각이 들었고, Release빌드 및 스크롤을 테스트해봤을 때, 버벅거림이 없는걸 확인할 수 있었다. (구글 스토어에서 내려받은 앱도 동일)
[Debug = JIT컴파일 && Release = AOT + JIT컴파일?]
이에 대한 글을 공식 홈페이지에서 직접 보진 않았지만, 안드로이드 공식 홈페이지에 이를 시사하는 간접적인 내용들이 많다.

그렇다면 기준 프로필을 적용안해도 되는걸까? 그렇지 않다. 위에서 말했다시피, 현재 안드로이드 컴파일 방식은 AOT + JIT혼용으로, 언제 어떤 화면에서 특정 컴파일 방식이 적용될진 블랙박스이다. 따라서 내가 의도하는 화면에선 확실히 AOT컴파일 방식을 사용하려거든, 기준 프로필 사용을 통해 확실히 하는게 좋다 생각한다.
Ps.
위와 같이 무수히 많은 벤치마크를 찍어보며frameOverrunMs를 음수로 만들려고 시도해봤다. 하지만 실패했다. 모든 컴포저블 함수는 stable하여 skippable했으며, 람다 내, unstable값을 캡쳐하지도 않았다. 혹시 컴포저블 함수 내 불필요한 연산들(eg., dimensionResource...)까지 제거해봤으나 큰 효과는 없었다. 또한 Modifier수정자를 람다 타입으로 사용함으로써 프레임 렌더링 단계 중 'Composition'단계를 건너뛰게도 해봤지만 마찬가지였다.
다음 글 : MacroBenchmark & Baselin Profile을 사용한 성능 개선 여정-2편
5. 참고
- 앱 벤치마크
- https://tourspace.tistory.com/535
- [DroidKnights 2024] 배필주 - 앱 성능 영혼까지 끌어올리기
- 앱 성능 영혼까지 끌어올리기 발표자료
- 소스 코드는 어떻게 앱이 되고 스마트폰에서 실행될까?
- ART 구성
- ART JIT 컴파일러 구현
- 느린 렌더링
- Macrobenchmark 작성
- 기준 프로필 개요
- 앱 시작 시간
- AndroidRuntime 및 Dalvik
- 컴포지션 추적
- (code-lab)기준 프로필을 사용한 앱의 성능 개선
- (code-lab) Macrobenchmark로 앱 성능 검사
- (code-lab) Jetpack Compose의 실제 성능 문제 해결
