텍스트 요약이란 긴 길이의 문서(Document)를 핵심 주제만으로 구성된 짧은 요약(Summary)로 변환하는 것을 말한다. 예를 들어 뉴스 기사 중에서 핵심 주제를 기사 제목으로 만들어내는 것이다.
이때 가장 중요한 것은 요약 할 때, 정보 손실이 최소화되는 것이다.
텍스트 요약은 두 가지로 나뉘는데, 추출적 요약(extractive summarization)과 추상적 요약(abstractive summarization)으로 나뉜다.
추출적 요약(extractive summarization)
추출적 요약은 원문에서 중요한 핵심 문장 또는 단어를 뽑아 구성된 요약문을 만드는 방식이다. 이 방식을 통해 만들어진 문장이나 단어는 모두 원문에 있는 문장들이다. 추출적 요약의 대표적인 머신러닝 알고리즘은 텍스트랭크(TextRank)가 있다. 이 방식의 단점은 이미 존재하는 문장이나 단어를 구성하기 때문에 모델의 언어 표현 능력이 제한된다. 이로인해 출력 결과의 문장들이 자연스럽지 않을 수 있다.
대표적인 예로는 네이버 뉴스의 요약봇이다.
추상적 요약(abstractive summarization)
추상적 요약은 원문에 없던 문장이라도 핵심 문맥을 반영해 새로운 문장을 생성해 원문을 요약하는 방식이다. 이는 사람이 요약한 것 처럼 보이고, 이는 당연하게도 추출적 요약보다 난이도가 높다.
추상적 요약은 자연어 처리 분야 중 자연어 생성(Natural Language Generation, NLG) 영역이다.. 또한 원문의 구성 중 어느 것이 요약할 문장인지 판별하는 점이 문장 분류(Text Classification) 문제로 볼 수 있다.
대표적인 예로 인공 신경망을 사용하는 모델인 seq2seq가 있다. 이 방식은 지도학습이라는 단점이 있다.
seq2seq
seq2seq는 두 개의 RNN 아키텍처를 사용하여 입력 시퀀스로부터 출력 시퀀스를 생성해 내는 자연어 생성 모델이다.
일반적으로 번역기에서 대표적으로 사용하는 모델이다.
seq2seq 기본 구성
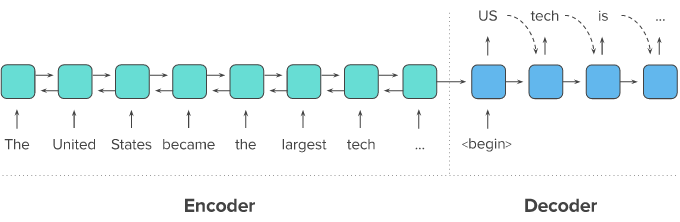
seq2seq는 Encoder와 Decoder 두 개의 모듈로 구성되어있다. 인코더는 원문인 모든 단어들을 순차적으로 입력받으면 단어 정보들을 압축해 하나의 고정된 벡터로 변환하고 디코더로 전달한다. (이 벡터는 컨텍스트 벡터(context vector)라고 한다.) Decoder는 컨텍스트 벡터를 전달받아 한 단어씩 생성해 요약 문장(또는 번역된 단어)을 완성한다.
인코더와 디코더는 두 개의 RNN 아키텍처이다. 입력받는 RNN을 인코더, 출력하는 RNN을 디코더라고 한다. 실제 사용에서는 성능 문제로 인해 RNN이 아닌 LSTM 또는 GRU로 구성된다.
LSTM과 컨텍스트 벡터
LSTM과 RNN의 차이점은 LSTM은 time step의 셀에 hidden state와 더불어 cell state가 전달된다. 이는 인코더가 디코더에 전달하는 컨테스트 벡터가 hidden state와 cell state 두 개의 값이 존재한다는 뜻이다.
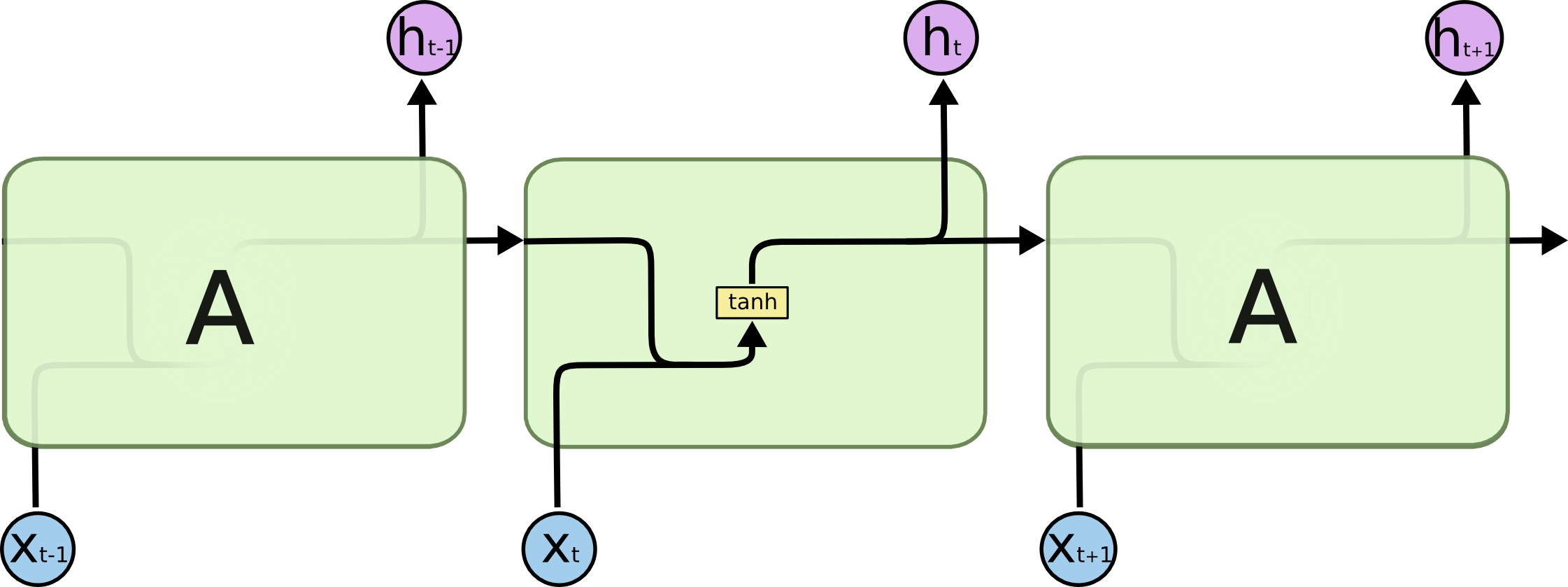
The repeating module in a standard RNN contains a single layer.
The repeating module in an LSTM contains four interacting layers.
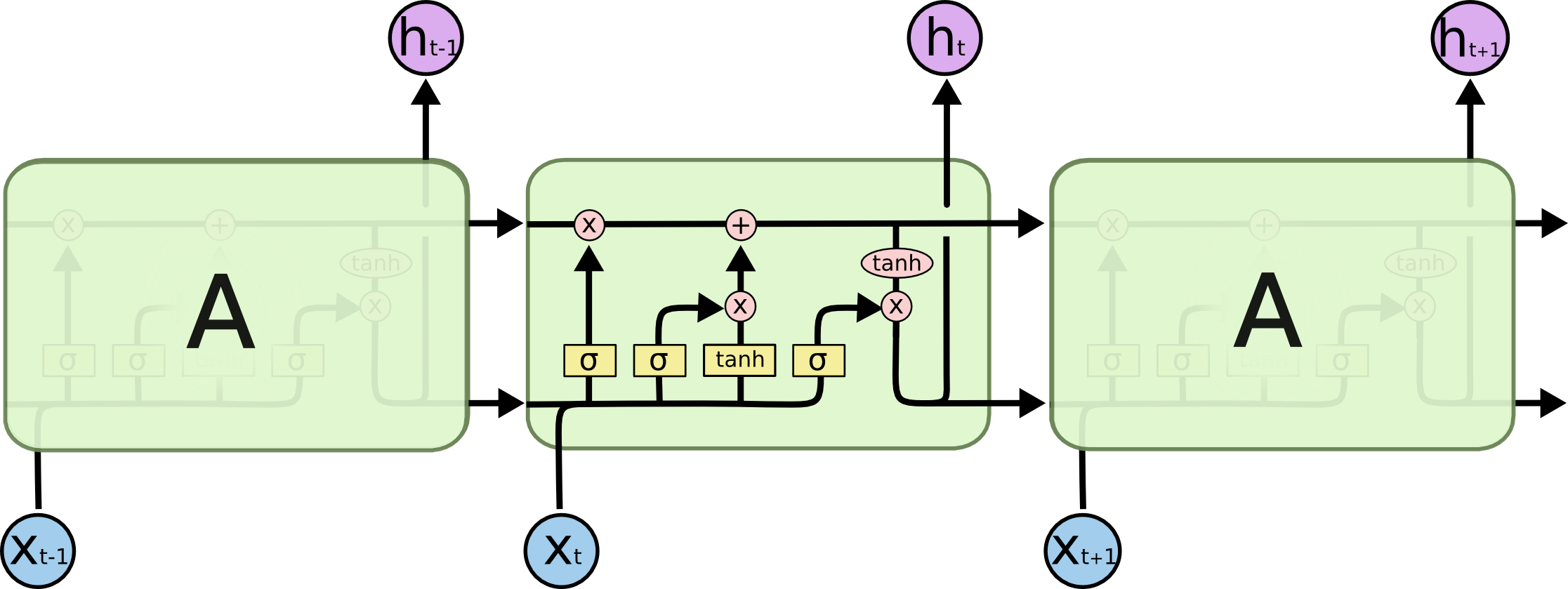
[출처 : http://colah.github.io/posts/2015-08-Understanding-LSTMs/]
시작 토큰(sos), 종료 토큰(eos)
디코더는 처음 시작할 때 SOS(Start Of a Sequence)가 입력된다. sos가 입력되면 다음에 올 적절한 단어를 출력하고 그 출력된 단어는 다시 입력되어 다음 단어를 예측해 출력하는 방식으로 마지막에 EOS(End Of a Sequence)가 예측될 때까지 계속 반복한다.
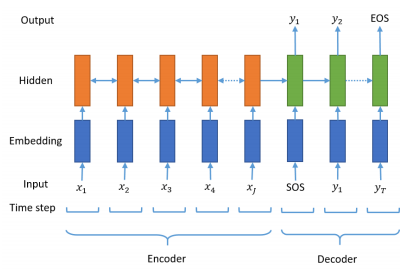
[출처 : https://arxiv.org/pdf/1812.02303.pdf]
어텐션 메커니즘 활용 컨텍스트 벡터 사용하기
seq2seq는 인코더의 마지막 time step의 hidden state를 컨텍스트 벡터로 사용한다. 이는 RNN 계열의 인공 신경망(바닐라 RNN, LSTM, GRU)의 한계로 입력 시퀀스의 많은 정보가 손실된다.
어텐션 메커니즘(Attention Mechanism)은 인코더의 모든 step의 hidden state의 정보가 컨텍스트 벡터에 반영되도록 한다. 반영되는 방식은 디코더의 현재 time step의 예측에 인코더의 각 step이 얼마나 영향을 미치는지에 따른 가중치의 합으로 계산한다.
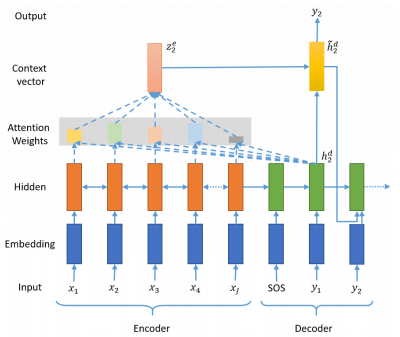
[출처 : https://arxiv.org/pdf/1812.02303.pdf]
위 그림에서 seq2seq 모델이면 디코더로 전달되는 인코더의 컨텍스트 벡터는 인코더 마지막 hidden state인 가 되어야 하지만 어텐션 메커니즘을 적용하면 컨텍스트 벡터는 와 같이 된다.
주의할 점
인코더 hidden state 가중치 합은 디코더의 현재 step이 어딘지에 따라 계속 달라진다.
디코더의 현재 스텝에 따라 동적으로 달라지는 인코더의 컨텍스트 벡터를 사용해 현재의 예측에 활용하는 방식은 디코더가 더 정확한 예측을 할 수 있게 해준다. 이 Attention 방식은 seq2seq를 비롯해 다양한 딥러닝 분야를 획기적으로 발전시킨 핵심 개념이 된다.
과정 정리
- seq2seq 사용
- RNN 계열 중 LSTM 사용 // hidden state 뿐 아니라 cell state도 사용해야 한다.
- 디코더의 예측 시퀀스에는 시작에 SOS, 끝에 EOS 토큰을 붙인다.
- seq2seq를 구동시키면 디코더는 시작 토큰을 입력받아 예측을 시작한다.
- 어텐션 메커니즘을 사용해 인코더의 hidden state 가중치를 계산한 컨텍스트 벡터를 디코더 스텝 별로 구한다.
- 계산된 컨텍스트 벡터를 이용해 디코더는 다음 단어를 예측한다.
