Abstract
BERT: 트랜스포머의 양방향 인코더 표현(Bidirectional Encoder Representations from Transformers)
모든 레이어의 왼쪽 및 오른쪽 context에서 공동으로 조건을 지정하여 ****라벨링이 되지 않은 텍스트로부터 deep한 양방향 표현을 사전훈련 하도록 설계됨
결과적으로 pre-trained BERT 모델은 output 레이어 하나를 추가하여 fine-tune 될 수 있으며, task-specific한 아키텍처 수정 없이 QA, language inference 등 많은 태스크에 적용 가능
Introduction
사전훈련 언어 표현을 다운스트림 태스크에 적용하는 feature-based와 fine-tuning 두 방법이 존재.
ELMo와 같은 feature-based 접근법은 추가적인 feature로 사전 훈련된 표현을 포함한 task-specific 구조를 사용.
GPT와 같은 fine-tuning 접근법은 minimal한 task-specific 파라미터를 소개하며, 간단하게 모든 사전훈련된 파라미터들을 fine-tuning함으로써 다운스트림 태스크에 맞게 훈련됨.
두 접근법은 사전훈련 중 같은 목적 함수를 공유하며, 단방향 언어 모델을 사용하여 일반 언어 표현을 학습.
현재 기술들은 사전 훈련된 표현의 파워를 제한함, 특히 fine-tuning 접근법에서
주요 한계는 표준 언어 모델들은 단방향이라는 것이고, 이게 사전훈련 중에 사용되는 아키텍처의 선택을 제한한다는 것이다.
이 논문은 BERT를 제안함으로써 fine-tuning 기반 접근법을 improve함
BERT는 masked language model (MLM)을 사용함으로써 단뱡향 제약을 덜어냈다.
MLM은 인풋으로부터 얻은 토큰의 일부를 랜덤하게 마스킹하고, 오직 context만으로 마스킹된 단어의 기존 단어 id를 예측하는 것을 목적으로 함.
MLM objective는 표현이 왼쪽과 오른쪽 context를 융합할 수 있게 하여 깊은 양방향 트랜스포머를 사전훈련 할 수 있게 함
또한 공동으로 사전훈련된 텍스트 쌍 표현인 next sentence prediction (NSP) 태스크를 사용
- BERT는 sentence-level 및 token-level 태스크에서 SOTA를 달성한 첫 fine-tuning 기반의 표현 모델
- 11개의 NLP 태스크에서 SOTA 달성
BERT
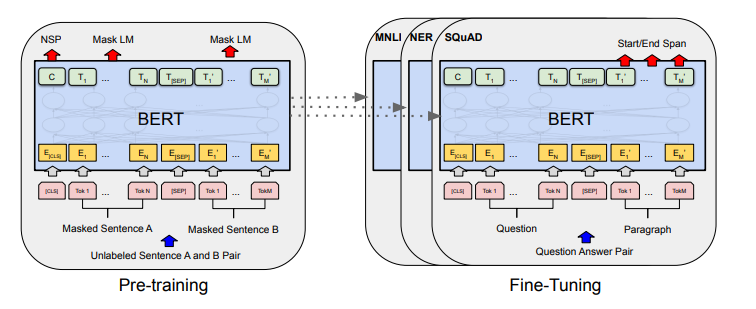
두 스텝: pre-training / fine-tuning
pre-training 단계에서는 다양한 사전훈련 태스크를 통해 라벨링이 되지 않은 데이터로 훈련됨
fine-tuning 단계에서 BERT 모델은 pre-trained 파라미터로 초기화되며, 모든 파라미터들이 다운스트림 태스크로부터 라벨링된 데이터를 사용하여 fine-tuning 된다.
BERT의 독특한 특징은 다른 태스크들에 대한 통합된 아키텍처 → 사전 훈련된 아키텍처와 최종 다운스트림 아키텍처 사이에 작은 차이밖에 존재하지 않음
Model Architecture
BERT의 모델 구조는 다층 양방향 트랜스포머 인코더
BERT_base (L=12, H=768, A=12, total params=110M)
BERT_large (L=24, H=1024, A=16, total params=340M)
L: layer 수, A: self-attention head 수, H: hidden size
Input/Output Representations
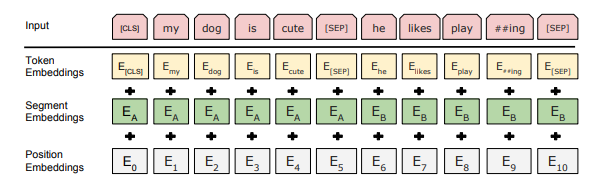
input representation은 하나의 token sequence에서 단일 문장과 한 쌍의 문장을 모두 명확하게 나타낼 수 있음
여기서 “sentence”는 실제 언어학적인 문장 보다는 인접한 text의 임의의 span
“sequence”는 BERT의 input token sequence, 하나의 문장이거나 함께 묶인 두 개의 문장일수도
30000 토큰 단어의 WordPiece 임베딩 사용. 모든 sequence의 첫 토큰은 [CLS] 토큰(special classification token)이다. 이 토큰에 해당하는 마지막 hidden state는 classification task를 위한 sequence representation을 합하는 데 사용됨
문장을 구분하는 데 두 방법이 사용됨:
1. [SEP] 토큰으로 구분
2. 모든 토큰에 이게 문장 A 또는 문장 B에 속하는지 가리키는 학습된 임베딩 추가
주어진 토큰에 대해서 입력 표현은 해당 토큰, segment, 그리고 position embeddings를 합산하여 구성됨
Pre-training BERT
Task #1: Masked LM
양반향 조건부가 각 단어를 간접적으로 자기 자신을 보게 할 수 있고, 모델이 multi-layered context에서 대상 단어를 trivial하게 예측할 수 있기 때문에 표준 조건부 언어 모델은 left-to-right 또는 right-to-left로만 훈련 가능
깊은 양방향 표현을 훈련하기 위해서 논문은 간단하게 특정 비율의 input 토큰을 랜덤하게 마스킹하고, 마스킹 된 토큰을 예측 → masked LM (MLM)이라고 부름
mask token에 해당하는 최종 hidden vector는 표준 LM에서와 같이 vocabulary에 대한 출력 softmax로 공급됨
실험에서 각 sequence에 대해 랜덤하게 15%의 WordPiece 토큰들을 마스킹 함
denoising auto-encoders와 다르게 전체 input을 재구축하기 보다는 마스킹된 단어를 예측하기만 함
이 방법이 양방향 사전훈련 모델을 얻게 해주지만, [MASK] 토큰이 fine-tuning 중에 나타나지 않기 때문에 사전 훈련과 fine-tuning 사이에 미스매치가 생길 수 있다는 단점이 있음
이를 완화시키기 위해 마스킹된 단어를 항상 실제 [MASK] 토큰으로 대체하지는 않음.
랜덤하게 마스킹 된 15%의 토큰 중 80%의 토큰은 [MASK] 토큰으로 바꾸며, 10%의 토큰은 임의의 토큰(임의의 단어)으로 바꾸고, 나머지 10%의 토큰은 바꾸지 않음
input token의 마지막 hidden vector는 cross entropy loss와 함께 original token을 예측하는 데 사용됨
Task #2: Next Sentence Prediction (NSP)
QA나 NLI와 같은 많은 중요한 다운스트림 태스크들은 언어 모델링에 의해 직접 포착되지 않는 두 문장 사이의 “관계”를 이해하는 것을 기반으로 함
문장 사이의 관계를 이해하는 모델을 훈련하기 위해 단일 언어 말뭉치에서 생성할 수 있는 이진화된 next sentence prediction 태스크를 위해 사전훈련함
구체적으로 각 훈련 example에서 문장 A와 B를 고를 때, 50%는 B가 A의 다음 문장이고(IsNext로 라벨링 됨), 나머지 50%는 말뭉치의 랜덤한 문장(NotNext로 라벨링 됨)
Figure 1에서 C는 next sentence prediction에 사용됨.
Pre-training data
사전훈련 절차는 주로 언어 모델 훈련에 관한 기존 문헌을 따름
BooksCorpus(800M words), English Wikipedia(2500M words)를 사용
Wikipedia는 텍스트 문단만 가져옴
Fine-tuning BERT
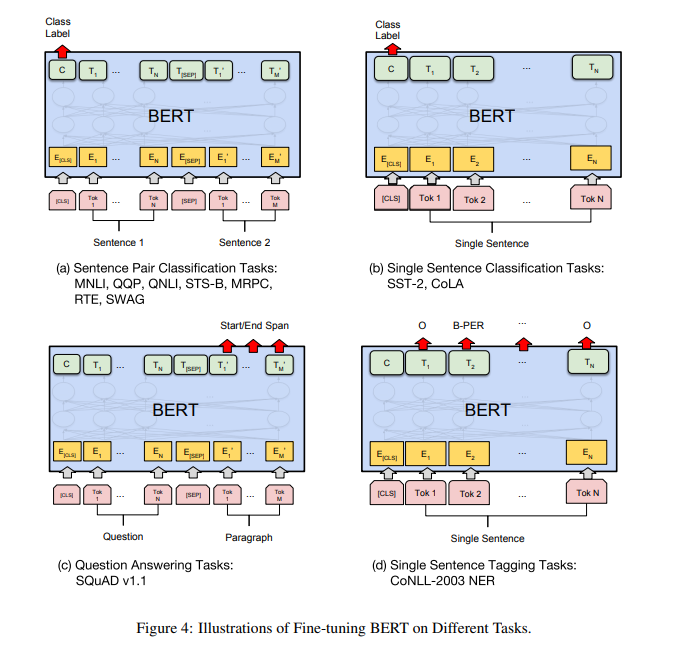
트랜스포머의 self-attention 매커니즘이 BERT가 싱글 텍스트나 텍스트 쌍을 포함하여 적절한 입력과 출력을 교체하여 많은 다운스트림 태스크를 모델링 가능하게 했기 때문에 fine-tuning은 직관적임
텍스트 쌍을 포함하는 적용의 경우, 일반적인 패턴은 양방향 cross attention을 적용하기 전에 텍스트 쌍을 독립적으로 인코딩하는 것
BERT는 대신 이 두 단계를 통합하기 위해 self-attention 메커니즘을 사용. self-attention으로 연결된 텍스트 쌍을 인코딩하면 두 문장 사이의 양방향 cross attention이 효과적으로 포함되기 때문.
각 태스크에 대해 작업 별 input과 output을 BERT에 연결하고, 모든 파라미터를 end-to-end로 fine-tuning
입력에서 pre-training의 문장 A와 B는 (1) pharaprasing의 문장 쌍, (2) 가설-전제 쌍, (3) QA에서의 질문-구문 쌍, (4) text classification이나 sequence tagging의 degenerate text - ∅ ****쌍과 유사함
출력에서 토큰 표현은 sequence tagging 또는 QA와 같은 토큰 레벨 태스크를 위한 output layer에 공급되고, [CLS] 표현은 entailment 또는 sentiment analysis와 같은 분류를 위해 output layer에 공급됨
Limitation
입력 sequence의 토큰 중 약 15% 마스킹 → 전체 토큰 중 15%에 대해서만 loss 발생 ⇒ 연산량이 많다(많은 비용) → 모델이 무겁다
학습 시 [MASK] 토큰을 모델이 참고하여 예측하지만, 실제로는 [MASK] 토큰이 존재하지 않는다.
