논문 링크: https://arxiv.org/pdf/1408.5882.pdf
Abstract
문장 단위의 분류 태스크를 위해서 pre-trained 단어 벡터를 위에 쌓은 CNN 아키텍쳐
하이퍼파라미터 튜닝과 정적 벡터를 사용한 SimpleCNN이 다양한 벤치마크에서 좋은 성능을 보임.
파인 튜닝을 통한 task-specific 벡터를 학습하는 것이 성능 면에서 상당히 좋은 모습을 보였음.
추가적으로 아키텍쳐에 약간의 수정을 통해서 task-specific 벡터와 정적인 벡터 모두 사용 가능할 수 있는 것을 제안함.
CNN 모델은 2014년 당시 감성분석과 질문 분류를 포함, 총 7개 중 4개의 태스크에 있어서 SOTA를 달성했음.
1. Introduction
NLP에서 대부분의 딥러닝 방법론은 neural language models를 통한 단어 벡터 표현을 학습하고, 분류를 위해 학습된 단어 벡터에 대해 합성을 수행하는 것과 관련이 되어있다.
단어벡터(Word Vector)
단어의 의미론적인 특징을 차원으로 인코딩하는 필수적인 특징 추출기
단어가 hidden layer를 통해 sparse한 1-of-V(V는 vocab size) 인코딩에서 저차원의 벡터 공간으로 투영됨
dense한 표현에서 의미론적으로 가까운 단어들은 저차원 벡터 공간에서의 euclidean 또는 코사인 거리에서 또한 가깝다.
Convolutional Neural Network (CNN)
로컬 특징들에 적용되는 convolving 필터가 있는 레이어를 활용
컴퓨터 비전을 위해 발명되었지만, NLP의 다양한 태스크에서도 좋은 성능을 보임.
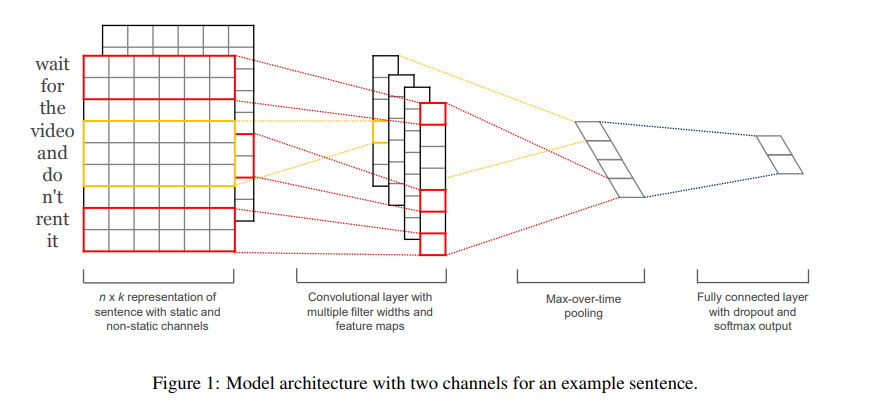
2. Model
를 k차원의 단어 벡터 중 i번째 단어라고 하자.
이때 길이가 n인 문장은 (1)로 표현된다. (필요하다면 패딩을 한다)
: concatenation operator, : 단어 를 concatenate한 것
합성 연산은 새로운 feature를 생산하기 위한 h개의 단어에 적용되는 필터 와 관련됨
예를 들어 feature 가 단어 로부터 생성되었다면 (2)
여기서 은 bias term이고, f는 tanh같은 비선형함수이다. 이 필터는 문장 내의 가능한 단어의 윈도우에 적용되어 feature map( (3),
)을 만들었다
그러면 feature map 위에 max-over-time pooling 연산을 적용할 수 있고, 최대값 를 특정 필터에 대응하는 feature로 취할 수 있으며, 이 pooling scheme은 다양한 문장 길이를 다룬다.
여러개의 필터를 사용하여 (다양한 윈도우 사이즈와 함께) 여러개의 feature를 얻는다. 이 feature들은 끝에서 두 번째(penultimate) 레이어를 생성하며, label에 대한 확률분포를 output으로 내는 fc softmax 레이어를 거친다.
모델 변형 중 하나로 단어 벡터의 두 “채널”을 갖고 실험을 했다. 하나는 훈련 내내 정적으로 유지되고, 다른 하나는 역전파를 통해 fine-tune 된다.
이 multichannel 아키텍처에서(figure1), 각 필터는 두 채널 모두에 적용되고, 결과는 식 (2)에서 를 계산하기 위해 더해진다.
다른 부분은 single-channel 아키텍처와 동일하다.
Regularization
penultimate 레이어에 l2 normalization과 함께 dropout을 적용
dropout은 p의 비율의 hidden unit을 forward-backpropagation 중에 랜덤하게 드롭함으로써(i.e. 0으로 셋팅) 히든 유닛의 상호 적응을 예방
❓ 상호적응?
어떤 뉴런이 다른 특정 뉴런에 의존적으로 변하는 것
어느 시점에서 같은 층의 두 개 이상의 노드의 입력 및 출력의 연결 강도가 같아져서 아무리 학습이 진행되어도 그 노드들은 같은 일을 수행하게 되어 불필요한 중복이 생김
그것이 주어진 penultimate(끝에서 두 번째) 레이어 임. (note! m개의 필터를 가짐)
대신 dropout은 를 사용, 는 element-wise multiplicator 연산자이고, 은 1이 되는 것의 확률값이 p인 베르누이 랜덤 변수의 ‘마스킹’ 벡터
Gradient는 마스킹 되지 않은 유닛을 통해서만 역전파 됨.
테스트 시 학습된 가중치 벡터들은 와 같이 p에 의해 스케일 되며, 는 보지 않은 문장을 점수매기기 위해 사용됨(without dropout)
추가로 경사 하강 스텝 후에 어디든 인 곳에서 를 로 rescaling함으로써 가중치 벡터의 -norm을 제한
3. Datasets and Experimental Setup
Hyperparametes and Training
- ReLU
- filter windows (h) = 3, 4, 5 w/ 100 feature maps each
- dropout (p) = 0.5
- constraint (s) = 3
- mini-batch size = 50
- dev set에 early stopping 한 것 빼고 다른 건 하지 않음
Model Variations
CNN-rand
baseline 모델. 모든 단어들이 랜덤하게 initialize되었고, training 중 수정됨
CNN-static
word2vec pretrained 벡터 사용. 알려지지 않은 단어를 포함한 모든 단어들이 랜덤하게 initialize되었고, 정적으로 유지되며, 모델의 다른 파라미터만 학습됨
CNN-non-static
CNN-static과 같지만, pretrained 벡터가 각 태스크에 대해 fine-tuning 됨
CNN-multichannel
두 세트의 단어 벡터를 사용한 모델. 각 벡터의 집합은 채널로 다뤄지며, 각 필터는 양 채널에 모두 적용됨. 하지만 그라디언트는 둘 중 하나의 채널을 통해 역전파가 수행됨. 따라서 모델은 하나는 static하게 냅두면서 다른 하나는 fine-tuning이 가능하게 됨. 양 채널 모두 word2vec으로 initialize됨.
