2. 시작하기 전에: 신경망의 수학적 구성 요소 p60
딥러닝을 이해하려면 여러 가지 수학 개념과 친숙해져야 합니다. 텐서, 텐서 연산, 미분, 경사 하강법gradient descent 등입니다. 이 장의 목표는 너무 기술적으로 깊게 들어가지 않고 이 개념들을 이해하는 것입니다. 특히 수학에 익숙하지 않은 사람들이 어려워할 수 있고 설명을 위해 꼭 필요하지도 않기 때문에 수학 기호는 사용하지 않습니다.
텐서와 경사 하강법을 설명하기 위해 실제 신경망 예제로 이 장을 시작하겠습니다. 그리고 새로운 개념을 하나씩 소개합니다. 이 개념들은 이어진 장에 포함된 예제들을 이해하려면 꼭 알고 넘어가야 합니다!
이 장을 읽고 나면 신경망의 작동 원리를 이해할 수 있고, 3장에서 다룰 실제 애플리케이션으로도 넘어갈 수 있습니다.
2.1 신경망과의 첫 만남 p60
케라스 파이썬 라이브러리를 사용하여 손글씨 숫]자 분류를 학습하는 구체적인 신경망 예제를 살펴보겠습니다. 케라스나 비슷한 라이브러리를 사용한 경험이 없다면 당장은 이 첫 번째 예제를 모두 이해하지 못할 것입니다. 어쩌면 아직 케라스를 설치하지 않았을지도 모릅니다. 괜찮습니다. 다음 장에서 이 예제를 하나하나 자세히 설명합니다. 코드가 좀 이상하거나 요술처럼 보이더라도 너무 걱정하지 마세요. 일단 시작해 보겠습니다
지금 풀려는 문제는 흑백 손글씨 숫자 이미지(28×28픽셀)를 10개의 범주(0에서 9까지)로 분류하는 것입니다. 머신 러닝 커뮤니티에서 고전으로 취급받는 데이터셋인 MNIST를 사용하겠습니다. 이 데이터셋은 머신 러닝의 역사만큼 오래되었고 많은 연구에 사용되었습니다. 이 데이터셋은 1980년대 미국 국립표준기술연구소National Institute of Standards and Technology, NIST에서 수집한 6만 개의 훈련 이미지와 1만 개의 테스트 이미지로 구성되어 있습니다. MNIST 문제를 알고리즘이 제대로 작동하는지 확인하기 위한 딥러닝계의 “hello world”라고 생각해도 됩니다. 머신 러닝 기술자가 되기까지 연구 논문이나 블로그 포스트 등에서 MNIST를 보고 또 보게 될 것입니다. 그림 2-1에 몇 개의 MNIST 샘플이 있습니다.

그림 2-1 MNIST 샘플 이미지
클래스와 레이블에 관한 노트
머신 러닝에서 분류 문제의 범주category를 클래스class 1라고 합니다. 데이터 포인트는 샘플sample이라고 합 니다. 특정 샘플의 클래스는 레이블label이라고 합니다.
이 예제를 당장 실습할 필요는 없습니다. 하고 싶다면 3.3절에 나와 있는 대로 케라스 환경을 먼저 설정해 주어야 합니다.
MNIST 데이터셋은 넘파이NumPy 2 배열 형태로 케라스에 이미 포함되어 있습니다.
2.2 신경망을 위한 데이터 표현
이전 예제에서 텐서tensor라 부르는 다차원 넘파이 배열에 데이터를 저장하는 것부터 시작했습니다.8 최근의 모든 머신 러닝 시스템은 일반적으로 텐서를 기본 데이터 구조로 사용합니다. 텐서는 머신 러닝의 기본 구성 요소입니다. 구글의 텐서플로 이름을 여기에서 따왔습니다. 그럼 텐서는 무엇일까요?
핵심적으로 텐서는 데이터를 위한 컨테이너container입니다. 거의 항상 수치형 데이터를 다루므로 숫자를 위한 컨테이너입니다. 아마 2D 텐서인 행렬에 대해 이미 알고 있을 것입니다. 텐서는 임의의 차원 개수를 가지는 행렬의 일반화된 모습입니다(텐서에서는 차원dimension을 종종 축axis이라고 부릅니다).
2.2.1 스칼라(0D 텐서)
하나의 숫자만 담고 있는 텐서를 스칼라scalar 스칼라 텐서, 0차원 텐서, 0D 텐서)라고 부릅니다. 넘파이에서는 float32나 float64 타입의 숫자가 스칼라 텐서(또는 배열 스칼라array scalar 9입니다. ndim 속성을 사용하면 넘파이 배열의 축 개수를 확인할 수 있습니다. 스칼라 텐서의 축 개수는 0입니다(ndim = = 0). 텐서의 축 개수를 랭크rank라고도 부릅니다.10 다음이 스칼라 텐서입니다.
2.2.2 벡터(1D 텐서)
숫자의 배열을 벡터vector 또는 1D 텐서라고 부릅니다. 1D 텐서는 딱 하나의 축을 가집니다. 넘파이에서 벡터를 나타내면 다음과 같습니다.
>>> x = np.array([12, 3, 6, 14, 7])
>>> x
array([12, 3, 6, 14, 7])
>>> x.ndim
1이 벡터는 5개의 원소를 가지고 있으므로 5차원 벡터라고 부릅니다. 5D 벡터와 5D 텐서를 혼동하지 마세요! 5D 벡터는 하나의 축을 따라 5개의 차원을 가진 것이고 5D 텐서는 5개의 축을 가진 것입니다(텐서의 각 축을 따라 여러 개의 차원을 가진 벡터가 놓일 수 있습니다). 차원수dimensionality는 특정 축을 따라 놓인 원소의 개수(5D 벡터와 같은 경우)이거나 텐서의 축 개수(5D 텐서와 같은 경우)를 의미하므로 가끔 혼동하기 쉽습니다. 후자의 경우 랭크5 인 텐서라고 말하는 것이 기술적으로 좀 더 정확합니다(텐서의 랭크가 축의 개수입니다). 그럼에도 5D 텐서처럼 모호한 표기가 통용됩니다.
2.2.3 행렬(2D 텐서)
벡터의 배열이 행렬matrix 또는 2D 텐서입니다. 행렬에는 2개의 축이 있습니다(보통 행row과 열column이라고 부릅니다). 행렬은 숫자가 채워진 사각 격자라고 생각할 수 있습니다. 넘파이에 서 행렬을 나타내면 다음과 같습니다.
>>> x = np.array([[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]])
>>> x.ndim
2첫 번째 축에 놓여 있는 원소를 행이라 부르고, 두 번째 축에 놓여 있는 원소를 열이라 부릅니다. 앞의 예에서는 x의 첫 번째 행은 [5, 78, 2, 34, 0]이고, 첫 번째 열은 [5, 6, 7]입니다.
2.2.4 3D 텐서와 고차원 텐서
이런 행렬들을 하나의 새로운 배열로 합치면 숫자가 채워진 직육면체 형태로 해석할 수 있는 3D 텐서가 만들어집니다. 넘파이에서 3D 텐서를 나타내면 다음과 같습니다.
>>> x = np.array([[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]],
[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]],
[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]]])
>>> x.ndim
33D 텐서들을 하나의 배열로 합치면 4D 텐서를 만드는 식으로 이어집니다. 딥러닝에서는 보통 0D에서 4D까지의 텐서를 다룹니다. 동영상 데이터를 다룰 경우에는 5D 텐서까지 가기도 합니다.
2.2.5 핵심 속성
텐서는 3개의 핵심 속성으로 정의됩니다.
- 축의 개수(랭크): 예를 들어 3D 텐서에는 3개의 축이 있고, 행렬에는 2개의 축이 있습니다. 넘파이 라이브러리에서는 ndim 속성에 저장되어 있습니다.
- 크기shape: 텐서의 각 축을 따라 얼마나 많은 차원이 있는지를 나타낸 파이썬의 튜플tuple입니다. 예를 들어 앞에 나온 행렬의 크기는 (3, 5)이고 3D 텐서의 크기는 (3, 3, 5)입니다. 벡터의 크기는 (5,)처럼 1개의 원소로 이루어진 튜플입니다. 배열 스칼라는 ()처럼 크기가 없습니다.
- 데이터 타입(넘파이에서는 dtype에 저장됩니다): 텐서에 포함된 데이터의 타입입니다. 예를 들어 텐서의 타입은 float32, uint8, float64 등이 될 수 있습니다. 드물게 char 타입을 사용합니다. 텐서는 사전에 할당되어 연속된 메모리에 저장되어야 하므로 넘파이 배열은 (그리고 대부분 다른 라이브러리는) 가변 길이의 문자열을 지원하지 않습니다.
이를 구체적으로 확인해 보기 위해서 MNIST 예제에서 사용했던 데이터를 다시 들여다봅시다. 먼저 MNIST 데이터셋을 불러들입니다.
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()그다음 train_images 배열의 ndim 속성으로 축의 개수를 확인합니다.
>>> print(train_images.ndim)
3다음은 배열의 크기입니다.
>>> print(train_images.shape)
(60000, 28, 28)dtype 속성으로 데이터 타입을 확인합니다.
>>> print(train_images.dtype)
uint8이 배열은 8비트 정수형 3D 텐서입니다. 좀 더 정확하게는 28×28 크기의 정수 행렬 6만 개가 있는 배열입니다. 각 행렬은 하나의 흑백 이미지고, 행렬의 각 원소는 0에서 255 사이의 값을 가집니다.
이 3D 텐서에서 다섯 번째 샘플을 (파이썬의 표준 과학 라이브러리 중 하나인) 맷플롯립Matplotlib 라이브러리를 사용해서 확인해 봅시다11(그림 2–2 참고).
코드 2-6 다섯 번째 이미지 출력하기
digit = train_images[4]
import matplotlib.pyplot as plt
plt.imshow(digit, cmap=plt.cm.binary)
plt.show()2.2.6 넘파이로 텐서 조작하기
이전 예제에서 train_images[i] 같은 형식으로 첫 번째 축을 따라 특정 숫자를 선택했습니다. 배열에 있는 특정 원소들을 선택하는 것을 슬라이싱slicing이라고 합니다. 넘파이 배열에서 할 수 있는 슬라이싱 연산을 살펴보겠습니다.
다음 예는 11번째에서 101번째까지(101번째는 포함하지 않고) 숫자를 선택하여 (90, 28, 28) 크기의 배열을 만듭니다.
>>> my_slice = train_images[10:100]
>>> print(my_slice.shape)
(90, 28, 28)
동일하지만 조금 더 자세한 표기법은 각 배열의 축을 따라 슬라이싱의 시작 인덱스와 마지막 인덱스를 지정하는 것입니다. :(콜론)은 전체 인덱스를 선택합니다.>>> my_slice = train_images[10:100, :, :] 이전 예와 동일합니다.
>>> my_slice.shape
(90, 28, 28)
>>> my_slice = train_images[10:100, 0:28, 0:28] 역시 이전과 동일합니다.
>>> my_slice.shape
(90, 28, 28)
일반적으로 각 배열의 축을 따라 어떤 인덱스 사이도 선택할 수 있습니다. 예를 들어 이미지의 오른쪽 아래 14×14픽셀을 선택하려면 다음과 같이 합니다.my_slice = train_images[:, 14:, 14:]음수 인덱스도 사용할 수 있습니다. 파이썬 리스트의 음수 인덱스와 마찬가지로 현재 축의 끝에서 상대적인 위치를 나타냅니다. 정중앙에 위치한 14×14픽셀 조각을 이미지에서 잘라 내려면 다음과 같이 합니다.
my_slice = train_images[:, 7:-7, 7:-7]2.2.7 배치 데이터
일반적으로 딥러닝에서 사용하는 모든 데이터 텐서의 첫 번째 축(인덱스가 0부터 시작하므로 0번째 축)은 샘플 축sample axis입니다(이따금 샘플 차원sample dimension이라고도 부릅니다). MNIST 예제에서는 숫자 이미지가 샘플입니다.
딥러닝 모델은 한 번에 전체 데이터셋을 처리하지 않습니다. 그 대신 데이터를 작은 배치batch로 나눕니다. 구체적으로 말하면 MNIST 숫자 데이터에서 크기가 128인 배치 하나는 다음과 같습니다.
batch = train_images[:128]그다음 배치는 다음과 같습니다.
batch = train_images[128:256]그리고 n번째 배치는 다음과 같습니다.
batch = train_images[128 * n:128 * (n + 1)]이런 배치 데이터를 다룰 때는 첫 번째 축(0번 축)을 배치 축batch axis 또는 배치 차원batch dimension이라고 부릅니다. 케라스나 다른 딥러닝 라이브러리를 사용할 때 이런 용어를 자주 만날 것입니다.
2.2.8 텐서의 실제 사례
앞으로 보게 될 텐서의 몇 가지 예를 통해 좀 더 확실하게 알아보겠습니다. 우리가 사용할 데이터는 대부분 다음 중 하나에 속할 것입니다.
- 벡터 데이터: (samples, features) 크기의 2D 텐서
- 시계열 데이터 또는 시퀀스sequence 데이터: (samples, timesteps, features) 크기의 3D 텐서
- 이미지: (samples, height, width, channels) 또는 (samples, channels, height, width) 크기의 4D 텐서
- 동영상: (samples, frames, height, width, channels) 또는 (samples, frames, channels, height, width) 크기의 5D 텐서
2.2.9 벡터 데이터
대부분의 경우에 해당됩니다. 이런 데이터셋에서는 하나의 데이터 포인트가 벡터로 인코딩될 수 있으므로 배치 데이터는 2D 텐서로 인코딩될 것입니다(즉 벡터의 배열입니다). 여기서 첫 번째 축은 샘플 축이고, 두 번째 축은 특성 축feature axis입니다.
2개의 예를 살펴보겠습니다.
- 사람의 나이, 우편 번호, 소득으로 구성된 인구 통계 데이터. 각 사람은 3개의 값을 가진 벡터로 구성되고 10만 명이 포함된 전체 데이터셋은 (100000, 3) 크기의 텐서에 저장될 수 있습니다.
- (공통 단어 2만 개로 만든 사전에서) 각 단어가 등장한 횟수로 표현된 텍스트 문서 데이터셋. 각 문서는 2만 개의 원소(사전에 있는 단어마다 하나의 원소에 대응합니다)를 가진 벡터로 인코딩될 수 있습니다. 500개의 문서로 이루어진 전체 데이터셋은 (500, 20000) 크기의 텐서로 저장됩니다.
2.2.10 시계열 데이터 또는 시퀀스 데이터
데이터에서 시간이 (또는 연속된 순서가) 중요할 때는 시간 축을 포함하여 3D 텐서로 저장됩니다. 각 샘플은 벡터(2D 텐서)의 시퀀스로 인코딩되므로 배치 데이터는 3D 텐서로 인코딩될 것입니다(그림 2–3 참고).
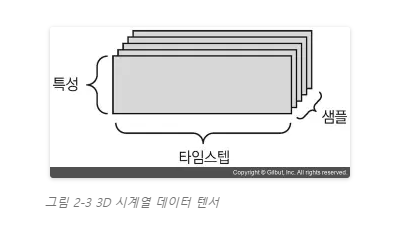
관례적으로 시간 축은 항상 두 번째 축(인덱스가 1인 축)입니다.12 몇 가지 예를 들어 보겠습니다.
- 주식 가격 데이터셋: 1분마다 현재 주식 가격, 지난 1분 동안에 최고 가격과 최소 가격을 저장합니다. 1분마다 데이터는 3D 벡터로 인코딩되고 하루 동안의 거래는 (390, 3) 크기의 2D 텐서로 인코딩됩니다(하루의 거래 시간은 390분입니다13). 250일치의 데이터는 (250, 390, 3) 크기의 3D 텐서로 저장될 수 있습니다. 여기에서 1일치 데이터가 하나의 샘플이 됩니다.
- 트윗 데이터셋: 각 트윗은 128개의 알파벳으로 구성된 280개의 문자 시퀀스입니다. 여기에서는 각 문자가 128개의 크기인 이진 벡터로 인코딩될 수 있습니다(해당 문자의 인덱스만 1이고 나머지는 모두 0인 벡터). 그러면 각 트윗은 (280, 128) 크기의 2D 텐서로 인코딩될 수 있습니다. 100만 개의 트윗으로 구성된 데이터셋은 (1000000, 280, 128) 크기의 텐서에 저장됩니다.
2.2.11 이미지 데이터
이미지는 전형적으로 높이, 너비, 컬러 채널의 3차원으로 이루어집니다. (MNIST 숫자처럼) 흑백 이미지는 하나의 컬러 채널만을 가지고 있어 2D 텐서로 저장될 수 있지만 관례상 이미지 텐서는 항상 3D로 저장됩니다. 흑백 이미지의 경우 컬러 채널의 차원 크기는 1입니다. 256×256 크기의 흑백 이미지에 대한 128개의 배치는 (128, 256, 256, 1) 크기의 텐서에 저장될 수 있습니다. 컬러 이미지에 대한 128개의 배치라면 (128, 256, 256, 3) 크기의 텐서에 저장될 수 있습니다(그림 2–4 참고).
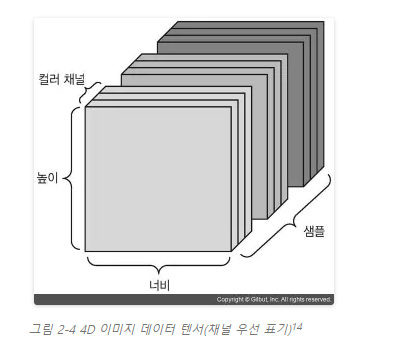
이미지 텐서의 크기를 지정하는 방식은 두 가지입니다. (텐서플로에서 사용하는) 채널 마지막channel-last 방식과 (씨아노에서 사용하는) 채널 우선channel-first 방식입니다. 구글의 텐서플로 머신 러닝 프레임워크는 (samples, height, width, color_depth)처럼 컬러 채널의 깊이를 끝에 놓습니다. 반면에 씨아노는 (samples, color_depth, height, width)처럼 컬러 채널의 깊이를 배치 축 바로 뒤에 놓습니다. 씨아노 방식을 사용하면 앞선 예는 (128, 1, 256, 256)과 (128, 3, 256, 256)이 됩니다. 케라스 프레임워크는 두 형식을 모두 지원합니다.15
2.2.12 비디오 데이터
비디오 데이터는 현실에서 5D 텐서가 필요한 몇 안 되는 데이터 중 하나입니다. 하나의 비디오는 프레임의 연속이고 각 프레임은 하나의 컬러 이미지입니다. 프레임이 (height, width, color_depth)의 3D 텐서로 저장될 수 있기 때문에 프레임의 연속은 (frames, height, width, color_depth)의 4D 텐서로 저장될 수 있습니다. 여러 비디오의 배치는 (samples, frames, height, width, color_depth)의 5D 텐서로 저장될 수 있습니다.
예를 들어 60초짜리 144×256 유튜브 비디오 클립을 초당 4프레임으로 샘플링하면 240프레임이 됩니다. 이런 비디오 클립을 4개 가진 배치는 (4, 240, 144, 256, 3) 크기의 텐서에 저장될 것입니다. 총 106,168,320개의 값이 있습니다! 이 텐서의 dtype을 float32로 했다면16 각 값이 32비트로 저장될 것이므로 텐서의 저장 크기는 405MB가 됩니다. 아주 크네요! 실생활에서 접하는 비디오는 float32 크기로 저장되지 않기 때문에 훨씬 용량이 적고, 일반적으로 높은 압축률로 (MPEG 포맷 같은 방식을 사용하여) 압축되어 있습니다.
2.3 신경망의 톱니바퀴: 텐서 연산 p75
컴퓨터 프로그램을 이진수의 입력을 처리하는 몇 개의 이항 연산(AND, OR, NOR 등)으로 표현할 수 있는 것처럼, 심층 신경망이 학습한 모든 변환을 수치 데이터 텐서에 적용하는 몇 종류의 텐서 연산tensor operation으로 나타낼 수 있습니다. 예를 들어 텐서 덧셈이나 텐서 곱셈 등입니다.
첫 번째 예제에서는 Dense 층을 쌓아서 신경망을 만들었습니다. 케라스의 층은 다음과 같이 생성 합니다.
keras.layers.Dense(512, activation='relu')
이 층은 2D 텐서를 입력으로 받고 입력 텐서의 새로운 표현인 또 다른 2D 텐서를 반환하는 함수처럼 해석할 수 있습니다. 구체적으로 보면 이 함수는 다음과 같습니다(W는 2D 텐서고, b는 벡터입니다. 둘 모두 층의 속성입니다1
output = relu(dot(W, input) + b)
좀 더 자세히 알아보겠습니다. 여기에는 3개의 텐서 연산이 있습니다. 입력 텐서와 텐서 W 사이의 점곱(dot), 점곱의 결과인 2D 텐서와 벡터 b 사이의 덧셈(+), 마지막으로 relu(렐루) 연산입니다. relu(x)는 max(x, 0)입니다.18
Note 이 절은 선형대수학(linear algebra)을 다루지만 어떤 수학 기호도 사용하지 않습니다. 수학에 익숙하지 않은 프로그래머는 수학 방정식보다 짧은 파이썬 코드를 보는 것이 수학 개념을 이해하는 데 훨씬 도움이 됩니다. 앞으로도 계속 넘파이 코드를 사용하여 설명합니다.
2.3.1 원소별 연산 p76
relu 함수와 덧셈은 원소별 연산 element-wise operation 입니다. 이 연산은 텐서에 있는 각 원소에 독립적으로 적용됩니다. 이 말은 고도의 병렬 구현(1970~1990년대 슈퍼컴퓨터의 구조인 벡터 프로세서vector processor에서 온 용어인 벡터화된 구현을 말합니다)이 가능한 연산이라는 의미입니다. 파이썬으로 단순한 원소별 연산을 구현한다면 다음 relu 연산 구현처럼 for 반복문을 사용할 것입니다.19
def naive_relu(x): assert len(x.shape) == 2 # x는 2D 넘파이 배열입니다. x = x.copy() # 입력 텐서 자체를 바꾸지 않도록 복사합니다. for i in range(x.shape[0]): for j in range(x.shape[1]): x[i, j] = max(x[i, j], 0) return x
덧셈도 동일합니다.
def naive_add(x, y): assert len(x.shape) == 2 # x와 y는 2D 넘파이 배열입니다. assert x.shape == y.shape x = x.copy() # 입력 텐서 자체를 바꾸지 않도록 복사합니다. for i in range(x.shape[0]): for j in range(x.shape[1]): x[i, j] += y[i, j] return x
같은 원리로 원소별 곱셈, 뺄셈 등을 할 수 있습니다.
사실 넘파이 배열을 다룰 때는 최적화된 넘파이 내장 함수로 이런 연산들을 처리할 수 있습니다. 넘파이는 시스템에 설치된 BLASBasic Linear Algebra Subprogram 구현에 복잡한 일들을 위임합니다.20 BLAS는 고도로 병렬화되고 효율적인 저수준의 텐서 조작 루틴이며, 전형적으로 포트란Fortran이나 C 언어로 구현되어 있습니다.
넘파이는 다음과 같은 원소별 연산을 엄청난 속도로 처리합니다
import numpy as np z = x + y # 원소별 덧셈 z = np.maximum(z, 0.) # 원소별 렐루 함수
2.3.2 브로드캐스팅 p77
앞서 살펴본 단순한 덧셈 구현인 naive_add는 동일한 크기의 2D 텐서만 지원합니다. 하지만 이전에 보았던 Dense 층에서는 2D 텐서와 벡터를 더했습니다. 크기가 다른 두 텐서가 더해질 때 무슨 일이 일어날까요?
모호하지 않고 실행 가능하다면 작은 텐서가 큰 텐서의 크기에 맞추어 브로드캐스팅broadcasting됩니다. 브로드캐스팅은 두 단계로 이루어집니다.
- 큰 텐서의 ndim에 맞도록 작은 텐서에 (브로드캐스팅 축이라고 부르는) 축이 추가됩니다.
- 작은 텐서가 새 축을 따라서 큰 텐서의 크기에 맞도록 반복됩니다.
구체적인 예를 살펴보겠습니다.
X의 크기는 (32, 10)이고 y의 크기는 (10,)라고 가정합시다. 먼저 y에 비어 있는 첫 번째 축을 추가하여 크기를 (1, 10)으로 만듭니다. 그런 다음 y를 이 축에 32번 반복하면 텐서 Y의 크기는 (32, 10)이 됩니다. 여기에서 Y[i, :] == y for i in range(0, 32)입니다. 이제 X와 Y의 크기가 같으므로 더할 수 있습니다.
구현 입장에서는 새로운 텐서가 만들어지면 매우 비효율적이므로 어떤 2D 텐서도 만들어지지 않습니다. 반복된 연산은 완전히 가상적입니다. 이 과정은 메모리 수준이 아니라 알고리즘 수준에서 일어납니다. 하지만 새로운 축을 따라 벡터가 32번 반복된다고 생각하는 것이 이해하기 쉽습니다. 다음은 단순하게 구현한 예입니다.
def naive_add_matrix_and_vector(x, y): assert len(x.shape) == 2 # x는 2D 넘파이 배열입니다. assert len(y.shape) == 1 # y는 넘파이 벡터입니다. assert x.shape[1] == y.shape[0] x = x.copy() # 입력 텐서 자체를 바꾸지 않도록 복사합니다. for i in range(x.shape[0]): for j in range(x.shape[1]): x[i, j] += y[j] return x
(a, b, .. . n, n + 1, .. . m) 크기의 텐서와 (n, n + 1, .. . m) 크기의 텐서 사이에 브로드캐스팅으로 원소별 연산을 적용할 수 있습니다. 이때 브로드캐스팅은 a부터 n – 1까지의 축에 자동으로 일어납니다.
다음은 크기가 다른 두 텐서에 브로드캐스팅으로 원소별 maximum 연산을 적용하는 예입니다.
import numpy as np x = np.random.random((64, 3, 32, 10)) # x는 (64, 3, 32, 10) 크기의 랜덤 텐서입니다. y = np.random.random((32, 10)) # y는 (32, 10) 크기의 랜덤 텐서입니다. z = np.maximum(x, y) # 출력 z 크기는 x와 동일하게 (64, 3, 32, 10)입니다.
2.3.3 텐서 점곱 p79
텐서 곱셈 tensor product이라고도 부르는(원소별 곱셈과 혼동하지 마세요) 점곱 연산dot operation은 가장 널리 사용되고 유용한 텐서 연산입니다. 원소별 연산과 반대로 입력 텐서의 원소들을 결합시킵니다.
넘파이, 케라스, 씨아노, 텐서플로에서 원소별 곱셈은 * 연산자를 사용합니다. 텐서플로에서는 dot 연산자가 다르지만 넘파이와 케라스는 점곱 연산에 보편적인 dot 연산자를 사용합니다.
import numpy as np z = np.dot(x, y) z = x · y
점곱 연산은 수학에서 어떤 일을 할까요? 2개의 벡터 x와 y의 점곱은 다음과 같이 계산을 합니다.
def naive_vector_dot(x, y): assert len(x.shape) == 1 # x와 y는 넘파이 벡터입니다. assert len(y.shape) == 1 assert x.shape[0] == y.shape[0] z = 0. for i in range(x.shape[0]): z += x[i] * y[i] return z
여기서 볼 수 있듯이 두 벡터의 점곱은 스칼라가 되므로 원소 개수가 같은 벡터끼리 점곱이 가능합니다.
행렬 x와 벡터 y 사이에서도 점곱이 가능합니다. y와 x의 행 사이에서 점곱이 일어나므로 벡터가 반환됩니다. 다음과 같이 구현할 수 있습니다.
import numpy as np def naive_matrix_vector_dot(x, y): assert len(x.shape) == 2 # x는 넘파이 행렬입니다. assert len(y.shape) == 1 # y는 넘파이 벡터입니다. assert x.shape[1] == y.shape[0] # x의 두 번째 차원이 y의 첫 번째 차원과 같아야 합니다! z = np.zeros(x.shape[0]) # 이 연산은 x의 행과 같은 크기의 0이 채워진 벡터를 만듭니다. for i in range(x.shape[0]): for j in range(x.shape[1]): z[i] += x[i, j] * y[j] return z
행렬–벡터 점곱과 벡터–벡터 점곱 사이의 관계를 부각하기 위해 앞에서 만든 함수를 재사용해 보겠습니다.
def naive_matrix_vector_dot(x, y): z = np.zeros(x.shape[0]) for i in range(x.shape[0]): z[i] = naive_vector_dot(x[i, :], y) return z
두 텐서 중 하나라도 ndim이 1보다 크면 dot 연산에 교환 법칙이 성립되지 않습니다. 다시 말하면 dot(x, y)와 dot(y, x) 가 같지 않습니다.
물론 점곱은 임의의 축 개수를 가진 텐서에 일반화됩니다. 가장 일반적인 용도는 두 행렬 간의 점곱일 것입니다. x.shape[1] = = y.shape[0]일 때 두 행렬 x와 y의 점곱(dot(x, y))이 성립됩니다. x의 열과 y의 행 사이 벡터 점곱으로 인해 (x.shape[0], y.shape[1]) 크기의 행렬이 됩니다. 다음은 단순한 구현 예입니다.
def naive_matrix_dot(x, y): assert len(x.shape) == 2 # x와 y는 넘파이 행렬입니다. assert len(y.shape) == 2 assert x.shape[1] == y.shape[0] # x의 두 번째 차원이 y의 첫 번째 차원과 같아야 합니다! z = np.zeros((x.shape[0], y.shape[1])) # 이 연산은 0이 채워진 특정 크기의 벡터를 만듭니다. for i in range(x.shape[0]): # x의 행을 반복합니다. for j in range(y.shape[1]): # y의 열을 반복합니다. row_x = x[i, :] column_y = y[:, j] z[i, j] = naive_vector_dot(row_x, column_y) return z
그림 2-5와 같이 입력과 출력을 배치해 보면 어떤 크기의 점곱이 가능한지 이해하는 데 도움이 됩니다.
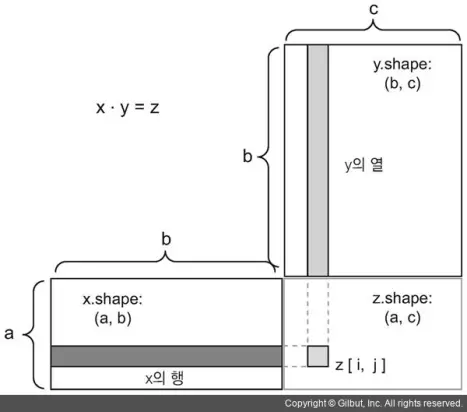
x, y, z는 직사각형 모양으로 그려져 있습니다(원소들이 채워진 박스라고 생각하면 됩니다). x의 행 벡터와 y의 열 벡터가 같은 크기여야 하므로 자동으로 x의 너비는 y의 높이와 동일해야 합니다. 새로운 머신 러닝 알고리즘을 개발할 때 이런 그림을 자주 그리게 될 것입니다.
더 일반적으로는 앞서 설명한 2D의 경우처럼 크기를 맞추는 동일한 규칙을 따르면 다음과 같이 고차원 텐서 간의 점곱을 할 수 있습니다.
(a, b, c, d) . (d,) -> (a, b, c)
(a, b, c, d) . (d, e) -> (a, b, c, e)
2.3.4 텐서 크기 변환 p81
꼭 알아 두어야 할 세 번째 텐서 연산은 텐서 크기 변환 tensor reshaping입니다. 첫 번째 신경망 예제의 Dense 층에서는 사용되지 않지만 신경망에 주입할 숫자 데이터를 전처리할 때 사용했습니다.
train_images = train_images.reshape((60000, 28 * 28))
텐서의 크기를 변환한다는 것은 특정 크기에 맞게 열과 행을 재배열한다는 뜻입니다. 당연히 크기가 변환된 텐서는 원래 텐서와 원소 개수가 동일합니다. 간단한 예제를 통해 크기 변환을 알아보겠습니다.
>> x = np.array([[0., 1.], [2., 3.], [4., 5.]]) >> print(x.shape) (3, 2) >> x = x.reshape((6, 1)) >> x array([[ 0.], [ 1.], [ 2.], [ 3.], [ 4.], [ 5.]]) >> x = x.reshape((2, 3)) >> x array([[ 0., 1., 2.], [ 3., 4., 5.]])
자주 사용하는 특별한 크기 변환은 전치 transposition입니다. 행렬의 전치는 행과 열을 바꾸는 것을 의미합니다. 즉 x[i, :]이 x[:, i]가 됩니다.
>> x = np.zeros((300, 20)) # 모두 0으로 채워진 (300, 20) 크기의 행렬을 만듭니다. >> x = np.transpose(x) >> print(x.shape) (20, 300)
2.3.5 텐서 연산의 기하학적 해석 p82
텐서 연산이 조작하는 텐서의 내용은 어떤 기하학적 공간에 있는 좌표 포인트로 해석될 수 있기 때문에 모든 텐서 연산은 기하학적 해석이 가능합니다. 예를 들어 덧셈을 생각해 보죠. 다음 벡터를 먼저 보겠습니다.
A = [0.5, 1]
이 포인트는 2D 공간에 있습니다(그림 2–6 참고). 일반적으로 그림 2–7과 같이 원점에서 포인트를 연결하는 화살표로 벡터를 나타냅니다.
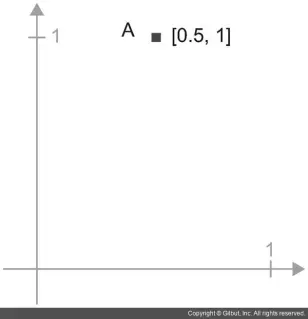
2D 공간에 있는 포인트그림
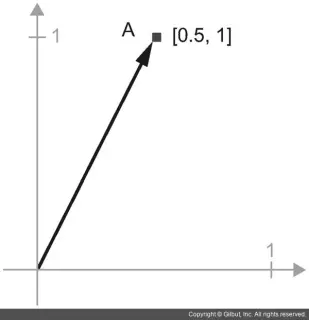
화살표로 나타낸 2D 공간에 있는 포인트
새로운 포인트 B = [1, 0.25]를 이전 벡터에 더해 보겠습니다. 기하학적으로는 벡터 화살표를 연결하여 계산할 수 있습니다. 최종 위치는 두 벡터의 덧셈을 나타내는 벡터가 됩니다(그림 2-8 참고).
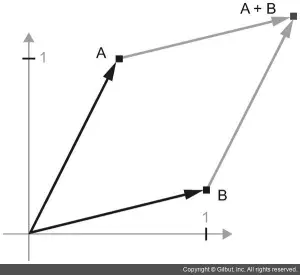
그림 2-8 두 벡터의 덧셈에 대한 기하학적 해석
일반적으로 아핀 변환 affine transformation, 회전, 스케일링scaling 등처럼 기본적인 기하학적 연산은 텐서 연산으로 표현될 수 있습니다. 예를 들어 theta 각도로 2D 벡터를 회전하는 것은 2×2 행렬 R = [u, v]를 점곱하여 구현할 수 있습니다. 여기에서 u, v는 동일 평면상의 벡터이며, u = [cos(theta), sin(theta)]고 v = [-sin(theta), cos(theta)]입니다.
2.3.6 딥러닝의 기하학적 해석 p86
신경망은 전체적으로 텐서 연산의 연결로 구성된 것이고, 모든 텐서 연산은 입력 데이터의 기하학적 변환임을 배웠습니다. 단순한 단계들이 길게 이어져 구현된 신경망을 고차원 공간에서 매우 복잡한 기하학적 변환을 하는 것으로 해석할 수 있습니다.
3D라면 다음 비유가 이해하는 데 도움이 될 것입니다. 하나는 빨간색이고 다른 하나는 파란색인 2개의 색종이가 있다고 가정합시다. 두 장을 겹친 다음 뭉쳐서 작은 공으로 만듭니다. 이 종이 공이 입력 데이터고 색종이는 분류 문제의 데이터 클래스입니다. 신경망(또는 다른 머신 러닝 알고리즘)이 해야 할 일은 종이 공을 펼쳐서 두 클래스가 다시 깔끔하게 분리되는 변환을 찾는 것입니다. 손가락으로 종이 공을 조금씩 펼치는 것처럼 딥러닝을 사용하여 3D 공간에서 간단한 변환들을 연결해서 이를 구현합니다.
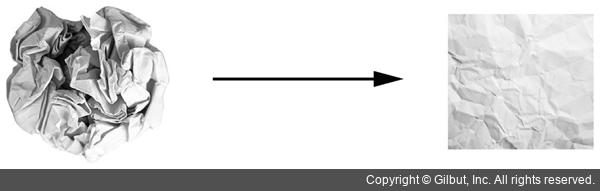
그림 2-9 복잡한 데이터의 매니폴드(manifold)24 펼치기
종이 공을 펼치는 것이 머신 러닝이 하는 일입니다. 복잡하고 심하게 꼬여 있는 데이터의 매니폴드에 대한 깔끔한 표현을 찾는 일입니다. 이쯤이면 왜 딥러닝이 이런 작업에 뛰어난지 알았을 것입니다. 기초적인 연산을 길게 연결하여 복잡한 기하학적 변환을 조금씩 분해하는 방식이 마치 사람이 종이 공을 펼치기 위한 전략과 매우 흡사하기 때문입니다.
심층 네트워크의 각 층은 데이터를 조금씩 풀어 주는 변환을 적용하므로, 이런 층을 깊게 쌓으면 아주 복잡한 분해 과정을 처리할 수 있습니다.
2.4 신경망의 엔진: 그래디언트 기반 최적화 p87
이전 절에서 보았듯이 첫 번째 신경망 예제에 있는 각 층은 입력 데이터를 다음과 같이 변환합니다.
output = relu(dot(W, input) * b)
이 식에서 텐서 W와 b는 층의 속성처럼 볼 수 있습니다. 가중치 weight 또는 훈련되는 파라미터trainable parameter라고 부릅니다.(각각 커널kernel 25과 편향bias이라고 부르기도 합니다). 이런 가중치에는 훈련 데이터를 신경망에 노출시켜서 학습된 정보가 담겨 있습니다.
훈련은 다음과 같은 훈련 반복 루프(training loop) 안에서 일어납니다. 필요한 만큼 반복 루프 안에서 이런 단계가 반복됩니다.
- 훈련 샘플 x와 이에 상응하는 타깃 y의 배치를 추출합니다.
- x를 사용하여 네트워크를 실행하고(정방향 패스forward pass 단계), 예측 y_pred를 구합니다.
- y_pred와 y의 차이를 측정하여 이 배치에 대한 네트워크의 손실을 계산합니다.
- 배치에 대한 손실이 조금 감소되도록 네트워크의 모든 가중치를 업데이트합니다.
결국 훈련 데이터에서 네트워크의 손실, 즉 예측 y_pred와 타깃 y의 오차가 매우 작아질 것입니다. 이 네트워크는 입력에 정확한 타깃을 매핑하는 것을 학습했습니다. 전체적으로 보면 마술처럼 보이지만 개별적인 단계로 쪼개어 보면 단순합니다.
1단계는 그냥 입출력 코드이므로 매우 쉽습니다. 2단계와 3단계는 몇 개의 텐서 연산을 적용한 것 뿐이므로 이전 절에서 배웠던 연산을 사용하여 이 단계를 구현할 수 있습니다. 어려운 부분은 네트워크의 가중치를 업데이트하는 4단계입니다. 개별적인 가중치 값이 있을 때 값이 증가해야 할지 감소해야 할지, 또 얼마큼 업데이트해야 할지 어떻게 알 수 있을까요?
한 가지 간단한 방법은 네트워크 가중치 행렬의 원소를 모두 고정하고 관심 있는 하나만 다른 값을 적용해 보는 것입니다. 이 가중치의 초깃값이 0.3이라고 가정합시다. 배치 데이터를 정방향 패스에 통과시킨 후 네트워크의 손실이 0.5가 나왔습니다. 이 가중치 값을 0.35로 변경하고 다시 정방향 패스를 실행했더니 손실이 0.6으로 증가했습니다.
반대로 0.25로 줄이면 손실이 0.4로 감소했습니다. 이 경우에 가중치를 –0.05만큼 업데이트한 것이 손실을 줄이는 데 기여한 것으로 보입니다. 이런 식으로 네트워크의 모든 가중치에 반복합니다.
이런 접근 방식은 모든 가중치 행렬의 원소마다 두 번의 (비용이 큰) 정방향 패스를 계산해야 하므로 엄청나게 비효율적입니다(보통 수천에서 경우에 따라 수백만 개의 많은 가중치가 있습니다). 신경망에 사용된 모든 연산이 미분 가능differentiable하다는 장점을 사용하여 네트워크 가중치에 대한 손실의 그래디언트gradient 를 계산하는 것이 훨씬 더 좋은 방법입니다. 그래디언트의 반대방향으로 가중치를 이동하면 손실이 감소됩니다.
미분 가능하다는 것과 그래디언트가 무엇인지 이미 알고 있다면 2.4.3절로 건너뛰어도 좋습니다. 그렇지 않으면 다음 두 절이 이해하는 데 도움이 될 것입니다.
2.4.1 도함수란? p89
미분,도함수,기울기,미분계수,그래디언트
실수 x를 새로운 실수 y로 매핑하는 연속적이고 매끄러운 함수 f(x) = y를 생각해 봅시다. 이 함수가 연속적이므로 x를 조금 바꾸면 y가 조금만 변경될 것입니다. 이것이 연속성의 개념입니다. x를 작은 값 epsilon_x만큼 증가시켰을 때 y가 epsilon_y만큼 바뀐다고 말할 수 있습니다.
f(x + epsilon_x) = y + epsilon_y
또 이 함수가 매끈하므로(곡선의 각도가 갑자기 바뀌지 않습니다) epsilon_x가 충분히 작다면 어떤 포인트 p에서 기울기 a의 선형 함수로 f를 근사할 수 있습니다. 따라서 epsilon_y는 a * epsilon_x가 됩니다.
f(x + epsilon_x) = y + a * epsilon_x
이 선형적인 근사는 x가 p에 충분히 가까울 때 유효합니다.
이 기울기를 p에서 f의 변화율 derivative 이라고 합니다. 이는 a가 음수일 때 p에서 양수 x만큼 조금 이동하면 f(x)가 감소한다는 것을 의미합니다(그림 2–10과 같이). a가 양수일 때는 음수 x만큼 조금 이동하면 f(x)가 감소됩니다. a의 절댓값(변화율의 크기)은 이런 증가나 감소가 얼마나 빠르게 일어날지 알려 줍니다.
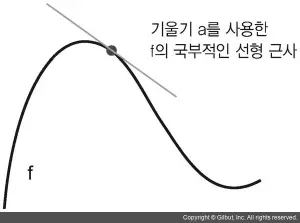
모든 미분 가능한(미분 가능하다는 것은 변화율을 유도할 수 있다는 의미로, 예를 들어 매끄럽고 연속적인 함수입니다) 함수 f(x)에 대해 x의 값을 f의 국부적인 선형 근사인 그 지점의 기울기로 매핑하는 변화율 함수 f'(x)가 존재합니다. 예를 들어 cos(x)의 변화율은 -sin(x)이고, f(x) = a * x의 변화율은 f'(x) = a입니다.
f(x)를 최소화하기 위해 epsilon_x만큼 x를 업데이트하고 싶을 때 f의 변화율을 알고 있으면 해결됩니다. 변화율 함수는 x가 바뀜에 따라 f(x)가 어떻게 바뀔지 설명해 줍니다. f(x)의 값을 감소시키고 싶다면 x를 변화율의 방향과 반대로 조금 이동해야 합니다.
2.4.2 텐서 연산의 변화율: 그래디언트 p90
: 기울기(gradient 그레이디언트) 또는 경도란 벡터 미적분학에서 스칼라장의 최대의 증가율을 나타내는 벡터장을 뜻한다
그래디언트는 텐서 연산의 변화율입니다. 이는 다차원 입력, 즉 텐서를 입력으로 받는 함수에 변화율 개념을 확장시킨 것입니다.
입력 벡터 x, 행렬 W, 타깃 y와 손실 함수 loss가 있다고 가정합시다. W를 사용하여 타깃의 예측 y_pred를 계산하고 손실, 즉 타깃 예측 y_pred와 타깃 y 사이의 오차를 계산할 수 있습니다.
y_pred = dot(W, x)
loss_value = loss(y_pred, y)
입력 데이터 x와 y가 고정되어 있다면 이 함수는 W를 손실 값에 매핑하는 함수로 볼 수 있습니다.
loss_value = f(W)
W의 현재 값을 W0라고 합시다. 포인트 W0에서 f의 변화율은 W와 같은 크기의 텐서인 gradient(f)(W0)입니다. 이 텐서의 각 원소 gradient(f)(W0)[i, j]는 W0[i, j]를 변경했을 때 loss_value가 바뀌는 방향과 크기를 나타냅니다. 다시 말해 텐서 gradient(f)(W0)가 W0에서 함수 f(W) = loss_value의 그래디언트입니다.
앞서 함수 f(x)의 변화율 하나는 곡선 f의 기울기로 해석할 수 있다는 것을 보았습니다. 비슷하게 gradient(f)(W0)는 W0에서 f(W)의 기울기를 나타내는 텐서로 해석할 수 있습니다.
그렇기 때문에 함수 f(x)에 대해서는 변화율의 반대 방향으로 x를 조금 움직이면 f(x)의 값을 감소시킬 수 있습니다. 동일한 방식을 적용하면 함수 f(W)의 입장에서는 그래디언트의 반대 방향으로 W를 움직이면 f(W)의 값을 줄일 수 있습니다.29 예를 들어 W1 = W0 - step * gradient(f)(W0)입니다(step은 스케일을 조정하기 위한 작은 값입니다). 이 말은 기울기가 작아지는 곡면의 낮은 위치로 이동된다는 의미입니다. gradient(f)(W0)는 W0에 아주 가까이 있을 때 기울기를 근사한 것이므로 W0에서 너무 크게 벗어나지 않기 위해 스케일링 비율 step이 필요합니다.

2.4.3 확률적 경사 하강법 p92
미분 가능한 함수가 주어지면 이론적으로 이 함수의 최솟값을 해석적으로 구할 수 있습니다. 함수의 최솟값은 변화율이 0인 지점입니다. 따라서 우리가 할 일은 변화율이 0이 되는 지점을 모두 찾고 이 중에서 어떤 포인트의 함수 값이 가장 작은지 확인하는 것입니다.
신경망에 적용하면 가장 작은 손실 함수의 값을 만드는 가중치의 조합을 해석적으로 찾는 것을 의미합니다. 이는 식 gradient(f)(W) = 0을 풀면 해결됩니다. 이 식은 N개의 변수로 이루어진 다항식입니다. 여기에서 N은 네트워크의 가중치 개수입니다. N = 2나 N = 3인 식을 푸는 것은 가능하지만 실제 신경망에서는 파라미터의 개수가 수천 개보다 적은 경우가 거의 없고 종종 수천만 개가 되기 때문에 해석적으로 해결하는 것이 어렵습니다.
그 대신 앞서 2.4절에서 설명한 알고리즘 네 단계를 사용할 수 있습니다. 랜덤한 배치 데이터에서 현재 손실 값을 토대로 하여 조금씩 파라미터를 수정하는 것입니다. 미분 가능한 함수를 가지고 있으므로 그래디언트를 계산하여 단계 4를 효율적으로 구현할 수 있습니다. 그래디언트의 반대 방향으로 가중치를 업데이트하면 손실이 매번 조금씩 감소할 것입니다.
- 훈련 샘플 배치 x와 이에 상응하는 타깃 y를 추출합니다.
- x로 네트워크를 실행하고 예측 y_pred를 구합니다.
- 이 배치에서 y_pred와 y 사이의 오차를 측정하여 네트워크의 손실을 계산합니다.
- 네트워크의 파라미터에 대한 손실 함수의 그래디언트를 계산합니다(역방향 패스(backward pass)).
- 그래디언트의 반대 방향으로 파라미터를 조금 이동시킵니다. 예를 들어 W -= step * gradient처럼 하면 배치에 대한 손실이 조금 감소할 것입니다.
아주 쉽네요! 방금 전에 이야기한 것이 미니 배치 확률적 경사 하강법(mini-batch stochastic gradient descent)(미니 배치 SGD)입니다. 확률적(stochastic)이란 단어는 각 배치 데이터가 무작위로 선택된다는 의미입니다(확률적이란 것은 무작위(random)하다는 것의 과학적 표현입니다). 네트워크의 파라미터와 훈련 샘플이 하나일 때 이 과정을 그림 2-11에 나타냈습니다.
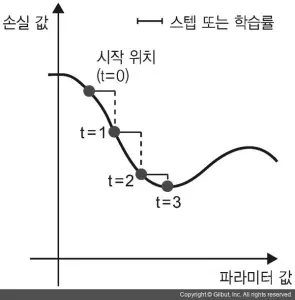
그림에서 볼 수 있듯이 step 값을 적절히 고르는 것이 중요합니다. 이 값이 너무 작으면 곡선을 따라 내려가는 데 너무 많은 반복이 필요하고 지역 최솟값(local minimum)에 갇힐 수 있습니다. step이 너무 크면 손실 함수 곡선에서 완전히 임의의 위치로 이동시킬 수 있습니다.
미니 배치 SGD 알고리즘의 한 가지 변종은 반복마다 하나의 샘플과 하나의 타깃을 뽑는 것입니다. 이것이 (미니 배치 SGD와 반대로) 진정한(true) SGD입니다. 다른 한편으로 극단적인 반대의 경우를 생각해 보면 가용한 모든 데이터를 사용하여 반복을 실행할 수 있습니다. 이를 배치 SGD(batch SGD) 라고 합니다. 더 정확하게 업데이트되지만 더 많은 비용이 듭니다. 극단적인 두 가지 방법의 효율적인 절충안은 적절한 크기의 미니 배치를 사용하는 것입니다.
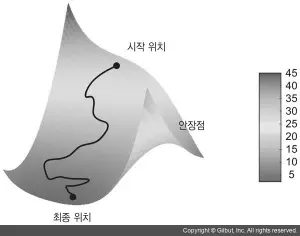
그림 2-11은 1D 파라미터 공간에서 경사 하강법을 설명하고 있지만 실제로는 매우 고차원 공간에서 경사 하강법을 사용하게 됩니다. 신경망에 있는 각각의 가중치 값은 이 공간에서 하나의 독립된 차원이고 수만 또는 수백만 개가 될 수도 있습니다. 손실 함수의 표면을 좀 더 쉽게 이해하기 위해 그림 2-12와 같이 2D 손실 함수의 표면을 따라 진행하는 경사 하강법을 시각화해 볼 수 있습니다.
하지만 신경망이 훈련되는 실제 과정을 시각화하기는 어렵습니다. 사람이 이해할 수 있도록 1,000,000차원의 공간을 표현하는 것이 불가능하기 때문입니다. 그렇기 때문에 저차원 표현으로 얻은 직관이 실전과 항상 맞지는 않는다는 것을 유념해야 합니다. 이는 딥러닝 연구 분야에서 오랫동안 여러 이슈를 일으키는 근원이었습니다
또 업데이트할 다음 가중치를 계산할 때 현재 그래디언트 값만 보지 않고 이전에 업데이트된 가중치를 여러 가지 다른 방식으로 고려하는 SGD 변종이 많이 있습니다. 예를 들어 모멘텀을 사용한 SGD, Adagrad, RMSProp 등입니다. 이런 변종들을 모두 최적화 방법(optimization method) 또는 옵티마이저라고 부릅니다. 특히 여러 변종들에서 사용하는 모멘텀(momentum) 개념은 아주 중요합니다. 모멘텀은 SGD에 있는 2개의 문제점인 수렴 속도와 지역 최솟값을 해결합니다. 그림 2-13은 네트워크의 파라미터 하나에 대한 손실 값의 곡선을 보여 줍니다.
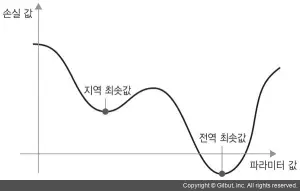
그림에서 볼 수 있듯이 어떤 파라미터 값에서는 지역 최솟값에 도달합니다. 그 지점 근처에서는 왼쪽으로 이동해도 손실이 증가하고, 오른쪽으로 이동해도 손실이 증가합니다. 대상 파라미터가 작은 학습률을 가진 SGD로 최적화되었다면 최적화 과정이 전역 최솟값으로 향하지 못하고 이 지역 최솟값에 갇히게 될 것입니다.
물리학에서 영감을 얻은 모멘텀을 사용하여 이 문제를 피할 수 있습니다. 여기에서 최적화 과정을 손실 곡선 위로 작은 공을 굴리는 것으로 생각하면 쉽게 이해할 수 있습니다. 모멘텀이 충분하면 공이 골짜기에 갇히지 않고 전역 최솟값에 도달할 것입니다. 모멘텀은 현재 기울기 값(현재 가속도)뿐만 아니라 (과거의 가속도로 인한) 현재 속도를 함께 고려하여 각 단계에서 공을 움직입니다. 실전에 적용할 때는 현재 그래디언트 값뿐만 아니라 이전에 업데이트한 파라미터에 기초하여 파라미터 w를 업데이트합니다. 다음은 단순한 구현 예입니다.
past_velocity = 0. momentum = 0.1 # 모멘텀 상수 while loss > 0.01: # 최적화 반복 루프 w, loss, gradient = get_current_parameters() velocity = momentum * past_velocity - learning_rate * gradient w = w + momentum * velocity - learning_rate * gradient past_velocity = velocity update_parameter(w)2.4.4 도함수 연결: 역전파 알고리즘 P96
앞의 알고리즘에서 함수가 미분 가능하기 때문에 변화율을 직접 계산할 수 있다고 잠시 가정했습니다. 실제로 신경망은 많은 텐서 연산으로 구성되어 있고 이 연산들의 변화율은 간단하며 이미 잘 알려져 있습니다. 3개의 텐서 연산 a, b, c와 가중치 행렬 W1, W2, W3로 구성된 네트워크 f를 예로 들어 보겠습니다.
f(W1, W2, W3) = a(W1, b(W2, c(W3)))
미적분에서 이렇게 연결된 함수는 연쇄 법칙(chain rule)이라 부르는 다음 항등식 f (g(x))' = f '(g(x)) * g'(x)를 사용하여 유도될 수 있습니다. 연쇄 법칙을 신경망의 그래디언트 계산에 적용하여 역전파(Backpropagation) 알고리즘(후진 모드 자동 미분(reverse-mode automatic differentiation)이라고도 부릅니다)이 탄생되었습니다. 역전파는 최종 손실 값에서부터 시작합니다. 손실 값에 각 파라미터가 기여한 정도를 계산하기 위해 연쇄 법칙을 적용하여 최상위 층에서 하위 층까지 거꾸로 진행됩니다.
요즘에는 그리고 향후 몇 년 동안은 텐서플로처럼 기호 미분(symbolic differentiation)이 가능한 최신 프레임워크를 사용하여 신경망을 구현할 것입니다. 이 말은 변화율이 알려진 연산들로 연결되어 있으면 (연쇄 법칙을 적용하여) 네트워크 파라미터와 그래디언트 값을 매핑하는 그래디언트 함수를 계산할 수 있다는 의미입니다. 이런 함수를 사용하면 역방향 패스는 그래디언트 함수를 호출하는 것으로 단순화될 수 있습니다. 기호 미분 덕택에 역전파 알고리즘을 직접 구현할 필요가 전혀 없고 정확한 역전파 공식을 유도하느라 시간과 노력을 소모하지 않아도 됩니다. 그래디언트 기반의 최적화가 어떻게 작동하는지 잘 이해하는 것으로 충분합니다.
연쇄법칙
역전파는 (덧셈,렐루,텐서 곱셈 같은 ) 간단한 연산의 도함수를 사용해서 이런 기초적인 연산을 조합한 복잡한 연산의 그레디언트를 쉽게 계산하는 방법입니다. 결정적으로 신경망은 서로 연결된 많은 텐서 연산으로 구성됩니다. 이런 연산은 간단하고 해당 도함수가 알려져 있습니다. 예를 들어 코드 2-2에서 정의한 모델은 (첫번째와 두 번째 dense 층의) 변수 W1,b1,w2,b2를 파라미터로 갖는 함수로 표현 할 수있습니다. 이 함수에 관련된 기초적인 연산은 dot,relu,softmax,+ 그리고 손실함수 loss도 모두 미분 가능합니다.
loss_value = loss(y_true, softmax(dot(relu(dot(inputs,W1)+b1),W2)+b2))
---- ------- ------- ------------------------
손실함수 진짜값, 예측값 활성화함수[ 선생님 설명 ]
- -> (x''2) -> 1 -> (2x) -> 2
- -> (x''2) -> 4 -> (2x) -> 8
- -> (x''2) -> 9 -> (2x) -> 18
#f(x) == x''2, #g(x) == 2x
#g(f(x))= 2(x''2)x=3
g(f(x))= '(g(f(3)) = g'()=2x, f'()=2 =g(f(x))= 2 3 2 = 12
f'(x)=2x ,g'(x)= 2 , 2*2x= 12
미적분의 연쇄법칙을 사용하면 이렇게 함수의 도함수를 구할 수 있습니다.
두 함수 f와 g가 있고, 두 함수를 연결한 fg가 있다고 가정해 보죠. 여기서 fg(x)==f(g(x))입니다.
연쇄 법칙을 사용하면 grad(y,x)==grad(x1,x)가 됩니다. 따라서 f와 g의 함수를 알고 있다면 fg의 도함수를 계산할 수 있습니다. 중간에 함수를 더 추가하면 사슬 처럼 보이기 떄문에 연쇄법칙(chain rule)이라고 부릅니다.
신경망의 그레디언트 값을 계산하는데 이 연쇄법칙을 적용하는 것이 역전파 알고리즘입니다.
구체적으로 어떻게 작동하는지 알아보겠습니다.
계산 그래프를 활용한 자동 미분
2.5 첫 번째 예제 다시 살표보기 P102
2.5.1 텐서플로를 사용하여 첫 번째 예제를 밑바닥부터 다시 구현하기 p104
- 단순한 Dense 클래스
- 단순한 Sequential 클래스
- 배치 제너레이터
2.5.2 훈련스텝 실행하기 p106
- GradientTape
- one_training_step
- update_weights
2.5.3 전체 훈련 루프 p108
- fit
2.5.4 모델 평가하기 p108
- argmax
https://colab.research.google.com/drive/1oCD4jjXsLPnfX19JchWUXznEXTm27CzV#scrollTo=Pq1HI0_5KwG- -> 내꺼 코랩
2.6 요약 P109
- 텐서는 현대 머신 러닝 시스템의 기초입니다. 텐서는 dtype,ndim,shape 속성을 제공합니다.
- 텐서 연산 (덧셈, 턴서 곱셈, 원소별 곱셈 등)을 통해 수치 텐서를 조작할 수 있다. 이런 연산은 기하학적변형을 적용하는 것으로 이해 할 수 있습니다. 일반적으로 딥러닝의 모든 것은 기하하적으로 해석할 수 있습니다.
- 딥러닝 모델은 가중치 텐서를 매개변수로 받는 간당한 텐서 연산을 연결하여 구성됩니다. 모델의 가중치는 모델이 학습한 '지식'을 저장하는 곳입니다.
- 학습은 훈련 데이터 샘플과 그에 상응하는 타깃이 주어졌을때 손실 함수를 최소화 하는 모델의 가중치 값을 찾는 것을 의미합니다.
- 데이터 샘플과 타깃의 배치를 랜덤하게 뽑고 이 배치에서 모델 파라미터에 대한 손실의 그레디언트를 계산함으로써 학습이 진행됩니다. 모델의 파라미터는 그레디언트의 반대방향으로 조금씩(학습률에 의해 정의된 크기만큼 )움직입니다. 이를 미니배치경사하강법이라고 부릅니다.
- 전체 학습 과정은 신경망에 있는 모든 텐서 연산이 미분 가능하기 때문에 가능합니다. 따라서 현재 파라미터와 배치 데이터를 그레디언트 값에 매핑해 주는 그레디언트 함수를 구성하기 위해 미분의 연쇄 법칙을 사용할 수 있습니다. 이를 역전파라고 합니다.
- 이어지는 장에서 자주 보게 될 두 가지 핵심 개념은 손실과 옵티마이저 입니다. 이 두가지는 모델의 데이터를 주입하기 전에 정의되어야 합니다.
- 손실은 훈련하는 동안 최소화해야 할 양이므로 해결하려는 문제의 성공을 측정하는 데 사용합니다.
- 옵티마이저는 손실에 대한 그레디언트가 파라미터를 업데이트하는 정확한 방식을 정의 합니다. 예를 들어 RMSProp 옵티마이저, 모멤텀을 사용한 SGD등 입니다.
https://m.blog.naver.com/mindo1103/90103504970 -> 편도함수
https://crush-on-study.tistory.com/57 -> 편도함수
https://tensorflow.blog/%ec%bc%80%eb%9d%bc%ec%8a%a4-%eb%94%a5%eb%9f%ac%eb%8b%9d/2-2-%ec%8b%a0%ea%b2%bd%eb%a7%9d%ec%9d%84-%ec%9c%84%ed%95%9c-%eb%8d%b0%ec%9d%b4%ed%84%b0-%ed%91%9c%ed%98%84/-> 정리
https://livebook.manning.com/book/deep-learning-with-python-second-edition/chapter-5/v-2/202-정리
