작동원리
활성화함수
비용함수
옵티마이저
경사하강법
오차역전파
학습률
오버피팅
- 딥런닝의 간단 구조
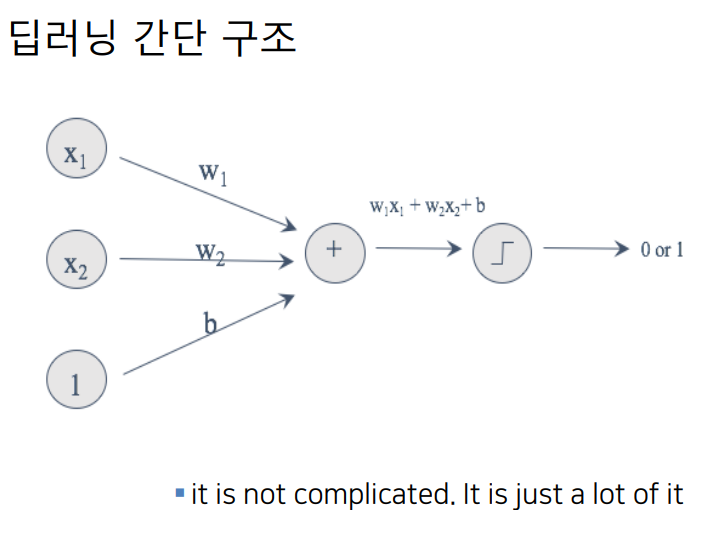
it is not complicated. it is just a lot of it
여러개의 가중치와 여러개의 편향들
가중치와 별개로 가중치와 무관한 x들 속성,
사람은 하나고 네게의 (피처)칼럼이다.
- 신경망 학습과정 -
- 신경망
가중치적당한 값으로 초기화- 데이터를 신경망에 입력해
출력값(결과)를 얻음- 출력값과 해당 데이터의 정답을 비교해서
오차계산- 위 단계에서 게산한 오차가 줄어들도록 신경망의
가중치를 조절최소의 오차가 나올떄 까지2-3단계 반복한다.
활성화함수
-
활성화 함수란? 입력된 데이터의 가중 합을 출력 신호로 변환하는 함수
-
활성화 함수의 종류는? Relu,sigmoid, Tanh
-
활성화 함수의 식과 그래프는?
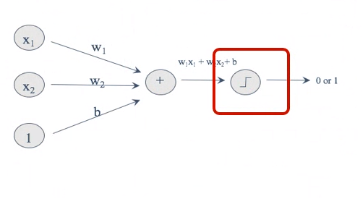
p 긍정 부정, 이진분류 -> sigmoid
p 0-45, 다중분류 -> softmax
softmax
-
소프트맥스란? 최종 출력층에 사용되며, 여러 개의 출력 노드의 합 중에 비중의 값으로 나타낸다.(확률처럼)
-
지수함수는 입력값 중 큰 값은 더 크게 작은 값은 더 작게 만들어 입력벡터가 더 잘 구분되게 함.
-
범주가 여러 개일 때 sigmoid 함수를 쓰면 출력값의 합이 1이 아니지만,
softmax 함수를 쓰면 정의에서 출력값의 합이 항상 1이 된다.
(물론 활성화 함수를 선택하는 것은 자유이며, 다른 함수를 써도 된다.)
수식을 알아야한다.
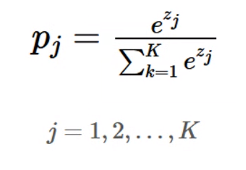
-
전체 중에서 비중을 나타낸다. 확률처럼 나타내도 된다.
-
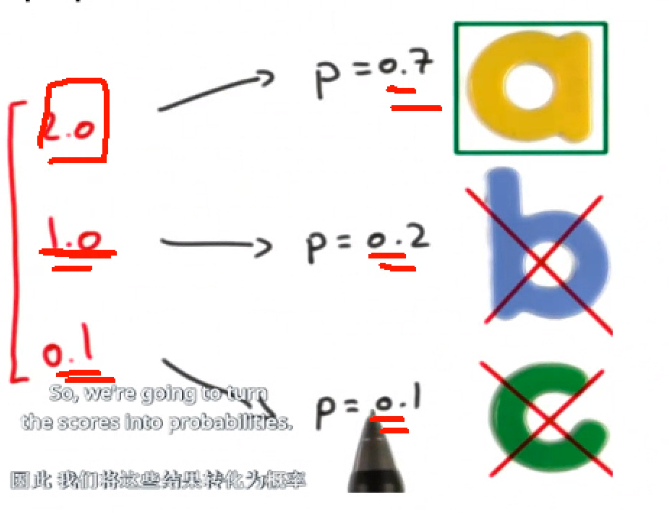
1,2,3,4 -> 1,100,1000,10000 한눈에 보기에도 차이난다.
-
쉽게 구별하기 위해서 멀쩡한 숫자를 바꾼다.
-
e:2.7 제곱,3제곱,4제곱
-

-
확률처럼 생각하자
-
손실함수 loss function, 비용함수 Cost Function
- 손실함수란? 지도학습(Supervised Learning) 시 알고리즘이 예측한 값과 실제 정답의 차이를 비교하기 위한 함수입니다.
-같은 이름이다.-
오차함수 (error function)
손실함수 (loss function))
비용함수 (Cost Function) : 모델을 구성하는 가중치(W)들의 합이다.
목적함수 (objective function) : 결국 학습의 목표는 오차를 최소로, 혹은 오차함수의 값이 최소가 되는 w를 찾는 것.
학습 : 비용함수를 최소로 하는 w를 찾는 것이 학습이다
-종류-
- MSE(Mean Squared Error) :
회귀, 각타겟값과 계산값과의 차이를 최소로 한다.- RMSE
- MAE(Mean Absolue Error)
- Cross Entropy :
분류, 두 데이터 집합 간의분포의 차이를 볼 때 사용 p154
𝐸(a, 𝑦) = 𝑦𝑙𝑜𝑔𝑎 + (1 − 𝑦)log(1 − a)- Binary Crossentropy
- mean_absolute_percentage_error
- mean_squared_logarithmic_error
- cosine_similarity
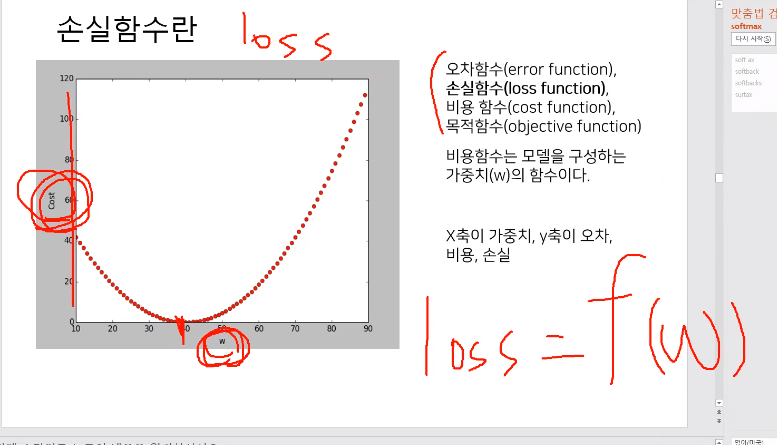
- 목표 : 손실이 가장 작아졌을 때 w값을 찾는거, 오차가 가장 없을때
옵티마이저
- 옵티마이저란? 가중치(w)를 업데이트(방향, 크기 수정) 시켜주는 알고리즘이다.
- 옵티마이저의 종류는?-
- RMRprop
- Adam
- Batch GD, Mini-Batch GD
- SGD(Stochastic GD)
stock
경사 하강법 Gradient Descent
- 경사하강법이란? 함수가 학습될 바를 정의한 비용함수의 값이 최소로 하기 위해 가중치를 업데이트 하기 위한 알고리즘
- 경사하강법의 알고리즘들?
- Adadelta
- NAG
- SGD
늘릴지 줄일지 알아보는거
오차 역전파 backpropagation
-
역전파란? 출력된 값과 원하는 값과의 차이를 가지고 그 전의 w 값들을 변경하는 알고리즘.
-
뒤에서부터 그 오차의 값이 전파된다.
-
실제 변경되는 값의 크기는 GD로 결정됨.
-
경사하강법+연쇄법칙
기울기 구하는거에요.미분하는거에요. 연쇄법칙
학습률
-
학습률이란? 가중치가 변경되는 정도
-
학습률이 크면 크게 수정하면 오차가 크다.
-
학습률이 적으면 조금씩 수정하니까 느리다.
수식: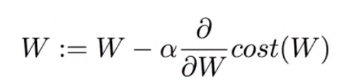
-
경사를 구해서 코스트를 줄이는 방향으로 간다.
오버피팅 overfitting
-
오버피팅이란 뭐예요?
-
모든 데이터를 다 설명하면 오히려 안좋다.
-
이미지인 경우 (회전,반전,축소,확대,밝기,명암,색상변경)
-
방지법 (3가지 정도 알기) 증강을 추천합니다.
-
DropOut
-
Batch Normalization
-
Regularization (L1, L2 penalty on weights)
-
Early stopping
-
Data Augmentation
-
핵심은 충분한 데이터 양
5장. 머신 러닝의 기본 요소
5-1.일반화: 머신 러닝의 목표
5-2.머신 러닝 모델 평가 p193
5-2.1 훈련,검증,테스트 세트 p193
5-2.2 상식 수준의 기준점 넘기 p197
5-2.3 모델 펼가에 대해 유념해야 할 점 p198
-
대표성 있는 데이터
:훈련 세트와 -
시간의 방향
-
데이터 중복
5-1.일반화: 머신 러닝의 목표
케라스 공홈 가이드 잘 나왔음.
-> https://keras.io/api/optimizers/
