[ TF-IDF, ppt정리 ]
TF - Term Frequency (단어 빈도수)
: 특정한 단어가 얼마나 자주 등장하는지 나타냄IDF - Inverse Document Frequency (역문서 빈도)
: log(전체 문서의 수 : D / term이 포함된 문서의 수 : T)TF-IDF - TF * IDF : 목적이 다른 문서에 자주 언급되지 않고 해당 문서에서는 자주 언급되는 단어 (term, token)에 대해 점수를 높게 부여하는 것.
- 한페이지에 여러번 언급 된것 보다 여러 페이지에서 한번씩 나오는게 하는게 더 중요하다.
- 적게 언급 되더라도 중요도가 있을 수 있다.
- 분모의 값이 클수록 로그의 수는 작아진다.
- 분모가 작을수록 더 좋은거다. -> log D/T
- -log1 = 0

[ 비지도학습 기반 감성 분석 소개 p524]
lexicon : 감성사전
semantic (시멘트 분석) : 맥락상 의미상
비지도 감성 분석은 Lexicon을 기반으로 한다. Lexicon은 NLTK 패키지의 서브 모듈로 감성을 분석하기 위해 지원하는 감성 어휘 사전을 의미하고, 감성 사전은 긍정 감성 또는 부정 감성의 정도를 의미하는 수치를 가지고 있는데 이를 감성 지수라고 한다.
이 감성 지수는 단어의 위치나 주변 단어, 문맥, POS(Part of Speech) 등을 참고해 결정된다.
텍스트 분석에는 문맥상 의미를 나타내는 semantic이라는 용어가 자주 등장하는데 동일한 단어나 문장이라도 다른 환경과 문맥에서 다르게 표현되거나 이해될 수 있기 때문이다. 언어학에서 이러한 semantic을 표현하기 위해서 여러 가지 규칙을 정해왔으며 NLP 패키지는 semantic을 프로그램적으로 인터페이스할 수 있는 다양한 방법을 제공한다.
특히 NLP 패키지의 WordNet 모듈을 통해 semantic 분석을 진행할 수 있고 이 모듈은 다양한 상황에서 같은 어휘라도 다르게 사용되는 어휘의 semantic 정보를 제공하며 이를 위해 각각의 품사로 구성된 개별 단어를 Synset(Sets of cognitive synonyms)이라는 개념을 이용해 표현한다.
Synset은 단순한 하나의 단어가 아니라 그 단어가 가지는 문맥, semantic 정보를 제공하는 WordNet의 핵심 개념이다. 하지만 NLTK 감성 사전은 예측 성능이 그리 좋지 않다는 단점이 있다.
감성 분석
- 문서의 주관적인 감성/의견/감정/기분 등을 파악하기 위한 방법
- 소셜미디어, 여론조사, 온라인 리뷰 등 다양한 분야에서 활용됨
- 분석 방법
- 지도 학습 기반의 분석: 텍스트 기반 분류와 거의 동일
- 감성 어휘 사전을 이용한 분석: 감성 분석을 위한 용어와 문맥에 대한 정보를 가지고 있음. 이를 이용해 긍부정 감성 여부를 판단
대표적인 감성사전 분석
-
SentiWordNet : NLTK 패키지의 WordNet과 유사하게 감성 단어 전용의
WordNet을 구현한 것. WordNet의 Synset 개념을 감성 분석에 적용한 것으로Synset별로 3가지 감성 점수를 할당한다(긍정 감성 지수, 부정 감성 지수, 객관성 지수).
여기서 객관성 지수는 긍정/부정 감성 지수와 완전히 반대되는 개념으로 단어가 감성과 관계없이 얼마나 객관적인지를 수치로 나타낸 것이다.
문장별로 단어들의 긍정 감성 지수와 부정 감성 지수를 합산하여 최종 감성 지수를 계산하고 이에 기반해 감성이 긍정인지 부정인지를 결정한다. -
VADER : 주로
소셜 미디어의 텍스트에 대한 감성 분석을 제공하기 위한 패키지이다. 뛰어난 감성 분석 결과를 제공하며,비교적 빠른 수행 시간을 보장해 대용량 텍스트 데이터에 잘 사용되는 패키지이다. -
Pattern :
예측 성능 측면에서 가장 주목받는 패키지이다. (책에는 아직 파이썬 3.X 에서 호환되지 않는다고 나와 있는데 3.6 버전부터는 호환된다고 한다)
[SentiWordNet을 이용한 감성 분석 p525 ]
import nltk
nltk.download('all')from nltk.corpus import wordnet as wn
term = 'present'
# 'present'라는 단어로 wordnet의 synsets 생성.
synsets = wn.synsets(term)
print('synsets() 반환 type :', type(synsets))
print('synsets() 반환 값 갯수:', len(synsets))
print('synsets() 반환 값 :', synsets)
for synset in synsets :
print('##### Synset name : ', synset.name(),'#####')
print('POS :',synset.lexname())
print('Definition:',synset.definition())
print('Lemmas:',synset.lemma_names())-> 어휘간의 유사도
- path_similarity
# synset 객체를 단어별로 생성합니다.
tree = wn.synset('tree.n.01')
lion = wn.synset('lion.n.01')
tiger = wn.synset('tiger.n.02')
cat = wn.synset('cat.n.01')
dog = wn.synset('dog.n.01')
entities = [tree , lion , tiger , cat , dog]
similarities = []
entity_names = [ entity.name().split('.')[0] for entity in entities]
# 단어별 synset 들을 iteration 하면서 다른 단어들의 synset과 유사도를 측정합니다.
for entity in entities:
similarity = [ round(entity.path_similarity(compared_entity), 2) for compared_entity in entities ]
similarities.append(similarity)
# 개별 단어별 synset과 다른 단어의 synset과의 유사도를 DataFrame형태로 저장합니다.
similarity_df = pd.DataFrame(similarities , columns=entity_names,index=entity_names)
similarity_df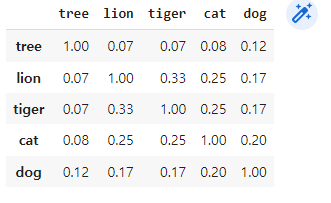
WordNet Synset과 SentiWordNet SentiSynSet 클래스의 이해
SentiWordNet을 이용한 영화 감상평 감성 분석 p529
- 문서(Document)를
문장(Sentence) 단위로 분해 - 다시 문장을 단어(Word) 단위로 토큰화하고 품사 태깅(POS)
- 품사 태킹된 단어 기반으로 synset 객체와 senti_synset 객체를 생성
- Senti_synset에서 긍정 감성/부정 감성 지수를 구하고 이를 모두 합산해 특정 임계치 값 이상일 때 긍정 감성으로, 그렇지 않을 때는 부정 감성으로 결정
SentiWordNet을 이용하기 위해 WordNet을 이용해 문서를 다시 단어로 토큰화한 뒤 어근 추출(Lemmatization)과 품사 태깅(POS Tagging)을 적용해야 한다.
VADER를 이용한 감성 분석 p532
- VADER는
소셜 미디어의 감성 분석용도로 만들어진 룰 기반의 Lexicon이다. - SentimentIntensityAnalyzer 클래스 이용
- 문서별로 polarity_scores 메서드를 호출해 감성 점수를 구한 뒤, 해당 문서의 감성 점수가
특정 임계값이상이면 긍정, 아니면 부정으로 판단 - neg: 부정, neu:중립, pos:긍정, compound: neg,neu,pos를 적절히 조합해 -1 ~ 1 사이의 감성 지수를 표현한 값
- VADER는 NLTK 패키지의 서브 모듈로 제공될 수도 있고 단독 패키지로 제공될 수도 있다.
여기서는 이전에 nltk.download('all')을 통해 완료하였다.
import pandas as pd
review_df = pd.read_csv('/content/drive/MyDrive/book/labeledTrainData.tsv', header=0, sep="\t", quoting=3)
review_df.head(3) 
import re
# <br> html 태그는 replace 함수로 공백으로 변환
review_df['review'] = review_df['review'].str.replace('<br />',' ')
# 파이썬의 정규 표현식 모듈인 re를 이용하여 영어 문자열이 아닌 문자는 모두 공백으로 변환
review_df['review'] = review_df['review'].apply( lambda x : re.sub("[^a-zA-Z]", " ", x) )
from sklearn.model_selection import train_test_split
class_df = review_df['sentiment']
feature_df = review_df.drop(['id','sentiment'], axis=1, inplace=False)
X_train, X_test, y_train, y_test= train_test_split(feature_df, class_df, test_size=0.3, random_state=156)
X_train.shape, X_test.shape 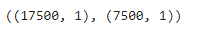
from nltk.sentiment.vader import SentimentIntensityAnalyzer
senti_analyzer = SentimentIntensityAnalyzer()
senti_scores = senti_analyzer.polarity_scores(review_df['review'][0])
print(senti_scores)
- neg : 부정 감성 지수
- neu : 중립적인 감성 지수
- pos : 긍정 감성 지수
- compound : neg, neu, pos score를 적절히 조합한 -1 ~ 1 사이의 감성 지수 ( 보통 0.1 이상이면 긍정, 이하면 부정으로 판단 )
from sklearn.metrics import confusion_matrix, accuracy_score , precision_score, recall_score
# 입력 파라미터로 영화 감상평 테스트와 긍정/부정을 결정하는 임곗값을 가지고 polarity_scores() 메소드를 호출해 감성 결과를 반환하는 함수
def vader_polarity(review,threshold=0.1):
analyzer = SentimentIntensityAnalyzer()
scores = analyzer.polarity_scores(review)
# compound 값에 기반하여 threshold 입력값보다 크면 1, 그렇지 않으면 0을 반환
agg_score = scores['compound']
final_sentiment = 1 if agg_score >= threshold else 0
return final_sentiment
# apply lambda 식을 이용하여 레코드별로 vader_polarity( )를 수행하고 결과를 'vader_preds'에 저장
review_df['vader_preds'] = review_df['review'].apply( lambda x : vader_polarity(x, 0.1) )
y_target = review_df['sentiment'].values
vader_preds = review_df['vader_preds'].values
print(confusion_matrix( y_target, vader_preds))
print("정확도:", np.round(accuracy_score(y_target , vader_preds),4))
print("정밀도:", np.round(precision_score(y_target , vader_preds),4))
print("재현율:", np.round(recall_score(y_target, vader_preds),4))
- 정확도가 SentiWordNet보다 향상되었다.
- 감성 사전을 이용한 감성 분석 예측 성능 ( 비지도 학습 )은 지도학습 분류 기반의 예측 성능에 비해 아직 낮은 수준이지만 결정 클래스 값이 없는 상황을 고려한다면 예측 성능에 일정 수준 만족할 수 있다
토픽 모델링(Topic Modeling) - 20 뉴스그룹 p534
토픽 모델링(Topic Modeling)이란 문서 집합에 숨어 있는 주제를 찾아내는 것이다.
많은 양의 문서가 있을 때 사람이 이 문서를 다 읽고 핵심 주제를 찾는 것은 매우 많은 시간이 소모된다.
이 경우에 머신러닝 기반의 토픽 모델링을 적용해 숨어 있는 중요 주제를 효과적으로 찾아낼 수 있다.
사람이 수행하는 토픽 모델링은 더 함축적인 의미로 문장을 요약하는 것에 반해, 머신러닝 기반의 토픽 모델은 숨겨진 주제를 효과적으로 표현할 수 있는 중심 단어를 함축적으로 추출한다.
머신러닝 기반의 토픽 모델링에 자주 사용되는 기법은 LSA(Latent Semantic Analysis)와 LDA(Latent Dirichlet Allocation)이다.
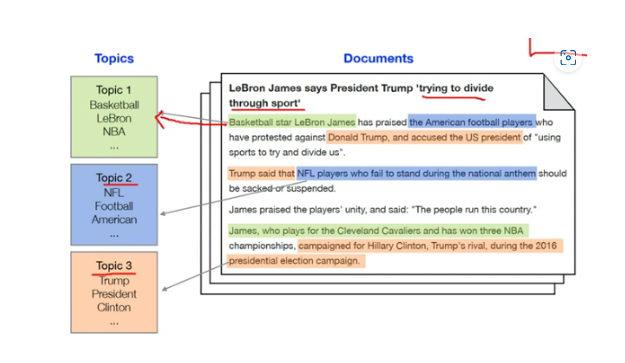
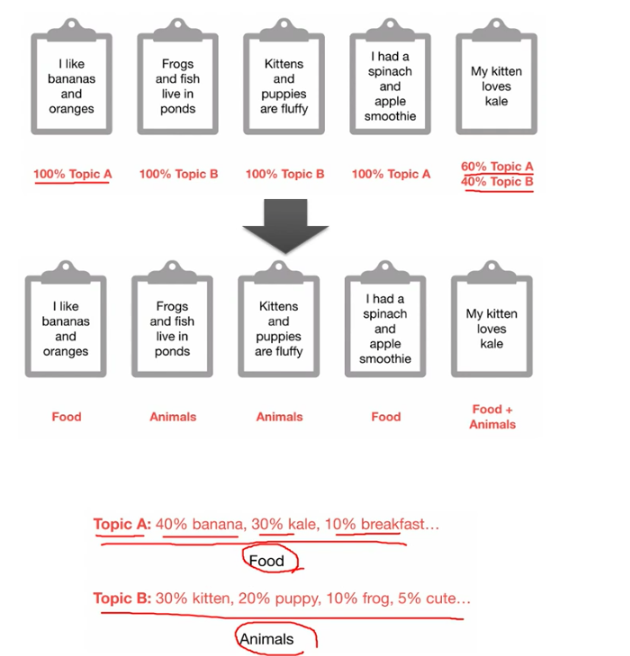
알고리즘 유형, 종류
- 종류
- LSA (Latent Semantic Analysis), pLSA
- LDA (Latent Dirichlet Allocation)
- NMF (Non Negative Factorization)
- 유형
- 행렬 분해 기반 토픽 모델링: LSA, NMF
- 확률 기반의 토픽 모델링: pLSA, LDA
- 가정
- 개별 문서는 혼합된 여러 개의 주제로 구성되어 있다
- 개별 주제는 여러 개의 단어로 구성되어 있다.


단점
- 추출된 토픽은 다시 사람의 주관적인 해석이 필요함
- 초기화 파라미터(토픽개수, α, β) 및 Document-Term 행렬의 단어 필터링 최적화가 어려움
문서 군집화 소개와 실습(Opinoin Review 데이터 세트) p538
문서 군집화 개념
문서 군집화는 비슷한 텍스트 구성의 문서를 군집화 하는 것이다.
문서 군집화는 동일한 군집에 속하는 문서를 같은 카테고리 소속으로 분류할 수 있으므로 앞에서 소개한 텍스트 분류 기반의 문서 분류와 유사하다.
하지만 텍스트 분류 기반의 문서 분류는 사전에 결정 카테고리 값을 가진 학습 데이터 세트가 필요한 데 반해, 문서 군집화는 학습 데이터 세트가 필요 없는 비지도학습 기반으로 동작한다.
군집별 핵심 단어 추출하기 p546
각 군집에 속한 문서는 핵심 단어를 주축으로 군집화되어 있을 것이다.
KMeans 객체는 각 군집을 구성하는 단어 피처가 군집의 중심을 기준으로 얼마나 가깝게 위치해 있는지 clusters_centers_라는 속성으로 제공하는데, 이는 배열 값으로 되어 있고 행은 개별 군집을, 열은 개별 피처를 의미한다.
각 배열 내의 값은 개별 군집 내의 상대 위치를 숫자 값으로 표현한 일종의 좌표 값이다.
예를 들어 cluster_centers[0,1]는 0번 군집에서 두 번째 피처의 위치 값을 의미한다.
문서 유사도
문서 유사도 측정 방법 - 코사인 유사도
문서와 문서 간의 유사도 비교는 일반적으로 코사인 유사도(Cosine Similarity)를 사용한다.
코사인 유사도는 벡터와 벡터 간의 유사도를 비교할 때 벡터의 크기보다는 벡터의 상호 방향성이 얼마나 유사한지에 기반한다.
즉, 코사인 유사도는 두 벡터 사이의 사잇각을 구해서 얼마나 유사한지 수치로 적용한 것이다.
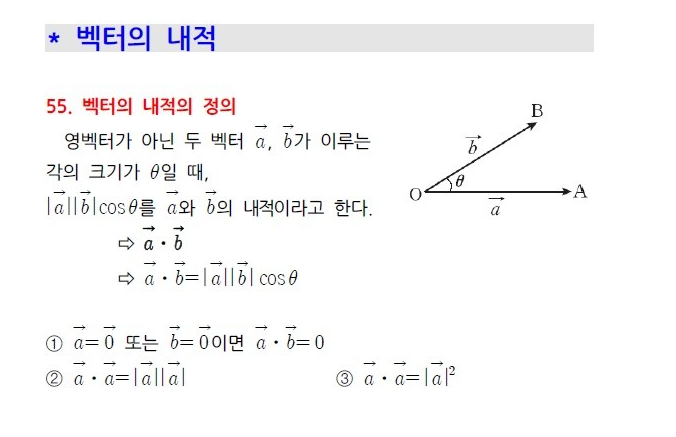
길이: 1 ,cos0 = 루트2/2
문서 유사도 측정
- Cosine Similarity
- Jaccard Similarity
- Manhattan Distance
- Euclidean Distance
두 벡터 사잇각
두 벡터의 사잇각에 따라서 상호 관계는 유사하거나, 관련이 없거나, 아예 반대 관계가 될 수 있다.
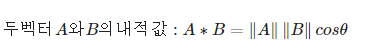
따라서 유사도 cosθ는 두 벡터의 내적을 총 벡터 크기의 합으로 나눈 것이다.( 내적 결과를 총 벡터 크기로 L2 정규화한 것이다.)
코사인 유사도가 문서의 유사도 비교에 가장 많이 사용되는 이유
- 문서를 피처 벡터화 변환하면 차원이 매우 많은 희소 행렬이 되기 쉬운데 이러한 희소 행렬 기반에서 문서와 문서 벡터간의 크기에 기반한 유사도 지표는
정확도가 떨어지기 쉽다. - 문서가 매우 긴 경우 단어의 빈도수도 더 많을 것이기 때문에 이러한 빈도수에만 기반해서는
공정한 비교를 할 수 없다.
한글 텍스트 처리 NLP - 네이버 영화 평점 감성 분석 p58
한글 NLP 처리의 어려움
한글 NLP 처리는 대표적인 파이썬 기반의 한글 형태소 패키지인 KoNLPy를 사용한다. 일반적으로 한글 언어 처리는 영어 등의 라틴어 처리보다 어렵다.
그 이유는 띄어쓰기와 다양한 조사 때문인데 한글은 띄어쓰기를 잘못하면 의미가 왜곡되어 전달될 수 있고, 조사는 주어나 목적어를 위해 추가되는데 워낙 경우의 수가 많기 때문에 어근 추출(stemming/Lemmatization) 등의 전처리 시 제거하기가 까다롭다.
한글 NLP를 어렵게 만드는 요인들
- 띄워 쓰기
- 다양한 조사
- 주어/목적어가 생략되어도 의미 전달 가능
- 의성어/의태어, 높임말 등
한글 형태소 분석
- 형태소의 사전적인 의미는 단어로서 의미를 가지는 최소 단위로 정의
- 형태소 분석(Morphological analysis)이란 말뭉치를 형태소 어근 단위로 쪼개고 각 형태소에 품사 태깅을 부착하는 작업을 일반적으로 지칭
- 예시
머릿결 --> 머리 + 결
너를 --> 너 + 를(을)
KoNLPy
- 기존의 C/C++, Java로 만들어진 한글 형태소 엔진을 파이썬 래퍼 기반으로 재작성한 패키지
- 종류
- 꼬꼬마
- 한나눔
- Komoran
- Mecab
KoNLPy 소개
KoNLPy는 파이썬의 대표적인 한글 형태소 패키지이다. 형태소의 사전적인 의미는 '단어로서 의미를 가지는 최소 단위'이고, 형태소 분석(Morphological analysis)이란 말뭉치를 이러한 형태소 어근 단위로 쪼개고 각 형태소에 품사 태깅(POS tagging)을 부착하는 작업을 일반적으로 지칭한다.
KoNLPy는 기존의 C/C++, Java로 잘 만들어진 한글 형태소 엔진을 파이썬 래퍼 기반으로 재작성한 패키지이다. 꼬꼬마(Kkma), 한나눔(Hannanum), Komoran, 은전한닢 프로젝트(Mecab), Twitter와 같이 5개의 형태소 분석 모듈을 KoNLPy에서 모두 사용할 수 있다. ( Mecab은 리눅스 환경의 KoNLPy에서만 사용이 가능하다 )
데이터 로딩
(1)
pip install konlpy(2)
# konlpy 다운로드
import konlpy(3)
import pandas as pd
train_df= pd.read_csv("https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt",sep='\t')
train_df.head(3)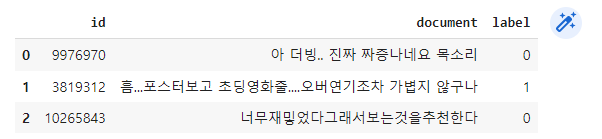
(4)
train_df['label'].value_counts() # label 값 비교하겠다. 1이 긍정, 0이 부정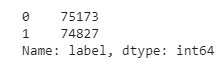
- 0,1이 균등하게 분포되어 있다.
(5)
import re # 정규 표현식 모듈
train_df = train_df.fillna(' ')
# 정규 표현식을 이용하여 숫자를 공백으로 변경(정규 표현식으로 \d 는 숫자를 의미함.)
train_df['document'] = train_df['document'].apply( lambda x : re.sub(r"\d+", " ", x) )
# 테스트 데이터 셋을 로딩하고 동일하게 Null 및 숫자를 공백으로 변환
test_df = pd.read_csv('https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt', sep='\t')
test_df = test_df.fillna(' ')
test_df['document'] = test_df['document'].apply( lambda x : re.sub(r"\d+", " ", x) )
# id 칼럼 삭제
train_df.drop('id', axis=1, inplace=True)
test_df.drop('id', axis=1, inplace=True)(6)
# TF-IDF 방식으로 단어를 벡터화, 각 문장을 한글 형태소 분석을 통해 형태소 단어로 토큰화
# KoNLPy v0.4.5. 이후 Twitter가 Okt로 changed
from konlpy.tag import Okt
Okt = Okt()
def tw_tokenizer(text):
# 입력 인자로 들어온 text 를 형태소 단어로 토큰화 하여 list 객체 반환
tokens_ko = Okt.morphs(text)
return tokens_ko(7)
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
# Okt 객체의 morphs( ) 객체를 이용한 tokenizer를 사용. ngram_range는 (1,2)
tfidf_vect = TfidfVectorizer(tokenizer=tw_tokenizer, ngram_range=(1,2), min_df=3, max_df=0.9)
tfidf_vect.fit(train_df['document'])
tfidf_matrix_train = tfidf_vect.transform(train_df['document'])(8)
# Logistic Regression 을 이용하여 감성 분석 Classification 수행.
lg_clf = LogisticRegression(random_state=0, max_iter = 500)
# Parameter C 최적화를 위해 GridSearchCV 를 이용.
params = { 'C': [4.5, 5.5] }
grid_cv = GridSearchCV(lg_clf , param_grid=params , cv=3 ,scoring='accuracy', verbose=1 )
grid_cv.fit(tfidf_matrix_train , train_df['label'] )
print(grid_cv.best_params_ , round(grid_cv.best_score_,4))
(9)
from sklearn.metrics import accuracy_score
# 학습 데이터를 적용한 TfidfVectorizer를 이용하여 테스트 데이터를 TF-IDF 값으로 Feature 변환함.
tfidf_matrix_test = tfidf_vect.transform(test_df['document'])
# classifier 는 GridSearchCV에서 최적 파라미터로 학습된 classifier를 그대로 이용
best_estimator = grid_cv.best_estimator_
preds = best_estimator.predict(tfidf_matrix_test)
print('Logistic Regression 정확도: ',accuracy_score(test_df['label'],preds))
추천 시스템의 중요성 (Recommender/Recommendation System)
- 아마존과 같은 전자상거래 업체부터 넷플릭스, 유튜브 등 콘텐츠 포털까지 활용하고 있음.
- 사용자의 취향을 이해하고 맞춤 상품과 콘텐츠를 제공해 조금이라도 오래동안 자기 사이트에 고객을 머무르게 하기 위해 전력을 기울이고 있음.
- 정교한 추천시스템은 사용자에게 높은 신뢰도를 주고 사용자가 의존하게 만듦.
추천 시스템 방식
- 콘텐츠 기반 필터링 (Content Based Filtering:CB)
- 협업 필터링 (Collaborative Filtering:CF)
- 하이브리드 (콘텐츠 기반 + 협업 필터링)
컨텐츠 기반 필터링
사용자가 특정한 아이템을 매우 선호하는 경우, 그 아이템과 비슷한 콘텐츠를 가진 다른 아이템을 추천하는 방식
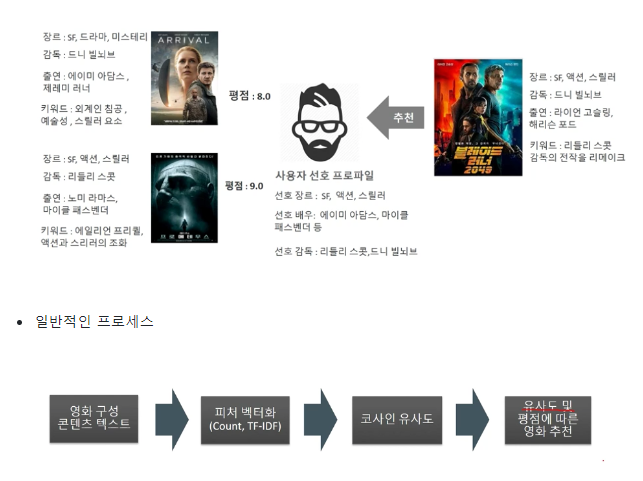
컨텐츠 기반 필터링 구현 프로세스
- 컨텐츠에 대한 여러 텍스트 정보들을 피처 벡터화
- 코사인 유사도로 컨텐츠별 유사도 계산
- 컨텐츠 별로 가중 평점을 계산
- 유사도가 높은 컨텐츠 중에 평점이 좋은 컨텐츠 순으로 추천
1. 협업 필터링(Collaborative Filtering : CF)
유형
- 최근접 이웃 기반 (Nearest Neighbor)
- 사용자 기반 (User-user CF) , UBCF (User Based CF) : 패턴이 비슷한 사용자를 기반으로 상품(Item) 추천
- 아이템 기반 (Item-item CF) , IBCF (Item Based CF) : 상품(Item)을 기반으로 연관성이 있는 상품(Item) 추천
- 잠재 요인 기반 (Latent Factor)
- 행렬 분해 기반 (Matrix Factorization)
추천 알고리즘
① 협업 필터링 (Collaborative Filtering : CF)
- 구매/소비 패턴이 비슷한 사용자를 한 집단으로 보고 그 집단에 속한 소비자들의 취향을 추천하는 방식
- UBCF (User Based CF) : 패턴이 비슷한 사용자를 기반으로 상품(Item) 추천
- IBCF (Item Based CF) : 상품(Item)을 기반으로 연관성이 있는 상품(Item) 추천
② 내용기반 필터링 (Content-Based Filtering : CB)
- 뉴스, 책 등 텍스트의 내용을 분석해서 추천하는 방식
- 소비자가 소비하는 제품 중 텍스트 정보가 많은 제품을 대상으로 함
- 텍스트 중에서 형태소(명사, 동사 등)를 분석하여 핵심 키워드를 분석하는 기술이 핵심
③ 지식기반 필터링 (Knowledge-Based Filtering : KB)
- 특정 분야에 대한 전문가의 도움을 받아서 그 분야에 대한 전체적인 지식구조를 만들고 이를 활용하는 방식
특징
- User behavior에만 기반하여 추천 알고리즘들을 전반적으로 지칭함
- 상품, 영화 등 사용자가 아직 평가하지 않은 아이템에 대한 평가를 예측하는 것이 주요 역할
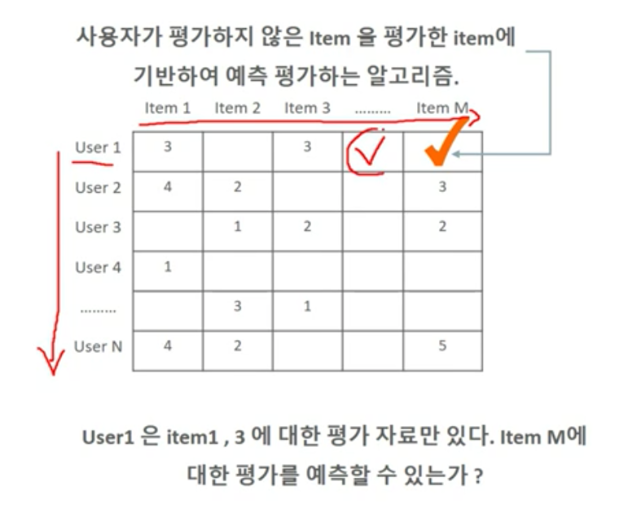
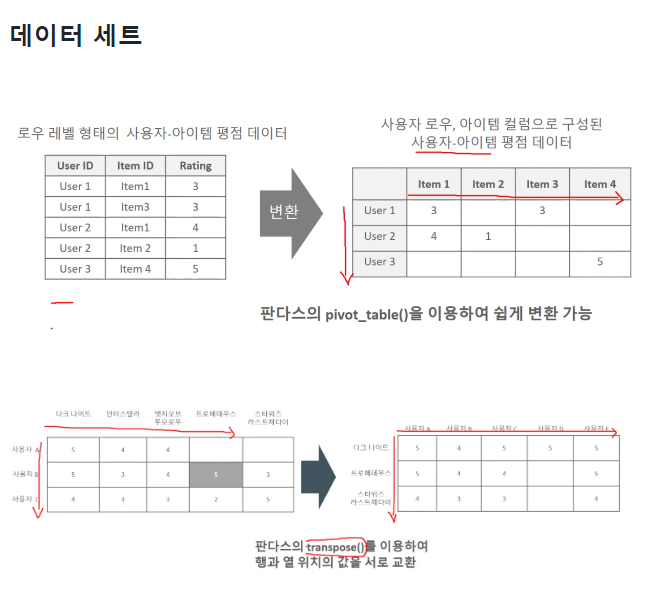
협업 필터링의 유사도(Similarity) 계산 방법
- 상관계수 (Correlation coefficient) 유사도 : 피어슨 상관계수 이용
- 코사인 (Cosine) 유사도 : 두 벡터 사이의 각도
- Jaccard 유사도 : 이진화 자료(binary data) 대상 유사도 계산
- 유클리드 거리 계산법 : 거리 기반 유사도 계산
2. 사용자 기반, 아이템 기반 협업 필터링
사용자 기반
- 특정 사용자와 비슷한 고객들을 기반으로 선호하는 다른 상품을 추천
- 특정 사용자와 비슷한 상품을 구매해온 고객들은 비슷한 고객으로 간주
- 당신과 비슷한 고객들이 다음 상품도 구매했습니다.
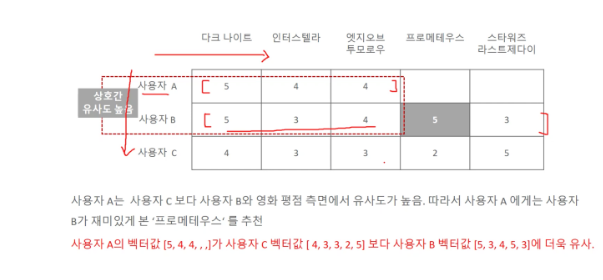
아이템 기반
- 특정 상품과 유사한 좋은 평가를 받은 다른 비슷한 상품을 추천
- 사용자들로부터 특정 상품과 비슷한 평가를 받은 상품들은 비슷한 상품으로 간주
- 이 상품을 선택한 다른 고객들은 다음 상품도 구매했습니다.
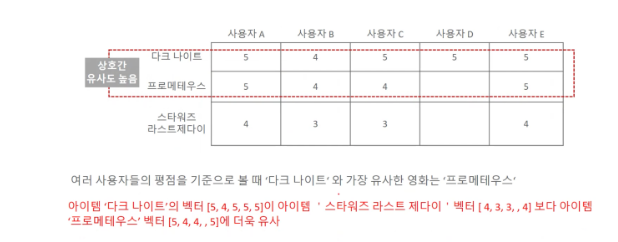
-
일반적으로
아이템기반 방식이 더 선호됨- 사람간의 특성은 상대적으로 다양한 요소들에 기반하고
- 단순히 동일한 상품을 구입했다고 유사한 사람이라고 판단하기 어렵기 때문
SVD
- 특이값 분해 (SVD : Singular Value Decomposition)
- 차원 축소 (dimension reduction) 기법 사용
- 모든 m x n 행렬에 대해 적용 가능
- m x n 행렬 A를 다음과 같이 분해
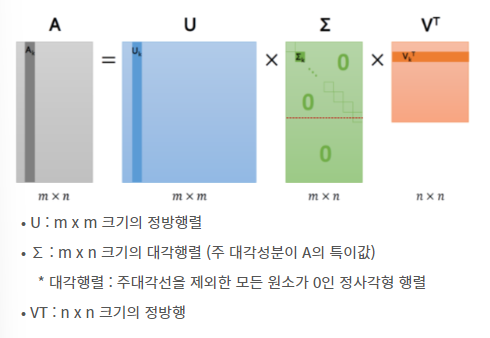
• U : m x m 크기의 정방행렬
• ∑ : m x n 크기의 대각행렬 (주 대각성분이 A의 특이값)
* 대각행렬 : 주대각선을 제외한 모든 원소가 0인 정사각형 행렬
• VT : n x n 크기의 정방행SVD 기반 추천시스템
- 사용자의 특징과 아이템의 특징 그리고 이 두 가지를 대표하는 대각행렬 추출
- 대각 행렬의 특이값으로 차원을 축소 (데이터의 양 줄이기)
- 아직 평가하지 않은 데이터에 대해서 평균값을 이용해 결측치를 채운 뒤 SVD를 이용해 점수 예측
- 추천 시스템에서는 이 예측된 점수가 높은 아이템을 추천
출처:
https://rahites.tistory.com/m/40 -> 정리
https://github.com/e9t/nsmc -> 깃허브
https://velog.io/@gjtang/%ED%8C%8C%EC%9D%B4%EC%8D%AC-%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-%EC%99%84%EB%B2%BD-%EA%B0%80%EC%9D%B4%EB%93%9C-Section9->
