

-> p432 k-평균의 단점 1.

-> 많아짐

->make_blobs(),make_circles() p437 p471

-> n_target ,p433
[ 텍스트 분석 p488 ]
텍스트 분석 개요
- NLP: 인간의 언어를 이해하고 해석하는데 중점 ,(텍스트 마이닝)
- 텍스트 분석:
비전형 텍스트에서 의미 있는 정보를 추출하는 것. 머신러닝, 언어 이해, 통계 등을 활용해 모델을 수립하고 정보를 추출해 BI(비즈니스 인텔리전스)나 예측 분석 등의 분석 작업을 주로 수행
주요 영역
- 텍스트 분류: 문서가 특정 분류 또는 카테고리에 속하는 것을 예측하는 기법을 통칭
- 감성 분석: 텍스트에 나타나는 감정/판단/믿음/의견/기분 등의 주관적인 요소를 분석하는 기법을 총칭
- 텍스트 요약: 텍스트 내에서 중요한 주제나 중심 사상을 추출하는 기법
- 텍스트 군집화와 유사도 측정: 비슷한 유형의 문서에 대해 군집화를 수행하는 기법
파이선 기반 NLP, 텍스트 분석 패키지 p488
- NLTK: 대표적인 NLP 패키지, 실제 대량의 데이터 기반에서는 수행 속도 문제로 활용되지 못하고 있음
- Gensim: 토픽모델링 분야에서 두각을 나타냄. Word2Vec 구현 등의 다양한 신기능 제공
- SpaCy: 뛰어난 수행 성능으로 가장 주목 받음
텍스트 분석 이해 p489
-
텍스트 분석은
비정형 데이터인 텍스트를 분석하는 것이다. -
지금까지 머신러닝 모델은 주어진 정형 데이터 기반에서 모델을 수립하고 예측을 수행하였는데, 텍스트를 머신러닝에 적용하기 위해서는 머신러닝 알고리즘이 숫자형의 피처 기반 데이터만 입력받을 수 있기 때문에 word 기반의 다수의 피처로 추출하고 이 피처에 단어 빈도수와 같은 숫자 값을 부여한 벡터 값으로 표현하는 텍스트 변환 방법인 (피처 벡터화), ( 피처 추출 )를 거쳐야 한다.
-
대표적인 방법으로 BOW ( Bag of Words )와 Word2Vec방법이 있다.
텍스트 분석 수행 프로세스 p490
- 텍스트 사전 준비작업 ( 텍스트 전처리 ) : 텍스트를 피처로 만들기 전에 미리 대/소문자 변경, 특수문자 삭제 등의 클렌징 작업, 단어 등의 토큰화 작업, 의미 없는 단어 ( Stop Word ) 제거 작업, 어근 추출 ( Stemming / Lemmatization ) 등의 텍스트 정규화 작업을 수행하는 것을 말한다.
- 피처 벡터화 / 추출 : 사전 준비 작업으로 가공된 텍스트에서 피처를 추출하고 여기에 벡터 값을 할당한다. 대표적인 방법으로는 BOW 와 Word2Vec이 있으며
BOW는 대표적으로 Count 기반과 TF-IDF 기반 벡터화가 있다. - ML 모델 수립 및 학습/예측/평가 : 피처 벡터화된 데이터 세트에 ML 모델을 적용해 학습/예측 및 평가를 수행한다.
파이썬 기반의 NLP,텍스트 분석 패키지 p490
- NLTK ( Natural Language Toolkit for Python ) : 파이썬의 가장 대표적인 NLP 패키지로 방대한 데이터 세트와 서브 모듈을 가지고 있으며 NLP의 거의 모든 영역을 커버하고 있다. 하지만 수행 속도 면에서는 아쉬운 부분이 있어 실제 대량의 데이터 기반에서는 제대로 활용되지 못하고 있다.
- Gensim : 토픽 모델링 분야에서 가장 두각을 나타내는 패키지로 오래전부터 토픽 모델링을 쉽게 구현할 수 있는 기증을 제공해 왔으며 Word2Vec 구현 등의 다양한 신기능도 제공한다.
- SpaCy : 뛰어난 수행 성능으로 최근 가장 주목을 받는 NLP 패키지이다.
[ 텍스트 전처리 p491 ]
텍스트 정규화
- (1)
클렌징: 불필요한 문자, 기호 등을 사전에 제거 (ex. html, xml tag) - (2)
토큰화: 문장/단어 토큰화, n-gram, 쉼표기준으로 조각조각 내줌. - (3) 필터링/불용어(stopwords) 제거/철자 수정: 불필요한 단어나 의미 없는 단어 제거
- (4) Stemming/Lemmatization: 문법적 or 의미적으로 변화하는 단어의 원형을 찾는 것
Stemming: 원형 단어로 변환 시, 일반적인 방법 또는 더 단순화된 방법을 적용해서 원래 단어에서 일부 철자가 훼손된 어근 단어를 추출하는 경향이 있음- python library: nltk.stem.LancasterStemmer
Lemmatization: 품사와 같은 문법적인 요소와 더 의미적인 부분을 감안해 정확한 철자로 된 어근 단어를 찾아줌- 변환 시간이 Stemming보다 오래 걸림
- python library: nltk.stem.WordNetLemmatizer
copus : 말뭉치,코퍼스stem : 어간stemming : 어간추출:plays -> playLemmatization : 표제어 추출:is -> be 품사.
(1) 클렌징 p492
텍스트에서 분석에 방해가 되는 불필요한 문자, 기호 등을 사전에 제거하는 작업 ( ex. HTML, XML 태그나 특정 기호 등을 사전에 제거 )
(2) 택스트 토큰화
문장/단어 토큰화, n-gram, 쉼표기준으로 조각조각 내줌.
(2-1) 문장 토큰화 p493
- 문서에서 문장 추출함.
- 문장의 마침표, 개행문자(\n) 등 문장의 마지막을 뜻하는 기호에 따라 분리하는 것이 일반적이다.
- 또한 정규 표현식에 따른 문장 토큰화도 가능하다.
- sent_tokenize() 사용
# 각각의 문장으로 구성된 list 객체 반환
from nltk import sent_tokenize
import nltk
nltk.download('punkt')
text_sample = 'The Matrix is everywhere its all around us, here even in this room. \
You can see it out your window or on your television. \
You feel it when you go to work, or go to church or pay your taxes.'
sentences = sent_tokenize(text=text_sample)
print(type(sentences),len(sentences))
print(sentences)-> oup put
[nltk_data] Downloading package punkt to /root/nltk_data...
[nltk_data] Unzipping tokenizers/punkt.zip.
<class 'list'> 3
['The Matrix is everywhere its all around us, here even in this room.', 'You can see it out your window or on your television.', 'You feel it when you go to work, or go to church or pay your taxes.'](2-2) 단어 토큰화
- 문장에거 단어 추출함.
- 공백, 콤마, 마침표, 개행문자 등으로 단어를 분리하지만,
- 정규표현식을 이용해 다양한 유형으로 토큰화를 수행 할 수 있다.
- word_tokenize() 사용.
from nltk import word_tokenize
sentence = "The Matrix is everywhere its all around us, here even in this room."
words = word_tokenize(sentence)
print(type(words), len(words))
print(words)-> out put
<class 'list'> 15
['The', 'Matrix', 'is', 'everywhere', 'its', 'all', 'around', 'us', ',', 'here', 'even', 'in', 'this', 'room', '.'](2-3) tokenize_text() 함수 생성
from nltk import word_tokenize, sent_tokenize
#여러개의 문장으로 된 입력 데이터를 문장별로 단어 토큰화 만드는 함수 생성
def tokenize_text(text):
# 문장별로 분리 토큰
sentences = sent_tokenize(text)
# 분리된 문장별 단어 토큰화
word_tokens = [word_tokenize(sentence) for sentence in sentences]
return word_tokens
#여러 문장들에 대해 문장별 단어 토큰화 수행.
word_tokens = tokenize_text(text_sample)
print(type(word_tokens),len(word_tokens))
print(word_tokens)택스트 토큰화, N-gram p494
문장을 개별 단어 별로 하나씩 토큰화하면 문맥적인 의미가 무시됨. 이러한 문제를 해결하려고 도입한 것이 n-gram- 연속된 n개의 단어를 하나의 토큰화 단위로 분리해 내는 것
- Agent Smith knocks the door 을 2-gram(bigram)으로 만들면 (Agent, Smith), (Smith, knocks), (knocks, the), (the, door)과 같이 연속적으로 2개의 단어들을 순차적으로 이동하면서 단어들을 토큰화함
1-gram : uni-gram
2-gram : bi-gram
3-gram : tri-gram
n-gram :
(3) 필터링 / 스톱 워드 제거 / 철자 수정 p495
스톱 워드 ( Stop Word )는 분석에 큰 의미가 없는 단어를 지칭한다.
print('영어 stop words 갯수:',len(nltk.corpus.stopwords.words('english')))
print(nltk.corpus.stopwords.words('english')[:20])
- 영어의 경우 스톱 워드의 개수가 179개이며, 그중 20개만 살펴 보았다.
import nltk
nltk.download('stopwords')
stopwords = nltk.corpus.stopwords.words('english')
all_tokens = []
# 위 예제의 3개의 문장별로 얻은 word_tokens list 에 대해 stop word 제거 Loop
for sentence in word_tokens:
filtered_words=[]
# 개별 문장별로 tokenize된 sentence list에 대해 stop word 제거 Loop
for word in sentence:
#소문자로 모두 변환합니다.
word = word.lower()
# tokenize 된 개별 word가 stop words 들의 단어에 포함되지 않으면 word_tokens에 추가
if word not in stopwords:
filtered_words.append(word)
all_tokens.append(filtered_words)
print(all_tokens)
- is, this와 같은 스톱 워드는 필터링 되었다.
(4) Stemming과 Lemmatization p496
문법적으로 또는 의미적으로 변화하는 단어의 원형을 찾는 것.
-
Stemming( 어간 추출 ) : 원형 단어로 변환 시 일반적인 방법을 적용하거나 더 단순화된 방법을 적용해 원래 단어에서 일부 철자가훼손된어근 단어를 추출하는 경향이 있다. (stemmer 제공), ( Porter, Lancaster, Snowball Stemmer ) -
Lemmatization( 표제어 추출 ) : 품사와 같은 문법적인 요소와 더 의미적인 부분을 감안해정확한철자로 된 어근 단어를 찾아준다. 변환에 오랜 시간 필요함. ( WordNetLemmatizer 제공 )
(4-1) PorterStemmer
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem('working'),stemmer.stem('works'),stemmer.stem('worked'))
print(stemmer.stem('amusing'),stemmer.stem('amuses'),stemmer.stem('amused'))
print(stemmer.stem('happier'),stemmer.stem('happiest'))
print(stemmer.stem('fancier'),stemmer.stem('fanciest'))
print(stemmer.stem('was'), stemmer.stem('were'))-> out put
work work work
amus amus amus
happier happiest
fancier fanciest
wa were(4-2) LancasterStemmer (단어 원형), stemmer객체
from nltk.stem import LancasterStemmer
stemmer = LancasterStemmer()
print(stemmer.stem('working'),stemmer.stem('works'),stemmer.stem('worked'))
print(stemmer.stem('amusing'),stemmer.stem('amuses'),stemmer.stem('amused'))
print(stemmer.stem('happier'),stemmer.stem('happiest'))
print(stemmer.stem('fancier'),stemmer.stem('fanciest'))-> out put
work work work
amus amus amus
happy happiest
fant fanciest(4-3) Lemmatization (품사 입력), lemmatize() 파라미터 생성
from nltk.stem import WordNetLemmatizer
import nltk
nltk.download('omw-1.4')
lemma = WordNetLemmatizer()
print(lemma.lemmatize('amusing','v'),lemma.lemmatize('amuses','v'),lemma.lemmatize('amused','v'))
print(lemma.lemmatize('happier','a'),lemma.lemmatize('happiest','a'))
print(lemma.lemmatize('fancier','a'),lemma.lemmatize('fanciest','a'))-> out put
[nltk_data] Downloading package omw-1.4 to /root/nltk_data...
amuse amuse amuse
happy happy
fancy fancy[ Bag of Words - BOW p498 ]
Bag of Words 모델은 문서가 가지는 모든 단어를 문맥이나 순서를 무시하고 일괄적으로 단어에 대해 빈도 값을 부여해 피처 값을 추출하는 모델이다.
문서 내 모든 단어를 한꺼번에 봉투 안에 넣은 뒤에 흔들어서 섞는다는 의미로 Bag of Words 모델이라고 한다.
-
BOW 모델의
장점은쉽고 빠르게 구축할 수 있다는 것이고 단순히 단어의 발생 횟수에 기반하고 잇지만, 예상보다 문서의 특징을 잘 나타낼 수 있는 모델이다. -
하지만 BOW 기반의 NLP 연구는 여러 가지 제약을 지니는데
우선은 문맥의 의미를 반영하지 못한다는단점을 지닌다.- BOW는 단어의 순서를 고려하지 않기 때문에 문장 내에서 단어의
문맥적인 의미가 무시된다.
이를 보완하기 위해 n_gram 기법을 활용할 수는 있지만 이는 제한적으로 언어의 많은 부분을 차지하는 문맥적인 해석을 처리하지 못한다는 단점이 있다. - 두번째는
희소 행렬 문제이다.
BOW로 피처 벡터화를 수행하면 희소 행렬 ( 대규모의 칼럼으로 구성된 행렬에서 대부분의 값이 0으로 채워지는 행렬 <-> 밀집 행렬) 형태의 데이터 세트가 만들어지기 쉽다.
- BOW는 단어의 순서를 고려하지 않기 때문에 문장 내에서 단어의
많은 문서에서 단어를 추출하면 문서마다 서로 다른 단어로 구성되어 매우 많은 단어가 칼럼으로 만들어지기 때문이다.
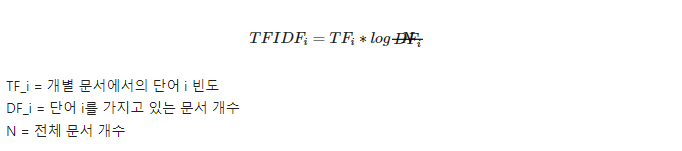
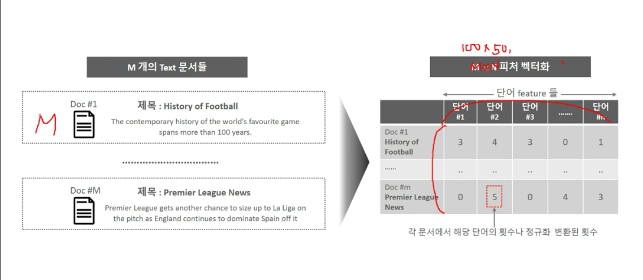
BOW 피처 벡터화 p499
머신러닝 알고리즘은 일반적으로 숫자형 피처를 데이터로 입력받아 동작하기 때문에 텍스트 자체를 바로 피처로 머신러닝 알고리즘에 입력할 수가 없다.
따라서 텍스트를 특정 의미를 가지는 숫자형 값인 벡터 값으로 변환해야 하는데, 이러환 변환을 피처 벡터화라고 한다.
BOW 모델에서 피처 벡터화는 모든 문서에서 모든 단어를 칼럼 형태로 나열하고 각 문서에서 해당 단어의 횟수나 정규화된 빈도를 값으로 부여하는 데이터 세트 모델로 변경하는 것이다.
BOW의 피처 벡터화 방식에는 2가지가 존재한다.
-
(1)
카운트 기반 벡터화: 단어 피처에 값을 부여할 때 각 문서에서 해당 단어가 나타나는횟수에 Count를부여하는 경우를 카운트 벡터화라고 한다.카운트 값이 높을수록중요한 단어로 인식되며, 이에 그 문서의 특징을 나타내는 단어가 아닌 언어의 특성상 문장에서 자주 사용될 수 밖에 없는 단어까지 높은 값을 부여하게 된다. -
(2)
TF-IDF( Term Frequency - Inverse Document Frequency ) 기반 벡터화 : 위와 같은 카운트 기반 벡터화의 문제를 보완하기 위해 개별 문서에서자주 나오는 단어에 높은 가중치를 주되, 모든 문서에서 전반적으로 자주 나타나는 단어에 대해서는페널티를 주는 방식으로 값을 부여한다.

- 문서마다 택스트 길이가 문서의 개수가 많을 수록
TF-IDF방식을 사용하는것이 더 좋다.
사이킷런의 Count 및 TF-IDF 벡터화 구현 : CountVectorizer, TfidVectorizer p501
-
< CountVectorizer, TfidVectorizer의 파라미터 >
- max_df : 너무
높은 빈도수를 가지는 단어 피처를 제외, 정수 값을 가지면 전체 문서에 걸쳐 n개 이하로 나타나는 단어만 피처로 추출하고 부동 소수점 값을 가지면 전체 문서에 걸쳐 빈도수% 까지의 단어만 피처로 추출한다. - min_df : 너무
낮은 빈도수를 가지는 단어 피처를 제외 - max_features :
높은 빈도를 가지는 단어 순으로 몇 개를 추출할 건지 입력 - stop_words :
english로 지정하면 여어의 스톱 워드로 지정된 단어는 추출에서 제외한다. - n_gram_range : BOW 모델이 문맥의 의미를 반영하지 못한다는 단점을 극복하기 위해
n_gram 범위를 설정한다. 튜플 형태로 (범위 최솟값, 범위 최댓값)을 지정 - analyzer : 피처 추출을 수행한
단위를 지정한다. default = 'word' - token_pattern :
토큰화를 수행하는 정규 표현식 패턴을 지정합니다. default = '\b\w\w+\b' - tokenizer :
토큰화를 별도의 커스텀 함수로 이용시 적용한다.
- max_df : 너무
-
< CountVectorizer 클래스를 이용한 피처 벡터화 방법 >
- 사전 데이터 가공 : 영어의 경우 모든 문자를 소문자로 변경하는 등의 전처리 작업을 수행한다.
- 토큰화 : 디폴트(analyzer = True)로 단어 기준으로 n_gram_range를 반영해 각 단어를 토큰화한다.
- 텍스트 정규화 : Stop Word 필터링을 수행한다. ( Stemmer, Lemmatize는 자체 지원 x )
- 피처 벡터화 : max_df, min_df, max_features 등의 파라미터를 이용해 토큰화된 단어를 피처로 추출하고 단어 빈도수 벡터 값을 적용한다.

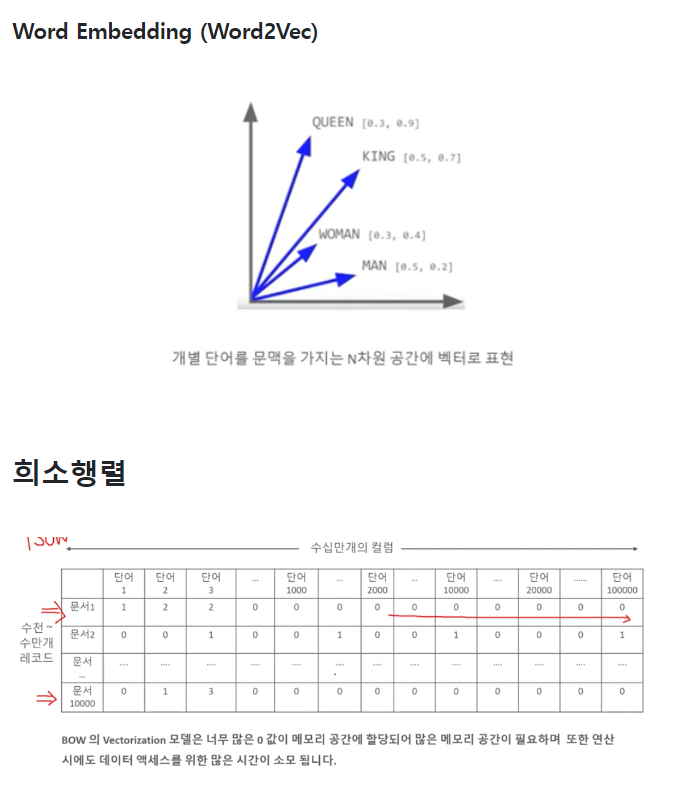
BOW 벡터화를 위한 희소 행렬 p503
BOW 벡터화를 수행할 경우 불필요한 0값이 메모리 공간에 할당되어 메모리 공간이 많이 필요하다.
따라서 적은 메모리 공간을 차지할 수 있도록 변환이 필요하다.
대표적인 방법으로 COO 형식과 CSR 형식이 있다.
일반적으로 큰 희소 행렬을 저장하고 계산을 수행하는 능력이 CSR 형식이 더 뛰어나기 때문에 CSR 형식을 많이 사용한다.
저장 변환 형식 p504
(1) 희소 행렬 - COO형식
COO(Coordinate : 좌표) 형식은 0이 아닌 데이터만 별도의 데이터 배열에 저장하고, 그 데이터가 가리키는 행과 열의 위치를 별도의 배열로 저장하는 방식이다.
주로 scipy(사이파이)이용함. sparse.coo_matrix

(2) 희소 행렬 - CSR형식
CSR(Compressed Sparse Row) 형식은 COO 형식이 행과 열의 위치를 나타내기 위해서 반복적인 위치 데이터를 사용해야 하는 문제점을 해결한 방식이다.
COO 형식의 행 위치 배열을 자세히 살펴보면 순차적인 같은 값이 반복적으로 나타나는 것을 확인할 수 있다.
행 위치 배열이 0부터 순차적으로 증가하는 값으로 이루어졌다는 특성을 고려하면 행 위치 배열의 고유한 값의 시작 위치만 표기하는 방법으로 이러한 반복을 제거할 수 있다.
주로 scipy(사이파이)이용함. sparse.csr_matrix

from scipy import sparse
dense2 = np.array([[0,0,1,0,0,5],
[1,4,0,3,2,5],
[0,6,0,3,0,0],
[2,0,0,0,0,0],
[0,0,0,7,0,8],
[1,0,0,0,0,0]])
# 0 이 아닌 데이터 추출
data2 = np.array([1, 5, 1, 4, 3, 2, 5, 6, 3, 2, 7, 8, 1]) # 데이터 값 배열
# 행 위치와 열 위치를 각각 array로 생성
row_pos = np.array([0, 0, 1, 1, 1, 1, 1, 2, 2, 3, 4, 4, 5]) # 행 위치 배열
col_pos = np.array([2, 5, 0, 1, 3, 4, 5, 1, 3, 0, 3, 5, 0]) # 열 위치 배열
# COO 형식으로 변환
sparse_coo = sparse.coo_matrix((data2, (row_pos,col_pos)))
# 행 위치 배열의 고유한 값들의 시작 위치 인덱스를 배열로 생성
row_pos_ind = np.array([0, 2, 7, 9, 10, 12, 13]) # 마지막에 총 항목 개수 배열을 추가로 넣어준다
# CSR 형식으로 변환
sparse_csr = sparse.csr_matrix((data2, col_pos, row_pos_ind))
print('COO 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인')
print(sparse_coo.toarray())
print('CSR 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인')
print(sparse_csr.toarray())-> out put
COO 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인
[[0 0 1 0 0 5]
[1 4 0 3 2 5]
[0 6 0 3 0 0]
[2 0 0 0 0 0]
[0 0 0 7 0 8]
[1 0 0 0 0 0]]
CSR 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인
[[0 0 1 0 0 5]
[1 4 0 3 2 5]
[0 6 0 3 0 0]
[2 0 0 0 0 0]
[0 0 0 7 0 8]
[1 0 0 0 0 0]][ 뉴스그룹 텍스트 분류 p509 ]
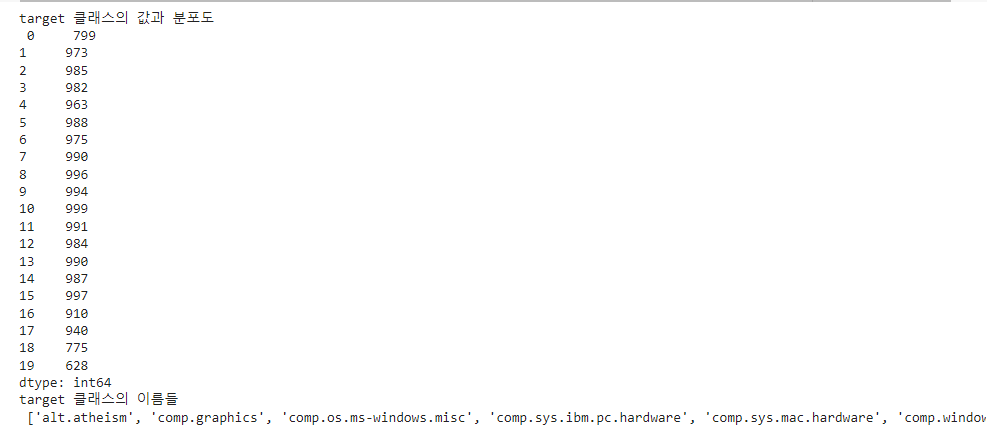
from sklearn.datasets import fetch_20newsgroups
news_data = fetch_20newsgroups(subset='all',random_state=156)
print(news_data.keys())
import pandas as pd
print('target 클래스의 값과 분포도 \n',pd.Series(news_data.target).value_counts().sort_index())
print('target 클래스의 이름들 \n',news_data.target_names)
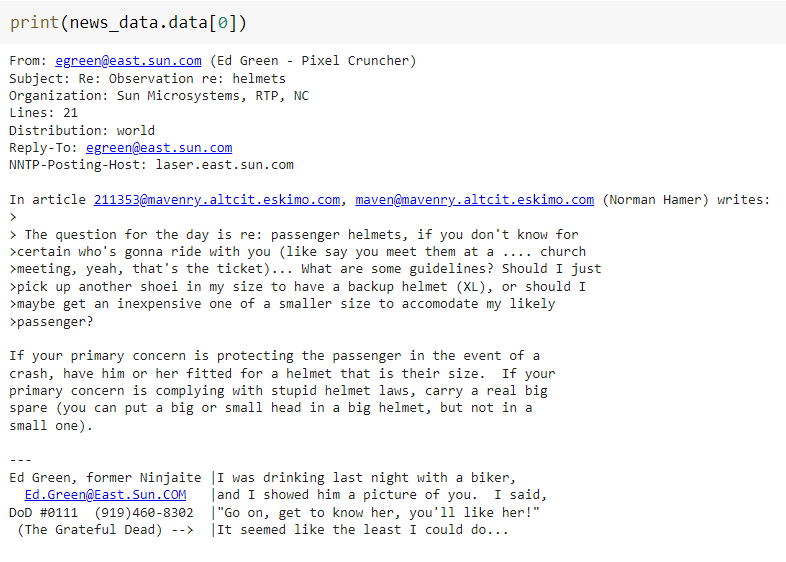
print(news_data.data[0])
from sklearn.datasets import fetch_20newsgroups
# subset='train'으로 학습용(Train) 데이터만 추출, remove=('headers', 'footers', 'quotes')로 내용만 추출
train_news= fetch_20newsgroups(subset='train', remove=('headers', 'footers', 'quotes'), random_state=156)
X_train = train_news.data
y_train = train_news.target
print(type(X_train))
# subset='test'으로 테스트(Test) 데이터만 추출, remove=('headers', 'footers', 'quotes')로 내용만 추출
test_news= fetch_20newsgroups(subset='test',remove=('headers', 'footers','quotes'),random_state=156)
X_test = test_news.data
y_test = test_news.target
print('학습 데이터 크기 {0} , 테스트 데이터 크기 {1}'.format(len(train_news.data) , len(test_news.data)))-> out put
<class 'list'>
학습 데이터 크기 11314 , 테스트 데이터 크기 7532피처 벡터화 변환과 머신러닝 모델 학습/예측/평가 p512
from sklearn.feature_extraction.text import CountVectorizer
# Count Vectorization으로 feature extraction 변환 수행.
cnt_vect = CountVectorizer()
cnt_vect.fit(X_train)
X_train_cnt_vect = cnt_vect.transform(X_train)
# 학습 데이터로 fit( )된 CountVectorizer를 이용하여 테스트 데이터를 feature extraction 변환 수행.
X_test_cnt_vect = cnt_vect.transform(X_test)
print('학습 데이터 Text의 CountVectorizer Shape:',X_train_cnt_vect.shape)->
학습 데이터 Text의 CountVectorizer Shape: (11314, 101631)from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# LogisticRegression을 이용하여 학습/예측/평가 수행.
lr_clf = LogisticRegression(max_iter=500)
lr_clf.fit(X_train_cnt_vect , y_train)
pred = lr_clf.predict(X_test_cnt_vect)
print('CountVectorized Logistic Regression 의 예측 정확도는 {0:.3f}'.format(accuracy_score(y_test,pred)))-> out put
CountVectorized Logistic Regression 의 예측 정확도는 0.597from sklearn.feature_extraction.text import TfidfVectorizer
# TF-IDF Vectorization 적용하여 학습 데이터셋과 테스트 데이터 셋 변환.
tfidf_vect = TfidfVectorizer()
tfidf_vect.fit(X_train)
X_train_tfidf_vect = tfidf_vect.transform(X_train)
X_test_tfidf_vect = tfidf_vect.transform(X_test)
# LogisticRegression을 이용하여 학습/예측/평가 수행.
lr_clf = LogisticRegression()
lr_clf.fit(X_train_tfidf_vect , y_train)
pred = lr_clf.predict(X_test_tfidf_vect)
print('TF-IDF Logistic Regression 의 예측 정확도는 {0:.3f}'.format(accuracy_score(y_test ,pred)))-> out put
TF-IDF Logistic Regression 의 예측 정확도는 0.674# stop words 필터링을 추가하고 ngram을 기본(1,1)에서 (1,2)로 변경하여 Feature Vectorization 적용.
tfidf_vect = TfidfVectorizer(stop_words='english', ngram_range=(1,2), max_df=300 )
tfidf_vect.fit(X_train)
X_train_tfidf_vect = tfidf_vect.transform(X_train)
X_test_tfidf_vect = tfidf_vect.transform(X_test)
lr_clf = LogisticRegression(max_iter=500)
lr_clf.fit(X_train_tfidf_vect , y_train)
pred = lr_clf.predict(X_test_tfidf_vect)
print('TF-IDF Vectorized Logistic Regression 의 예측 정확도는 {0:.3f}'.format(accuracy_score(y_test ,pred)))-> out put
TF-IDF Vectorized Logistic Regression 의 예측 정확도는 0.692from sklearn.model_selection import GridSearchCV
# 최적 C 값 도출 튜닝 수행. CV는 3 Fold셋으로 설정.
params = { 'C':[0.01, 0.1, 1, 5, 10]}
grid_cv_lr = GridSearchCV(lr_clf ,param_grid=params , cv=3 , scoring='accuracy' , verbose=1 )
grid_cv_lr.fit(X_train_tfidf_vect , y_train)
print('Logistic Regression best C parameter :',grid_cv_lr.best_params_ )
# 최적 C 값으로 학습된 grid_cv로 예측 수행하고 정확도 평가.
pred = grid_cv_lr.predict(X_test_tfidf_vect)
print('TF-IDF Vectorized Logistic Regression 의 예측 정확도는 {0:.3f}'.format(accuracy_score(y_test ,pred)))-> out put
오래걸림 -__-
Fitting 3 folds for each of 5 candidates, totalling 15 fits
Logistic Regression best C parameter : {'C': 10}
TF-IDF Vectorized Logistic Regression 의 예측 정확도는 0.701사이킷런 파이프라인(Pipeline) 사용 및 GridSearchCV와의 결합 p516
피처 벡터화와 ML 알고리즘 학습 / 예측을 위한 코드 작성을 한 번에 진행할 수 있다. 사이킷런은 GridSearchCV 클래스의 생성 파라미터로 Pipeline을 입력해 Pipeline 기반에서도 하이퍼 파라미터 튜닝을 GridSearchCV 방식으로 진행할 수 있게 지원한다.
이 때 Estimator가 아닌 Pipeline을 GridSearchCV에 입력할 경우에는 딕셔너리 형태의 key를 입력할 때 하이퍼 파라미터명이 객체 변수명과 결합되어 제공되기 때문에 객체 변수명에 언더바(\'_\') 2개를 연달아 붙인 뒤 파라미터 명을 붙여 Key 값으로 할당한다.
from sklearn.pipeline import Pipeline
# TfidfVectorizer 객체를 tfidf_vect 객체명으로, LogisticRegression객체를 lr_clf 객체명으로 생성하는 Pipeline생성
pipeline = Pipeline([
('tfidf_vect', TfidfVectorizer(stop_words='english', ngram_range=(1,2), max_df=300)),
('lr_clf', LogisticRegression(max_iter=500, C=10))
])
# 별도의 TfidfVectorizer객체의 fit_transform( )과 LogisticRegression의 fit(), predict( )가 필요 없음.
# pipeline의 fit( ) 과 predict( ) 만으로 한꺼번에 Feature Vectorization과 ML 학습/예측이 가능.
pipeline.fit(X_train, y_train)
pred = pipeline.predict(X_test)
print('Pipeline을 통한 Logistic Regression 의 예측 정확도는 {0:.3f}'.format(accuracy_score(y_test ,pred)))-> out put
겁나 오래걸림 -__-
Pipeline을 통한 Logistic Regression 의 예측 정확도는 0.701# Grid Search 시간이 오래 걸려 실행은 생략
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('tfidf_vect', TfidfVectorizer(stop_words='english')),
('lr_clf', LogisticRegression(max_iter = 500))
])
# Pipeline에 기술된 각각의 객체 변수에 언더바(_)2개를 연달아 붙여 GridSearchCV에 사용될
# 파라미터/하이퍼 파라미터 이름과 값을 설정. .
params = { 'tfidf_vect__ngram_range': [(1,1), (1,2), (1,3)],
'tfidf_vect__max_df': [100, 300, 700],
'lr_clf__C': [1,5,10]
}
# GridSearchCV의 생성자에 Estimator가 아닌 Pipeline 객체 입력
grid_cv_pipe = GridSearchCV(pipeline, param_grid=params, cv=3 , scoring='accuracy',verbose=1)
grid_cv_pipe.fit(X_train , y_train)
print(grid_cv_pipe.best_params_ , grid_cv_pipe.best_score_)
pred = grid_cv_pipe.predict(X_test)
print('Pipeline을 통한 Logistic Regression 의 예측 정확도는 {0:.3f}'.format(accuracy_score(y_test ,pred)))-> out put
모르겠음... 기다려도 안나와- 희소 행렬의 분류를 효과적으로 잘 처리할 수 있는 알고리즘은 로지스틱 회귀, 선형 서포트 벡터 머신, 나이브 베이즈이다.
[ 감성 분석 p519]
감성 분석(Sentiment Analysis)은 문서의 주관적인 감성/의견/감정/기분 등을 파악하기 위한 방법으로 소셜 미디어, 여론조사, 온라인 리뷰, 피드백 등 다양한 분야에서 활용되고 있다.
감성 분석은 문서 내 텍스트가 나타내는 여러 가지 주관적인 단어와 문맥을 기반으로 감성 수치를 계산하는 방법을 이용한다.
이러한 감성 지수는 긍정 감성 지수와 부정 감성 지수로 구성되며 이들 지수를 합산해 긍정 감성 또는 부정 감성을 결정한다.
감성 분석은 머신러닝 관점에서 지도학습과 비지도학습 방식으로 나눌 수 있는데,
우선 지도학습은 학습 데이터와 타깃 레이블 값을 기반으로 감성 분석 학습을 수행한 뒤 이를 기반으로 다른 데이터의 감성 분석을 예측하는 방법으로 일반적인 텍스트 기반의 분류와 거의 동일하다.
비지도학습의 경우에는 'Lexicon'이라는 일종의 감성 어휘 사전을 이용하는데, Lexicon은 감성 분석을 위한 용어와 문맥에 대한 다양한 정보를 가지고 있으며, 이를 이용해 긍정적, 부정적 감성 여부를 판단한다.
- 문서의 주관적인 감성/의견/감정/기분 등을 파악하기 위한 방법
- 소셜미디어, 여론조사, 온라인 리뷰 등 다양한 분야에서 활용됨
- 분석 방법
- 지도 학습 기반의 분석: 텍스트 기반 분류와 거의 동일
- 감성 어휘 사전을 이용한 분석: 감성 분석을 위한 용어와 문맥에 대한 정보를 가지고 있음. 이를 이용해 긍부정 감성 여부를 판단
지도학습 기반 감성 분석 실습 - IMDB 영화평
import pandas as pd
review_df = pd.read_csv("/content/drive/MyDrive/book/labeledTrainData.tsv", header = 0, sep = "\t", quoting = 3)
review_df.head(3)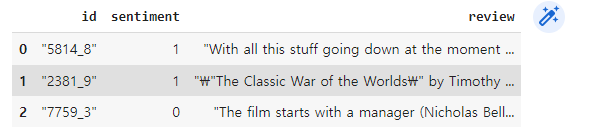
- id : 각 데이터의 id
- sentiment : 영화평의 Sentiment 결과 값 ( 1은 긍정적, 0은 부정적 )
- review : 영화평의 텍스트
# 텍스트가 어떻게 구성되어 있는지 확인
print(review_df['review'][0])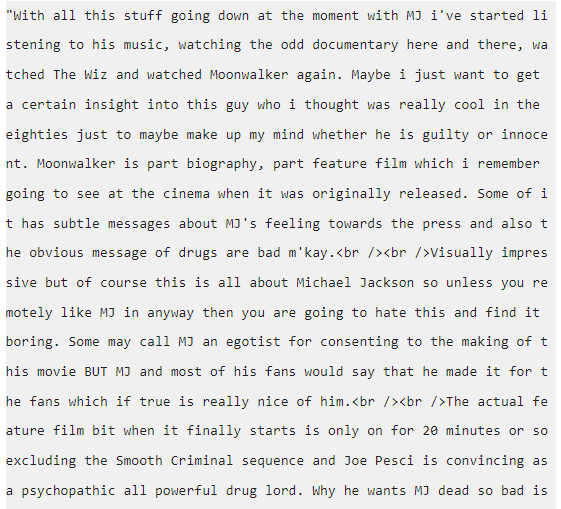
...
- 문자열은 피처로 만들 필요가 없다
-> 공백으로 숫자, 특수문자 역시 모두 Sentiment를 위한 피처로는 의미가 없어 공란으로 변경 ( 정규 표현식 사용 )
-> 파이썬의 re모듈은 편리하게 정규 표현식을 지원한다.
import re
# <br> html 태그는 replace 함수로 공백으로 변환
review_df['review'] = review_df['review'].str.replace('<br />', ' ')
# 파이썬의 re 모듈을 이용해 영어 문자열이 아닌 문자는 모두 공백으로 변환
review_df['review'] = review_df['review'].apply(lambda x : re.sub("[^a-zA-Z]", " ", x))
# [^a-zA-Z] 는 영어 대/소문자가 아닌 모든 문자를 찾는 정규 표현식# 결정 값 클래스인 sentiment 칼럼을 별도로 추출
from sklearn.model_selection import train_test_split
class_df = review_df['sentiment']
feature_df = review_df.drop(['id','sentiment'], axis=1, inplace=False)
X_train, X_test, y_train, y_test= train_test_split(feature_df, class_df, test_size=0.3, random_state=156)
X_train.shape, X_test.shape-> out put
((17500, 1), (7500, 1))- 학습 데이터 : 17500 리뷰, 테스트용 데이터 : 7500개 리뷰
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, roc_auc_score
# 스톱 워드는 English, filtering, ngram은 (1,2)로 설정해 CountVectorization수행.
# LogisticRegression의 C는 10으로 설정.
pipeline = Pipeline([
('cnt_vect', CountVectorizer(stop_words='english', ngram_range=(1,2) )),
('lr_clf', LogisticRegression(C=10, max_iter = 500))]) # C 값이 작으면 훈련을 덜 복잡 ( 강한 규제)
# Pipeline 객체를 이용하여 fit(), predict()로 학습/예측 수행. predict_proba()는 roc_auc때문에 수행.
pipeline.fit(X_train['review'], y_train)
pred = pipeline.predict(X_test['review'])
pred_probs = pipeline.predict_proba(X_test['review'])[:,1]
print('예측 정확도는 {0:.4f}, ROC-AUC는 {1:.4f}'.format(accuracy_score(y_test ,pred),
roc_auc_score(y_test, pred_probs)))-> out put
예측 정확도는 0.8860, ROC-AUC는 0.9503# 스톱 워드는 english, filtering, ngram은 (1,2)로 설정해 TF-IDF 벡터화 수행.
# LogisticRegression의 C는 10으로 설정.
pipeline = Pipeline([
('tfidf_vect', TfidfVectorizer(stop_words='english', ngram_range=(1,2) )),
('lr_clf', LogisticRegression(C=10, max_iter = 500))])
pipeline.fit(X_train['review'], y_train)
pred = pipeline.predict(X_test['review'])
pred_probs = pipeline.predict_proba(X_test['review'])[:,1]
print('예측 정확도는 {0:.4f}, ROC-AUC는 {1:.4f}'.format(accuracy_score(y_test ,pred),
roc_auc_score(y_test, pred_probs)))-> out put
예측 정확도는 0.8936, ROC-AUC는 0.9598출처:
