
-> 6조각 p262

-> 4, 5 p245
- 걸리는 시간 짧음.
- 별 차이 없다.
- 단점: 적은 데이터 -> 과적합 크다.
- 리프중심 트리 분활 방식
- 장점: 학습 시간이 빠르다, 메모리 사용량도 적다.

-> 4
- 재현율: p->n 보면 큰일난다. 재현율 = TP/(TP + FN)
- 결합한 평가 지표이다. p180
- 치우치지 않을떄 큰 값 가진다. p180
- FPR = FP/(TN + FP) -> 0 , FP=0, 임계값 :1 p169
5(1). FPR = FP/(TN + FP) -> 1, TN=0 임계값:0

-> 4
1. 정밀도: n->p 보면 큰일남. p155
2. 정밀도 = TP/(TP + FP) p라고 예측 p154
3. TPR = 민감도 = 재현율 = Recall p154
4. P:1 t:n -> n p151
5. p:1,n:0 -> 1 p151
캐글 신용카드 사기 검출 p279
캐글의 신용카드 dataset을 이용해 신용카드 사기 검출 분류 실습을 수행해 보겠다.
해당 dataset의 label인 Class 속성은 매우 불균형한 분포를 가지고 있다.
Class에서 0은 정상적인 신용카드 트랜잭션 데이터이고, 1은 신용카드 사기 트랜잭션을 의마하며, 전체 데이터의 약 0.172%만이 사기 트랜잭션이다.
일반적으로 사기 검출(Fraud Detection)이나 이상 검출(Anomaly Detection)과 같은 dataset은 label 값이 극도로 불균형한 분포를 가지기 쉽다.
언더 샘플링과 오버 샘플링 이해 p279
- 언더 샘플링은 많은 dataset를 적은 dataset 수준으로 감소시키는 방식이다.
- 오버 샘플링은 이상 데이터와 같이 적은 dataset을 증식하여 학습을 위한 충분한 dataset을 확보하는 방법이다.
- 대표적으로 SMOTE(Synthetic Minority Over-sampling Technique) 방법이 있다. - SMOTE는 적은 dataset에 있는 개별 데이터들의 K 최근접 이웃 (K Nearest Neighbor)을 찾아서 이 데이터와 K개 이웃들의 차리를 일정 값으로 만들어서 기존 데이터와 약간 차이가 나는 새로운 데이터를 생성하는 방식이다.
- SMOTE를 구현한 대표적인 파이썬 패키지는 imbalanced-learn이다.
데이터 일차 가공 및 모델 학습/예측/평가 p281
필요한 모듈과 데이터를 로딩하고 데이터를 확인해보겠다.
pip install imbalanced-learn
import pandas as pd
import numpy as np
card_df = pd.read_csv('./creditcard.csv')
card.head(3)
card.info()
card.shapeV로 시작하는 feature는 의미를 알 수 없고,
Time feature는 데이터 생성과 관련한 작업용 속성으로서 큰 의미가 없어 제거하였다.
Amount feature는 신용카드 트랙잭션 금액을 의미하고,
card.info()로 확인해 보면 결측치(Missing Value) 값은 없다.

(1) time 칼럼을 삭제한다.
card.drop('Time', axis=1, inplace=True)
(2) 데이터셋 분리
from sklearn.model_selection import train_test_split
# DataFrame의 맨 마지막 컬럼이 레이블, 나머지는 피처들
features = card.iloc[:, :-1]
labels= card.iloc[:, -1]
# train_test_split( )으로 학습과 테스트 데이터 분할. stratify=labels 으로 Stratified 기반 분할
X_train, X_test, y_train, y_test = \
train_test_split(features, labels, test_size=0.3, stratify=labels)
# 학습 데이터 레이블 값 비율 p283
y_train.value_counts()/len(y_train)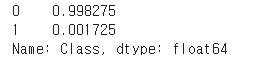
- 학습 데이터 레이블 값 비율 0 : 0.9982 , 1 : 0.00172
# (3) 모델 생성, fit,predict,evaluate
from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression(max_iter = 1000)
lr_clf.fit(X_train, y_train)
preds = lr_clf.predict(X_test)
preds_proba = lr_clf.predict_proba(X_test)[:,1]
get_clf_eval(y_test, preds ,preds_proba)
- 로지스틱 회귀 모델 학습 후 재현율 : 0.5946, AUC : 0.9496
get_clf_eval 함수정의
from sklearn.metrics import roc_auc_score, confusion_matrix, accuracy_score, precision_score, recall_score, f1_score def get_clf_eval(y_test, pred=None, pred_proba=None): confusion = confusion_matrix( y_test, pred) accuracy = accuracy_score(y_test , pred) precision = precision_score(y_test , pred) recall = recall_score(y_test , pred) f1 = f1_score(y_test,pred) # ROC-AUC 추가 roc_auc = roc_auc_score(y_test, pred_proba) print('오차 행렬') print(confusion) # ROC-AUC print 추가 print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f},\ F1: {3:.4f}, AUC:{4:.4f}'.format(accuracy, precision, recall, f1, roc_auc))
# (3.1) 모델 생성, fit,predict,evaluate
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(n_estimators= 1000, num_leaves= 64, n_jobs= -1, boost_from_average = False)
lgbm_clf.fit(X_train, y_train)
preds = lgbm_clf.predict(X_test)
preds_proba = lgbm_clf.predict_proba(X_test)[:,1]
get_clf_eval(y_test, preds ,preds_proba)
- lightGBM 모델 학습 후 재현율:0.7925, AUC:0.9844
- 로지스틱 회귀보다 높은 수치를 나타냈다.
데이터 분포도 변환 후 모델 학습/예측/평가 p285
데이터 정제(스케일링) 후 적용
card["Amount"].describe()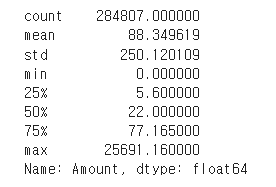

- 정규분포로 바꾸기 위해 사이킷런의 StandardScaler 클래스를 이용해 Amount feature를 정규 분포로 변환하겠다.
표준화 - 표준정규 분포
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
card["Amount"] = scaler.fit_transform(card["Amount"].values.reshape(-1,1))
card["Amount"]
# (2) 데이터셋 분리
from sklearn.model_selection import train_test_split
# DataFrame의 맨 마지막 컬럼이 레이블, 나머지는 피처들
features = card.iloc[:, :-1]
labels= card.iloc[:, -1]
# train_test_split( )으로 학습과 테스트 데이터 분할. stratify=labels 으로 Stratified 기반 분할
X_train, X_test, y_train, y_test = \
train_test_split(features, labels, test_size=0.3, stratify=labels)
# (3) 모델 생성, fit,predict,evaluate
from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression(max_iter = 1000)
lr_clf.fit(X_train, y_train)
preds = lr_clf.predict(X_test)
preds_proba = lr_clf.predict_proba(X_test)[:,1]
print(get_clf_eval(y_test, preds ,preds_proba))
print()
# (3.1) 모델 생성, fit,predict,evaluate
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(n_estimators= 1000, num_leaves= 64, n_jobs= -1, boost_from_average = False)
lgbm_clf.fit(X_train, y_train)
preds = lgbm_clf.predict(X_test)
preds_proba = lgbm_clf.predict_proba(X_test)[:,1]
print(get_clf_eval(y_test, preds ,preds_proba))
- 두 모델 모두 이전과 성능이 크게 개선되지 않았다.
데이터 정제 (로그변환) 후 적용 p287
- 이번에는 로그 변환을 수행해 보겠다.
- 로그 변환은 데이터 분포도가 심하게 왜곡되어 있을 경우 적용하는 중요 기법 중 하나이다.
- log 변환으로 원래 큰 값을 상대적으로 작은 값으로 변환하기 때문에 데이터 분포도의 왜곡을 상당 수준 개선해준다.
import pandas as pd
import numpy as np
# 데이처 불러오기
card = pd.read_csv('/content/drive/MyDrive/book/creditcard.csv')
# (1) time 삭제
card.drop('Time', axis=1, inplace=True)
card["Amount"] 
# 로그변환하기 (로그 사용 이유 : 숫자가 너무 커서)
card["Amount"] = np.log1p(card["Amount"])
card["Amount"] 
# (2) 데이터셋 분리
from sklearn.model_selection import train_test_split
# DataFrame의 맨 마지막 컬럼이 레이블, 나머지는 피처들
features = card.iloc[:, :-1]
labels= card.iloc[:, -1]
# train_test_split( )으로 학습과 테스트 데이터 분할. stratify=labels 으로 Stratified 기반 분할
X_train, X_test, y_train, y_test = \
train_test_split(features, labels, test_size=0.3, stratify=labels)
# (3) 모델 생성, fit,predict,evaluate
from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression(max_iter = 1000)
lr_clf.fit(X_train, y_train)
preds = lr_clf.predict(X_test)
preds_proba = lr_clf.predict_proba(X_test)[:,1]
print(get_clf_eval(y_test, preds ,preds_proba))
print()
# (3.1) 모델 생성, fit,predict,evaluate
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(n_estimators= 1000, num_leaves= 64, n_jobs= -1, boost_from_average = False)
lgbm_clf.fit(X_train, y_train)
preds = lgbm_clf.predict(X_test)
preds_proba = lgbm_clf.predict_proba(X_test)[:,1]
print(get_clf_eval(y_test, preds ,preds_proba))
- 두 모델 모두 정밀도와 재현율, ROC-AUC에서 약간의 성능 개선을 확인할 수 있다.
이상치 데이터 제거 후 모델 학습/예측/평가 p288
- 이상치 데이터(Outlier)는 전체 데이터의 패턴에서 벗어난 이상 값을 가진 데이터이며, 이로 인해 머신러닝 모델의 성능에 영향을 받는 경우가 발생하기 쉽다.
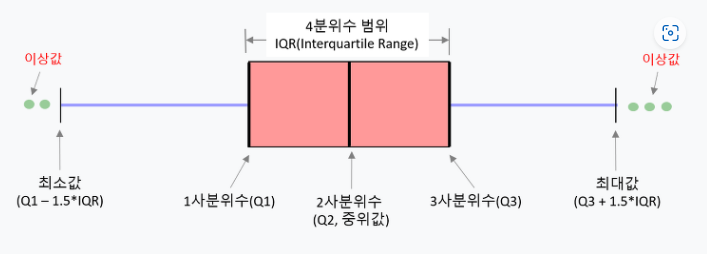
- IQR(Inter Quantile Range) 방식을 적용해 보겠다.
- IQR은 사분위(Quantile) 값의 편차를 이용하는 기법으로 흔히 박스 플롯(Box Plot) 방식으로 시각화할 수 있다.
-
사분위는 전체 데이터를 값이 높은 순으로 정렬하고, 이를 25%씩으로 구간을 분할하는 것을 지칭한다.
-
IQR을 이용해 이상치 데이터를 검출하는 방식은 보통 IQR에 1.5를 곱해서 생성된 범위를 이용해 최대값과 최솟값을 결정한 뒤 최댓값을 초과하거나 최솟값에 미달하는 데이터를 이상치로 간주하는 것이다.
-
Q3에 IQR1.5를 더해서 일반적인 데이터가 가질 수 있는 최대값으로 가정하고, Q1에 IQR1.5를 빼서 일반적인 데이터가 가질 수 있는 최솟값으로 가정하였다.
-
경우에 따라 1.5가 아닌 값을 적용할 수도 있지만 일반적으로 1.5를 적용한다. 이렇게 결정된 최댓값보다 크거나, 최솟값보다 작은 값을 이상치 데이터로 간주한다.
-
이상치 데이터 IQR을 제거하기 위해 먼저 어떤 feature의 이상치 데이터를 검출할 것인지 선택이 필요하다. 매우 많은 feature가 있을 경우 이들 중 결정값(label)과 가장 상관성이 높은 feature들을 위주로 이상치를 검출하는 것이 좋다.
-
모든 feature들의 이상치를 검출하는 것은 시간이 많이 소모되며, 결정값과 상관성이 높지 않은 feature들의 경우는 이상치를 제거하더라도 크게 성능 향상에 기여하지 않기 때문이다.
-
DataFrame의 corr()을 이용해 각 feature 별로 상관도를 구한 뒤 시본의 heatmap을 통해 시각화해보았다.
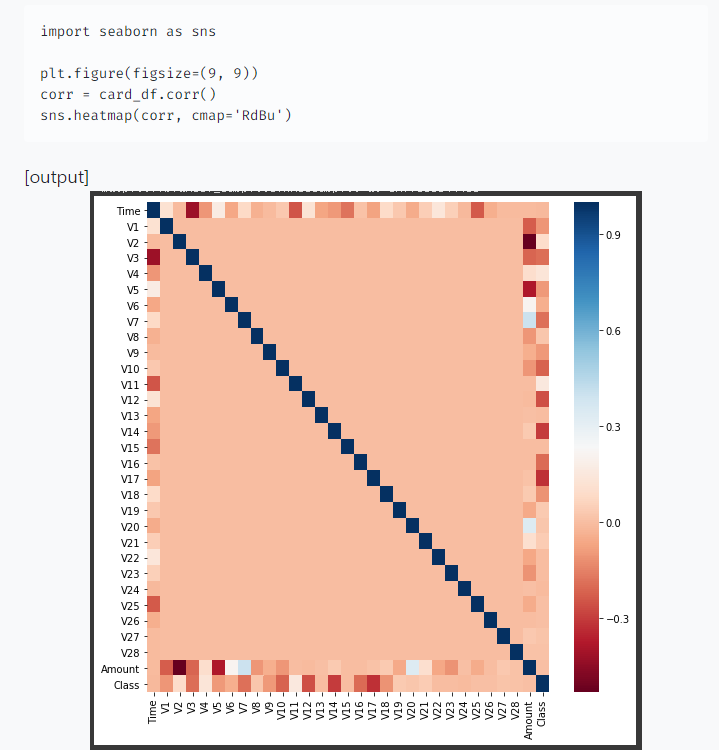
- cmap을 'RdBu'로 설정해 양의 상관관계가 높을수록 색깔이 진한 파란색에 가까우며, 음의 상관관계가 높을수록 색깔이 진한 빨간색에 가깝게 표현된다.
- 결정 label인 Class feature와 음의 상관관계가 가장 높은 feature는 V14, V17이다.
- 이 중 V14만 이상치를 찾아서 제거해보겠다.
- 넘파이의 percentile()을 이용해 Q1과 Q3를 구하고, 이에 기반해 IQR을 계산하겠다.
# (1) 이상치 찾기, class가 1인것만 찾겠다.
fraud = card[card["Class"]==1]
fraud
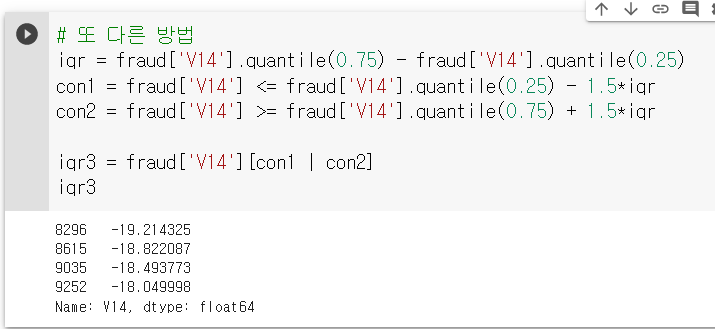
fraud["V14"]
# IQR로 이상치 구하기
pct25 = np.percentile(fraud.V14, 25)
pct75 = np.percentile(fraud.V14, 75)
# IQR을 구하고, IQR에 1.5를 곱하여 최대값과 최소값 지점 구함.
IQR = pct75 - pct25
upper_out = pct75 + 1.5 * IQR
under_out = pct25 - 1.5 * IQR
# 최대값 보다 크거나, 최소값 보다 작은 값을 아웃라이어로 설정하고 DataFrame index 반환.
cond1 = fraud['V14'] >= upper_out
cond2 = fraud['V14'] <= under_out
cond3=fraud.V14[cond1 | cond2]
cond3.index 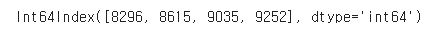
- 총 4개의 data가 이상치로 추출되었다.
- 이제 이상치를 추출하고 이를 삭제한 로직을 추가한 후 데이터를 다시 가공해 로지스틱 회귀와 LightGBM 모델에 적용시켜보겠다.
card.shape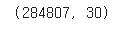
#card에서 이상치를 빼주세요.
card = card.drop(labels = cond3.index, axis=0)
card.shape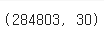
# (2) 데이터셋 분리
from sklearn.model_selection import train_test_split
# DataFrame의 맨 마지막 컬럼이 레이블, 나머지는 피처들
features = card.iloc[:, :-1]
labels= card.iloc[:, -1]
# train_test_split( )으로 학습과 테스트 데이터 분할. stratify=labels 으로 Stratified 기반 분할
X_train, X_test, y_train, y_test = \
train_test_split(features, labels, test_size=0.3, stratify=labels)
# (3) 모델 생성, fit,predict,evaluate
from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression(max_iter = 1000)
lr_clf.fit(X_train, y_train)
preds = lr_clf.predict(X_test)
preds_proba = lr_clf.predict_proba(X_test)[:,1]
print(get_clf_eval(y_test, preds ,preds_proba))
print()
# (3.1) 모델 생성, fit,predict,evaluate
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(n_estimators= 1000, num_leaves= 64, n_jobs= -1, boost_from_average = False)
lgbm_clf.fit(X_train, y_train)
preds = lgbm_clf.predict(X_test)
preds_proba = lgbm_clf.predict_proba(X_test)[:,1]
print(get_clf_eval(y_test, preds ,preds_proba))
- 두 모델 모두 예측 성능이 크게 향상되었다.
SMOTE 오버 샘플링 적용 후 모델 학습/예측/평가 p292
- SMOTE 기법으로 오버 샘플링을 적용한 뒤 로지스틱 회귀와 LightGBM 모델의 예측 성능을 평가해보겠다.
- SMOTE는 imbalanced-learn 패키지의 SMOTE 클래스를 이용해 간단하게 구현이 가능하며,
- SMOTE를 적용할 경우엔 반드시 학습 dataset만 오버 샘플링 해야한다.
검증 dataset이나 테스트 dataset을 오버 샘플링하는 경우 결국은 원본 데이터가 아닌
dataset에서 검증/테스트를 수행하기 때문에 올바른 검증/테스트가 될 수 없다.
from imblearn.over_sampling import SMOTE
from sklearn.linear_model import LogisticRegression
from lightgbm import LGBMClassifier
# DataFrame의 맨 마지막 컬럼이 레이블, 나머지는 피처들
features = card.iloc[:, :-1]
labels= card.iloc[:, -1]
# train_test_split( )으로 학습과 테스트 데이터 분할. stratify=labels 으로 Stratified 기반 분할
X_train, X_test, y_train, y_test = \
train_test_split(features, labels, test_size=0.3, stratify=labels)
smote= SMOTE(random_state = 0)
X_train, y_train = smote.fit_resample(X_train, y_train)
# (3) 모델 생성, fit,predict,evaluate
lr_clf = LogisticRegression(max_iter = 1000)
lr_clf.fit(X_train, y_train)
preds = lr_clf.predict(X_test)
preds_proba = lr_clf.predict_proba(X_test)[:,1]
print(get_clf_eval(y_test, preds ,preds_proba))
print()
# (3.1)모델 생성, fit,predict,evaluate
lgbm_clf = LGBMClassifier(n_estimators= 1000, num_leaves= 64, n_jobs= -1, boost_from_average = False)
lgbm_clf.fit(X_train, y_train)
preds = lgbm_clf.predict(X_test)
preds_proba = lgbm_clf.predict_proba(X_test)[:,1]
print(get_clf_eval(y_test, preds ,preds_proba)) 
- 재현율이 92.4%로 크게 증가하지만, 정밀도가 5.4%로 급격하게 저하되는 것을 볼 수 있다.
- 이는 로지스틱 회귀 모델이 오버 샘플링으로 인해 실제 원본 데이터의 유형보다 너무나 많은 Class가 1인 데이터를 학습하여 실제 테스트 dataset에서 예측을 시나치게 Class 1로 적용해 정밀도가 급격하게 떨어지는 것이다.
- 분류 결정 임계값을 조정하여 정밀도와 재현율 곡선을 그려보겠다.
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
from sklearn.metrics import precision_recall_curve
%matplotlib inline
def precision_recall_curve_plot(y_test , pred_proba_c1):
# threshold ndarray와 이 threshold에 따른 정밀도, 재현율 ndarray 추출.
precisions, recalls, thresholds = precision_recall_curve( y_test, pred_proba_c1)
# X축을 threshold값으로, Y축은 정밀도, 재현율 값으로 각각 Plot 수행. 정밀도는 점선으로 표시
plt.figure(figsize=(8,6))
threshold_boundary = thresholds.shape[0]
plt.plot(thresholds, precisions[0:threshold_boundary], linestyle='--', label='precision')
plt.plot(thresholds, recalls[0:threshold_boundary],label='recall')
# threshold 값 X 축의 Scale을 0.1 단위로 변경
start, end = plt.xlim()
plt.xticks(np.round(np.arange(start, end, 0.1),2))
# x축, y축 label과 legend, 그리고 grid 설정
plt.xlabel('Threshold value'); plt.ylabel('Precision and Recall value')
plt.legend(); plt.grid()
plt.show()
precision_recall_curve_plot( y_test, lr_clf.predict_proba(X_test)[:, 1] )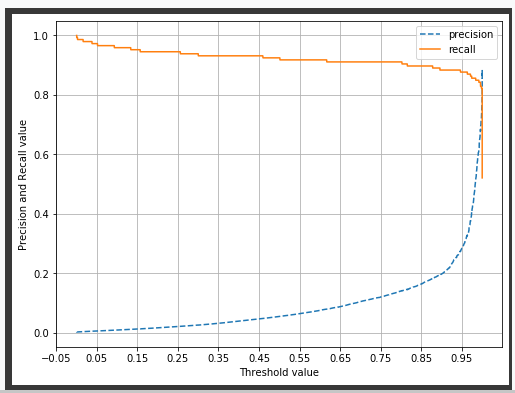
- 임계값이 0.99 이하에서는 재현율이 매우 좋고 정밀도가 극단적으로 낮다가 0.99 이상에서는 반대로 재현율이 대폭 떨어지고 정밀도가 높아진다.
- 임계값의 민감도가 너무 심하여 올바른 재현율/정밀도 성능을 얻을 수 없으므로 로지스틱 회귀 모델의 경우엔 SMOTE를 적용하여 올바른 모델을 생성하지 못했다.
스태킹 앙상블 p295

정리 p306
- 앙상블 기법은 결정 트리 기반의 다수의 약한 학습기를 결합해 변동성을 줄여 예측 오류응 줄이고 성능 개선 하고 있다.
- 결정트리는 알고리즘은 정보의 균일도에 기반한 규칙 트리를 만들어 예측합니다.
- 결정 트리의 단점으로는 균일한 최종예측 결과가 도출하기 위해 결정트리가 깊어지고 복잡해 지면서 과적합이 발생 되기 쉽다.
- 앙사블 기법은 대표적으로 배깅과 부스팅 방법으로 나눌 수 있다.
- 배깅방식은 랜덤 포레스트 이다.
- 현대는 배깅 보다 부스팅을 더 많이 사용한다.
- 부스팅에는 GBM이 있다.
- GBM은 뛰어난 예측 성능을 가졌지만 수행 시간이 너무 길다.
- XGBoost,LightGBM은 머신러닝 패키지 입니다.
- 스태킹은 여러 개의 개별 모델들이 생성한 예측 데이터를 기반으로 최종 메타 모델이 학습할 별도의 학습데이터 와 예측할 테스트 데이터 세트를 재 생성하는 기법이다.
출처:
https://colab.research.google.com/drive/17jkzmhVqdvMx6tUpEVKAYFP5zokFF7UO#scrollTo=WB-QfCmtf44f -> 책 정리 잘하심.
https://m.blog.naver.com/wideeyed/221867273249 -> 베이직 판다스 보기 좋음.
오류모음:
- TypeError: fit_transform() missing 1 required positional argument: 'X'
ex) scaler = StandardScaler -> scaler = StandardScaler() : 클라스에 괄호 없음.
