피마 인디언 당뇨병 데이터 세트
북아메리카 피마 지역 원주민의 Type-2 당뇨병 결과 데이터
https://www.kaggle.com/uciml/pima-indians-diabetes-database 에서 다운
< 데이터 세트 피처 >
- Pregnancies : 임신 횟수
- Glucose : 포도당 부하 검사 수치
- BloodPressure : 혈압(mm Hg)
- SkinThickness : 팔 삼두근 뒤쪽의 피하지방 측정값(mm)
- Insulin : 혈청 인슐린(mu U/ml)
- BMI : 체질량지수(체중(kg)/(키(m))^2)
- DiabetesPedigreeFunction : 당뇨 내력 가중치 값
- Age : 나이
- Outcome : 클래스 결정 값(0또는 1)
## (1) 피마 인디언 당뇨병 예측
# p173
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score
from sklearn.metrics import f1_score, confusion_matrix, precision_recall_curve, roc_curve
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
diabetes = pd.read_csv("/content/drive/MyDrive/book/diabetes.csv")
diabetes[:3]
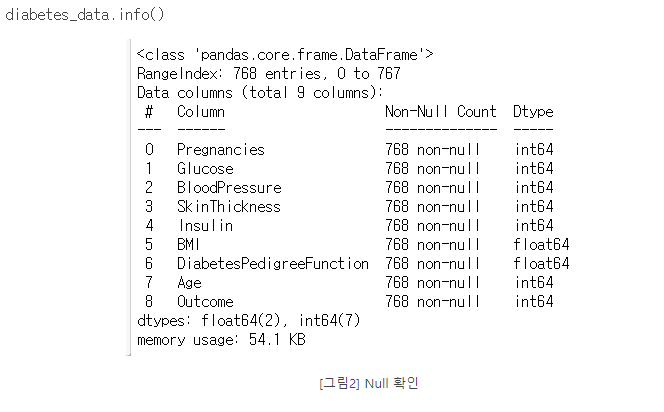
# null 값은 없으며 피처의 타입은 모두 숫자형이다.
# 피처 인코딩은 필요하지 않아 보입니다.
diabetes.info()
## (2) 피터 데이터 세트 X, 레이블 데이터 세트 y를 추출한다
#p175
# 피터 데이터 세트 X, 레이블 데이터 세트 y를 추출한다.
# 맨 끝이 Outcome 칼럼으로 레이블 값임. 칼럼 위치 -1을 이용해 추출
X = diabetes.iloc[:,:-1]
y = diabetes.iloc[:,-1]
X_train,X_test, y_train, y_test = train_test_split(X,y,test_size= .2, random_state= 156)
# 로지스틱 회귀로 학습, 예측 및 평가 수행.
lr_clf = LogisticRegression(solver = "liblinear")
lr_clf.fit(X_train, y_train)
pred = lr_clf.predict(X_test)
pred_proba = lr_clf.predict_proba(X_test)[:,-1] # pred_proba :각 클래스에 대한 확률이다.
get_clf_eval(y_test,pred,pred_proba)
# mean의 0을 각 칼럼의 평균으로 대체한다.
# p178
# 0값을 검사할 피처명 리스트
zero_features = ["Glucose", "BloodPressure","SkinThickness","Insulin","BMI"]
diabetes[zero_features].mean()
# zero_features 리스트 내부에 저장된 개별 피처들에 대해서 0값을 평균 값을 대체
diabetes[zero_features] = diabetes[zero_features].replace(0,diabetes[zero_features].mean())
diabetes[zero_features]
#diabetes
```python
## 표준화
# p178
X = diabetes.iloc[:,:-1]
y = diabetes.iloc[:,-1]
# StandardScaler 클래스를 이용해 피처 데이터 세트에 일괄적으로 스케일링 적용
scaler = StandardScaler()
scaler.fit_transform(X)
X_train,X_test, y_train, y_test = train_test_split(X,y,test_size= .2, random_state= 156)
# 로지스틱 회귀로 학습, 예측 및 평가 수행.
lr_clf = LogisticRegression(solver = "liblinear")
lr_clf.fit(X_train, y_train)
pred = lr_clf.predict(X_test)
pred_proba = lr_clf.predict_proba(X_test)[:,-1]
get_clf_eval(y_test,pred,pred_proba)
분류 p181
분류의 개요
- 지도학습은 레이블, 즉 명시적인 정답이 있는 데이터가 주어진 상태에서 학습하는 머신러닝 방식입니다.
- 직도학습의 대표적인 유형인 분류는 학습 데이터로 주어진 데이터의 피처와 레이블값을 머신러닝 알고리즘으로 학습해 모델을 생성,예측하는 것.
분류 알고리즘
- 베이즈(Bayes) 통계와 생성 모델에 기반한 나이브 베이즈(Naive Bayes)
- 독립변수와 종속변수의 선형 관계성에 기반한 로지스틱 회귀(Logistic Regression)
- 데이터 균일도에 따른 규칙 기반의 결정 트리(Decision Tree)
- 개별 클래스 간의 최대 분류 마진을 효과적으로 찾아주는 서포트 벡터 머신(Support Vector Machine)
- 근접 거리를 기준으로 하는 최소 근접(Nearest Neighbor) 알고리즘
- 심층 연결 기반의 신경망(Neural Network)
- 서로 다른(또는 같은) 머신러닝 알고리즘을 결합한 앙상블(Ensemble)
앙상블(Ensembel)
일반적으로 배깅(Bagging)과 부스팅(Boosting) 방식으로 나뉜다.
- 배깅(Bagging) 방식의 대표인 랜덤 포레스트(Random Forest)는 뛰어난 예측 성능, 상대적으로 빠른 수행 시간, 유연성 등으로 많은 분석가가 애용하는 알고리즘이다.
- 부스팅의 효시라고 할 수 있는 그래디언트 부스팅(Gradient Bossting)의 경우 뛰어난 예측 성능을 가지고 있지만, 수행 시간이 너무 오래 걸리는 단점을 가지고 있는데, XgBoost(eXtra Gradient Boost)와 LightGBM 등 기존 그래디언트 부스팅의 예측 성능을 발전시키는 알고리즘이 나오면서 정형 데이터의 분류 영역에서 가장 활용도가 높은 알고리즘으로 자리 잡았다.
결정트리 p183
- 앙상블의 기본 알고리즘으로 일반적으로 사용하는것을 결정 트리입니다.
- 매우 직관적이고, 쉽고 유연하게 적용될 수 있는 알고리즘이다.
- 데이터에 있는 규칙을 학습으 통해 자동으로 찾아내 트리 기반의 분류 규칙을 만드는 것입니다.
- 데이터의 어떤 기준을 바탕으로 규칙을 만들어야 효과적인 분류가 될 것인가가 알고리즘의 성능을 크게 좌우한다.
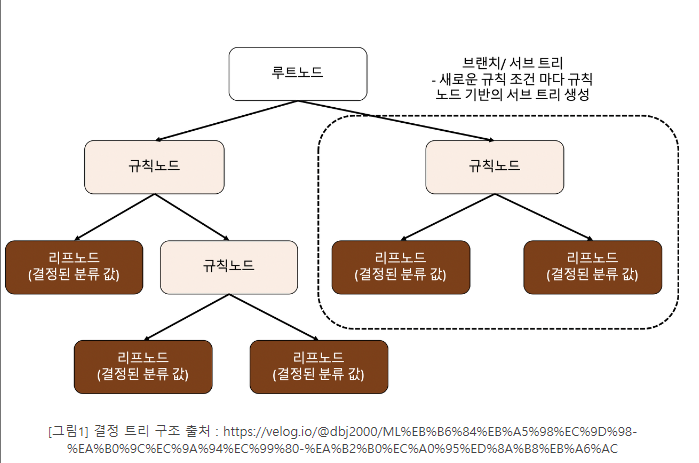
- 규칙 노드(Decision Node) : 규칙 조건이 되는 것
- 리프 노드(Leaf Node) : 결정된 클래스 값
- 서브 트리(Sub Tree) : 새로운 규칙 조건마다 생성
- 루트 노드 : 트리 구조가 시작되는 곳
-
반응 변수가 범주형인 경우
- 카이제곱 통계량의 p값: p값이 가장 작은 예측 변수와 그 떄의 최적 분리에 의해서 자식 마디를 형성
- 지니 지수: 불순도를 측정하는 하나의 지수로서 지니 지수를 가장 감소 시켜주는 예측 변수와 그 떄의 최적 분리에 의해서 자식 마디를 선택
- 엔트로피 지수: 이 지수가 가장 작은 예측변수와 그때의 최적 분리에 의해서 자식 마디 형성
-
반응 변수가 수치형인 경우
- 분산 분석에서의 F 통게량: p값이 가장 작은 예측변수와 그 뗴의 최적 분리에 의해서 자식 마디 형성
- 분산의 감소량: 에측 오차를 최소화하는 것과 동일한 기준으로 분산의 감소량을 최대화하는 기준의 최적의 분리에 의해서 자식 마다 형성
-
지니지수의 정의
-
집합에 이질적인 것이 얼마나 섞였는지를 측정하는 지표로 불순도를 측정한다.

-

- 의사결정나무의 학습 과정
- 재귀적 분기
구분하기 전보다 구분된 뒤에 각 영역의 순도가 증가하도록 입력 변수의 영역을 두개로 구분한다. - 가지치기
과적합을 방지하기 위하여 너무 자세하게 구분된 영역을 통합한다.
- 재귀적 분기
- 의사결정나무의 학습 진행 방향
- 구분 뒤 각 영역의 순도가 증가/불확실성(엔트로피, 지니지수)이 최대한 감소하는 방향으로 학습을 진행
- 재귀적 분기 방법
- 특정 영역에 속하는 개체들을 하나의 기준 변수 값의 범위에 따라 분기한다.
- 새로 생성될 자식 노드의 동질성이 최대화되도록 분기점을 선택한다.
- 불순도를 측정하는 기준으로 범주형 변수에 대해 지니계수, 수치형 변수에 대해 분산을 이용한다.
- 분기 횟수가 정해지지 않은 채로 사전에 설정한 기준을 만족할 때까지 분기를 반복하는 데서 재귀적 분기라는 이름이 붙었다.
- 가치치기 방법
- Full tree: 모든 Terminal node의 순도가 100%인 상태
- Full tree를 생성한 뒤 적절한 수준에서 Terminal node를 결합한다.
- 의사결정나무의 분기 수가 증가할 때 처음에는 새로운 데이터에 대한 오분류율아 감소하나 일정 수준 이상이 되면 오분류율이 되레 증가한다.
- 과적합을 방지하기 위해서 하위 노드들을 상위 노드로 결합한다.
- Pre-pruning : Tree를 생성하는 과정에서 최소 분기 기준을 이용하는 사전적 가지치기
-Post-pruning : Full-tree 생성 후, 검증 데이터의 오분류율과 Tree의 복잡도(끝노드의 수)등을 고려하는 사후적 가지치기

결정 트리 모델의 특징 p185
- 결정 트리 가장 큰 장점 : 정보의
균일도라는 룰을 기반으로 하고 있어서 알고리즘이 쉽고 객관적이다. - 결정 트리 가장 큰 단점 :
과적합(overfitting)으로 정확도가 떨어진다.- 피처 정보의 균일도에 따른 룰 규칙으로 서브 트리를 계속 만들다 보면 피처가 많고 균일도가 다양하게 존재할수록 트리의 깊이가 커지고 복잡해질 수밖에 없다.

장점:
- 화이트 박스 모형이며, 결과를 해석하고 이해하기 쉽다.
- 자료를 가공할 필요가 거의 없다.
- 수치 자료와 범주형 자료 모두에 적용할 수 있다.
-이상치 자체를 하나의 경우로 분류하기 때문에 이상치에 안정적이다. - 대규모의 데이터 셋에서도 잘 동작한다.
단점:
- 최적 결정 트리 알아낸다고 보장 할 수는 없다.
- 과적합: 훈련 데이터르 제대로 일반화하지 못할 겨우 너무 혼잡한 결정 트리 만들 수 있다.
- 데이터의 특성이 특정 변수에 수직/수평적으로 구분되지 못할 때 분류율이 떨어지고, 트리가 복잡해지는 문제가 발생한다.
- 약간의 데이터 변화에 트리의 모양이 전혀 달라질 수 있다. 즉, 분산이 큰 불안정한 방법이다.
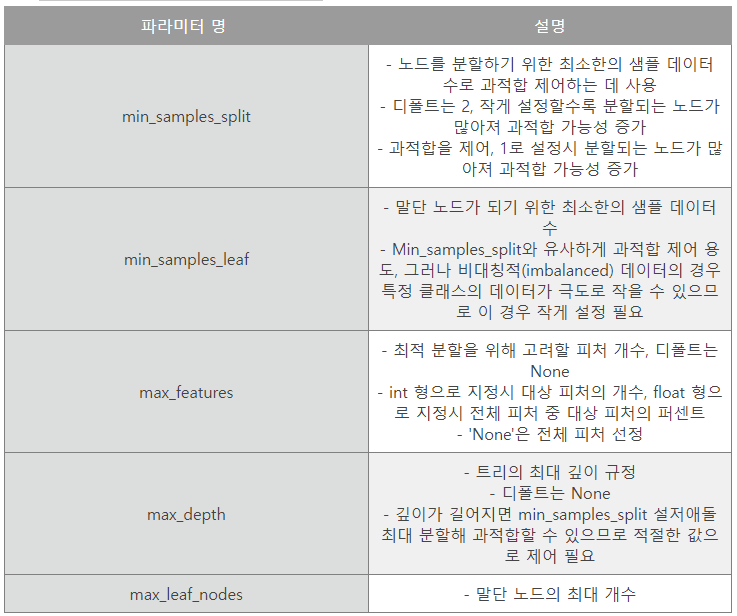
결정 트리 파라미터 p186
- 사이킷런 결정 트리 알고리즘 구현한 DecisionTreeClassifier와 DecisionTreeRegressor 클래스를 제공한다.
- 각 전자는 분류, 후자는 회귀를 위한 클래스
- 사이킷런 결정 트리 구현은 CART(Classification And Regression Trees) 알고리즘 기반이다.
- CART는 분류뿐만 아니라 회귀에서도 사용될 수 있는 트리 알고리즘이다.
- 둘 모두 파라미터는 동일한 파라미터 사용
결정 트리 모델의 시각화 p187
- 결정 트리 알고리즘이 어떠한 규칙을 가지고 트리를 생성하는지 시각적으로 보여줄 수 있는 방법 - Graphviz 패키지를 사용
- Graphviz는 원래 그래프 기반의 dot 파일로 기술된 다양한 이미지를 수비게 시각화할 수 있는 패키지다.
- 사이킷런은 export_graphviz() API 제공
- export_graphviz()는 함수 인자로 학습이 완료된 Estimator, 피처의 이름 리스트, 레이블 이름 리스트를 입력하면 학습된 결정 트리 규칙을 실제 트리 형태로 시각화해 보여준다.
붓꽃 데이터 세트 DecisionTreeClassifier 이용해 학습 뒤 규칙 트리 확인
# 붓꽃 데이터 세트 DecisionTreeClassifier 이용해 학습 뒤 규칙 트리 확인
# p190
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
#DecisionTreeClassifier 생성
dt_clf = DecisionTreeClassifier(random_state=156)
#붓꽃 데이터를 로딩하고, 학습과 테스트 데이터 세트로 분리
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=11)
#DecisionTreeClassifier 학슴.
dt_clf.fit(X_train, y_train)
# Graphviz 이용
from sklearn.tree import export_graphviz
# export_graphviz()의 호출 결과로 out_file로 지정된 tree.dot 파일을 생성
export_graphviz(dt_clf, out_file='tree.dot', class_names=iris_data.target_names,\
feature_names=iris_data.feature_names, impurity=True, filled=True)
import graphviz
# 주피터 노트북상에서 시각화
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)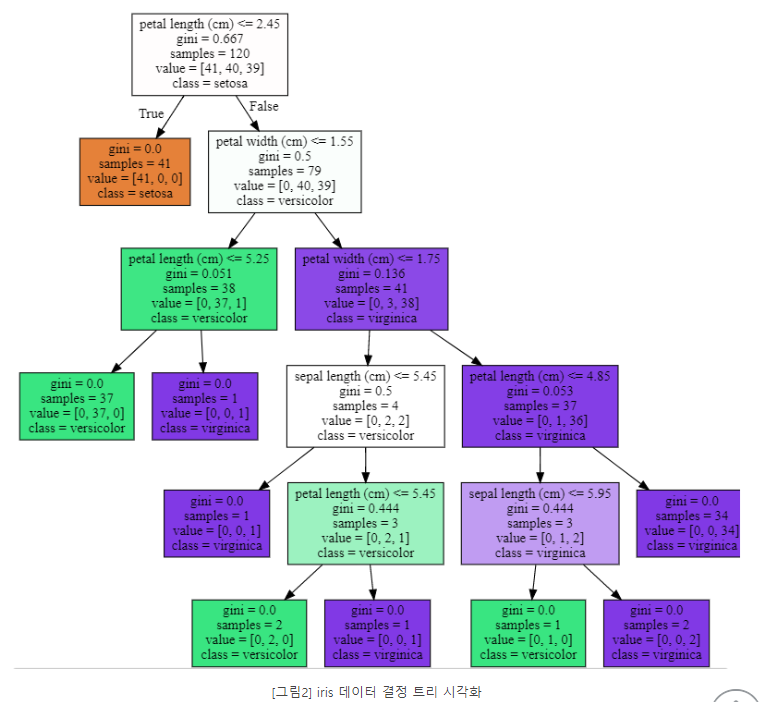
- petal length(cm) : <=2.24와 같이 피처의 조건이 있는 것은 자식 노드를 만들기 위한 규칙 조건이다. 이 조건이 없으면 리프 노드다.
- gini는 다음의 value=[]로 주어진 데이터 분포에서의 지니 계수다.
- samples는 현 규칙에 해당하는 데이터 건수다.
- value= []는 클래스 값 기반의 데이터 건수다. 붓꽃 데이터 세트는 클래스 값으로 0,1,2를 가지고 있으며, 0:Setosa, 41개, Vesicolor 40개, Virginica 39개로 데이터가 구성돼 있다는 의미다.
- 각 노드의 색깔은 붓꽃 데이터의 레이블 값을 의미한다.
-주황색은 0 : Setosa, 초록색은 1 : Versicolor, 보라색은 2 : Virginica 레이블을 나타낸다.
featureimportances 속성으로 피처별 중요도 값 매핑, 막대그래프 표현
# feature_importances_ 속성을 가져와 피처별로 중요도 값을 매핑하고 이를 막대그래프로 표현
import seaborn as sns
import numpy as np
%matplotlib inline
# feature umportance 추출
print("Feature importances:\n{0}".format(np.round(dt_clf.feature_importances_,3)))
# feature별 importance 매핑
for name, value in zip(iris_data.feature_names, dt_clf.feature_importances_):
print('{0} : {1:.3f}'.format(name,value))
# feature importance를 column 별로 시각화하기
sns.barplot(x=dt_clf.feature_importances_, y=iris_data.feature_names)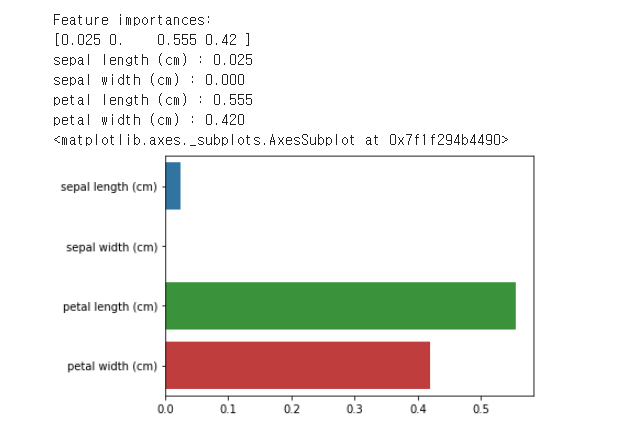
결정 트리 과적합(Overfitting)
- 분류를 위한 테스트용 데이터를 쉽게 만들 수 있도록 make_classification()함수 제공
# 결정 트리 과적합
# make_classifiaction()
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
%matplotlib inline
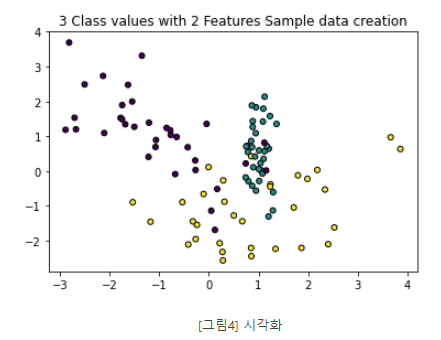
plt.title("3 Class values with 2 Features Sample data creation")
# 2차원 시각화를 위해서 피처는 2개, 클래스는 3가지 유형의 분류 샘플 데이터 생성
x_features, y_labels = make_classification(n_features=2, n_redundant=0, n_informative=2,\
n_classes=3, n_clusters_per_class=1, random_state=0)
# 그래프 형태로 2개의 피처로 2차원 좌표 시각화, 각 클래스 값은 다른 색깔로 표시된다.
plt.scatter(x_features[:,0], x_features[:,1], marker='o', c=y_labels, s=25, edgecolor='k')- x,y 축으로 나열된 2차원 그래프, 3개의 클래스 값 구분은 색깔로 돼 있다.
결정 기준 경계 시각화
# 결정 기준 경계 시각화
from sklearn.tree import DecisionTreeClassifier
def visualize_boundary(model, X, y):
fig,ax = plt.subplots()
# 학습 데이타 scatter plot으로 나타내기
ax.scatter(X[:, 0], X[:, 1], c=y, s=25, cmap='rainbow', edgecolor='k',
clim=(y.min(), y.max()), zorder=3)
ax.axis('tight')
ax.axis('off')
xlim_start , xlim_end = ax.get_xlim()
ylim_start , ylim_end = ax.get_ylim()
# 호출 파라미터로 들어온 training 데이타로 model 학습 .
model.fit(X, y)
# meshgrid 형태인 모든 좌표값으로 예측 수행.
xx, yy = np.meshgrid(np.linspace(xlim_start,xlim_end, num=200),np.linspace(ylim_start,ylim_end, num=200))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
# contourf() 를 이용하여 class boundary 를 visualization 수행.
n_classes = len(np.unique(y))
contours = ax.contourf(xx, yy, Z, alpha=0.3,
levels=np.arange(n_classes + 1) - 0.5,
cmap='rainbow', clim=(y.min(), y.max()),
zorder=1)
# 특정한 트리 생성 제약 없는 결정 트리의 학습가 결정 경계 시각화
dt_clf = DecisionTreeClassifier().fit(x_features, y_labels)
visualize_boundary(dt_clf, x_features, y_labels)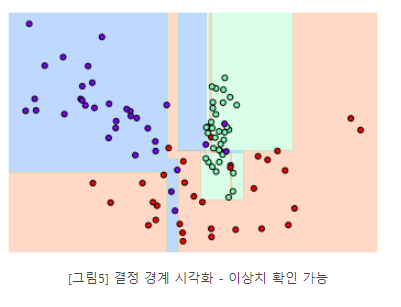
- 일부 이상치(Outlier) 데이터까지 분류해 결정 기준 경계가 매우 많아졌다.
- 복잡한 모델은 학습 데이터 세트의 특성과 약간만 다른 형태의 데이터 세트를 예측하면 예측 정확도가 떨어지게 된다.
min_samples_leaf = 6 설정해 6개 이하의 데이터는 리프 노드를 생성하 수 있도록 리프 노드 생성 규칙을 완화
# min_samples_leaf = 6 설정해 6개 이하의 데이터는 리프 노드를 생성하 수 있도록 리프 노드 생성 규칙을 완화
dt_clf = DecisionTreeClassifier(min_samples_leaf=6).fit(x_features, y_labels)
visualize_boundary(dt_clf, x_features, y_labels)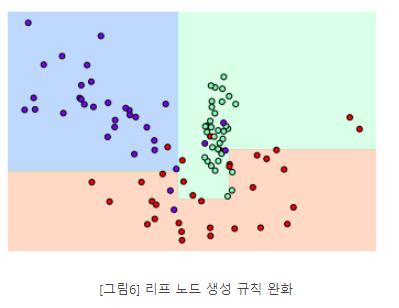
- 좀 더 일반화된 분류 규칙에 따라 분류됐음을 알 수 있다.
결정 트리 실습 - 사용자 행동 인식 데이터 세트
- 결정 트리 이용해 UCI 머신러닝 리포지토리(Machine Learning Repository)에서 제공하는 사용자 행동 인식(Human Activity Recognition) 데이터 세트에 대한 예측 분류 수행
- 해당 데이터는 스마트폰 센서를 장ㅁ착한 뒤 사람의 동작과 관련된 여러 가지 피처를 수집한 데이터다.
# 결정 트리 실습 - 사용자 행동 인식 데이터 세트
# p202
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# features.txt 파일에는 피처 이름 index와 피처명이 공백으로 분리되어 있음. 이를 DataFrame으로 로드.
feature_name_df = pd.read_csv('/content/drive/MyDrive/book/features.txt',sep='\s+',
header=None,names=['column_index','column_name'])
# 피처명 index를 제거하고, 피처명만 리스트 객체로 생성한 뒤 샘플로 10개만 추출
feature_name = feature_name_df.iloc[:, 1].values.tolist()
print('전체 피처명에서 10개만 추출:', feature_name[:10])- 인체 움직임 관련 속성의 평균/표준편차가 X,Y,Z 축 값으로 돼 있다.
중복된 피처 얼마나 있는지 확인
# 중복된 피처 알아보기
feature_dup_df = feature_name_df.groupby('column_name').count()
print(feature_dup_df[feature_dup_df['column_index'] > 1].count())
feature_dup_df[feature_dup_df['column_index'] > 1].head(10)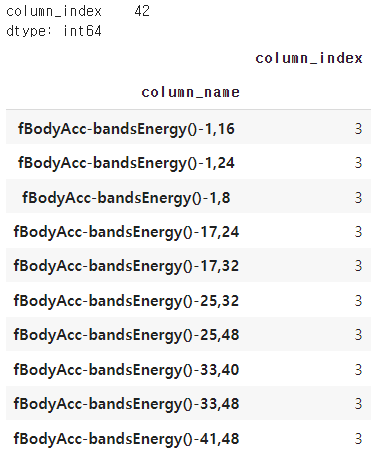
중복된 피처수 42개니 이름 _1또는 _2를 추가해 바꾸기
# 중복된 피처 이름 바꾸기
def get_new_feature_name_df(old_feature_name_df):
feature_dup_df = pd.DataFrame(data=old_feature_name_df.groupby('column_name').cumcount(),columns=['dup_cnt'])
feature_dup_df = feature_dup_df.reset_index()
new_feature_name_df = pd.merge(old_feature_name_df.reset_index(), feature_dup_df, how='outer')
new_feature_name_df['column_name'] = new_feature_name_df[['column_name','dup_cnt']].apply(lambda x:x[0]+'_'+str(x[1]) if x[1] > 0 else x[0], axis=1)
new_feature_name_df = new_feature_name_df.drop(['index'], axis=1)
return new_feature_name_dfimport pandas as pd
def get_human_dataset():
# 각 데이터 파일은 공백으로 분리되어 있으므로 read_csv에서 공백 문자를 sep으로 할당.
feature_name_df = pd.read_csv('/content/drive/MyDrive/book/features.txt',sep='\s+',\
header=None, names=['column_index', 'column_name'])
# 중복된 피처명을 수정하는 get_new_feature_name_Df()를 이용, 신규 피처명은 DataFrame 생성
new_feature_name_df = get_new_feature_name_df(feature_name_df)
# DataFrame에 피처명을 칼럼으로 부여하기 위해 리스트 객체로 다시 변환
feature_name = new_feature_name_df.iloc[:,1].values.tolist()
# 학습 피처 데이터세트와 테스트 피처 데이터를 DataFrame으로 로딩, 칼럼명은 feature_name 적용
X_train = pd.read_csv('/content/drive/MyDrive/book/train/X_train.txt', sep='\s+', names=feature_name)
X_test = pd.read_csv('/content/drive/MyDrive/book/test/X_test.txt',sep='\s+', names=feature_name)
# 학습 레이블과 테스트 레이블 데이터를 DataFrame으로 로딩하고 칼럼명은 action으로 부여
y_train = pd.read_csv('/content/drive/MyDrive/book/train/y_train.txt', sep='\s+', header=None, names=['action'])
y_test = pd.read_csv('/content/drive/MyDrive/book/test/y_test.txt', sep='\s+', header=None, names=['action'])
# 로드된 학습/테스트용 DataFrame
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_human_dataset()
print('## 학습 피처 데이터셋 info()')
print(x_train.info())
- #학습데이터세트:7352, 피처:561, 전부 float형의 숫자형으로 카테고리 인코딩 필요없음
# 레이블 분포도 값 확인
print(y_train['action'].value_counts())
- 레이블 값은 6개이고 분포도는 특정 값으로 왜곡되지 않고 비교적 고르게 분포되어있다.
# p205
# 동작 예측 분류 수행
# 하이퍼파라미터 전부 추출
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 예제 반복 시 마다 동일한 예측 결과 도출을 위해 random_state 설정
dt_clf = DecisionTreeClassifier(random_state=156)
dt_clf.fit(X_train , y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test , pred)
print('결정 트리 예측 정확도: {0:.4f}'.format(accuracy))
# DecisionTreeClassifier의 하이퍼 파라미터 추출
print('DecisionTreeClassifier 기본 하이퍼 파라미터:\n', dt_clf.get_params())
트리 깊이가 예측 정확도에 주는 영향 확인해보기
# p208
# 트리 깊이가 예측 정확도에 주는 영향을 확인
from sklearn.model_selection import GridSearchCV
params = {
'max_depth' : [6,8,10,12,16,20,24],
'min_samples_split' : [16,24],
}
grid_cv = GridSearchCV(dt_clf, param_grid=params, scoring='accuracy', cv=5, verbose=3,n_jobs= -1)
grid_cv.fit(X_train, y_train)
print('GridSearchCV 최고 평균 정확도 수치 : {0:.4f}'.format(grid_cv.best_score_))
print('GridSearchCV 최적 하이퍼 파라미터 : ',grid_cv.best_params_)
best_df_clf = grid_cv.best_estimator_
pred1 = best_df_clf.predict(X_test)
accuracy_score(y_test,pred1)
print('결정 트리 예측 정확도:{0:4f}'.format(accuracy))
best_df_clf = grid_cv.best_estimator_
best_df_clf.feature_importances_ import seaborn as sns
ftr_importances_values = best_df_clf.feature_importances_
# Top 중요도로 정렬을 쉽게 하고, 시본(Seaborn)의 막대그래프로 쉽게 표현하기 위해 Series변환
ftr_importances = pd.Series(ftr_importances_values, index=X_train.columns )
# 중요도값 순으로 Series를 정렬
ftr_top20 = ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8,6))
plt.title('Feature importances Top 20')
sns.barplot(x=ftr_top20 , y = ftr_top20.index)
plt.show() 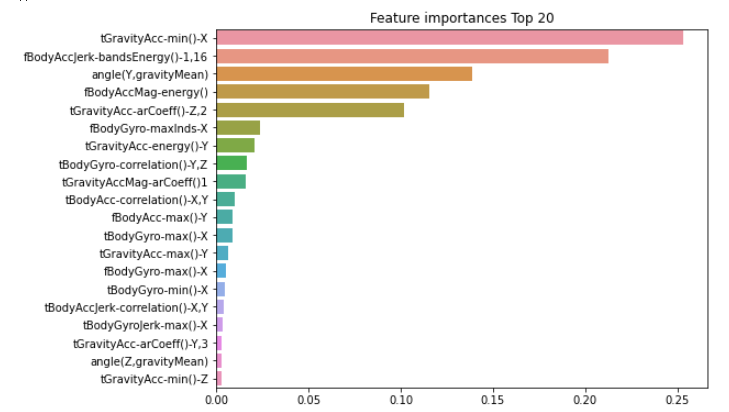
출처: https://asthtls.tistory.com/1203?category=904088 [포장빵의 IT:티스토리]

새싹 빅테이터 개발자