(p129) 사이킷런으로 수행하는 타이나닉 생존자 예측
./ -> 내 위치를 알려줌
https://rfriend.tistory.com/262
결측치 평균으로 대처하기 -> fillna

평가 p145
분류의 성능 평가 지표부터 살펴보겠다.
- 정확도 (Accuracy)
- 오차행렬 (confusion matrix)
- 정밀도 (Precision)
- 재현율 (Recall)
- F1스코어
- ROC AUC
정확도(Accuracy)
정확도(Accuracy) = 예측 결과가 동일한 데이터 건수 / 전체 예측 데이터 건수
정확도는 직관적으로 모델 예측 성능을 나타내는 평가 지표다.
하지만 이진 분류의 경우 데이터의 구성에 따라 ML 모델의 성능을 왜곡할 수 있기 때문에 정확도 수치 하나만 가지고 성능을 평가하지 않는다.
오차(confusion matrix,혼동) 행렬
: 학습된 분류 모델이 예측을 수행하면서 얼마나 헷갈리고 있는지도 함께 보여주는 지표
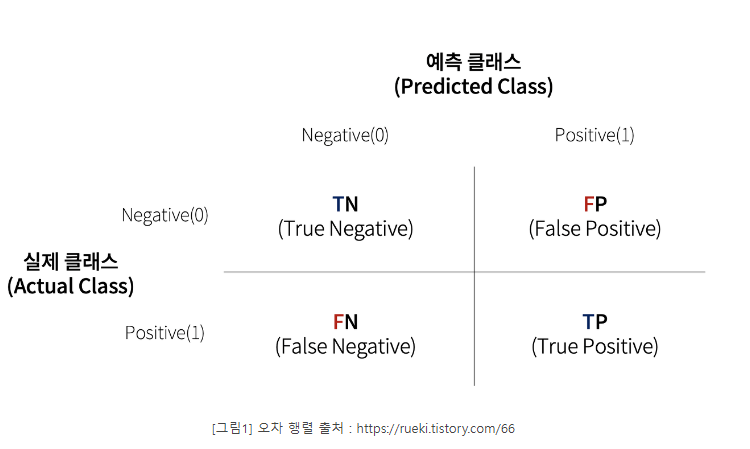
-
TN, FP, FN, TP는 예측 클래스와 실제 클래스의 Positive 결정 값(값 1)과 Negative 결정 값(값 0)의 결합에 따라 결정된다.
-
TN은 예측값을 Negative 값 0으로 예측했고 실제 값 역시 Negative 값 0
-
FP는 예측값을 Positive 값 1로 예측했는데 실제 값은 Negative 값 0
-
FN은 예측값을 Negative 값 0으로 예측했는데 실제 값은 Positive 값 1
-
TP는 예측값을 Positive 값 1로 예측했는데 실제 값 역시 Positive 값 1
-
TP, TN, FP, TN값을 조합해 Classifier의 성능을 측정할 수 이쓴ㄴ 주요 지표인 정확도(Accuracy), 정밀도(Precision), 재현율(Recall)값을 알 수 있다.
정밀도와 재현율 p154
: 정밀도와 재현율은 Positive 데이터 세트의 예측 성능에 좀 더 초점을 맞춘 평가 지표이다.
#예측예측을 Positive로 한 대상 중에 예측과 실제 값이 Positive로 일치한 데이터의 비율을 뜻한다.
- 정밀도 (Precision) = tp/(tp+fp) = 찐P/(예상)
#실제 값이 Positive인 대상 중에 예측과 실제 값이 Positive로 일치한 데이터의 비율을 뜻한다.
- 재현율 (Recall) = tp/(tp+fn) = 찐P/(실제P)= 민감도 = TPR
- 특이도 (Specificity)= tn/(fp+tn)= 찐N/(실제N)
재현율이 중요 지표인 경우는 실제 Positive 양성 데이터를 Negative로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우다.
정밀도가 상대적으로 더 중요한 지표인 경우는 실제 Negative 음성인 데이터 예측을 Positive 양성으로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우
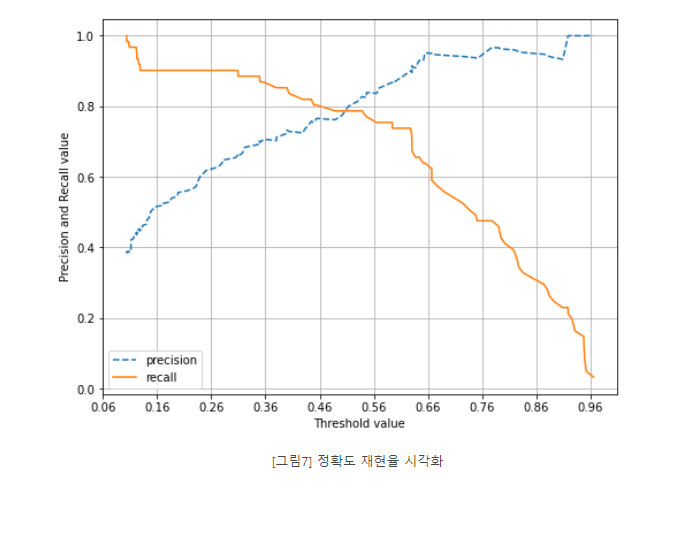
정밀도와 재현율의 맹점 p165
:Positive 예측의 임곗값을 변경함에 따라 정밀도와 재현율의 수치가 변경된다.
임곗값의 이러한 변경은 업무 환경에 맞게 두 개의 수치를 상호 보완할 수 있는 수준에서 적용돼야 한다.
-
정밀도 100% p165
정밀도 = TP / (TP+FP)
예) 전체 환자 1000명 중 확실한 Positive 징후만 가진 환자는 단 1명이라고 하면 이 한 명만 Positive로 예측하고 나머지는 모두 Negative로 예측하더라도FP는 0, TP는 1이 되므로 정밀도는 1/(1+0)으로 100%가 된다. -
재현율 100%가 되는 방법 p165
모든 환자를 Positive로 예측하면 된다.
재현율 = TP / (TP + FN)
전체 환자 1000명을 다 Positive로 예측. 이 중 30명이 양성이라도 tn이 수치에 포함되지 않고fn은 아예 0이므로 30/(30+0)으로 100%가 된다.
F1스코어 p166
: 정밀도와 재현율을 결합한 지표입니다.

ROC 곡선과 AUC p167
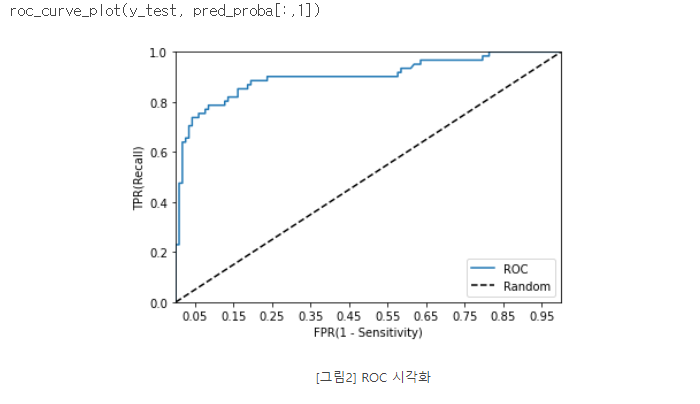
일반적으로 ROC 곡선 자체는 FPR과 TPR의 변화 값을 보는 데 이용하며 분류의 성능 지표로 사용되는 것은 ROC 곡선 면적에 기반한 AUC 값으로 결정한다.
AUC(Area Under Curve) 값은 ROC 곡선 밑의 면적을 구한 것으로서 일반적으로 1에 가까울수록 좋은 수치다.
AUC 수치가 커지려면 FPR이 작은 상태에서 얼마나 큰 TPR을 얻을 수 이쓴냐가 관건이다
출처: https://asthtls.tistory.com/1200 [포장빵의 IT:티스토리] ->정밀도와 재현율
