[14일 복습 문제]
- 무작위로 섞어서 [1,2,3,4,5]
import random
a=[1,2,3,4,5]
random.shuffle(a)
a -> [5, 3, 1, 2, 4]
- x의 5배의 숫자들 리스트로 구하기
x=[5,6,7,8]
list(map(lambda x : 5*x, a))-> [25, 30, 35, 40]
- while문 사용하여 1-9 반복 출력하시오
i = 0
while i< 9:
i += 1
print(i)- for 문 이용하여 [5,10,15,20] 만들기
a=[1,2,3,4]
li=[]
for i in a:
li.append(i*5)
li -> [5, 10, 15, 20]
- a=" l like apble And abple" -> 'I like apble And abple'
import re
re.sub("b","p",'I like apble And abple')-> 'I like apple And apple'
- phone_number= ['010-123-1234', '010-111-1111', '010-222-2222', '010-333-3333', '010-444-4444', '010-555-5555', '010-666-6666', '010-777-7777', '010-888-8888', '010-999-9999']
import re
for string in phone_number:
print(re.sub("\d{2}-\d{4}", "**-****", string)) ->
010-1-**
010-1-**
010-2-**
010-3-**
010-4-**
010-5-**
010-6-**
010-7-**
010-8-**
010-9-**
- 외자인 이름 "A"로 바꾸기
#li = ['손흥민', '황의조', '이 호', '황희찬', '홍 철']
- 외자인 이름 "A"로 바꾸기
#(1)
li = ['손흥민', '황의조', '이 호', '황희찬', '홍 철']
for i in li:
print(re.sub(".[ ].", "A", i), end = ", ")
#(2)
li = ['손흥민', '황의조', '이 호', '황희찬', '홍 철']
for i in li:
print(re.sub(".\s.","A",i))
#(3)
li = ['손흥민', '황의조', '이 호', '황희찬', '홍 철']
for i in li:
a = re.sub("\w\s\w","A",i)
print(a) - 20개의 문자열을 가진 리스트를 만드세요.
#조건1. 각 문자열의 길이는 최대 10, 최소1
#조건2. 각각 33.3333퍼센트의 확률로 문자열 안의 문자는
#대문자(ascii code 65~90) 이거나 chr(65) -> 'A'
#소문자(ascii code 97~ 122)이거나 chr(97) -> 'a'
#숫자
- 20개의 문자열을 가진 리스트를 만드세요.
#(1)
words = []
for count in range(20):
word = ''
while len(word) < random.randint(1,10):
a = random.randint(1,3)
if a == 1:
English = chr(random.randint(65,90))
word += English
elif a == 2:
english = chr(random.randint(97,122))
word += english
else:
number = str(random.randint(0,9))
word += number
words.append(word)
print(words)
#(2)
import random
words = []
for count in range(20):
word = ''
length = random.randint(1,10)
while True:
prob = random.randint(1,3)
if prob == 1: word = word + chr(random.randint(65,90))
elif prob == 2: word = word + chr(random.randint(97,122))
else: word = word + str(random.randint(0,9))
if len(word) == length: break
words.append(word)
words
#(3)
words = []
for count in range(20) :
word = ""
while len(word) < random.randint(1, 10) :
word += ''.join(random.choice(str(random.randint(0,9)) + chr(random.randint(65, 90))+chr(random.randint(97, 122))))
words.append(word)
words- 앞글자 소문자 맨뒷글자 대문자
li=['Vk', 'sSf', 'F7A', '1dz2dh', 'dK', '6277', '9wEE', 'b', '8xf', '4yl2fT', '44', 'Zbd65wY', 'F', 'rcbY', 'HqA', '92V2m', 'Y1Q1', 'boqOf', 'BlL', 'fYG']
for string in li:
print(re.sub("^[a-z].+[A-Z]$", "#", string), end = ", ")
- 10. 모든 글자 앞 뒤로
li=['Vk', 'sSf', 'F7A', '1dz2dh', 'dK', '6277', '9wEE', 'b', '8xf', '4yl2fT', '44', 'Zbd65wY', 'F', 'rcbY', 'HqA', '92V2m', 'Y1Q1', 'boqOf', 'BlL', 'fYG']
for string in li:
print(re.sub("^[A-z].+[A-z]$", "#", string), end = ", ")[ 오전 수업 시작 p298 ]
[ 파이썬에서 정규 표현식을 지원하는 re 모듈 ]
import re
p = re.compile('ab*')
- [p = re.compil]
:정규표현식을 컴파일 한다.
p : 컴파일된 패턴 객체
#for string in li:
#print(re.sub("^[A-z].+[A-z]$", "#", string), end = ", ")
#어떤 패턴에 대하여 바꾸어라 어떤 문장에 대하여
p = re.compile("^[A-z].+[A-z]$")
type(p)-> re.Pattern
#1번 방법 권장
#(1)
p = re.compile("^[A-z].+[A-z]$")
p.sub("#", string)#(2)
re.sub("^[A-z].+[A-z]$", "#", string)
[ 정규식을 사용한 문자열 검색 p298 ]

p = re.compile("[a-z]+")
match() : 문자열의 처음부터 정규식과 매치
p.match("python") -> <re.Match object; span=(0, 6), match='python'> 객체 돌려줌
p.match("PYTHONpython1234") -> none
seaech() : 문자열 전체를 검색하여 정규식과 매치되는지.
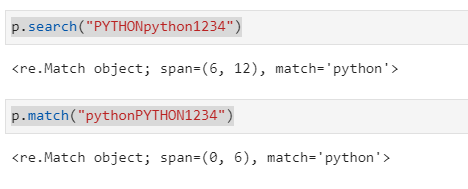
findall() : 정규식과 매치되는 모든 문자열을 리스트로 나옴.
p.findall("PYTHONpython1234") -> ['python']
finditer() : 정규식과 매치되는 모든 문자열을 반복 가능한 객체로 돌려줌.
p.finditer("PYTHONpython1234") -> <callable_iterator at 0x2391f8e4340>
:finditer는 findall과 동일하지만 그 결과로 반복 가능한 객체(iterator object)를 돌려준다. 반복 가능한 객체가 포함하는 각각의 요소는 match 객체이다.
[ match 객체의 메서드 p301 ]

#자주 사용한다. group()
p.match("pythonPYTHON1234").group()
[ 오후 수업 시작 - 강력한 정규표현식의 세계로 p309 ]
[ 메타 문자 ]
-
|
| : 메타 문자는 or과 동일한 의미로 사용된다. A|B라는 정규식이 있다면 A 또는 B라는 의미가 된다. -
^
^ : 메타 문자는 문자열의 맨 처음과 일치함을 의미한다. -
: 메타 문자는 ^ 메타 문자와 반대의 경우이다. 즉 $는 문자열의 끝과 매치함을 의미한다.
-
\A
\A : 문자열의 처음과 매치됨을 의미한다. -
\Z
\Z : 문자열의 끝과 매치됨을 의미한다. -
\b
\b : 단어 구분자(Word boundary)이다. 보통 단어는 whitespace에 의해 구분된다.
\b 메타 문자를 사용할 때 주의해야 할 점이 있다. \b는 파이썬 리터럴 규칙에 의하면 백스페이스(BackSpace)를 의미하므로 백스페이스가 아닌 단어 구분자임을 알려 주기 위해 r'\bclass\b'처럼 Raw string임을 알려주는 기호 r을 반드시 붙여 주어야 한다.
- \B
\B : 메타 문자는 \b 메타 문자와 반대의 경우이다. 즉 whitespace로 구분된 단어가 아닌 경우에만 매치된다.
예시)
print(p.search('no class at all')) 여기에서 no class 안에 o c 사이에는 2개의 바운더리가 있다. -> o_^_c
[ 그루핑(Grouping) ]
:그룹을 만들어 주는 메타 문자는 바로 ( )이다.
sentence = "park 010-1234-1234"
p = re.compile(r'(\w+)\s((\d+)[-]\d+[-]\d+)')
* 이름만 뽑기 (\w+)
p.search(sentence).group(1) -> 'park'
* 전화번호만 뽑기 (\d+)[-]\d+[-]\d+)
p.search(sentence).group(2) -> '010-1234-1234'
* 국번만 뽑기 (\d+)
p.search(sentence).group(3) -> '010'
* 그룹 전부다 뽑기 (\w+)\s((\d+)[-]\d+[-]\d+)
p.search(sentence).group(0) -> 'park 010-1234-1234'
* 바꿔 쓰기
print(p.search(sentence).group(2),p.search(sentence).group(1))
-> 010-1234-1234 park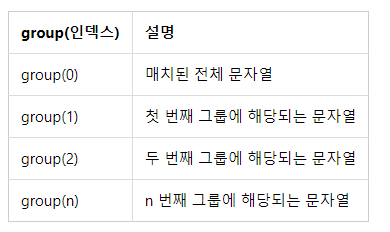
[ 그루핑된 문자열에 이름 붙이기 p314 ]
(?P < name > )
(\w+) --> (?P < name > \w+)
: (\w+)라는 그룹에 name이라는 이름을 붙인 것에 불과하다. 여기에서 사용한 (?...) 표현식은 정규 표현식의 확장 구문이다.
sentence = "park 010-1234-1234"
p = re.compile(r'(?P<family>\w+)\s((\d)+[-]\d+[-]\d+)')
p.search(sentence).group("family") -> 'park'[ 전방 탐색 ]
p = re.compile(".+:")
m = p.search("http://goolgle.com")
m
-> <re.Match object; span=(0, 5), match='http:'>
m.group()
-> 'http:' 정규식 .+:과 일치하는 문자열로 http:를 돌려주었다.
긍정형 전방 탐색((?=...))
... 에 해당되는 정규식과 매치되어야 하며 조건이 통과되어도 문자열이 소비되지 않는다.부정형 전방 탐색((?!...))
...에 해당되는 정규식과 매치되지 않아야 하며 조건이 통과되어도 문자열이 소비되지 않는다.
[긍정형 전방 탐색]
긍정형 전방 탐색을 사용하면 http:의 결과를 http로 바꿀 수 있다.
p = re.compile(".+(?=:)")
m = p.search("http://goolgle.com")
m.group()
-> 'http'정규식 중 :에 해당하는 부분에 긍정형 전방 탐색 기법을 적용하여 (?=:)으로 변경하였다.
검색 결과에서는 :이 제거된 후 돌려주는 효과가 있다.
[후방탐색]
p = re.compile("(?=:).+")
m = p.search("http://goolgle.com")
m.group()
-> '://goolgle.com'
* ll뒤로 나온다.
p = re.compile("(?<=ll).+")
m = p.search("hello2022")
m.group()
-> 'o2022'
* < 없애면 ll포함 하여 나옴.
p = re.compile("(?=ll).+")
m = p.search("hello2022")
m.group()
-> 'llo2022'
* ll기준으로 전방으로 나옴.
p = re.compile(".+(?=ll)")
m = p.search("hello2022")
m.group()
->'he'[ 문자열 바꾸기 p318 ]
:sub 메서드를 사용하면 정규식과 매치되는 부분을 다른 문자로 쉽게 바꿀 수 있다.
p = re.compile(r'(?P<name>\w+)\s+(?P<phone>(\d)+[-]\d+[-]\d+)')
print(p.sub("\g<2> \g<1>","park 010-1234-1234"))
-> 010-1234-1234 park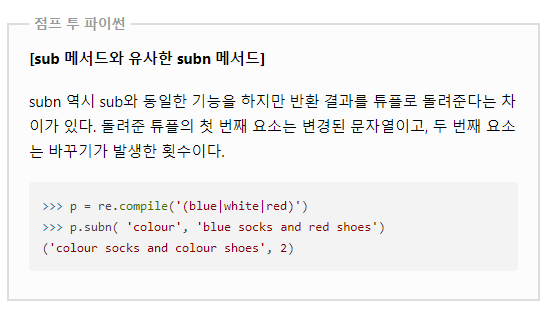
[ Greedy vs Non-Greedy p320 ]
data = ["soso", "sososo", "sosososo", "sososososo"]
p = re.compile(r'(so){3,5}')
for i in data:
print(p.search(i))
-> None
<re.Match object; span=(0, 6), match='sososo'>
<re.Match object; span=(0, 8), match='sosososo'>
<re.Match object; span=(0, 10), match='sososososo'> -> 최대한의 문자열을 모두 소비해 버렸다.
- non-greedy 문자인 ?를 사용하면 *의 탐욕을 제한할 수 있다.
data = ["soso", "sososo", "sosososo", "sososososo"]
p = re.compile(r'(so){3,5}?')
for i in data:
print(p.search(i))
-> None
<re.Match object; span=(0, 6), match='sososo'>
<re.Match object; span=(0, 6), match='sososo'>
<re.Match object; span=(0, 6), match='sososo'> - non-greedy 문자인 ?는 *?, +?, ??, {m,n}?와 같이 사용할 수 있다. 가능한 한 가장 최소한의 반복을 수행하도록 도와주는 역할을 한다.
